Apple A14
- Replacing x86 - The next big step
- Apple's Humongous CPU Microarchitecture
- out-of-order execution capabilities
- Execution Units
- Integer
- floating point and vector
Replacing x86 - The next big step
Apple A14 不使用X86,使用Arm ISA的自有内部处理器和CPU微体系结构
2006 年 放弃了IBM的PowerPC ISA和处理器,转而使用intel x86设计
2020年 放弃了intel x86设计,转而使用Arm ISA的自有内部处理器和CPU微体系结构
M1是苹果第一款以Mac为设计理念的SoC.
With four large performance cores, four efficiency cores, and an 8-GPU core GPU, it features 16 billion transistors on a 5nm process node. Apple’s is starting a new SoC naming scheme for this new family of processors, but at least on paper it looks a lot like an A14X.
4个core,8个GPU,将DRAM放置在计算芯片的一侧,不是顶部有助于确保这些芯片可以高效冷却。 芯片上可以找到128bit DRAM总线(类似AXI总线)。
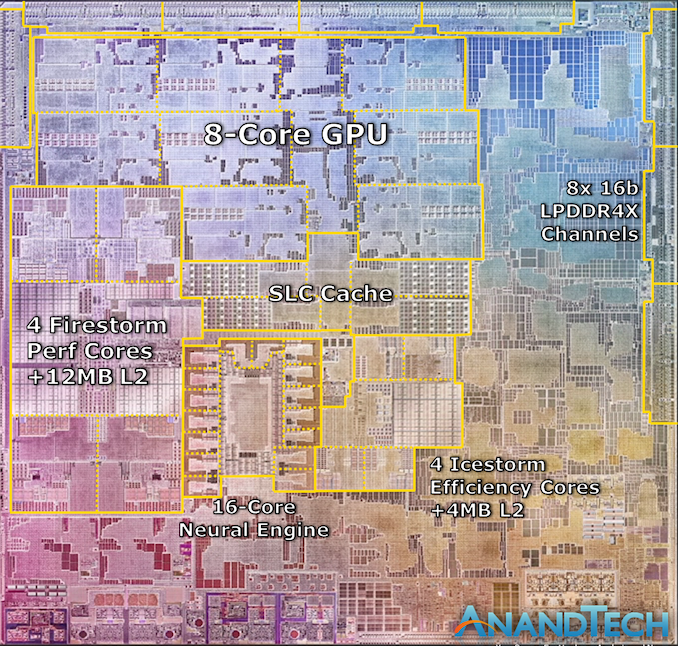
可以看到CORE 具有12MB的L2缓存,A14只有8MB的L2缓存。
Icestorm Efficiency Cores位于SOC的中心,所有的IP可以共享该资源。
M1可以被看做是一个真正的soc,包括了Mac在笔记本电脑里需要的独立芯片功能,像是I/O控制器,SSD和安全控制器( I/O controllers and Apple’s SSD and security controllers)
Project Marklar : Leveraging the flexibility of the Mac OS X and its underlying Darwin kernel, which like other Unixes is designed to be portable, Apple had been maintaining an x86 version of Mac OS X. 其可以不必绑定在PowerPC 及其大端内存模型上,走出了一个新的生态系统。
参考来源
Apple’s Humongous CPU Microarchitecture
A14: Firestorm CPU
A13: Lighting CPU
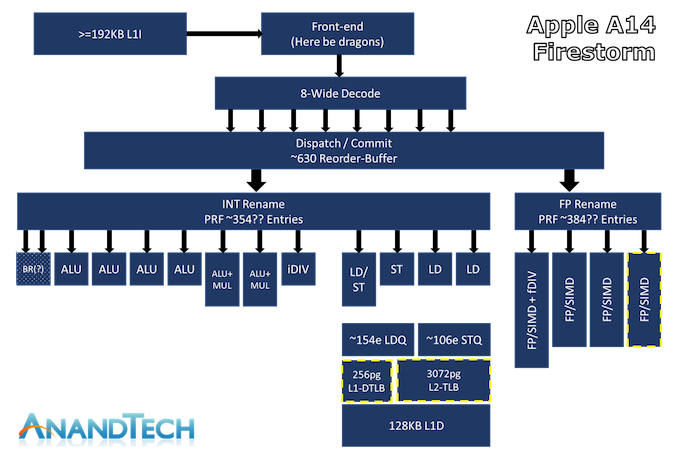
A14 an 8-wide decode block
A11-12 an 7-wide decode block
| AMD’s Zen | Intel’s µarch’s | X86 CPU | Intel | Samsung M3 | Arm silicon | Arm Cortex-X1 |
|---|---|---|---|---|---|---|
| 1-3 | X | 4 | 1+4 | 6 | 4 | 5 |
out-of-order execution capabilities
ROB (Re-order Buffer)
| Lightning | Firestorm | Intel’s Sunny Cove and Willow Cove cores | AMD’s newest Zen3 | Cortex-X1 |
|---|---|---|---|---|
| 560 instructions | 630 instruction | 352 instructions | 256 instructions | 224 instructions |
| A13 | A14 |
Execution Units
Integer
in-flight instructions and renaming physical register file capacity we estimate at around 354 entries
7 execution ports for actual arithmetic operations
4 simple ALUs capable of ADD instructions
2 complex units which feature also MUL (multiply) capabilities
1 dedicated integer division unit
The core is able to handle 2 branches per cycle,
one or two dedicated branch forwarding ports
an apparent slight increase (yes) in the integer division latency of that unit.
7个ALU
4个add 2个乘 1个专用除法,除法延时增大了一点点
floating point and vector
功能增加了33%, Apple 现在共有4个执行管道(add one)。
The FP rename registers here seem to land at 384 entries, which is again comparatively massive. The four 128-bit NEON pipelines。 do 4 FADDs and 4 FMULs per cycle with respectively 3 and 4 cycles latency。
吞吐量较低得指令是FP指令,倒数,平方根操作,在4个管道中,吞吐量只有1.
四个执行端口:一个负载/存储,一个专用存储和两个专用加载单元。内核可以执行每个周期的最大 3 次负载和每个周期的 2 个存储,但最多只能同时执行 2 个负载和 2 个存储。
148-154 outstanding loads and around 106 outstanding stores
AMD’s Zen3 at 44/64 loads & stores, and Intel’s Sunny Cove at 128/72.
The L1 TLB has been doubled from 128 pages to 256 pages, and the L2 TLB goes up from 2048 pages to 3072 pages.
A13 had 128KB L1 Instruction cache,A14 had 192KB L1 Instruction cache,比ARM大3倍。 L2 side of things, Apple has been employing an 8MB structure that’s shared between their two big cores.this generation the A14 saw the L2 of the big cores make a regression in terms of access latency, going back from 14 cycles to 16 cycles, reverting the improvements that had been made with the A13.

参考链接
最后
以上就是优美早晨最近收集整理的关于Apple MacBook -- A14Replacing x86 - The next big stepApple’s Humongous CPU Microarchitecture的全部内容,更多相关Apple内容请搜索靠谱客的其他文章。








发表评论 取消回复