1:hadoop 不过是一种框架,一种编程模型!!通过实现他所给定的编程接口(mapper和reducer),实现一定的处理流程!你可以实现分布式处理,但是数据总是需要有地方存储和管理的,所以就有了HDFS分布式文件系统!
2:什么是分布式:我的理解就是很多机器协同完成一项工作---也就集群,集群中的机器配置可以你那么高!!!在hadoop中,完成子工作的机器叫做 data node,那么那么多子工作该如何协调起来呢,所以就需要有一台机器充当指挥官的角色,在hadoop中叫做name node!----现在比如有很多很多的data node,,那总不可能杂乱无章的随意堆放,然后我们就做了一些架子,然后把data node放在架子上,架子之间通过switch通信!我们把架子叫做rack(机架),机架之间通信消耗带宽!!!data node 和 name node 之间通过一种叫心跳检测的东西进行通信!
3:在实现map 和reduce的时候有严格的限制!!比如输入输出是以键值对的形式传递的!
4:map ---->准备数据(过滤,清洗)>>>>>>----(map根据键值对进行排序和分组)--------->>>>>> reduce ----->在准备数据上进行处理

5:代码的实现:hadoop虽然是java写成的,但是他还提供了一些其他语言的编程接口,比如c++,python,ruby等等
6:三样东西实现变成框架------1 map函数 2 reduce函数 3 客户端调用函数
7:jobtracker 是司令官,tasktracker 是冲锋陷阵的士兵,士兵在做任务的同时还要给司令官报告任务进度,司令官用本子记录者士兵的任务完成情况,如果士兵任务不小心阵亡,司令官指派另外的士兵完成他的任务
8:每个士兵其实只是做一个巨大任务中的一小片任务(数据分片)
9:为了让士兵做的更块,尽量让任务资源归属于士兵(数据本地化)
10:士兵就地去任务,就地放任务,而不是把处理后的任务放到HDFS!!因为士兵做的任务只是临时的,以后还要处理
11:reduce的输出通常存放在HDFS以实现可靠存储,第一个副本存放在本地节点上,其他副本存放在其他机架节点中
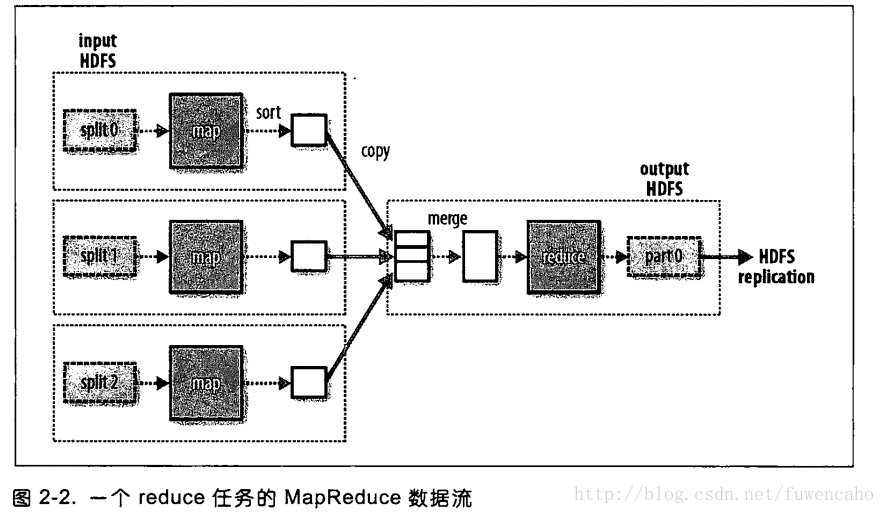
12:reduce 可以有多个,他不是由输入数据的大小来决定的,而是特别指定的,如果有多个reduce,map会对其输出进行分区,分区有用户自定义的分区函数控制,但通常使用默认的分区器通过哈希函数来分区!
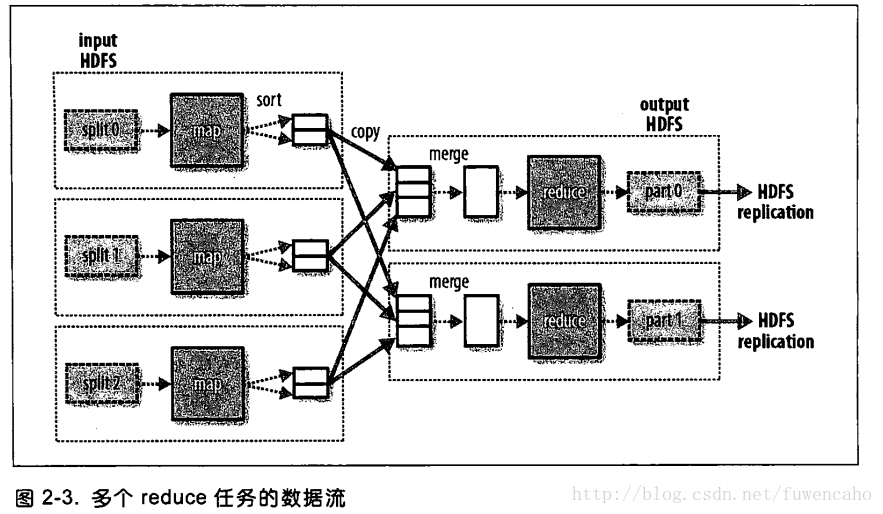
13:如上图可以看到,map和reduce任务之间的数据流称为混洗(shuffle),每个reduce的输入来自多个map的输出
14:也有可能没有任何reduce任务
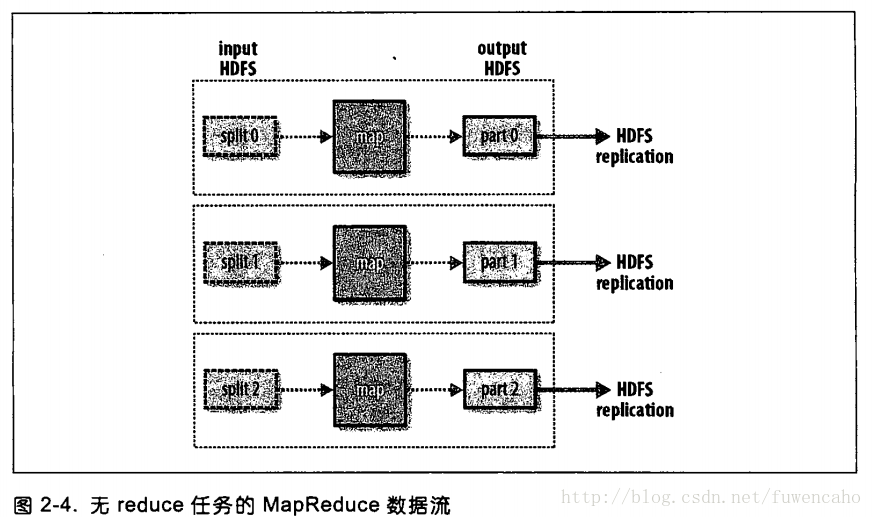
15:为减少带宽的使用,map的输出通常要经过合并(combiner)后作为reduce的输入
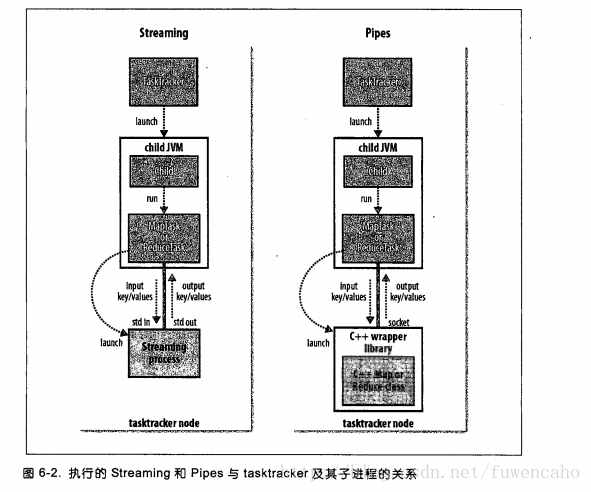
16:hadoop streaming 使用UNIX标准流作为hadoop和应用程序之间的接口,所以可以用任何编程语言通过标准输入输出来写mapreduce程序
17:分布式文件系统,该系统架构与网络之上,容错,当一台机器无法完全存储数据是,分布式发挥效用!!
18:HDFS以流式数据访问模式来存储超大文件
19:name node 将文件系统的元数据存储在内存中
20:磁盘块(512KB)----->文件系统块(64MB)----->
21:块只是存储数据的一部分----而文件的元数据,如权限信息,并不需要与块一同存储,这样一来,其他系统就可以单独的管理这些原数据!
22;name node(管理者) ,一个,管理文件系统的命令空间,维护文件系统树以及整棵树内的文件和目录,这些信息永久保留在本地磁盘文件上一两个文件的形式:命令空间镜像文件以及编辑日志文件!--name node 也记录着每个文件中各个块所在的数据节点信息,但是=他并不永久保存块的位置信息,因为这些信息会在系统启动时由数据节点重建
23:data node --工作者--多个
24:client代表用户通过与datanode 和namenode交互来访问整个文件系统,client提供了一个类似于posix的文件系统接口,编程时无需知道datanode与namenode就可以实现其功能
25:没有namenode,文件系统无法使用,如果运行namenode的机器坏了,文件系统上所有的文件将会丢失,因为我们不知道如何根据datanode 的块来重建文件,因此,对namenode实现容错至关重要,两种机制实现容错,1、备份文件2、辅助namenode
26:Thrift 实现为其他非JAVA语言访问操作文件系统
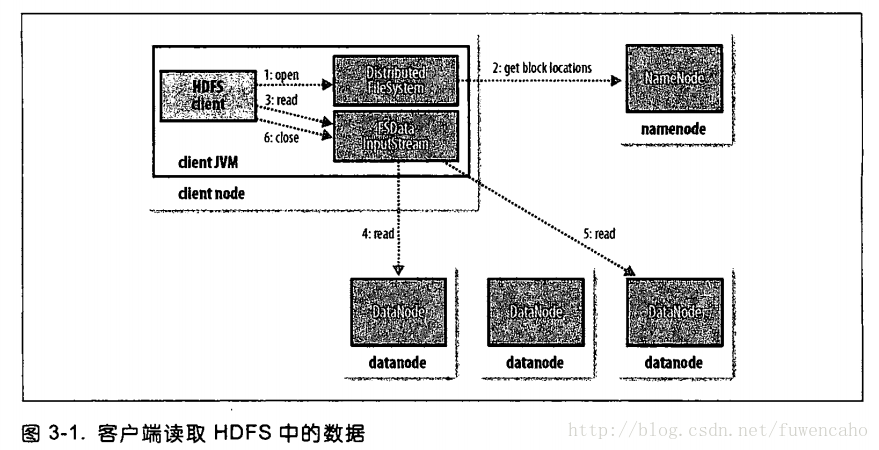
27:文件读取:客户端及与之交互的HDFS,namenode,datanode之间的数据流是什么样的,见图:
28:文件写入:见图
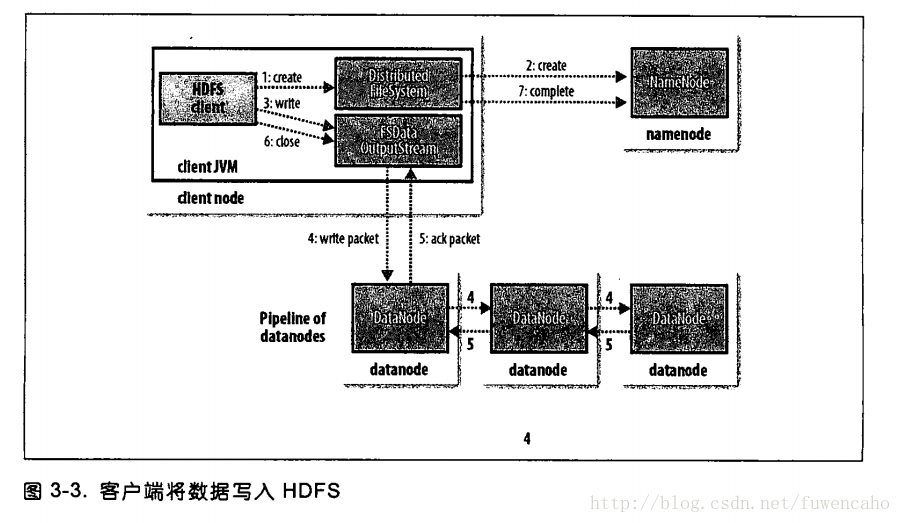
29:一致模型
30:hadoop IO --->数据完整性------->data node 计算校验和,客户端从data node 读取数据时也计算校验和--->检测到错误,name node
31:压缩与分片---->输入压缩,输出压缩
32:序列化与反序列化
33:基于文件的数据结构-----》sequence file -----》map file
34:mapreduce 的工作机制
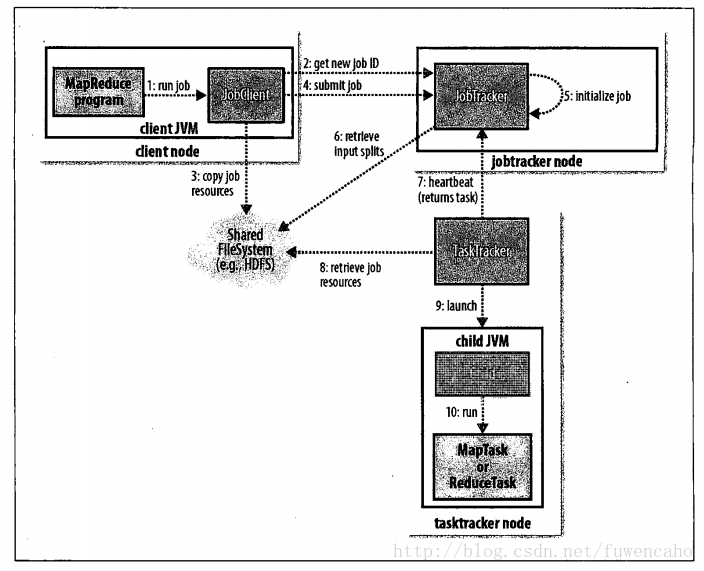
作业初始化-->任务的分配--->任务的执行---->进度和状态的更新--->作业的完成------>作业的调度
35:map,shuffle 和排序
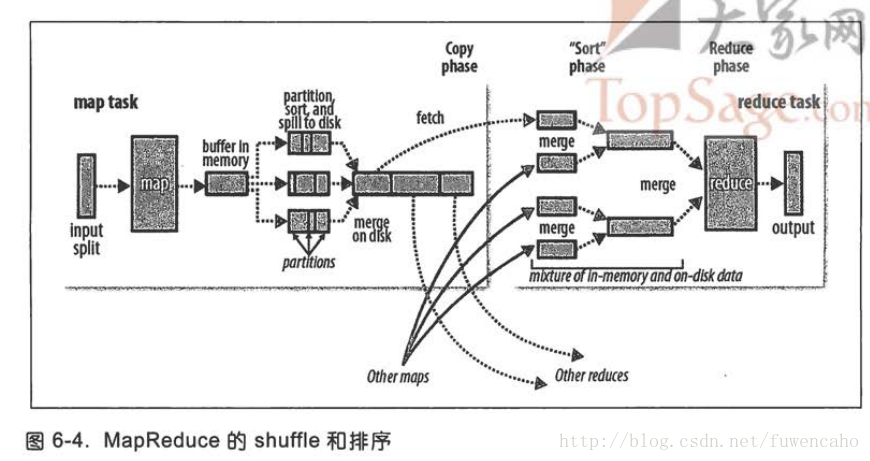
map输出--------缓冲------排序----【combiner】------触发写入磁盘(缓冲)-----reduce任务的复制阶段
36:任务的执行---推测执行,任务JVM重用,任务执行环境,streaming环境变量,任务附属文件,
最后
以上就是健壮爆米花最近收集整理的关于hadoop 我的总结的全部内容,更多相关hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复