目录
一、遍历集合的三种方式
1.普通for循环
2.迭代器循环
3.增强型for循环
二、性能测试
三、原因分析
1.ArrayList
1)普通for循环
2)迭代器循环
2.LinkedList
1)普通for循环
2)迭代器循环
结论:随机读取的情况下,数组结构优于链表结构;从头遍历的情况下,普通for循环只适用于数组结构,而迭代器根据实现不同,数组结构和链表结构都选取了效率高的方式遍历,迭代器遍历两种结构的效率相差不大,都很高,增强型for循环类比迭代器。
一、遍历集合的三种方式
1.普通for循环
2.迭代器循环
3.增强型for循环
/**
* 普通for循环
*/
for (int i = 0; i < arrayList.size(); i++) {
}
/**
* 迭代器
*/
Iterator<String> iterator = arrayList.iterator();
while (iterator.hasNext()) {
}
/**
* 增强型for循环
*/
for (String string : arrayList) {
}三种方法class文件代码如下:
for(int i = 0; i < arrayList.size(); ++i) {
}
Iterator iterator = arrayList.iterator();
while(iterator.hasNext()) {
}
String var5;
for(Iterator var4 = arrayList.iterator(); var4.hasNext(); var5 = (String)var4.next()) {
}我们可以发现,其实增强型for循环实际上也是用的迭代器循环,只是它把声明这些都隐藏了
二、性能测试
public class MainClass {
public static void main(String[] args) {
List<String> arrayList = new ArrayList<>();
List<String> linkedList = new LinkedList<>();
Long addTime = System.currentTimeMillis();
for (int count = 0; count < 100000; count++) {
arrayList.add("数组" + count);
}
Long addTime2 = System.currentTimeMillis();
for (int count = 0; count < 100000; count++) {
linkedList.add("链表" + count);
}
Long addTime3 = System.currentTimeMillis();
test(arrayList);
//test(linkedList);
System.out.println("数组添加耗时:" + (addTime2 - addTime));
System.out.println("链表添加耗时:" + (addTime3 - addTime2));
//arrayList.iterator();
//linkedList.iterator();
//arrayList.add("");
//linkedList.add("");
//arrayList.remove(0);
//linkedList.remove(0);
}
public static void test(List<String> list) {
Long time1 = System.currentTimeMillis();
/**
* 普通for循环
*/
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
Long time2 = System.currentTimeMillis();
/**
* 迭代器
*/
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
Long time3 = System.currentTimeMillis();
/**
* 增强型for循环
*/
for (String string : list) {
System.out.println(string);
}
Long time4 = System.currentTimeMillis();
String type = list instanceof ArrayList ? "数组" : "链表";
System.out.println(type + "普通for循环耗时:" + (time2 - time1));
System.out.println(type + "迭代器循环耗时:" + (time3 - time2));
System.out.println(type + "增强型for循环耗时:" + (time4 - time3));
}测试结果如下:
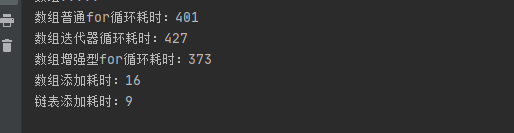
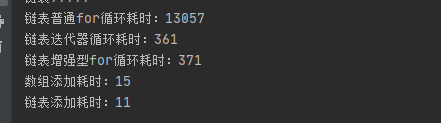
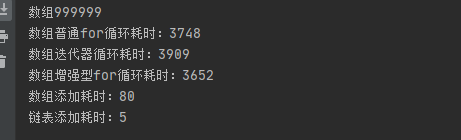
总结:对于数组结构,三种循环方式在10W数据甚至提高到100W下区别不明显,而链表结构,三种循环方式,普通for循环效率远远低于后两种;而添加数据而言,随着数据量的增大,数组结构效率远远低于链表结构
三、原因分析
数组数据结构:连续的内存空间,每个节点保存数据,不保存前后节点信息,保存了头节点的内存地址信息
链表数据结构:逻辑连续、物理不一定连续的内存空间,每个节点除了保存节点数据,还保存前后节点的指针信息
对于添加删除操作而言,数组结构效率远远低于链表结构,是因为数组每操作一次,都会移动操作数据下标后续的数据,比如删除了第五个节点,为了保持数组数据内存上的连续性,后续的第六第七等节点就会向前移动一位,以前的第六变成了第五,第七变成了第六,以此类推,并且数组在添加中还会进行扩容,这些也会消耗性能;而链表只需要修改操作节点前后节点的指针,删除了第五个节点,只需要把第四个节点的next指针由原来指向第五个节点改成指向原来的第六个节点,原来第六个节点的prev指针由以前指向第五个节点改成指向第四个节点,仅仅只需要修改三个节点的数据,也能维持数据的连续有序。
下面分析两种数据结构循环的流程(源码为java中的arraylist和linkedlist)
在分析之前,先解释一下array[i](数组结构的get(i)就是调用array[i])这个方法
在数组结构中,因为保存了头结点的内存地址,并且数组数据在内存中是连续的地址,所以计算某一个节点的内存地址就很容易:头结点的内存地址+头结点内存地址*数据下标,得到的内存地址就是对应下标数据的内存地址,时间复杂度为O(1)
例:头结点内存地址为1,那么第五个节点的内存地址就是1 + 1*4 = 5;
在链表结构中,因为内存地址的不连续性,所以要找到某一个节点的位置,必须从头或者从尾遍历,在java中,链表会根据下标的大小,决定要么从头遍历,要么从尾遍历,时间复杂度为O(n)
1.ArrayList
1)普通for循环
因为普通for循环是通过下标array[i]来获取数据,那么数组结构的get(i)只需要计算一次就能找到目标数据,所以能够最快速的返回目标数据
2)迭代器循环
先看一下ArrayList迭代器实现源代码:
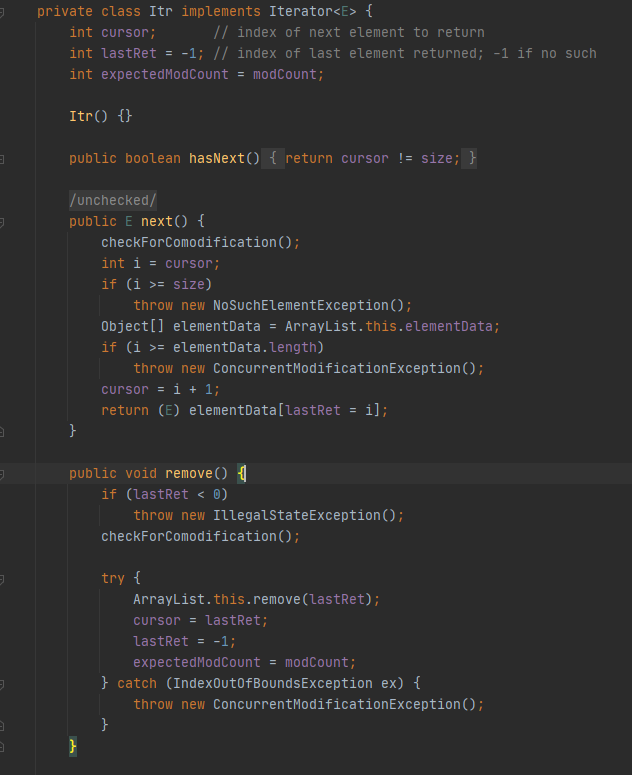
截图里面的Itr是ArrayList的内部类,调用arrayList.iterator()会new一个该对象,如下:
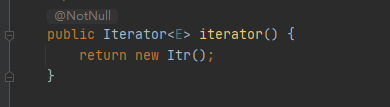
在Itr类中,cursor为游标,指向下一个元素下标,modCount是ArrayList的成员变量,记录数组的被操作次数,比如add()和remove()方法都会导致该变量+1,这个变量也是我们用迭代器遍历数组,操作数组之后会报错的原因
来看迭代器遍历中,先判断iterator.hasNext(),方法源码如下:

只要cursor不等于数组大小返回true,因为cursor初始值为0,所以正常情况下该值不会大于size
之后是获取目标数据iterator.next(),方法源码如下:
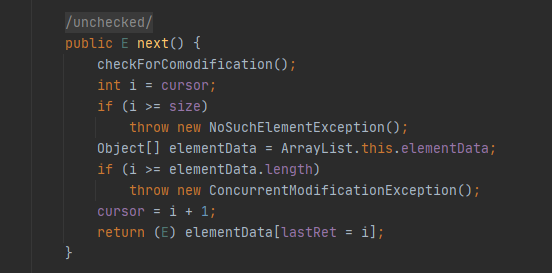
进入方法,第一部先检查修改次数checkForComodification(),源码如下:
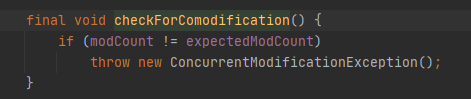
因为在初始化内部类时,Itr的成员变量被赋值为了modCount的值,而modCount的值表示该数组被操作了几次,add()和remove()都会是这个值+1,所以expectedModCount成员变量的意义就是记录数组在遍历之前被操作的次数
如果在遍历过程中,对数组进行了add()或者remove()等会导致modCount改变的方法,那么就会报错,这个判断的意义就在于,使用迭代器遍历时,不允许外部操作数组,而内部类Itr其实也提供了一个remove()方法,这个方法在操作数组的时候会更新expectedModCount和modCount的值,所以如果需要在遍历时操作数组,可以调用Itr的内部方法
继续往下看,通过对游标数值的合法判断,最后返回数组elementData[i]的值,上面也讲到,数组获取某个下标的数据,只需要进行一次计算就可以找到,所以这个方法是可以很快返回目标数据的
数组结构的遍历,总结下来就是,普通for循环和迭代器循环,最后都是通过array[i]来获取目标数据,时间复杂度都是O(1)所以相差不大,差别就在迭代器执行了其他的判断逻辑等
2.LinkedList
1)普通for循环
之前说到,链表结构因为内存地址的不连续性,所以要找某一个下标的数据,需要从头或者从尾遍历,所以每次通过linkedList[i]来查找,都会遍历链表,遍历次数完全取决于下标的大小,如果下标靠近中间,就会遍历最多次,linkdedList.get(i)源码如下:
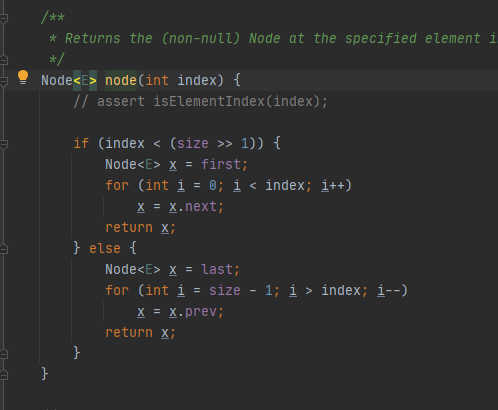
将index与size的一半做比较,靠近前半部分就从头遍历,靠近后半部分就从尾遍历
2)迭代器循环
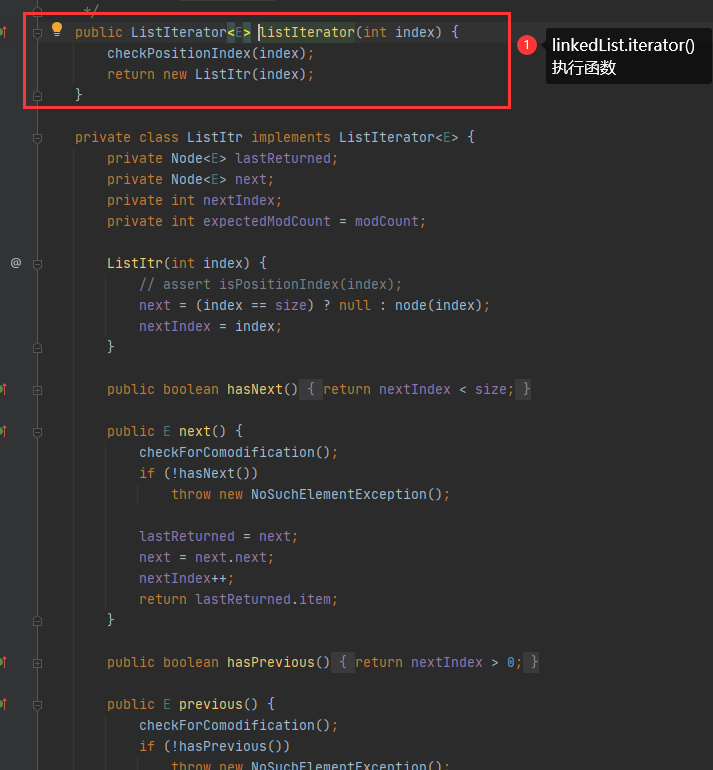
重复的地方就不讲述了,直接从next()方法分析:
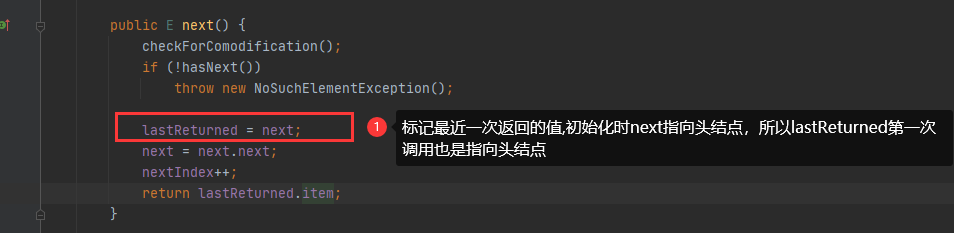
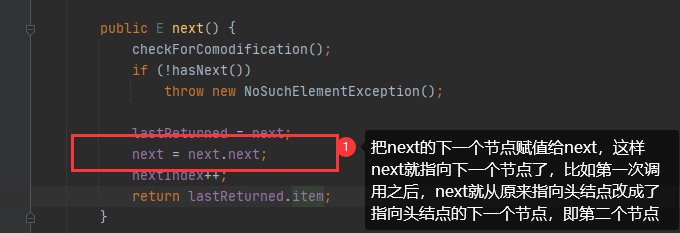
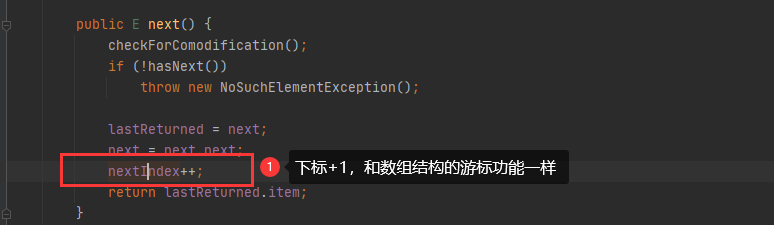
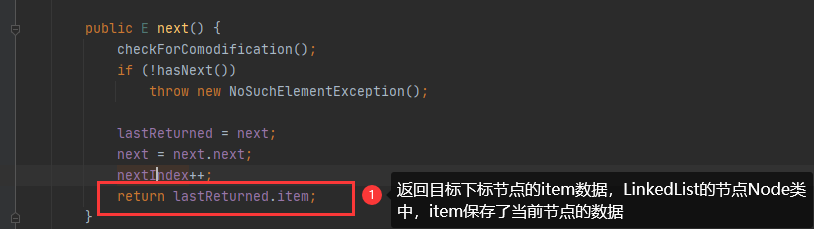
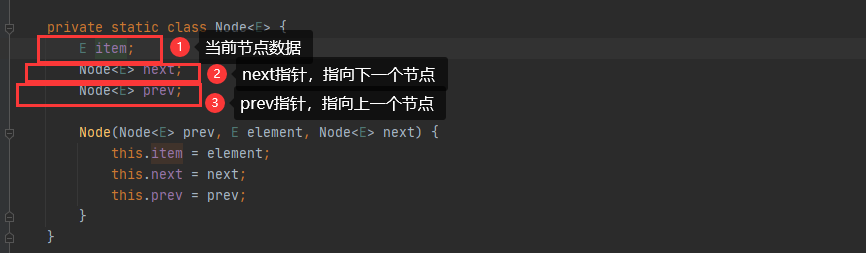
总结,迭代器遍历链表结构,因为链表的next和prev指针,所以查找目标数据还是很简单快速,这也是为什么迭代器遍历链表速度也高的原因,而且其实数组的迭代器和链表迭代器实现方式是不一样,选取了查询效率高的方式
综上所述,遍历集合,迭代器是可以根据数据结构选取效率高的方式遍历,而普通for循环只能用于数组结构,因为是通过下标访问数据,而且,迭代器只适合从头遍历,如果是随机读取遍历,数组结构还是要比链表结构快
最后
以上就是会撒娇大地最近收集整理的关于Java三种for循环的性能分析一、遍历集合的三种方式二、性能测试三、原因分析的全部内容,更多相关Java三种for循环内容请搜索靠谱客的其他文章。







![java迭代器底层用for_[转载]Java迭代器(iterator详解以及和for循环的区别)](https://www.shuijiaxian.com/files_image/reation/bcimg23.png)
发表评论 取消回复