一、前言
本文是文本分类的第二篇,来介绍一下微软在2016年发表的论文《Hierarchical Attention Networks for Document Classification》中提出的文本分类模型 HAN(Hierarchy Attention Network)。同时也附上基于 Keras 的模型实现,代码解读,以及通过实验来测试 HAN 的性能。
这里是文本分类系列:
文本分类模型第一弹:关于Fasttext,看这一篇就够了
文本分类模型第二弹:HAN(Hierarchy Attention Network)
文本分类模型第三弹:BoW(Bag of Words) + TF-IDF + LightGBM
二、相关论文
说到模型结构和原理,我们还是先来读读原论文吧:
(1)Document Modeling with Gated Recurrent Neural Network for Sentiment Classification
(2)Hierarchical Attention Networks for Document Classification
说到 HAN,不可不读的论文有两篇。首先第一篇论文《Document Modeling with Gated Recurrent Neural Network for Sentiment Classification》是哈工大在2015年发表的,而第二篇论文《Hierarchical Attention Networks for Document Classification》则是在第一篇的基础之上,加入了 Attention 机制,因此这里就依次对两篇论文进行解读。
1、Document Modeling with Gated Recurrent Neural Network for Sentiment Classification.
在 LDA 主题模型的思想中,一篇文章首先是由单词组成了主题,再由不同的主题来组成文章。而这篇论文的思想也非常相似,认为一篇文章首先由单词组成句子,再由句子组成文章。如此一来我们要想对一篇文章进行分类,就需要分两步来进行,首先从单词层面分析每个句子的语义。总结出每个句子的语义后,再将句子综合起来表征整篇文章的语义,并对其进行分类。这个思想很好的体现在本篇论文所提出的模型结构上,我们就po出论文中提出的模型来看看:
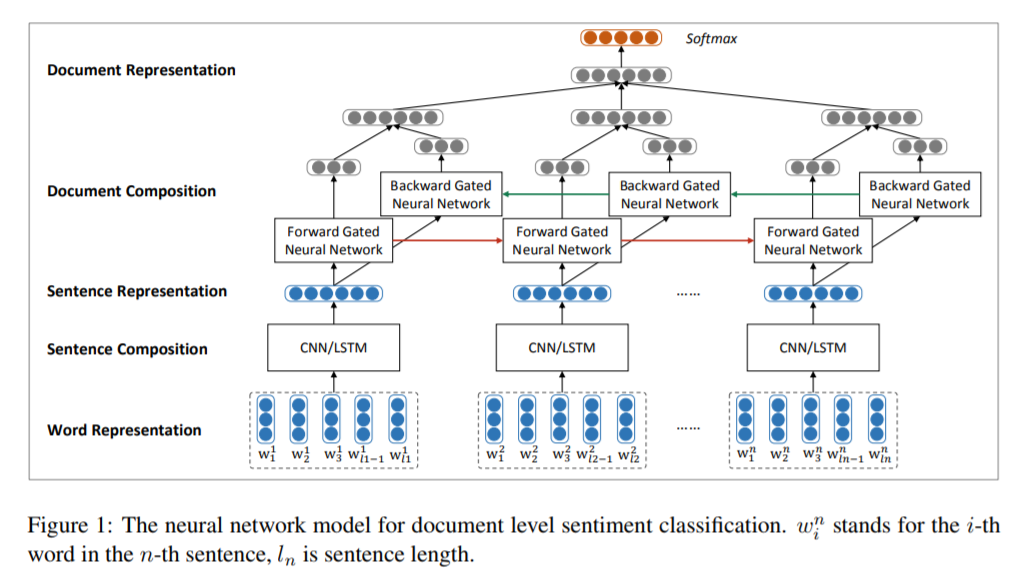
从下往上来解读模型,首先每个虚线框中为一句话所包含的单词,蓝色的 vector 为每个单词的词向量,也就是词的表示(Word Representation)。通过 CNN/LSTM 来提取一句话中包含所有单词的语义特征,形成句子的特征向量(Sentence Representation)。再经过一个 Bi-Directional Gated Neural Network(LSTM/GRU) 以及一些列的操作,最终生成整个文章的特征向量(Document Representation)。最后通过Softmax来进行文章分类。
当使用 CNN 作为句子级别的特征抽取器时,其结构形如 TextCNN(TextCNN我们下一弹再来说),使用了大小分别为,
,
的卷积窗口来对句子进行卷积,卷积窗口的宽度设置为1,2,3, 此举是考虑到对文本中的 uni-gram,bi-gram,tri-gram 的特征进行提取。随后对提取后的特征分别进行 average pooling,并使用 Tanh 函数进行激活。最后求出得到的三个 vector 的平均值,得到句子级别的特征向量表示,其整个结构如下图所示:
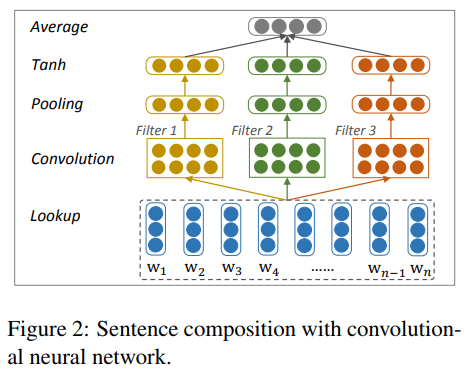
论文中并没有给出使用 LSTM 作为句子级别特征抽取器的结构,但其过程应该与文章层面特征抽取的方式如出一辙,下面来看看文章层面的特征抽取是如何进行的。
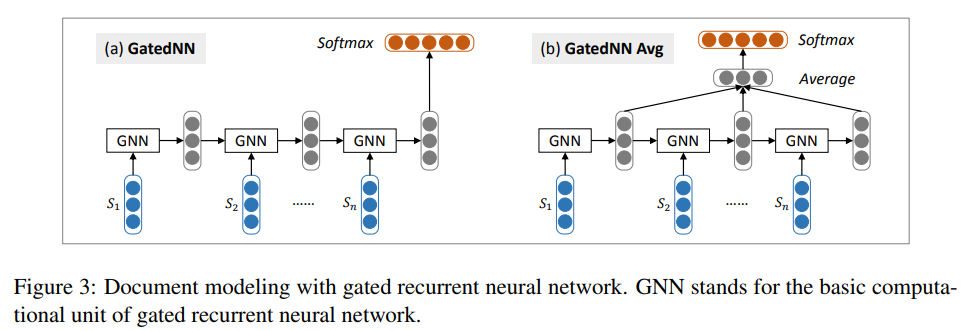
篇章级别的特征抽取器结构如上图所示。论文中介绍了两种方法,一种是使用 GNN(LSTM/GRU)最后一个时刻的隐藏层输出向量作为整个文章的特征表示,另一种则是取 GNN 每一个时刻的隐藏层输出,并对其求平均,用求平均后的向量作为整个文章的特征表示。两种方法最后都通过 Softmax 来进行最终的分类工作。
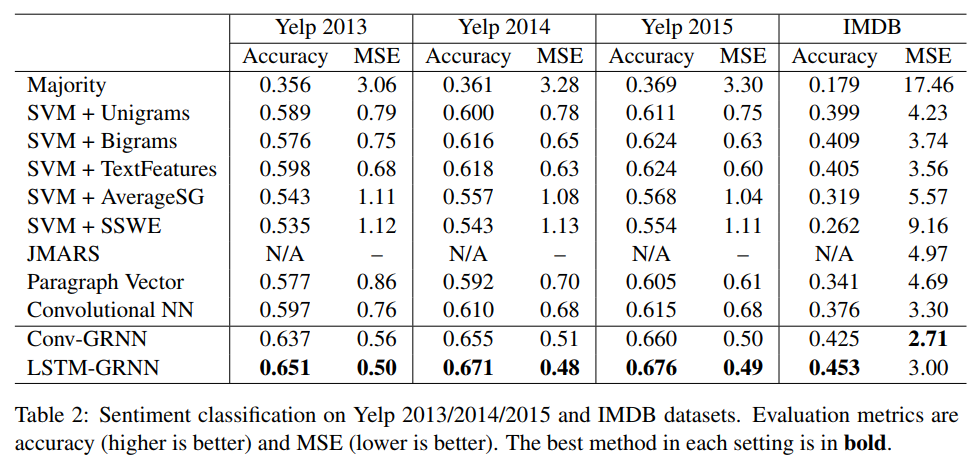
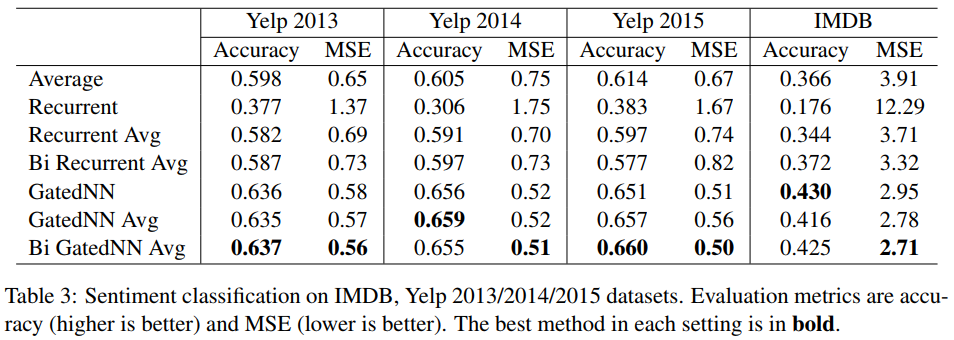
最后通过实验数据,得出了相较于 TextCNN,使用 LSTM 抽取句子级别的语义特征,搭配使用 Bi-GNN(Bi-LSTM / Bi-GRU)可以得到更好的效果。
2、Hierarchical Attention Networks for Document Classification.
第二篇论文,《Hierarchical Attention Networks for Document Classification》提出我们今天要说的模型 HAN,别看论文的题目对 GNN 只字不提,但它相较于第一篇论文而言,其实使用了向同的特征提取结构,区别就在于加入了多层注意力机制(Hierarchical Attention)。
首先我们还是来看看模型的结构吧:
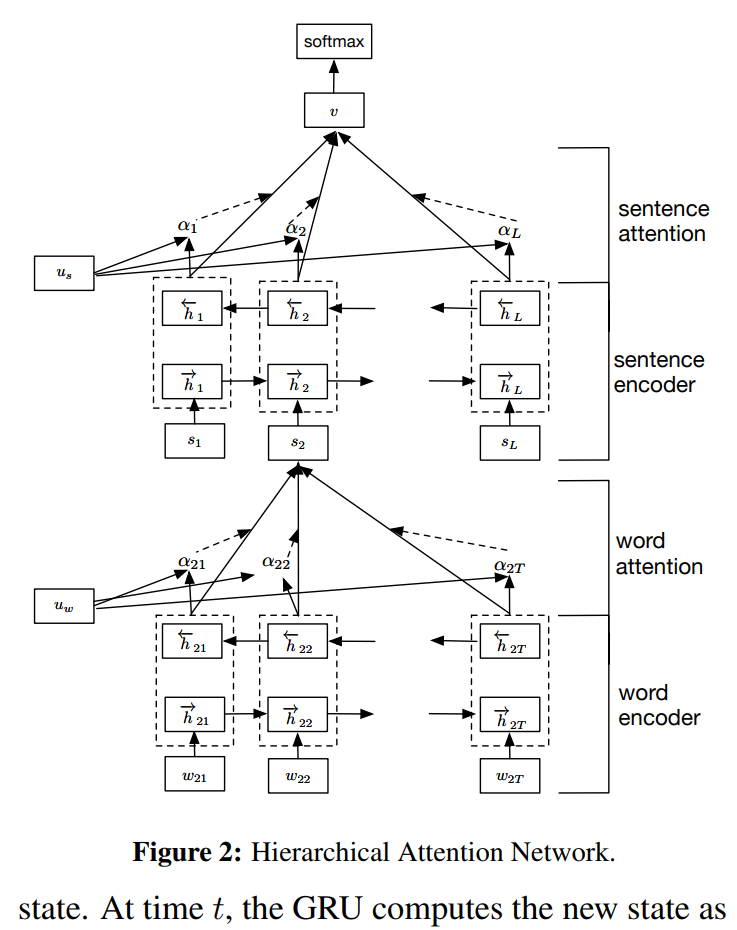
模型的结构就如上图所示,分为上下两个 block,两个 block 的结构完全一致,都是由 Bi-GNN 组成特征抽取器,同时添加了注意力机制。下层的 block 做句子级别的特征抽取,抽取后的特征作为上层 block 每一时刻的输入,再由上层 block 进行篇章级别的特征抽取,最后还是使用 Softmax 做最后的分类。
GNN 层面,无论是 GRU 还是 LSTM 都已经是老生常谈的结构,这里就不做介绍也不po公式了。Attention 机制作为整个模型的精髓所在,我们下一节用单独的一个篇章来说,这里先来看论文中的实验环节吧。
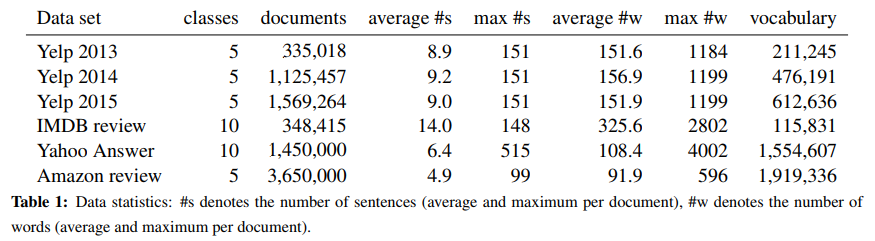
这张表是论文使用的数据集,当我看到这张语料统计表时,心里当时是凉凉了一半的,最小的数据集也包含了 33w 篇文章。在我们实际使用中确实难以获取到如此大的数据集来让模型进行发挥,不过后续在我自己的实验中,发现 HAN 在面对小数据集时也能有不错的表现,其性能是超过了 Fasttext 和 TextCNN 的。
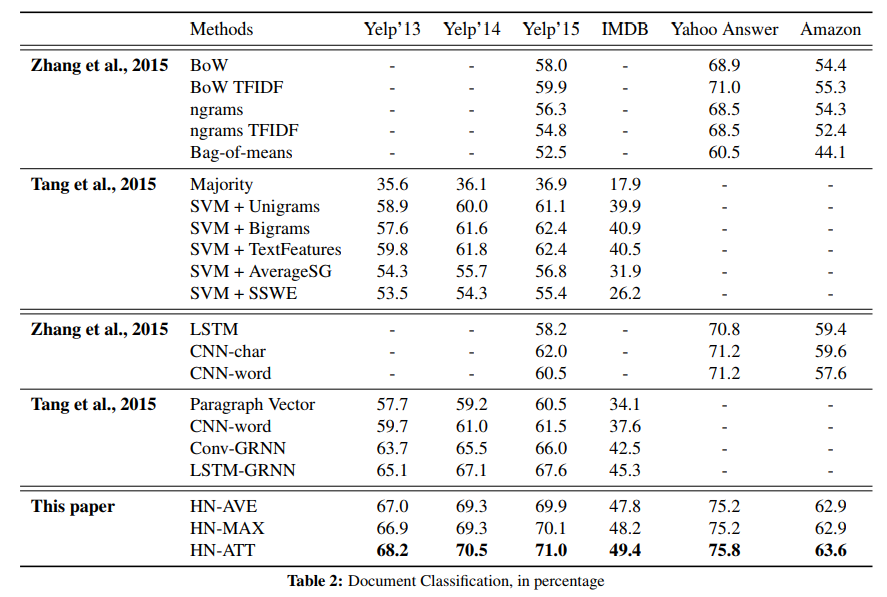
接下来是实验结果,表中 HN-AVE 与 HN-MAX 为将各层的特征向量生成方式由 Attention 加权求和转变为了直接做 Average Pooling 和 Max Pooling。但最终结果表明,Attention 的效果还是要优点于前两者的,这里也对比了我们前面提到的第一篇文章,由于在句子级别的特征抽取上也是用了 Bi-GNN 的结构,所以当使用 HN-AVE 与 HN-MAX 时性能也是超越了前者。
三、Attention
HAN 的模型结构其实比较简单,上一部分的论文解读其实已经将模型介绍的很清楚了,这一部分就主要来说一下 HAN 的精髓部分—— Attention 是如何进行计算的。
由于单词级别 Attention 和句子级别 Attention 的机制完全一样,我们就只来说说单词级别的实现原理,接下来还是要放上这张模型结构图:
每一层的注意力机制对该层中,每一时刻的 Bi-GNN 的隐层输出进行注意力权重的计算和权重的归一化。注意力采用了Scaled Dot-Product Attention 的方法来计算,公式如下所示:

首先每一时刻的 GNN 的输出向量 需要进行一次非线性变换得到
。为了与每一个单词和句子的特征向量区别开来,我们这里将
,
称为 “全局句子特征向量” 与 “全局单词特征向量”,这两个向量维度与 Bi-GNN 的隐藏层输出向量相等,在训练开始前随机初始化,并在训练中更新。论文中并没由明确的描述
与
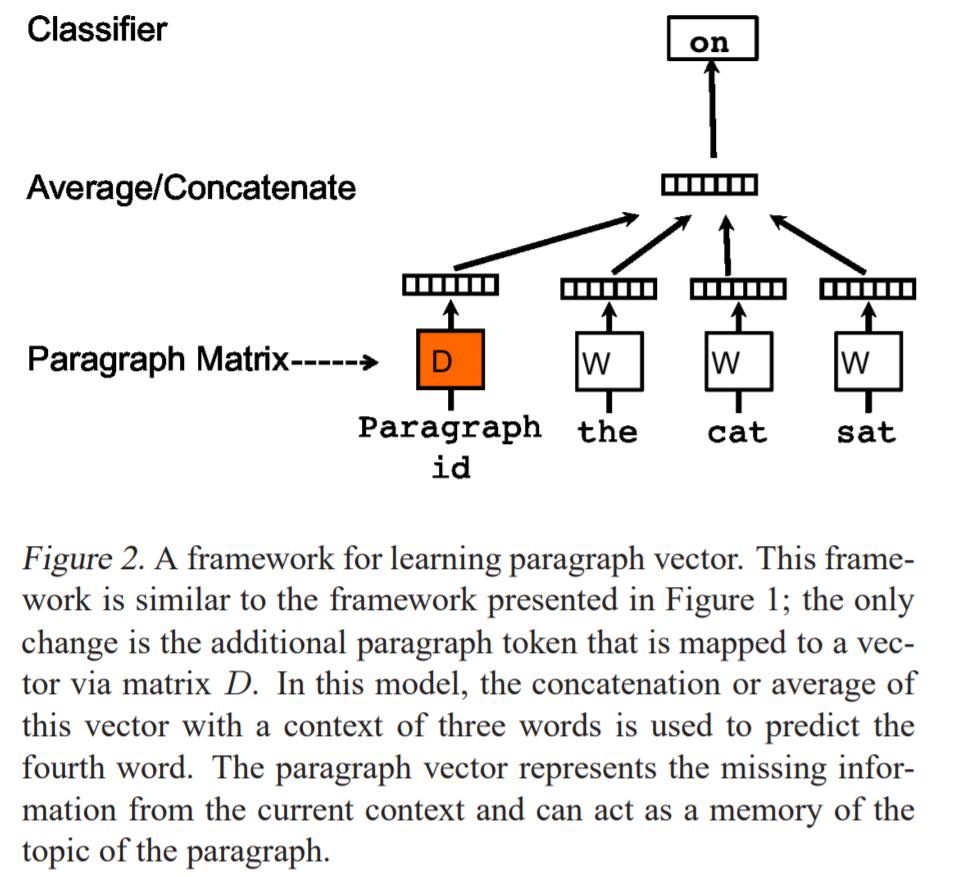
的意义,只是用 content vector 与 word level context vector 来表示。笔者认为这两个向量是语料中单词级别的特征与句子级别的特征的浓缩,与 Doc2Vec 中的 Paragraph Vector 是同样的思想,有异曲同工之妙。Doc2Vec 见下图,其中的 Paragraph Vector 也是随机初始化,并跟随词向量一同训练,最终Paragraph Vector 就代表了整个文章的特征。
四、代码
这部分主要来介绍一下 HAN 的实现,使用的是 Keras 框架,Backend 为 TensorFlow-gpu-1.14.0 版本。博客上主要介绍一下模型部分的代码,完整代码我会放到 Git 上,供大家参考。
首先是 Attention 的部分:
# Attentnion Layer
from keras.engine.topology import Layer
from keras import initializers as initializers, regularizers, constraints
from keras import backend as K
def dot_product(x, kernel):
"""
Wrapper for dot product operation, in order to be compatible with both
Theano and Tensorflow
Args:
x (): input
kernel (): weights
Returns:
"""
if K.backend() == 'tensorflow':
return K.squeeze(K.dot(x, K.expand_dims(kernel)), axis=-1)
else:
return K.dot(x, kernel)
class AttentionWithContext(Layer):
"""
Attention operation, with a context/query vector, for temporal data.
Supports Masking.
Follows the work of Yang et al. [https://www.cs.cmu.edu/~diyiy/docs/naacl16.pdf]
"Hierarchical Attention Networks for Document Classification"
by using a context vector to assist the attention
# Input shape
3D tensor with shape: `(samples, steps, features)`.
# Output shape
2D tensor with shape: `(samples, features)`.
How to use:
Just put it on top of an RNN Layer (GRU/LSTM/SimpleRNN) with return_sequences=True.
The dimensions are inferred based on the output shape of the RNN.
Note: The layer has been tested with Keras 2.0.6
Example:
model.add(LSTM(64, return_sequences=True))
model.add(AttentionWithContext())
# next add a Dense layer (for classification/regression) or whatever...
"""
def __init__(self,
W_regularizer=None, u_regularizer=None, b_regularizer=None,
W_constraint=None, u_constraint=None, b_constraint=None,
bias=True, **kwargs):
self.supports_masking = True
self.init = initializers.get('glorot_uniform')
self.W_regularizer = regularizers.get(W_regularizer)
self.u_regularizer = regularizers.get(u_regularizer)
self.b_regularizer = regularizers.get(b_regularizer)
self.W_constraint = constraints.get(W_constraint)
self.u_constraint = constraints.get(u_constraint)
self.b_constraint = constraints.get(b_constraint)
self.bias = bias
super(AttentionWithContext, self).__init__(**kwargs)
def build(self, input_shape):
assert len(input_shape) == 3
self.W = self.add_weight((input_shape[-1], input_shape[-1],),
initializer=self.init,
name='{}_W'.format(self.name),
regularizer=self.W_regularizer,
constraint=self.W_constraint)
if self.bias:
self.b = self.add_weight((input_shape[-1],),
initializer='zero',
name='{}_b'.format(self.name),
regularizer=self.b_regularizer,
constraint=self.b_constraint)
self.u = self.add_weight((input_shape[-1],),
initializer=self.init,
name='{}_u'.format(self.name),
regularizer=self.u_regularizer,
constraint=self.u_constraint)
super(AttentionWithContext, self).build(input_shape)
def compute_mask(self, input, input_mask=None):
# do not pass the mask to the next layers
return None
def call(self, x, mask=None):
uit = dot_product(x, self.W)
if self.bias:
uit += self.b
uit = K.tanh(uit)
ait = dot_product(uit, self.u)
a = K.exp(ait)
# apply mask after the exp. will be re-normalized next
if mask is not None:
# Cast the mask to floatX to avoid float64 upcasting in theano
a *= K.cast(mask, K.floatx())
# in some cases especially in the early stages of training the sum may be almost zero
# and this results in NaN's. A workaround is to add a very small positive number ε to the sum.
# a /= K.cast(K.sum(a, axis=1, keepdims=True), K.floatx())
a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx())
a = K.expand_dims(a)
weighted_input = x * a
return K.sum(weighted_input, axis=1)
def compute_output_shape(self, input_shape):
return input_shape[0], input_shape[-1]Attention 的部分使用 Keras 中的自定义层实现,在 build 中初始化权重,偏置,以及全局特征向量 ,
。call 中主要实现了 Attention 的计算过程,具体的计算方法与论文中的公式一致。
接下来是 HAN 模型的构建:
from keras import Input, Model
from keras.layers import Embedding, Dense, Bidirectional, CuDNNLSTM, TimeDistributed, CuDNNGRU
class HAN(object):
def __init__(self, maxlen_sentence, maxlen_word, max_features, embedding_dims, embedding_matrix, hidden_size, l2_reg, class_num=10, last_activation='softmax'):
self.maxlen_sentence = maxlen_sentence
self.maxlen_word = maxlen_word
self.max_features = max_features
self.embedding_dims = embedding_dims
self.class_num = class_num
self.last_activation = last_activation
self.embedding_matrix = embedding_matrix
self.hidden_size = hidden_size
self.l2_reg = l2_reg
def get_model(self):
# Word part
input_word = Input(shape=(self.maxlen_word,))
embedder = Embedding(self.max_features + 1, self.embedding_dims, input_length=self.maxlen_word, weights=[self.embedding_matrix], trainable=True)
embedding_vector = embedder(input_word)
x_word = Bidirectional(CuDNNGRU(self.hidden_size, return_sequences=True, kernel_regularizer=self.l2_reg))(embedding_vector) # LSTM or GRU
x_word = AttentionWithContext()(x_word)
model_word = Model(input_word, x_word)
# Sentence part
input_sen = Input(shape=(self.maxlen_sentence, self.maxlen_word))
x_sentence = TimeDistributed(model_word)(input_sen)
x_sentence = Bidirectional(CuDNNGRU(self.hidden_size, return_sequences=True, kernel_regularizer=self.l2_reg))(x_sentence) # LSTM or GRU
x_sentence = AttentionWithContext()(x_sentence)
output = Dense(self.class_num, activation=self.last_activation)(x_sentence)
model_sentence = Model(inputs=input_sen, outputs=output)
return model_sentence 模型部分构建了两个 Block,分别为 Word Part 和 Sentence Part,每一部分单独构建为一个 model,这里由于我的数据集较少,所以 Bi-GNN 部分采用了参数量较少的 Bi-GRU 来构建。Embedding 层使用了预训练好的 Word2Vec 词向量,并在训练中进行 Fine-tuning。
接下来是数据处理的部分:
def cut_doc_2_sentences(doc, sentence_flags=None, skip_limit=8, long_cut_limit=130,
all_flags=['.', '!', '?', '~', '。', '!', '?', '~', 'n', ' '],
strip_flags=None):
if strip_flags is None:
strip_flags = [' ']
if sentence_flags is None:
sentence_flags = all_flags
last_flag = 0
sentence_list = []
doc_length = len(doc)
for i in range(doc_length):
cut_flags = sentence_flags
if i + 1 - last_flag > long_cut_limit:
cut_flags = all_flags
if (i <= doc_length - 2 and doc[i] in cut_flags and doc[i + 1] not in cut_flags) or i == doc_length - 1:
temp = doc[last_flag:i + 1]
chars_no_flags = [char for char in temp if char not in cut_flags]
if len(chars_no_flags) < skip_limit:
# 句子内非标点句长小于阀值 skip_limit 的并入下一个分句
continue
# 分完句以后去掉前后无用的字符
for flag in strip_flags:
temp = temp.strip(flag)
sentence_list.append(temp)
last_flag = i + 1
return sentence_list
def cut_docs(docs):
start_time = time.time()
print('start 分句...')
docs_sentence_list = [cut_doc_2_sentences(doc) for doc in docs]
print('end 分句,Total docs = {},Cost time = {}'.format(len(docs), time.time() - start_time))
start_time = time.time()
print('start 分词...')
docs_cut = [[data_clean(sentence) for sentence in sentence_list] for sentence_list in docs_sentence_list]
print('end 分词, Cost time = {}'.format(time.time() - start_time))
return docs_cut
# 根据训练集生成 vocabulary,返回 fit 后的 tokenizer
def build_vocabulary_tokenizer(docs_cut):
vocabulary = []
for doc_sentence_list in docs_cut:
for sentence_list in doc_sentence_list:
for word in sentence_list:
vocabulary.append(word)
tokenizer = keras.preprocessing.text.Tokenizer()
tokenizer.fit_on_texts([vocabulary])
return tokenizer
# 根据fit后的tokenizer,将分词分句后的doc中的词替换成index
def index_docs_func(tokenizer, docs_cut):
index_docs = []
for doc_sentence_list in docs_cut:
index_docs.append(tokenizer.texts_to_sequences(doc_sentence_list))
return index_docs
def pad_docs(index_docs, doc_max_sentence_num, sentence_max_word_num, padding_value=0):
data = []
for doc in index_docs:
doc_data = []
for sentence in doc:
# 句子 word 数补齐成 sentence_max_word_num
if len(sentence) < sentence_max_word_num:
sentence.extend([padding_value] * (sentence_max_word_num - len(sentence)))
doc_data.append(sentence[:sentence_max_word_num])
# 每篇文章句子数补够 doc_max_sentence_num
if len(doc_data) < doc_max_sentence_num:
doc_data.extend([[padding_value] * sentence_max_word_num] * (doc_max_sentence_num - len(doc_data)))
data.append(doc_data[:doc_max_sentence_num])
data = np.array(data)
return data
def dump_data(data, file):
with open(file, 'wb') as f:
pickle.dump(data, f)
def load_data(file):
with open(file, 'rb') as f:
data = pickle.load(f)
return data
def pre_process_train_docs(docs, doc_max_sentence_num, sentence_max_word_num):
docs_cut = cut_docs(docs) # 分词分句
start_time = time.time()
print('start build_vocabulary_tokenizer...')
tokenizer = build_vocabulary_tokenizer(docs_cut)
print('end build_vocabulary_tokenizer, Cost time = {}'.format(time.time() - start_time))
index_docs = index_docs_func(tokenizer, docs_cut)
data = pad_docs(index_docs, doc_max_sentence_num, sentence_max_word_num)
vocabulary_size = len(tokenizer.word_index.values()) + 1
return data, vocabulary_size, tokenizer在数据处理方面, HAN 模型需要提前设置好每一篇文章中的句子数量以及每一个句子中的单词数量,对超过长度的进行截取,对长度不足的进行 Padding 补齐。我们使用 maxlen_word 和 maxlen_sentence 分别表示 “每个句子中包含单词的最大数量” 和 “每篇文章中包含句子的最大数量” ,处理完成后传入模型进行的训练的数据的 shape 应为:
[ batch_size, maxlen_sentence, maxlen_word ]。
由于要同时对句子和单词进行 Padding 的操作,所以 maxlen_word 及 maxlen_sentence 的值的选取对于数据有效信息的保留就显得至关重要了。
这部分的代码用来统计数据集中的一些语料指标,如:文章中单词数量分布,文章中句子数量分布,句子中单词数量分布。可以根据这些语料的统计指标,合理的选取 maxlen_sentence 和 maxlen_word 的值,从而将 Padding 对文本信息的损失降到最小。
# 标签分布
dict_list = {}
for label in data_df["label"]:
if label in dict_list:dict_list[label] += 1
else:dict_list[label] = 1
print(dict_list)# 查看 doc 字数分布
doc_lens = np.array([len(data_clean(doc)) for doc in all_content_list])
n, bins, patches = plt.hist(x=doc_lens, bins='auto', color='#0504aa', alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
doc_lens.mean(), doc_lens.max(), doc_lens.min(), np.median(doc_lens)# 查看 doc 中句子数量分布
docs_sentence_list = [cut_doc_2_sentences(doc, ['.', '!', '?', ';', '。', '!', '?', ';'], 10, 80) for doc in all_content_list]
sentence_lens = np.array([len(sentence) for sentence in docs_sentence_list])
n, bins, patches = plt.hist(x=sentence_lens, bins='auto', color='#0504aa', alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
np.mean(sentence_lens), np.min(sentence_lens), np.max(sentence_lens), np.median(sentence_lens)# 查看句子长度分布
sentence_lens = [[len(seq) for seq in sentence] for sentence in docs_sentence_list]
seq_lens = []
for i in sentence_lens:
seq_lens.extend(i)
n, bins, patches = plt.hist(x=seq_lens, bins='auto', color='#0504aa',alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
np.mean(seq_lens), np.min(seq_lens), np.max(seq_lens), np.median(seq_lens)# 句子中词数分布
sentence_lens = [[len(jieba.lcut(sentence)) for sentence in sentence_list] for sentence_list in docs_sentence_list[:]]
seq_lens = []
for i in sentence_lens:
seq_lens.extend(i)
n, bins, patches = plt.hist(x=seq_lens, bins='auto', color='#0504aa',alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
np.mean(seq_lens), np.min(seq_lens), np.max(seq_lens), np.median(seq_lens)五、实验
接下来就通过实验看看 HAN 模型的性能究竟如何吧。
为了对比模型性能,我们还是使用了文本分类第一弹中用到的数据集,来对 HAN 与 Fasttext 的性能做一个对比。由于 HAN模型主要针对篇章级别的长文本进行分类,而 IMDb Subjectivity Dataset V1.0 以及 Sentiment140 情感分类数据集都以短文本为主,所以我们这次主要使用 SougoCS 新闻数据集。
1.Experiment 1
实验数据:SougoCS 新闻数据集,分别取其中IT类、汽车类、商业类、体育类、娱乐类新闻各 5500 条,训练集与测试集比例为 9:1。
模型参数:dim=300;hidden size=64;batch size=128;epoch=10;maxlen_word=30;maxlen_sentence=45;
实验结果:
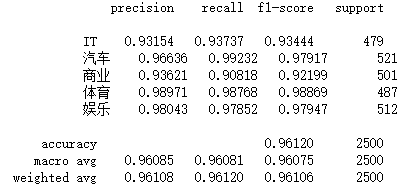
HAN 在样本均衡的 SouguCS 新闻数据集上,平均准确率为 0.9612,高于 Fasttext 的 0.9408。在各个子类的 F1-score 方面,HAN 均比 Fasttext 高 0.01~0.04。
2.Experiment 2
实验数据:SougoCS 新闻数据集,分别取其中IT类 5500 条、教育类 4400 条、汽车类 5500 条、商业类 11000 条、体育类 22000 条、娱乐类 11000 条,训练集与测试集比例为 9:1。
模型参数:dim=300;hidden size=256;batch size=512;epoch=10;maxlen_word=30;maxlen_sentence=40;
实验结果:
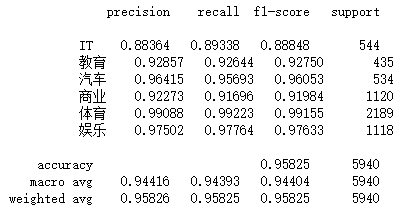
对于样本量不均衡的数据集,HAN 模型平均准确率为0.9583,与 Fasttext 相当,但在各个子类的 F1-score 方面,HAN 模型均要高于 Fasttext。
由于实验数据集中的语料均为新闻语料,语义较为单一,所以在该数据集上无法体现出 HAN 在面对包含复杂语义的长文本语料时的优势所在。
六、总结
HAN 模型针对篇章文本由单词组成句子,再由句子组成文章的特点,从句子层面到篇章层面分别建模。模型结构科学合理,并且增加了 Attention 机制,对句子中包含关键语义的单词及文章中包含关键语义的句子赋予更高的权重。总的来说,HAN 模型代表了以 GNN 结构作为特征抽取器的文本分类模型的性能巅峰。此后的2017年, Transformer 隆重登场,Multi-Head self-Attention 开始大行其道,曾经风光无限的 GNN 结构也就从此风光不再。
对于 HAN 的使用,本人觉得还是要根据语料的数量以及类型来进行模型的选择。HAN 中的 GNN 结构无法并行计算,处理训练数据耗时,并且难以训练,batch size learning rate 设置的稍有不慎就会发生梯度爆炸。而 TextCNN 和 Fasttext 训练难度低,训练速度快,所以在面对语义较为单一的短文本分类时,TextCNN 和 Fasttext 这类通过提取关键词信息作为主要特征的模型显然是更好的选择。但当面对语义较为复杂的长文本分类、篇章级分类、复杂情感分类时,HAN 则能通过分析关键词的上下语境,运用 Attention 机制为不同语境下的关键词赋予不同的权重,从而更好的完成分类任务。
七、参考文献及资源链接
1.参考文献
1.https://www.aclweb.org/anthology/D15-1167
2.https://www.microsoft.com/en-us/research/uploads/prod/2017/06/Hierarchical-Attention-Networks-for-Document-Classification.pdf
3.https://blog.csdn.net/liuchonge/article/details/73610734
2.数据集
- SougoCS:https://download.csdn.net/download/zjrn1027/11463182
如有错误遗漏欢迎交流指正,转载请注明出处。
最后
以上就是淡定钢笔最近收集整理的关于文本分类模型第二弹:HAN(Hierarchy Attention Network)一、前言二、相关论文三、Attention四、代码五、实验六、总结七、参考文献及资源链接的全部内容,更多相关文本分类模型第二弹:HAN(Hierarchy内容请搜索靠谱客的其他文章。








发表评论 取消回复