1. 检查编译器版本
#include <iostream>
using namespace std;
int main() {
cout << __cplusplus <<endl;
#if __cplusplus >= 201103L
#error __cplusplus >= 201103L
#elif __cplusplus <= 199711L
#error __cplusplus <= 199711L
#else
#error __cplusplus
#endif
return 0;
}2. 类成员变量的Set/Get宏
#ifndef CLASS_MACRO_H
#define CLASS_MACRO_H
#define GETSETMEMBER(varType, varName, funName)
private: varType varName;
public: inline varType Get##funName(void) const {return varName;}
public: inline void Set##funName(varType var) {varName = var;}
#define GETMEMBER(varType, varName, funName)
private: varType varName;
public: inline varType Get##funName(void) const {return varName;}
#define SETMEMBER(varType, varName, funName)
private: varType varName;
public: inline void Set##funName(varType var) {varName = var;}
#endif3. 加载配置
#include <map>
#include <fstream>
#include <iostream>
#include "logger.hpp"
#include "str_functs.hpp"
using namespace std;
class Config
{
public:
Config(const char * const filePath)
{
_loadFile(filePath);
}
public:
operator bool ()
{
return !_map.empty();
}
private:
bool _loadFile(const char * const filePath)
{
ifstream ifs(filePath);
if(!ifs)
{
LogFatal("open file[%s] failed.", filePath);
return false;
}
string line;
vector<string> vecBuf;
uint lineno = 0;
while(getline(ifs, line))
{
lineno ++;
trim(line);
if(line.empty() || startsWith(line, "#"))
{
continue;
}
vecBuf.clear();
if(!split(line, vecBuf, "=") || 2 != vecBuf.size())
{
LogFatal("line[%d:%s] is illegal.", lineno, line.c_str());
return false;
}
string& key = vecBuf[0];
string& value = vecBuf[1];
trim(key);
trim(value);
if(_map.end() != _map.find(key))
{
LogFatal("key[%s] already exists.", key.c_str());
return false;
}
_map[key] = value;
}
ifs.close();
return true;
}
public:
bool get(const string& key, string& value) const
{
map<string, string>::const_iterator it = _map.find(key);
if(_map.end() != it)
{
value = it->second;
return true;
}
return false;
}
private:
map<string, string> _map;
private:
friend ostream& operator << (ostream& os, const Config& config);
};
inline ostream& operator << (ostream& os, const Config& config)
{
return os << config._map;
}
4. 在main之前和之后执行代码
#include <iostream>
using namespace std;
class Base {
private:
int bs;
public:
Base() { bs = 0; }
~Base() { cout<< "Base delete..."<<endl; }
void Destory() { delete this; }
};
__attribute((constructor))void before()
{
printf("before mainn");
}
__attribute((destructor)) void after_main()
{
printf("%sn",__FUNCTION__);
}
int main()
{
Base * bs = new Base();
bs->Destory();
return 1;
}5. 定义不允许拷贝和直接赋值的类对象
#include <iostream>
using namespace std;
class nocopyable {
protected:
nocopyable(){};
~nocopyable(){};
private:
nocopyable(const nocopyable& that);
nocopyable& operator=(const nocopyable& that);
};
class nocopy : nocopyable {
};
int main() {
nocopy n1;
//nocopy n2 = n1; // or nocopy n2(n1) will compile error
return 0;
}C++类的默认拷贝构造函数的弊端 :
- 当类中没有定义任何构造函数时,编译器会默认提供一个无参构造函数且其函数体为空;
- 当类中没有定义拷贝构造函数时,编译器会默认提供一个拷贝构造函数,进行成员变量之间的拷贝。(这个拷贝操作是浅拷贝)
- C++的拷贝构造函数还有一处妙用,就是自定义拷贝构造函数,并设置为private属性,其实现体可以什么都不写,那么这个类将变成一个不可被复制的类了。
拷贝者和被拷贝者若是同一个地址,则为浅拷贝,反之为深拷贝。为类赋值需要调用的是class类的默认实现的赋值操作符重载函数,它们都是浅度拷贝的。前者其原型为:
class(const class& c)#include<iostream>
using namespace std;
class TestCls {
public:
int a;
int *p;
public:
TestCls()
{
std::cout<<"TestCls()"<<std::endl;
p = new int;
}
~TestCls()
{
delete p;
std::cout<<"~TestCls()"<<std::endl;
}
};
int main(void)
{
TestCls t;
TestCls t1 = t;
return 0;
}
编译运行:
# g++ -o testcopy testcopy.cpp
# ./testcopy
TestCls()
~TestCls()
testcopy(31828,0x1075185c0) malloc: *** error for object 0x7f9b84c00610: pointer being freed was not allocated
testcopy(31828,0x1075185c0) malloc: *** set a breakpoint in malloc_error_break to debug
Abort trap: 66. typedef定义模板类型
因为typedef不支持模板定义,所以需要借用类模板进行适配。
#include <iostream>
#include <functional>
#include <iomanip>
using namespace std;
//template <typename cls>
//typedef cls (*ttf)(cls, cls); //funptr.cpp:7:15: error: a typedef cannot be a template
typedef int (*ptf)(int ,int);
double my_divide (double x, double y) {return x/y;}
auto fn_half = std::bind (my_divide, placeholders::_1, 2);
int max(int a , int b)
{
return a >= b ? a : b;
}
int recac(int data, int size, ptf callback)
{
if(callback) {
return callback(data, size);
}
return 0;
}
template <typename ct, typename dt>
class Util
{
public:
//指针函数模板的使用需要结合类模板和函数模板。
typedef ct (*ctf)(dt ,dt);
ct max(dt a, dt b)
{
return a >= b ? a : b;
}
ct recac(dt data, dt size, ctf callback)
{
if(callback) {
return callback(data, size);
}
return 0;
}
};
int main()
{
// function pointer, 普通函数做实参时,会隐式转换成函数指针
ptf pfun = max;
cout << pfun(3,5) <<endl;
ptf pfun2 = &max;
cout << pfun2(3,8) <<endl;
cout << typeid(ptf).name() << endl;
std::cout << fn_half(10) << endl;
Util<double, double> utl;
cout << "Class Template Func Template Call:" << setw(2) << utl.recac(100.0, 20.0, &my_divide) << endl;
Util<int, int> itl;
cout << "Class Template Func Template Call:" << setw(2) << itl.recac(100, 20, max) <<endl;
return 0;
}7. 程序的内存空间布局
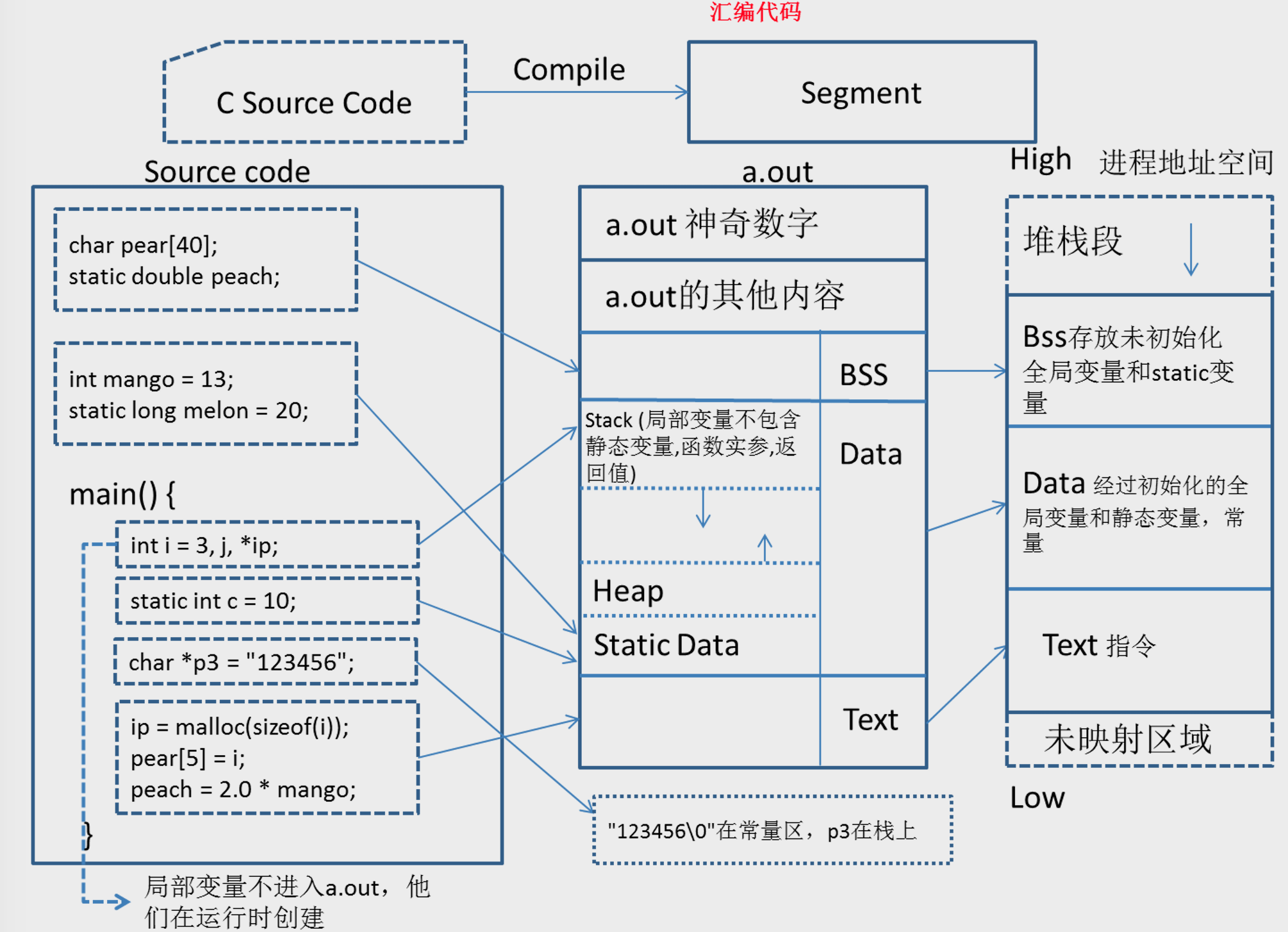
8. malloc/free为什么还要new/delete
- malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
- 对于非内部数据类型的对象而言,对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数,所以需要new/delete。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。由于内部数据类型的“对象”没有构造与析构的过程,对它们而言malloc/free和new/delete是等价的。
- 既然new/delete的功能完全覆盖了malloc/free,为什么C++不把malloc/free淘汰出局呢?这是因为C++程序经常要调用C函数,而C程序只能用malloc/free管理动态内存。
- 如果用free释放“new创建的动态对象”,那么该对象因无法执行析构函数而可能导致程序出错。如果用delete释放“malloc申请的动态内存”,结果也会导致程序出错,但是该程序的可读性很差。所以new/delete必须配对使用,malloc/free也一样。
9. 堆与栈的区别
堆与栈实际上是操作系统对进程占用的内存空间的两种管理方式,主要有如下几种区别:
- 管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
- 空间大小不同。每个进程拥有的栈的大小要远远小于堆的大小。理论上,程序员可申请的堆大小为虚拟内存的大小,进程栈的大小 64bits 的 Windows 默认 1MB,64bits 的 Linux 默认 10MB;
- 生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
- 分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由操作系统进行释放,无需我们手工实现。
- 分配效率不同。栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。
- 存放内容不同。栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。当主函数调用另外一个函数的时候,要对当前函数执行断点进行保存,需要使用栈来实现,首先入栈的是主函数下一条语句的地址,即扩展指针寄存器的内容(EIP),然后是当前栈帧的底部地址,即扩展基址指针寄存器内容(EBP),再然后是被调函数的实参等,一般情况下是按照从右向左的顺序入栈,之后是被调函数的局部变量,注意静态变量是存放在数据段或者BSS段,是不入栈的。出栈的顺序正好相反,最终栈顶指向主函数下一条语句的地址,主程序又从该地址开始执行。堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
10. 乐观锁和悲观锁
-
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
-
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
-
两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
乐观锁一般会使用版本号机制或CAS算法实现。
乐观锁的缺点:ABA 问题、循环时间长开销大、只能保证一个共享变量的原子操作
11. inline 定义和实现
| 非模板类型(none-template) | 模板类型(template) | |
| 头文件(.h) | • 全局变量申明(带extern限定符) • 全局函数的申明 • 带inline限定符的全局函数的定义 | • 带inline限定符的全局模板函数的申明和定义 |
| • 类的定义 • 类函数成员和数据成员的申明(在类内部) • 类定义内的函数定义(相当于inline) • 带static const限定符的数据成员在类内部的初始化 • 带inline限定符的类定义外的函数定义 | • 模板类的定义 • 模板类成员的申明和定义(定义可以放在类内或者类外,类外不需要写inline) | |
| 实现文件(.cpp) | • 全局变量的定义(及初始化) • 全局函数的定义 | (无) |
| • 类函数成员的定义 • 类带static限定符的数据成员的初始化 |
inline限定符
在头文件中,可以对函数用inline限定符来告知编译器,这段函数非常的简单,可以直接嵌入到调用定义之处。当然inline的函数并不一定会被编译器作为inline来实现,如果函数过于复杂,编译器也会拒绝inline。
自定义类型
对于自定义类型,包括类(class)和结构体(struct),它们的定义都是放在.h文件中。其成员的申明和定义就比较复杂了,不过看上边的表格,还是比较清晰的。
函数成员
- 函数成员无论是否带有static限定符,其申明都放在.h文件的类定义内部。
- 对于要inline的函数成员其定义放在.h文件;其他函数的实现都放在.cpp文件中。
数据成员
- 数据成员的申明与定义都是放在.h文件的类定义内部。对于数据类型,关键问题是其初始化要放在什么地方进行。
- 对于只含有static限定符的数据成员,它的初始化要放在.cpp文件中。因为它是所有类对象共有的,因此必须对它做合适的初始化。
- 对于只含有const限定符的数据成员,它的初始化只能在构造函数的初始化列表中完成。因为它是一经初始化就不能重新赋值,因此它也必须进行合适的初始化。
- 对于既含有static限定符,又含有const限定符的数据成员,它的初始化和定义同时进行。它也是必须进行合适的初始化
- 对于既没有static限定符,又没有const限定符的数据成员,它的值只针对本对象可以随意修改,因此我们并不在意它的初始化什么时候进行。
12. C++的多态 编译时多态和运行时多态
编译时多态:主要指泛型编程
运行时多态:
C++的多态性用一句话概括:在基类的函数前加上 virtual 关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数。
- 用 virtual 关键字申明的函数叫做虚函数,虚函数肯定是类的成员函数;
- 存在虚函数的类都有一个一维的虚函数表叫做虚表,类的对象有一个指向虚表开始的虚指针。虚表是和类对应的,虚表指针是和对象对应的;
- 多态性是一个接口多种实现,是面向对象的核心,分为类的多态性和函数的多态性;
- 多态用虚函数来实现,结合动态绑定;
- 纯虚函数:virtual void fun()=0;即抽象类,必须在子类实现这个函数,即先有名称,没有内容,在派生类实现内容。
- 抽象类是指包括至少一个纯虚函数的类;
13. 进程间的通信和线程间的通信
进程间的通信
- 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
- 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
- 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
线程间的通信
- 互斥锁
- 读写锁
- 信号量
- 条件变量
14. New不分配内存,指定地址
T & T::operator=(T const & x)
{
if (this != &x)
{
this->~T(); // destroy in place
new (this) T(x); // construct in place
}
return *this;
}It is called "placement new", and the comments in your code snippet pretty much explain it:
It constructs an object of type T without allocating memory for it, in the address specified in the parentheses.
So what you're looking at is a copy assignment operator which first destroys the object being copied to (without freeing the memory), and then constructs a new one in the same memory address. (It is also a pretty bad idea to implement the operator in this manner, as pointed out in the comments)
15. 理解 Memory barrier(CPU 内存屏障)
程序在运行时内存实际的访问顺序和程序代码编写的访问顺序不一定一致,这就是内存乱序访问。内存乱序访问行为出现的理由是为了提升程序运行时的性能。内存乱序访问主要发生在两个阶段:
- 编译时,编译器优化导致内存乱序访问(指令重排)
- 运行时,多 CPU 间交互引起内存乱序访问
Memory barrier 能够让 CPU 或编译器在内存访问上有序。一个 Memory barrier 之前的内存访问操作必定先于其之后的完成。Memory barrier 包括两类:
- 编译器 barrier
- CPU Memory barrier
参考:Linux内核同步机制之(三):memory barrier
解决:多线程pthread_barrier_init, asm 指令:__asm__ __volatile__("":::"memory");
16. 强制类型转换
C++同时提供了4种新的强制类型转换形式(通常称为新风格的或C++风格的强制转 型):const_cast(expression)、dynamic_cast(expression)、 reinterpret_cast(expression)和 static_cast(expression),每一种都适用于特定的目的,具体如下:
- dynamic_cast 主要用于执行“安全的向下转型(safe downcasting)”,也就是说,要确定一个对象是否是一个继承体系中的一个特定类型。支持父类指针到子类指针的转换,这种转换时最安全的转换。它是唯一不能用旧风格语法执行的强制类型转换,也是唯一可能有重大运行时代价的强制转换。
- static_cast 可以被用于强制隐形转换(例如,non-const对象转换为const对象,int转型为double,等等),它还可以用于很多这样的转换的反向转换 (例如,void*指针转型为有类型指针,基类指针转型为派生类指针),但是它不能将一个const对象转型为non-const对象(只有 const_cast能做到),它最接近于C-style的转换。应用到类的指针上,意思是说它允许子类类型的指针转换为父类类型的指针(这是一个有效的隐式转换),同时,也能够执行相反动作:转换父类为它的子类。
在这最后例子里,被转换的父类没有被检查是否与目的类型相一致。
代码:
class Base {};
class Derived : public Base {};
Base *a = new Base;
Derived *b = static_cast<Derived *>(a);'static_cast'除了操作类型指针,也能用于执行类型定义的显式的转换,以及基础类型之间的标准转换:
double d = 3.14159265;
int i = static_cast<int>(d);- const_cast一般用于强制消除对象的常量性。它是唯一能做到这一点的C++风格的强制转型。这个转换能剥离一个对象的const属性,也就是说允许你对常量进行修改。
class C {};
const C *a = new C;
C *b = const_cast<C *>(a);- reinterpret_cast 是特意用于底层的强制转型,导致实现依赖(就是说,不可移植)的结果,例如,将一个指针转型为一个整数。这样的强制类型在底层代码以外应该极为罕见。操作 结果只是简单的从一个指针到别的指针的值得二进制拷贝。在类型之间指向的内容不做任何类型的检查和转换。
17. mutable / volatile
在C++中,mutable是为了突破const的限制而设置的。被mutable修饰的变量,将永远处于可变的状态,即使在一个const函数中,甚至结构体变量或者类对象为const,其mutable成员也可以被修改。
volatile是一个类型修饰符。volatile修饰的数据,编译器不可对其进行执行期寄存于寄存器的优化。这种特性,是为了满足多线程同步、中断、硬件编程等特殊需要。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的直接访问。
18. __attribute__ ((__packed__))
struct unpacked_str{
char c;
int x;
char buf[1];
};
struct packed_str{
char c;
int x;
char buf[1];
}__attribute__((packed));输出(如果 buf[] 没有指定,则不占size 空间?)
size of char=1
size of int=4
size of unpacked_str=12
size of packed_str=6char buf[]; 这个特性是C99特有的一个新特性,称为伸缩型数组成员。利用这一特性可以声明最后一个成员是一个具有特殊属性的数组的结构。这个结构体sizeof(struct unpackstr )大小16,说明 char buf[]没有分配内存,等价于buf[0]。所以只能用时在堆里面分配。
19. enum类型的变量定义为一个字节存储
#include <stdio.h>
//给枚举类型限定字节数,只能在大于C++11模式下运行
typedef enum weekday: unsigned char {
SUN, MON, TUE, WED, THU, FRI, SAT
} weekday_t;
int main() {
weekday_t weekday = MON;
printf("%dn", sizeof (weekday_t));
printf("%dn", sizeof (weekday));
return 0;
}20. C 地址函数指针结构体数组初始化
void module_initial(void);
typedef struct {
void (* initial1) (void);
void (* initial2) (void);
}MODULE_T;
MODULE_T module = {
.initial1 = module_initial, //方法1
initial2 : module_initial, //方法2
};
void module_initial(void)
{
//............
}
MODULE_T mdl;
mdl.initial2 = module_initial; //方法321.模板类的声明和应用
对于普通的类,即使声明和定义分别位于.h和.cpp文件,在main.cpp中只需要把类的头文件用#include命令包含就行了;但对于模板类,由于模板类的实现不是函数,因此cpp执行文件不能单独编译。也就是说,编译器不能通过h头文件来找到并且编译对应的cpp执行文件。
解决办法有两种:
1. 把模板类的定义也放在头文件中,见代码中Vector.h部分被注释的代码段
2. 如果实在想把模板类的声明和定义(实现)分开,则需要在main.cpp中用#include命令将模板类的cpp文件包含进来
// Vector.h
#ifndef VECTOR_H
#define VECTOR_H
#include <iostream>
typedef int Rank;
#define DEFAULT_CAPACITY 3
using std::cout;
// Vector模板类
template <typename T> class Vector{
protected:
Rank _size, _capacity; //规模、容量
T *_elem; //数据区
void copyFrom(T const* A, Rank lo, Rank hi); //复制数组区间A[lo, hi)
public:
Vector(int c = DEFAULT_CAPACITY, int s = 0, T v=0) //容量c,规模为s,所有元素初始为v
{
_elem = new T[_capacity = c];
for(_size = 0; _size < s; _elem[_size++] = v);
}
Vector(T const* A, Rank lo, Rank hi) { copyFrom(A, lo, hi);} //数组区间复制
Vector(T const* A, Rank n) { copyFrom(A, 0, n);} //数组整体复制
Vector(Vector<T> const& V, Rank lo, Rank hi) { copyFrom(V._elem, lo, hi);} //向量区间复制
Vector(Vector<T> const& V, Rank n) { copyFrom(V._elem, 0, n);} //向量整体复制
//析构函数
~Vector() { delete [] _elem;}
void print()
{
for(Rank i=0; i<_size; ++i)
cout<<_elem[i]<<" ";
}
};
//template <typename T>
//void Vector<T>::copyFrom(T const *A, Rank lo, Rank hi)
//{ //以数组区间A[lo, hi)为蓝本复制向量
// _elem = new T[2*(hi-lo)]; //分配2倍于(hi-lo)的空间
// _size = 0; //规模清零
// while(lo<hi)
// {
// _elem[_size++] = A[lo++];
cout<<_size<<" "<<lo<<std::endl;
// }
//}
#endif //VECTOR_H
// Vector.cpp
#include "Vector.h"
template <typename T>
void Vector<T>::copyFrom(T const *A, Rank lo, Rank hi)
{ //以数组区间A[lo, hi)为蓝本复制向量
_elem = new T[2*(hi-lo)]; //分配2倍于(hi-lo)的空间
_size = 0; //规模清零
while(lo<hi)
_elem[_size++] = A[lo++];
}
//main.cpp
#include <iostream>
#include "Vector.h"
using namespace std;
int main()
{
int arr[3]={1,2,3};
Vector<int> v(arr, 3);
v.print();
return 0;
}22. Switch/Case语句的变量local 化
#include "iostream"
using namespace std;
int main()
{
int a;
cin>>a;
switch(a) {
case 0:
int i = 10;
break;
case 1:
{
cout << "hello" << endl;
cout << i << endl;
break;
}
default:
cout << "other" <<endl;
}
return 0;
}case中定义的变量不限制作用域会出现错误
case.cpp:19:5: error: cannot jump from switch statement to this case label
default:
^
case.cpp:11:13: note: jump bypasses variable initialization
int i = 10;
^
case.cpp:13:5: error: cannot jump from switch statement to this case label
case 1:
^
case.cpp:11:13: note: jump bypasses variable initialization
int i = 10;
^
2 errors generated.
最后
以上就是野性小懒虫最近收集整理的关于C++ 基础1. 检查编译器版本2. 类成员变量的Set/Get宏3. 加载配置4. 在main之前和之后执行代码 5. 定义不允许拷贝和直接赋值的类对象6. typedef定义模板类型 7. 程序的内存空间布局8. malloc/free为什么还要new/delete9. 堆与栈的区别10. 乐观锁和悲观锁11. inline 定义和实现12. C++的多态 编译时多态和运行时多态13. 进程间的通信和线程间的通信14. New不分配内存,指定地址 15. 理解 Memory barrier(的全部内容,更多相关C++内容请搜索靠谱客的其他文章。








发表评论 取消回复