背景
- Kotlin Flow 是基于 Kotlin 协程基础能力搭建的一套数据流框架,从功能复杂性上看是介于 LiveData 和 RxJava 之间的解决方案。Kotlin Flow 拥有比 LiveData 更丰富的能力,但裁剪了 RxJava 大量复杂的操作符,做得更加精简。并且在 Kotlin 协程的加持下,Kotlin Flow 目前是 Google 主推的数据流框架。
1. 为什么要使用 Flow?
LiveData、Kotlin Flow 和 RxJava 三者都属于 可观察的数据容器类,观察者模式是它们相同的基本设计模式,那么相对于其他两者,Kotlin Flow 的优势是什么呢?
LiveData 是 androidx 包下的组件,是 Android 生态中一个的简单的生命周期感知型容器。简单即是它的优势,也是它的局限,当然这些局限性不应该算 LiveData 的缺点,因为 LiveData 的设计初衷就是一个简单的数据容器。对于简单的数据流场景,使用 LiveData 完全没有问题。
- LiveData 只能在主线程更新数据: 只能在主线程 setValue,即使 postValue 内部也是切换到主线程执行;
- LiveData 数据重放问题: 注册新的订阅者,会重新收到 LiveData 存储的数据,这在有些情况下不符合预期(可以使用自定义的 LiveData 子类
SingleLiveData或 UnPeekLiveData 解决,此处不展开); - LiveData 不防抖: 重复 setValue 相同的值,订阅者会收到多次
onChanged()回调(可以使用distinctUntilChanged()解决,此处不展开); - LiveData 不支持背压: 在数据生产速度 > 数据消费速度时,LiveData 无法正常处理。比如在子线程大量
postValue数据但主线程消费跟不上时,中间就会有一部分数据被忽略。
RxJava 是第三方组织 ReactiveX 开发的组件,Rx 是一个包括 Java、Go 等语言在内的多语言数据流框架。功能强大是它的优势,支持大量丰富的操作符,也支持线程切换和背压。然而 Rx 的学习门槛过高,对开发反而是一种新的负担,也会带来误用的风险。
Kotlin 是 kotlinx 包下的组件,不是单纯 Android 生态下的产物。那么,Flow 的优势在哪里呢?
- Flow 支持协程: Flow 基于协程基础能力,能够以结构化并发的方式生产和消费数据,能够实现线程切换(依靠协程的 Dispatcher);
- Flow 支持背压: Flow 的子类 SharedFlow 支持配置缓存容量,可以应对数据生产速度 > 数据消费速度的情况;
- Flow 支持数据重放配置: Flow 的子类 SharedFlow 支持配置重放 replay,能够自定义对新订阅者重放数据的配置;
- Flow 相对 RxJava 的学习门槛更低: Flow 的功能更精简,学习性价比相对更高。不过 Flow 是基于协程,在协程会有一些学习成本,但这个应该拆分来看。
当然 Kotlin Flow 也存在一些局限:
- Flow 不是生命周期感知型组件: Flow 不是 Android 生态下的产物,自然 Flow 是不会关心组件生命周期。那么我们如何确保订阅者在监听 Flow 数据流时,不会在错误的状态更新 View 呢?这个问题在下文 第 6 节再说。
2. 冷数据流与热数据流
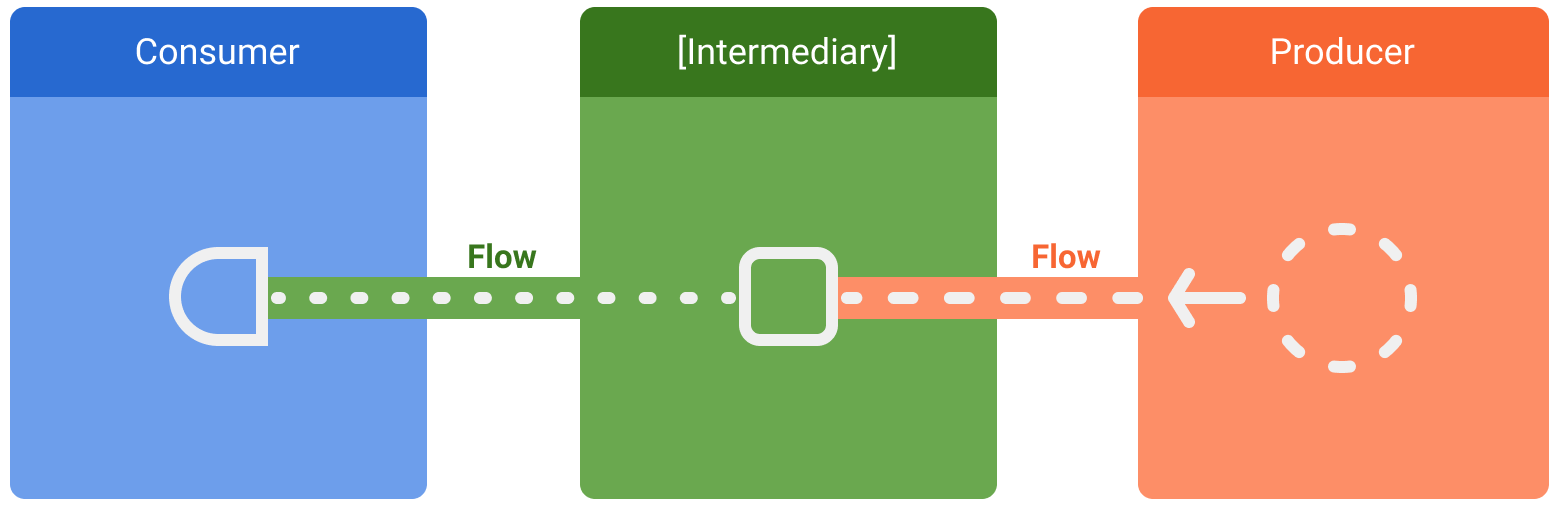
Kotlin Flow 包含三个实体:数据生产方 - (可选的)中介者 - 数据使用方。数据生产方负责向数据流发射(emit)数据,而数据使用方从数据流中消费数据。根据生产方产生数据的时机,可以将 Kotlin Flow 分为冷流和热流两种:
- 普通 Flow(冷流): 冷流是不共享的,也没有缓存机制。冷流只有在订阅者 collect 数据时,才按需执行发射数据流的代码。冷流和订阅者是一对一的关系,多个订阅者间的数据流是相互独立的,一旦订阅者停止监听或者生产代码结束,数据流就自动关闭。
- SharedFlow / StateFlow(热流): 热流是共享的,有缓存机制的。无论是否有订阅者 collect 数据,都可以生产数据并且缓存起来。热流和订阅者是一对多的关系,多个订阅者可以共享同一个数据流。当一个订阅者停止监听时,数据流不会自动关闭(除非使用
WhileSubscribed策略,这个在下文再说)。
3. 普通 Flow(冷流)
普通 Flow 是冷流,数据是不共享的,也没有缓存机制。数据源会延迟到消费者开始监听时才生产数据(如终端操作 collect{}),并且每次订阅都会创建一个全新的数据流。 一旦消费者停止监听或者生产者代码结束,Flow 会自动关闭。
val coldFlow: Flow<Int> = flow {
// 生产者代码
while(true) {
// 执行计算
emit(result)
delay(100)
}
// 生产者代码结束,流将被关闭
}.collect{ data ->
}
冷流 Flow 主要的操作如下:
- 创建数据流 flow{}: Flow 构造器会创建一个新的数据流。flow{} 是 suspend 函数,需要在协程中执行;
- 发送数据 emit(): emit() 将一个新的值发送到数据流中;
- 终端操作 collect{}: 触发数据流消费,可以获取数据流中所有的发出值。Flow 是冷流,数据流会延迟到终端操作 collect 才执行,并且每次在 Flow 上重复调用 collect,都会重复执行 flow{} 去触发发送数据动作(源码位置:
AbstractFlow)。collect 是 suspend 函数,需要在协程中执行。 - 异常捕获 catch{}: catch{} 会捕获数据流中发生的异常;
- 协程上下文切换 flowOn(): 更改上流数据操作的协程上下文 CoroutineContext,对下流操作没有影响。如果有多个 flowOn 运算符,每个 flowOn 只会更改当前位置的上游数据流;
- 状态回调 onStart: 在数据开始发送之前触发,在数据生产线程回调;
- 状态回调 onCompletion: 在数据发送结束之后触发,在数据生产线程回调;
- 状态回调 onEmpty: 在数据流为空时触发(在数据发送结束但事实上没有发送任何数据时),在数据生产线程回调。
普通 Flow 的核心代码在 AbstractFlow 中,可以看到每次调用终端操作 collect,collector 代码块都会执行一次,也就是重新执行一次数据生产代码:
AbstractFlow.kt
public abstract class AbstractFlow<T> : Flow<T> {
@InternalCoroutinesApi
public final override suspend fun collect(collector: FlowCollector<T>) {
// 1. 对 flow{} 的包装
val safeCollector = SafeCollector(collector, coroutineContext)
try {
// 2. 执行 flow{} 代码块
collectSafely(safeCollector)
} finally {
// 3. 释放协程相关的参数
safeCollector.releaseIntercepted()
}
}
public abstract suspend fun collectSafely(collector: FlowCollector<T>)
}
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
collector.block()
}
}
4. SharedFlow —— 高配版 LiveData
下文要讲的 StateFlow 其实是 SharedFlow 的一个子类,所以我们先讲 SharedFlow。SharedFlow 和 StateFlow 都属于热流,无论是否有订阅者(collect),都可以生产数据并且缓存。 它们都有一个可变的版本 MutableSharedFlow 和 MutableStateFlow,这与 LiveData 和 MutableLiveData 类似,对外暴露接口时,应该使用不可变的版本。
4.1 SharedFlow 与 MutableSharedFlow 接口
直接对着接口讲不明白,这里先放出这两个接口方便查看:
public interface SharedFlow<out T> : Flow<T> {
// 缓存的重放数据的快照
public val replayCache: List<T>
}
public interface MutableSharedFlow<T> : SharedFlow<T>, FlowCollector<T> {
// 发射数据(注意这是个挂起函数)
override suspend fun emit(value: T)
// 尝试发射数据(如果缓存溢出策略是 SUSPEND,则溢出时不会挂起而是返回 false)
public fun tryEmit(value: T): Boolean
// 活跃订阅者数量
public val subscriptionCount: StateFlow<Int>
// 重置重放缓存,新订阅者只会收到注册后新发射的数据
public fun resetReplayCache()
}
4.2 构造一个 SharedFlow
我会把 SharedFlow 理解为一个高配版的 LiveData,这点首先在构造函数就可以体现出来。SharedFlow 的构造函数允许我们配置三个参数:
SharedFlow.kt
public fun <T> MutableSharedFlow(
// 重放数据个数
replay: Int = 0,
// 额外缓存容量
extraBufferCapacity: Int = 0,
// 缓存溢出策略
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): MutableSharedFlow<T> {
val bufferCapacity0 = replay + extraBufferCapacity
val bufferCapacity = if (bufferCapacity0 < 0) Int.MAX_VALUE else bufferCapacity0 // coerce to MAX_VALUE on overflow
return SharedFlowImpl(replay, bufferCapacity, onBufferOverflow)
}
public enum class BufferOverflow {
// 挂起
SUSPEND,
// 丢弃最早的一个
DROP_OLDEST,
// 丢弃最近的一个
DROP_LATEST
}
| 参数 | 描述 |
|---|---|
| reply | 重放数据个数,当新订阅者时注册时会重放缓存的 replay 个数据 |
| extraBufferCapacity | 额外缓存容量,在 replay 之外的额外容量,SharedFlow 的缓存容量 capacity = replay + extraBufferCapacity(实在想不出额外容量有什么用,知道可以告诉我) |
| onBufferOverflow | 缓存溢出策略,即缓存容量 capacity 满时的处理策略(SUSPEND、DROP_OLDEST、DROP_LAST) |
SharedFlow 默认容量 capacity 为 0,重放 replay 为 0,缓存溢出策略是 SUSPEND,发射数据时已注册的订阅者会收到数据,但数据会立刻丢弃,而新的订阅者不会收到历史发射过的数据。
为什么我们可以把 SharedFlow 理解为 “高配版” LiveData,拿 SharedFlow 和 LiveData 做个简单的对比就知道了:
- 容量问题: LiveData 容量固定为 1 个,而 SharedFlow 容量支持配置 0 个到 多个;
- 背压问题: LiveData 无法应对背压问题,而 SharedFlow 有缓存空间能应对背压问题;
- 重放问题: LiveData 固定重放 1 个数据,而 SharedFlow 支持配置重放 0 个到多个;
- 线程问题: LiveData 只能在主线程订阅,而 SharedFlow 支持在任意线程(通过协程的 Dispatcher)订阅。
当然 SharedFlow 也并不是完胜,LiveData 能够处理生命周期安全问题,而 SharedFlow 不行(因为 Flow 本身就不是纯 Android 生态下的组件),不合理的使用会存在不必要的操作和资源浪费,以及在错误的状态更新 View 的风险。不过别担心,这个问题可以通过 第 6 节 的 Lifecycle API 来解决。
4.3 普通 Flow 转换为 SharedFlow
前面提到过,冷流是不共享的,也没有缓存机制。使用 Flow.shareIn 或 Flow.stateIn 可以把冷流转换为热流,一来可以将数据共享给多个订阅者,二来可以增加缓冲机制。
Share.kt
public fun <T> Flow<T>.shareIn(
// 协程作用域范围
scope: CoroutineScope,
// 启动策略
started: SharingStarted,
// 控制数据重放的个数
replay: Int = 0
): SharedFlow<T> {
val config = configureSharing(replay)
val shared = MutableSharedFlow<T>(
replay = replay,
extraBufferCapacity = config.extraBufferCapacity,
onBufferOverflow = config.onBufferOverflow
)
@Suppress("UNCHECKED_CAST")
scope.launchSharing(config.context, config.upstream, shared, started, NO_VALUE as T)
return shared.asSharedFlow()
}
public companion object {
// 热启动式:立即开始,并在 scope 指定的作用域结束时终止
public val Eagerly: SharingStarted = StartedEagerly()
// 懒启动式:在注册首个订阅者时开始,并在 scope 指定的作用域结束时终止
public val Lazily: SharingStarted = StartedLazily()
public fun WhileSubscribed(
stopTimeoutMillis: Long = 0,
replayExpirationMillis: Long = Long.MAX_VALUE
): SharingStarted =
StartedWhileSubscribed(stopTimeoutMillis, replayExpirationMillis)
}
sharedIn 的参数 scope 和 replay 不需要过多解释,主要介绍下 started: SharingStarted 启动策略,分为三种:
-
Eagerly(热启动式): 立即启动数据流,并保持数据流(直到 scope 指定的作用域结束);
-
Lazily(懒启动式): 在首个订阅者注册时启动,并保持数据流(直到 scope 指定的作用域结束);
-
WhileSubscribed(): 在首个订阅者注册时启动,并保持数据流直到在最后一个订阅者注销时结束(或直到 scope 指定的作用域结束)。通过 WhildSubscribed() 策略能够在没有订阅者的时候及时停止数据流,避免引起不必要的资源浪费,例如一直从数据库、传感器中读取数据。
whileSubscribed() 还提供了两个配置参数:
- stopTimeoutMillis 超时时间(毫秒): 最后一个订阅者注销订阅后,保留数据流的超时时间,默认值 0 表示立刻停止。这个参数能够帮助防抖,避免订阅者临时短时间注销就马上关闭数据流。例如希望等待 5 秒后没有订阅者则停止数据流,可以使用 whileSubscribed(5000)。
- replayExpirationMillis 重放过期时间(毫秒): 停止数据流后,保留重放数据的超时时间,默认值 Long.MAX_VALUE 表示永久保存(replayExpirationMillis 发生在停止数据流后,说明 replayExpirationMillis 时间是在 stopTimeoutMillis 之后发生的)。例如希望希望等待 5 秒后停止数据流,再等待 5 秒后的数据视为无用的陈旧数据,可以使用 whileSubscribed(5000, 5000)。
5. StateFlow —— LiveData 的替代品
StateFlow 是 SharedFlow 的子接口,可以理解为一个特殊的 SharedFlow。不过它们的继承关系只是接口上有继承关系,内部的实现类 SharedFlowImpl 和 StateFlowImpl 其实是分开的,这里要留个印象就好。
5.1 StateFlow 与 MutableStateFlow 接口
这里先放出这两个接口方便查看:
public interface StateFlow<out T> : SharedFlow<T> {
// 当前值
public val value: T
}
public interface MutableStateFlow<T> : StateFlow<T>, MutableSharedFlow<T> {
// 当前值
public override var value: T
// 比较并设置(通过 equals 对比,如果值发生真实变化返回 true)
public fun compareAndSet(expect: T, update: T): Boolean
}
5.2 构造一个 StateFlow
StateFlow 的构造函数就简单多了,有且仅有一个必选的参数,代表初始值:
public fun <T> MutableStateFlow(value: T): MutableStateFlow<T> = StateFlowImpl(value ?: NULL)
5.3 特殊的 SharedFlow
StateFlow 是 SharedFlow 的一种特殊配置,MutableStateFlow(initialValue) 这样一行代码本质上和下面使用 SharedFlow 的方式是完全相同的:
val shared = MutableSharedFlow(
replay = 1,
onBufferOverflow = BufferOverflow.DROP_OLDEST
)
shared.tryEmit(initialValue) // emit the initial value
val state = shared.distinctUntilChanged() // get StateFlow-like behavior
- 有初始值: StateFlow 初始化时必须传入初始值;
- 容量为 1: StateFlow 只会保存一个值;
- 重放为 1: StateFlow 会向新订阅者重放最新的值;
- 不支持 resetReplayCache() 重置重放缓存: StateFlow 的 resetReplayCache() 方法抛出
UnsupportedOperationException - 缓存溢出策略为 DROP_OLDEST: 意味着每次发射的新数据会覆盖旧数据;
总的来说,StateFlow 要求传入初始值,并且仅支持保存一个最新的数据,会向新订阅者会重放一次最新值,也不允许重置重放缓存。说 StateFlow 是 LiveData 的替代品一点不为过。除此之外,StateFlow 还额外支持一些特性:
- 数据防抖: 意味着仅在更新值并且发生变化才会回调,如果更新值没有变化不会回调 collect,其实就是在发射数据时加了一层拦截:
StateFlow.kt
public override var value: T
get() = NULL.unbox(_state.value)
set(value) { updateState(null, value ?: NULL) }
override fun compareAndSet(expect: T, update: T): Boolean =
updateState(expect ?: NULL, update ?: NULL)
private fun updateState(expectedState: Any?, newState: Any): Boolean {
var curSequence = 0
var curSlots: Array<StateFlowSlot?>? = this.slots // benign race, we will not use it
synchronized(this) {
val oldState = _state.value
if (expectedState != null && oldState != expectedState) return false // CAS support
if (oldState == newState) return true // 如果新值 equals 旧值则拦截, 但 CAS 返回 true
_state.value = newState
...
return true
}
}
- CAS 操作: 原子性的比较与设置操作,只有在旧值与 expect 相同时返回 ture。
5.4 普通 Flow 转换为 StateFlow
跟 SharedFlow 一样,普通 Flow 也可以转换为 StateFlow:
Share.kt
public fun <T> Flow<T>.stateIn(
// 共享开始时所在的协程作用域范围
scope: CoroutineScope,
// 共享开始策略
started: SharingStarted,
// 初始值
initialValue: T
): StateFlow<T> {
val config = configureSharing(1)
val state = MutableStateFlow(initialValue)
scope.launchSharing(config.context, config.upstream, state, started, initialValue)
return state.asStateFlow()
}
6. 安全地观察 Flow 数据流
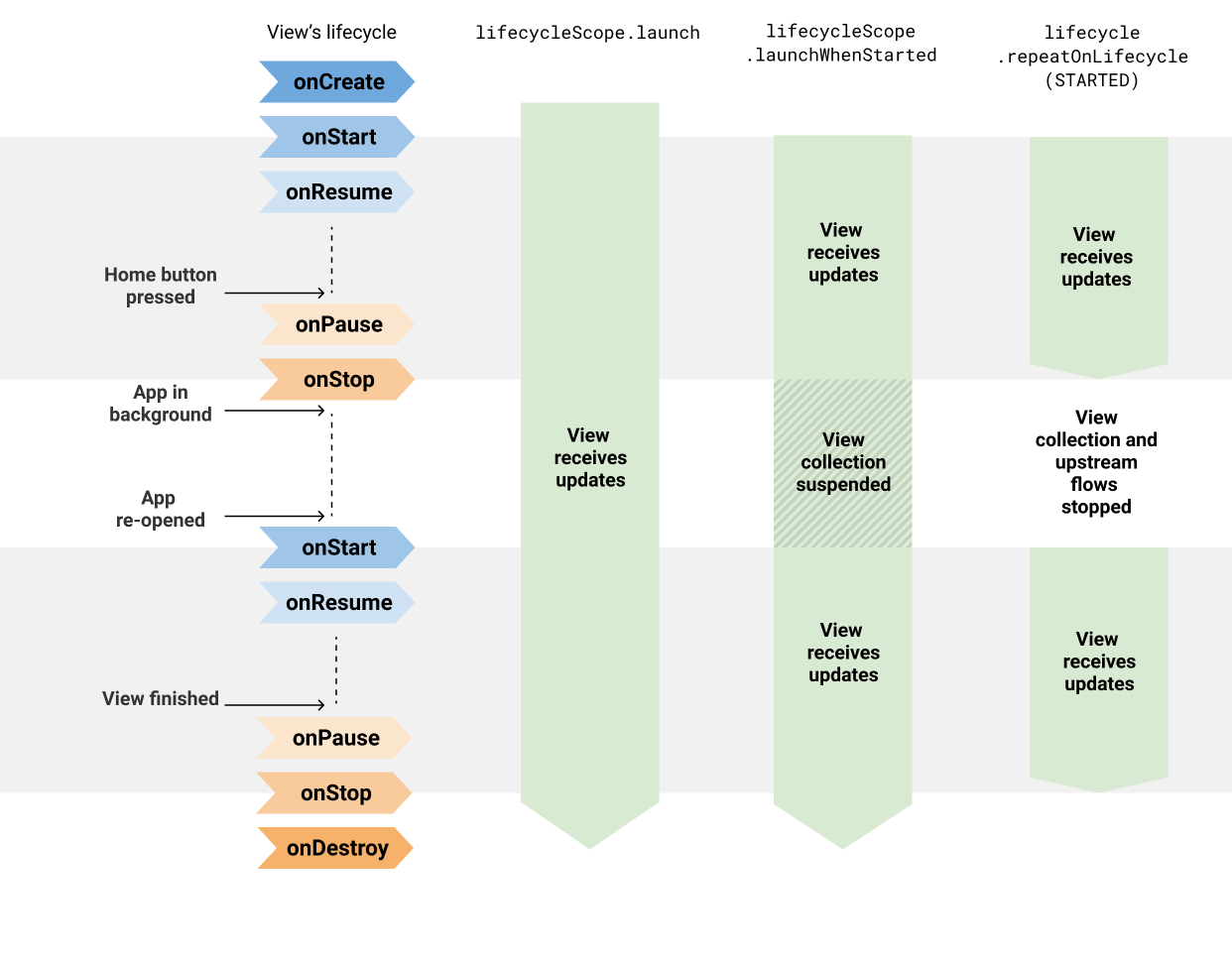
前面也提到了,Flow 不具备 LiveData 的生命周期感知能力,所以订阅者在监听 Flow 数据流时,会存在生命周期安全的问题。Google 推荐的做法是使用 Lifecycle#repeatOnLifecycle API:
// 从 2.4.0 开始支持 Lifecycle#repeatOnLifecycle API
implementation "androidx.lifecycle:lifecycle-runtime-ktx:2.4.1"
- LifecycleOwner#addRepeatingJob: 在生命周期到达指定状态时,自动创建并启动协程执行代码块,在生命周期低于该状态时,自动取消协程。因为 addRepeatingJob 不是挂起函数,所以不遵循结构化并发的规则。目前已经废弃,被下面的 repeatOnLifecycle() 替代了(废弃 addRepeatingJob 的考量见 设计 repeatOnLifecycle API 背后的故事 );
- Lifecycle#repeatOnLifecycle: repeatOnLifecycle 的作用相同,区别在于它是一个 suspend 函数,需要在协程中执行;
- Flow#flowWithLifecycle: Flow#flowWithLifecycle 的作用相同,内部基于 repeatOnLifecycle API。
class LocationActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleOwner.addRepeatingJob(Lifecycle.State.STARTED) {
locationProvider.locationFlow().collect {
// update UI
}
}
}
}
class LocationActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// repeatOnLifecycle 是 suspends 函数,所以需要在协程中执行
// 当 lifecycleScope 的生命周期高于 STARTED 状态时,启动一个新的协程并执行代码块
// 当 lifecycleScope 的生命周期低于 STARTED 状态时,取消该协程
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
// 当前生命周期一定高于 STARTED 状态,可以安全地从数据流中取数据,并更新 View
locationProvider.locationFlow().collect {
// update UI
}
}
// 结构化并发:生命周期处于 DESTROYED 状态时,切换回调用 repeatOnLifecycle 的协程继续执行
}
}
}
class LocationActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
locationProvider.locationFlow()
.flowWithLifecycle(this, Lifecycle.State.STARTED)
.onEach {
// update UI
}
.launchIn(lifecycleScope)
}
}
如果不使用 Lifecycle#repeatOnLifecycle API,具体会出现什么问题呢?
- Activity.lifecycleScope.launch: 立即启动协程,并在 Activity 销毁时取消协程;
- Fragment.lifecycleScope.launch: 立即启动协程,并在 Fragment 销毁时取消协程;
- Fragment.viewLifecycleOwner.lifecycleScope.launch: 立即启动协程,并在 Fragment 中视图销毁时取消协程。
可以看到,这些协程 API 只有在最后组件 / 视图销毁时才会取消协程,当视图进入后台时协程并不会被取消,Flow 会持续生产数据,并且会触发更新视图。
- LifecycleContinueScope.launchWhenX: 在生命周期到达指定状态时立即启动协程执行代码块,在生命周期低于该状态时挂起(而不是取消)协程,在生命周期重新高于指定状态时,自动恢复该协程。
可以看到,这些协程 API 在视图离开某个状态时会挂起协程,能够避免更新视图。但是 Flow 会持续生产数据,也会产生一些不必要的操作和资源消耗(CPU 和内存)。 虽然可以在视图进入后台时手动取消协程,但很明显增写了模板代码,没有 repeatOnLifecycle API 来得简洁。
class LocationActivity : AppCompatActivity() {
// 协程控制器
private var locationUpdatesJob: Job? = null
override fun onStart() {
super.onStart()
locationUpdatesJob = lifecycleScope.launch {
locationProvider.locationFlow().collect {
// update UI
}
}
}
override fun onStop() {
// 在视图进入后台时取消协程
locationUpdatesJob?.cancel()
super.onStop()
}
}
回过头来看,repeatOnLifecycle 是怎么实现生命周期感知的呢?其实很简单,是通过 Lifecycle#addObserver 来监听生命周期变化:
RepeatOnLifecycle.kt
suspendCancellableCoroutine<Unit> { cont ->
// Lifecycle observers that executes `block` when the lifecycle reaches certain state, and
// cancels when it falls below that state.
val startWorkEvent = Lifecycle.Event.upTo(state)
val cancelWorkEvent = Lifecycle.Event.downFrom(state)
val mutex = Mutex()
observer = LifecycleEventObserver { _, event ->
if (event == startWorkEvent) {
// Launch the repeating work preserving the calling context
launchedJob = this@coroutineScope.launch {
// Mutex makes invocations run serially,
// coroutineScope ensures all child coroutines finish
mutex.withLock {
coroutineScope {
block()
}
}
}
return@LifecycleEventObserver
}
if (event == cancelWorkEvent) {
launchedJob?.cancel()
launchedJob = null
}
if (event == Lifecycle.Event.ON_DESTROY) {
cont.resume(Unit)
}
}
this@repeatOnLifecycle.addObserver(observer as LifecycleEventObserver)
}
7. Channel 通道
在协程的基础能力上使用数据流,除了上文提到到 Flow API,还有一个 Channel API。Channel 是 Kotlin 中实现跨协程数据传输的数据结构,类似于 Java 中的 BlockQueue 阻塞队列。不同之处在于 BlockQueue 会阻塞线程,而 Channel 是挂起线程。Google 的建议 是优先使用 Flow 而不是 Channel,主要原因是 Flow 会更自动地关闭数据流,而一旦 Channel 没有正常关闭,则容易造成资源泄漏。此外,Flow 相较于 Channel 提供了更明确的约束和操作符,更灵活。
Channel 主要的操作如下:
- 创建 Channel: 通过 Channel(Channel.UNLIMITED) 创建一个 Channel 对象,或者直接使用 produce{} 创建一个生产者协程;
- 关闭 Channel: Channel#close();
- 发送数据: Channel#send() 往 Channel 中发送一个数据,在 Channel 容量不足时 send() 操作会挂起,Channel 默认容量 capacity 是 1;
- 接收数据: 通过 Channel#receive() 从 Channel 中取出一个数据,或者直接通过 actor 创建一个消费者协程,在 Channel 中数据不足时 receive() 操作会挂起。
- 广播通道 BroadcastChannel(废弃,使用 SharedFlow): 普通 Channel 中一个数据只会被一个消费端接收,而 BroadcastChannel 允许多个消费端接收。
public fun <E> Channel(
// 缓冲区容量,当超出容量时会触发 onBufferOverflow 拒绝策略
capacity: Int = RENDEZVOUS,
// 缓冲区溢出策略,默认为挂起,还有 DROP_OLDEST 和 DROP_LATEST
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
// 处理元素未能成功送达处理的情况,如订阅者被取消或者抛异常
onUndeliveredElement: ((E) -> Unit)? = null
): Channel<E>
8. 浅尝一下
到这里,LiveData、Flow 和 Channel 我们都讲了一遍了,实际场景中怎么使用呢,浅尝一下。
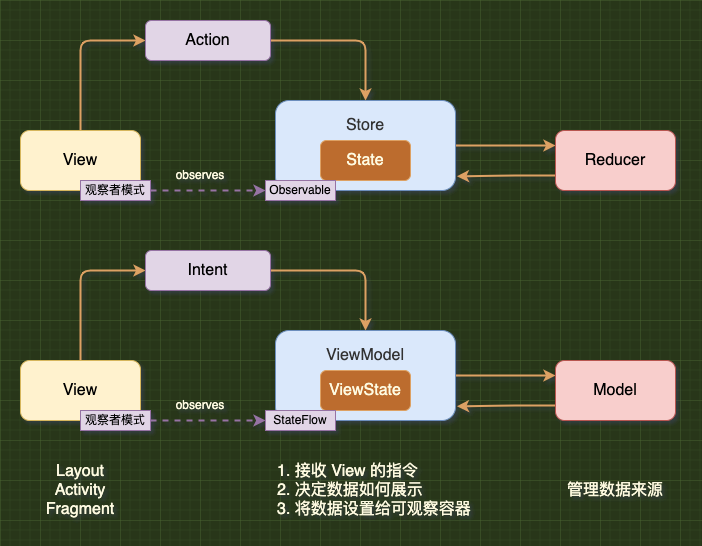
- 事件(Event): 事件是一次有效的,新订阅者不应该收到旧的事件,因此事件数据适合用 SharedFlow(replay=0);
- 状态(State): 状态是可以恢复的,新订阅者允许收到旧的状态数据,因此状态数据适合用 StateFlow。
示例代码如下,不熟悉 MVI 模式的同学可以移步:Android UI 架构演进:从 MVC 到 MVP、MVVM、MVI
BaseViewModel.kt
interface UiState
interface UiEvent
interface UiEffect
abstract class BaseViewModel<State : UiState, Event : UiEvent, Effect : UiEffect> : ViewModel() {
// 初始状态
private val initialState: State by lazy { createInitialState() }
// 页面需要的状态,对应于 MVI 模式的 ViewState
private val _uiState = MutableStateFlow<State>(initialState)
// 对外接口使用不可变版本
val uiState = _uiState.asStateFlow()
// 页面状态变更的 “副作用”,类似一次性事件,不需要重放的状态变更(例如 Toast)
private val _effect = MutableSharedFlow<Effect>()
// 对外接口使用不可变版本
val effect = _effect.asSharedFlow()
// 页面的事件操作,对应于 MVI 模式的 Intent
private val _event = MutableSharedFlow<Event>()
init {
viewModelScope.launch {
_event.collect {
handleEvent(it)
}
}
}
// 初始状态
protected abstract fun createInitialState(): State
// 事件处理
protected abstract fun handleEvent(event: Event)
/**
* 事件入口
*/
fun sendEvent(event: Event) {
viewModelScope.launch {
_event.emit(event)
}
}
/**
* 状态变更
*/
protected fun setState(newState: State) {
_uiState.value = newState
}
/**
* 副作用
*/
protected fun setEffect(effect: Effect) {
_effect.send(effect)
}
}
参考资料
- 协程 Flow 最佳实践 | 基于 Android 开发者峰会应用 —— Android 官方文档
- 设计 repeatOnLifecycle API 背后的故事 —— Android 官方文档
- 使用更为安全的方式收集 Android UI 数据流 —— Android 官方文档
- Flow 操作符 shareIn 和 stateIn 使用须知 —— Android 官方文档
- 从 LiveData 迁移到 Kotlin 数据流 —— Android 官方文档
- 用 Kotlin Flow 解决开发中的痛点 —— 都梁人 著
- 抽丝剥茧Kotlin - 协程中绕不过的Flow —— 九心 著
- Kotlin flow实践总结! —— 入魔的冬瓜 著
- Android—kotlin-Channel超详细讲解 —— hqk 著
最后
以上就是如意金毛最近收集整理的关于有小伙伴说看不懂 LiveData、Flow、Channel,跟我走背景1. 为什么要使用 Flow?2. 冷数据流与热数据流3. 普通 Flow(冷流)4. SharedFlow —— 高配版 LiveData5. StateFlow —— LiveData 的替代品6. 安全地观察 Flow 数据流7. Channel 通道8. 浅尝一下的全部内容,更多相关有小伙伴说看不懂内容请搜索靠谱客的其他文章。








发表评论 取消回复