0x01 缘由
本次学习的目的主要按照如下大纲开展:
以服务端客户端程序调试三次握手、数据传输、四次挥手过程。
搭建环境如下:前期调试linux内核环境
从物理层向上:
进入物理层:驱动程序处理中断?
进入链路层:网卡设备收到包后驱动程序做什么处理,是否做mac校验,满足什么条件会将数据包向协议栈上送,混杂模式和非混杂模式的区别,网卡驱动的工作模式?
进入网络层:ip包上来后经过的关键路径,ip层路由选择过程是怎么做的?
进入传输层:三次握手的过程、数据包传输、四次挥手的过程?
进入应用层:数据如何放入到缓冲队列中、socket怎么知道数据有了?
从应用层向下:
进入应用层:应用层调用send将数据放入缓存?
进入传输层:三次握手的过程、数据包传输、四次挥手的过程?
进入网络层:ip包上来后经过的关键路径,ip层路由选择过程是怎么做的?
进入链路层:网卡设备收到包后驱动程序做什么处理,是否做mac校验,满足什么条件会将数据包向协议栈上送,混杂模式和非混杂模式的区别,网卡驱动的工作模式?
进入物理层:驱动程序处理中断?
0x02 物理层
物理层主要是一些网络设备驱动与硬件交互。此处不做深入的了解,毕竟不是做相关的驱动开发,在后期学习DPDK的驱动时再做深入的理解。
1、标准模式
一般情况下,我们知道网卡往往只会接受目的地址是他的数据包而不会接受目的地址不是的它的数据包,所以我们应该知道网卡只会接受我们该接收的包而不会接受其他的地址的网络数据包。
2、混杂模式
混杂模式是指一台主机能够接受所有经过它的数据流,不论这个数据流的目的地址是不是它,它都会接受这个数据包。也就是说,混杂模式下,网卡会把所有的发往它的包全部都接收。在这种情况下,可以接收同一集线器局域网的所有数据。
0x03 链路层
1.网络收包原理
网络驱动收包大致有3种情况:
no NAPI:mac每收到一个以太网包,都会产生一个接收中断给cpu,即完全靠中断方式来收包
缺点是当网络流量很大时,cpu大部分时间都耗在了处理mac的中断。
netpoll:在网络和I/O子系统尚不能完整可用时,模拟了来自指定设备的中断,即轮询收包。
缺点是实时性差
NAPI: 采用 中断 + 轮询 的方式:mac收到一个包来后会产生接收中断,但是马上关闭。
直到收够了netdev_max_backlog个包(默认300),或者收完mac上所有包后,才再打开接收中断
通过sysctl来修改 net.core.netdev_max_backlog
或者通过proc修改 /proc/sys/net/core/netdev_max_backlog
2.内核启动时的准备工作
2.1初始化网络相关的全局数据结构和挂载相关软中断的钩子函数
start_kernel()
--> rest_init()
--> do_basic_setup()
--> do_initcall
-->net_dev_init ()
解读下net_dev_init()函数:
/*
* 初始化可以存放设备相关信息的全局数据结构,在此时设备一般还没有被初始化,
* 此函数由单一线程在 boot 的时候调用,不需要获取 rtnl 信号量
*/
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
/*...略...*/
for_each_possible_cpu(i) { //每个 CPU 有自己的一个队列
struct softnet_data *queue;
/*有一个全局变量叫 per_cpu__softnet_data,定义为
CPU 软中断(包括接收和发送)的数据队列,这个变量是
通 过 DEFINE_PER_CPU(struct softnet_data,
softnet_data) = { NULL };定义的*/
queue = &per_cpu(softnet_data, i);
skb_queue_head_init(&queue->input_pkt_queue); //初始化输入包队列
queue->completion_queue = NULL;
INIT_LIST_HEAD(&queue->poll_list);
queue->backlog.poll = process_backlog; //这个queue有一个名叫backlog_dev 的设备,其poll函数指针指向了一个叫做 process_backlog
的函数。我们设置的接收软中断(RX_SOFTIRQ)将要和这个 queue 以及 back_log 设备打交道
queue->backlog.weight = weight_p;
queue->backlog.gro_list = NULL;
queue->backlog.gro_count = 0;
}
/*...略...*/
open_softirq(NET_TX_SOFTIRQ, net_tx_action);//在软中断上挂网络发送handler
open_softirq(NET_RX_SOFTIRQ, net_rx_action);//在软中断上挂网络接收handler
hotcpu_notifier(dev_cpu_callback, 0);
dst_init(); //其中的参数是通知链 dst_dev_notifier,它在初始化过程中没有什么特别重要的用处,但是在删除设备接口的时候非常重要,因为它只响应删除事件。
dev_mcast_init();
rc = 0;
out:
return rc;
}
2.2加载网络驱动程序
我分析的网卡驱动为Ethernet controller: Advanced Micro Devices, Inc. [AMD] 79c970 [PCnet32 LANCE] (rev 10) PCI网卡驱动,此处就研究一下 PCI 网卡是如何被操控的,以此可以推断出在不同总线技术下驱动程序的实现基础
平台pci驱动结构:
static struct pci_driver pcnet32_driver = {
.name = DRV_NAME, //设备名
.probe = pcnet32_probe_pci, //设配绑定驱动,由PCI模块调用
.remove = __devexit_p(pcnet32_remove_one),
.id_table = pcnet32_pci_tbl, // 这是一个 pci_device_id{}结构的数组,必须和设备的硬件信息一致
.suspend = pcnet32_pm_suspend,
.resume = pcnet32_pm_resume,
};
其他驱动部分详细的操作,不再赘述,知识点较多,为加快对我关心的那块的学习,调过这点。
static void pcnet32_rx_entry(struct net_device *dev,
struct pcnet32_private *lp,
struct pcnet32_rx_head *rxp,
int entry)
{
int status = (short)le16_to_cpu(rxp->status) >> 8;
int rx_in_place = 0;
struct sk_buff *skb;
short pkt_len;
/* 中间略 */
dev->stats.rx_bytes += skb->len;
skb->protocol = eth_type_trans(skb, dev);
netif_receive_skb(skb); //进入协议栈
dev->stats.rx_packets++;
return;
}
2.3netif_receive_skb函数
int netif_receive_skb(struct sk_buff *skb)
{
//略去一些代码
rcu_read_lock();
//第一步:先处理 ptype_all 上所有的 packet_type->func()
//所有包都会调func,对性能影响严重!内核默认没挂任何钩子函数
list_for_each_entry_rcu(ptype, &ptype_all, list) { //遍历ptye_all链表
if (!ptype->dev || ptype->dev == skb->dev) { //上面的paket_type.type 为 ETH_P_ALL
if (pt_prev) //对所有包调用paket_type.func()
ret = deliver_skb(skb, pt_prev, orig_dev); //此函数最终调用paket_type.func()
pt_prev = ptype;
}
}
//第二步:若编译内核时选上BRIDGE,下面会执行网桥模块
//调用函数指针 br_handle_frame_hook(skb), 在动态模块 linux_2_6_24/net/bridge/br.c中
//br_handle_frame_hook = br_handle_frame;
//所以实际函数 br_handle_frame。
//注意:在此网桥模块里初始化 skb->pkt_type 为 PACKET_HOST、PACKET_OTHERHOST
skb = handle_bridge(skb, &pt_prev, &ret, orig_dev);
if (!skb) goto out;
//第三步:编译内核时选上MAC_VLAN模块,下面才会执行
//调用 macvlan_handle_frame_hook(skb), 在动态模块linux_2_6_24/drivers/net/macvlan.c中
//macvlan_handle_frame_hook = macvlan_handle_frame;
//所以实际函数为 macvlan_handle_frame。
//注意:此函数里会初始化 skb->pkt_type 为 PACKET_BROADCAST、PACKET_MULTICAST、PACKET_HOST
skb = handle_macvlan(skb, &pt_prev, &ret, orig_dev);
if (!skb) goto out;
//第四步:最后 type = skb->protocol; &ptype_base[ntohs(type)&15]
//处理ptype_base[ntohs(type)&15]上的所有的 packet_type->func()
//根据第二层不同协议来进入不同的钩子函数,重要的有:ip_rcv() arp_rcv()
type = skb->protocol;
list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&15], list) {
if (ptype->type == type && //遍历包type所对应的链表
(!ptype->dev || ptype->dev == skb->dev)) { //调用链表上所有pakcet_type.func()
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev); //就这里!arp包会调arp_rcv()
pt_prev = ptype; // ip包会调ip_rcv()
}
}
if (pt_prev) {
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
} else { //下面就是数据包从协议栈返回来了
kfree_skb(skb); //注意这句,若skb没进入socket的接收队列,则在这里被释放
ret = NET_RX_DROP; //若skb进入接收队列,则系统调用取包时skb释放,这里skb引用数减一而已
}
out:
rcu_read_unlock();
return ret;
}
int deliver_skb(struct sk_buff *skb,struct packet_type *pt_prev, struct net_device *orig_dev){
atomic_inc(&skb->users);
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);//调函数ip_rcv() arp_rcv()等
}
重要数据结构:
内核处理网络第二层,有下面2个重要list_head变量 (文件linux_2_6_24/net/core/dev.c)
list_head 链表上挂了很多packet_type数据结构
static struct list_head ptype_base[16] __read_mostly; /* 16 way hashed list */
static struct list_head ptype_all __read_mostly; /* Taps */
struct packet_type {
__be16 type; /* 成员保存了二层协议类型,ETH_P_IP、ETH_P_ARP等等*/
struct net_device *dev; /* NULL is wildcarded here */
int (*func) (struct sk_buff *,
struct net_device *,
struct packet_type *,
struct net_device *); /*成员就是钩子函数了,如 ip_rcv()、arp_rcv()等等*/
struct sk_buff *(*gso_segment)(struct sk_buff *skb, int features);
int (*gso_send_check)(struct sk_buff *skb);
void *af_packet_priv;
struct list_head list;
};
操作API:
void dev_add_pack(struct packet_type *pt); //在每层协议初始化时调用
void dev_remove_pack(struct packet_type *pt);
如下是arp_rcv()过程:
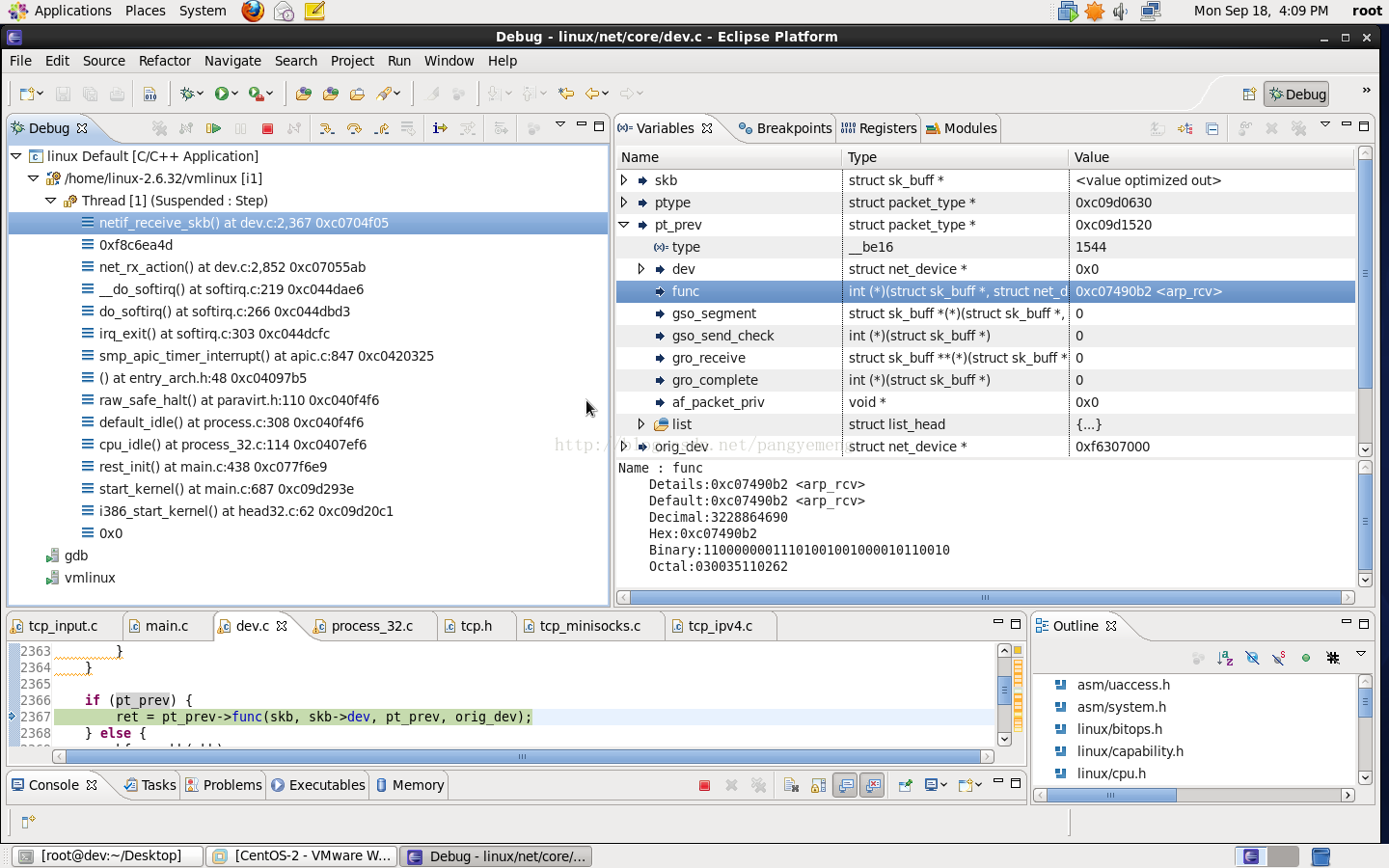
ip_rcv:
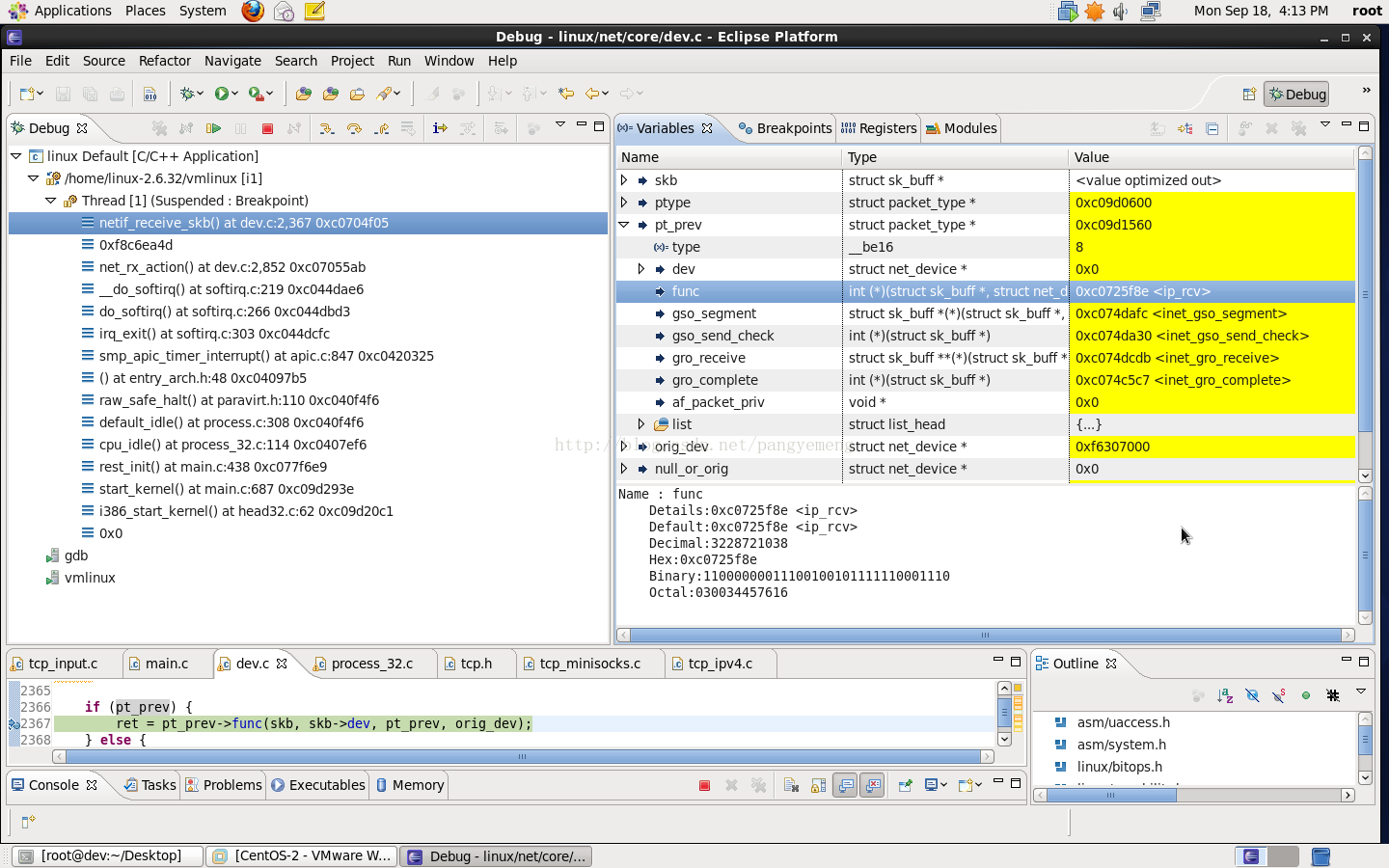
0x04 总结
本节主要了解了pci网卡驱动注册和初始化过程,产生软中断后进行协议栈的过程,期间学习了一些关键数据结构。下一章节了解arp_rcv的过程。(大神勿喷,学习过程,多指点)
最后
以上就是孝顺皮皮虾最近收集整理的关于tcp/ip协议栈-驱动到应用0x01 缘由0x02 物理层0x03 链路层0x04 总结的全部内容,更多相关tcp/ip协议栈-驱动到应用0x01内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复