CART算法
- 引言
- 1、概述
- 2、CART算法
- 2.1 CART生成
- 2.1.1 回归树的生成
- 2.1.2 分类树的生成
- 2.2 CART剪枝
- 2.2.1 剪枝,形成一个子树序列
- 2.2.2 在剪枝得到的子树序列 T 0 , T 1 , T 2 , T 3 . . . . . . T n T_0,T_1,T_2,T_3......T_n T0,T1,T2,T3......Tn中通过交叉验证选取最优子树 T α T_alpha Tα
- 2.2.3 CART剪枝算法
- 3、基于scikit-learn决策树算法类库实现CART算法
- 3.1 scikit-learn决策树算法类库概述
- 3.2 实战1—分类树
- 3.3 实战2—回归树
- 4、决策树算法小结
引言
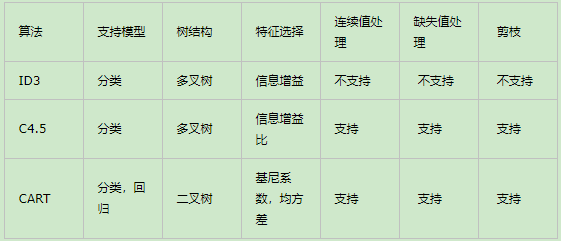
quad quad 在决策树、ID3、C4.5算法一文中,简单地介绍了决策树模型,以及决策树生成算法ID3算法和ID3算法的改进版C4.5算法;在决策时剪枝算法一文中,简单地介绍了剪枝的算法。我们也提到了它的不足,比如模型是用较为复杂的熵来度量,使用了相对较为复杂的多叉树,只能处理分类不能处理回归等。对于这些问题, CART算法大部分做了改进。CART算法也就是我们下面的重点了。由于CART算法可以做回归,也可以做分类,我们分别加以介绍,先从CART分类树算法开始,重点比较和C4.5算法的不同点。接着介绍CART回归树算法,重点介绍和CART分类树的不同点。然后我们讨论CART树的建树算法和剪枝算法,最后总结决策树算法的优缺点。
1、概述
quad quad 所谓CART算法,全名叫Classification and Regression Tree,即分类与回归树。顾名思义,相较于此前的ID3算法和C4.5算法,CART除了可以用于分类任务外,还可以完成回归分析。完整的CART算法包括特征选择、决策树生成和决策树剪枝三个部分。
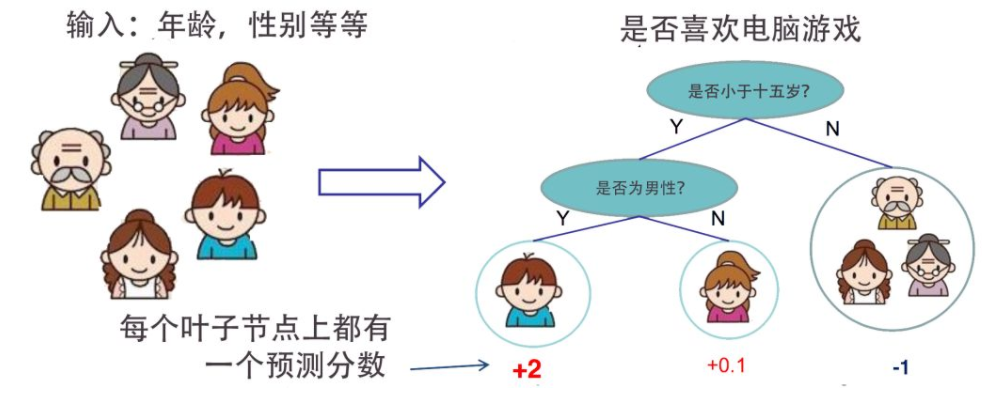
quad quad 有以下特点:
(1)CART是一棵二叉树;
(2)CART算法主要包括回归树和分类树两种。回归树用于目标变量为连续型的建模任务,其特征选择准则用的是平方误差最小准则。分类树用于目标变量为离散型的的建模任务,其特征选择准则用的是基尼指数(Gini Index),这也有别于此前ID3的信息增益准则和C4.5的信息增益比准则。无论是回归树还是分类树,其算法核心都在于递归地选择最优特征构建决策树。
(3)CART作为一种单模型,也是GBDT的基模型。当很多棵CART分类树或者回归树集成起来的时候,就形成了GBDT模型。关于GBDT,笔者将在后续中进行详细讲述,这里不再展开。
2、CART算法
quad quad
CART算法由以下两步生成:
(1)决策树生成:递归地构建二叉决策树的过程,基于训练数据集生成决策树,生成的决策树要尽量大;自上而下从根开始建立节点,在每个节点处要选择一个最好的属性来分裂,使得子节点中的训练集尽量的纯。不同的算法使用不同的指标来定义"最好"。
(2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。【剪枝可以视为决策树算法的一种正则化手段,作为一种基于规则的非参数监督学习方法,决策树在训练很容易过拟合,导致最后生成的决策树泛化性能不高。】
2.1 CART生成
quad quad CART算法的决策树生成实现过程如下:
-
使用CART算法选择特征
- 对回归树用平方误差最小化准测,进行特征选择;
- 对分类树用基尼指数(GINI)最小化准则,进行特征选择,
-
根据特征切分数据集合
-
构建树
【代码实现】简单例子:根据特征切分数据集合
import numpy as np
# 函数说明:根据给定特征和特征值,将数据集分为两个区域
"""
Parameters:
dataSet - 数据集合
feature - 待切分的特征
value - 特征的某个值
Returns:
mat0-切分的数据集合0
mat1-切分的数据集1
"""
def binSplitDataSet(dataSet,feature,value):
mat0=dataSet[np.nonzero(dataSet[:,feature]>value)[0],:]
mat1=dataSet[np.nonzero(dataSet[:,feature]<=value)[0],:]
return mat0,mat1
if __name__=='__main__':
testMat=np.mat(np.eye(4))
mat0,mat1=binSplitDataSet(testMat,1,0.5)
mat0, mat1 = binSplitDataSet(testMat, 1, 0.5)
print("原始集合:n", testMat)
print("mat0:n", mat0)
print("mat1:n", mat1)
原始集合:
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
mat0:
[[0. 1. 0. 0.]]
mat1:
[[1. 0. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
2.1.1 回归树的生成
划分的准则是平方误差最小化
quad quad
假设X与Y分别为输入和输出变量,并且Y是连续变量,给定训练数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
n
)
}
D={(x_1,y_1),(x_2,y_2),...,(x_N,y_n)}
D={(x1,y1),(x2,y2),...,(xN,yn)}
假定已将输入空间划分为M个单元
R
1
,
R
2
,
.
.
.
,
R
M
R_1,R_2,...,R_M
R1,R2,...,RM,并且在每个单元
R
M
R_M
RM上有一个固定的输出值
c
m
c_m
cm,则
回归模型:
f
(
x
)
=
∑
m
=
1
M
c
m
I
(
x
∈
R
m
)
f(x)=sum_{m=1}^Mc_mI(xin R_m)
f(x)=m=1∑McmI(x∈Rm)
预测误差:平方误差
∑
x
i
∈
R
m
(
y
i
−
f
(
x
i
)
)
2
sum_{x_iin R_m}(y_i-f(x_i))^2
xi∈Rm∑(yi−f(xi))2
如何选择每一个单元上的最优输出值 c m c_m cm?
quad quad
用平方误差最小的准则求解每个单元上的最优输出值得单元
R
M
R_M
RM上的
c
m
c_m
cm的最优值
c
m
^
hat{c_m}
cm^是
R
M
R_M
RM上的所有输入实例
x
i
x_i
xi对应的输出
y
i
y_i
yi的均值,即
c
m
^
=
a
v
e
(
y
i
∣
x
i
∈
R
m
)
hat{c_m}=ave(y_i|x_iin R_m)
cm^=ave(yi∣xi∈Rm)
如何对输入空间进行划分?
quad quad
采用启发式即二元切分的方法,假设选择第j个变量
x
(
j
)
x^{(j)}
x(j)和它的取值s,作为切分变量和切分点,那么就会得到两个区域:
R
1
(
j
,
s
)
=
{
x
∣
x
(
j
)
≤
s
}
和
R
2
(
j
,
s
)
=
{
x
∣
x
(
j
)
>
s
}
R_1(j,s)={x|x^{(j)}leq s} 和 R_2(j,s)={x|x^{(j)}> s}
R1(j,s)={x∣x(j)≤s} 和 R2(j,s)={x∣x(j)>s}
当j和s固定时,我们要找到两个区域的代表值c1,c2使各自区间上的平方差最小:
m
i
n
j
,
s
[
m
i
n
c
1
∑
x
i
∈
R
1
(
j
,
s
)
(
y
i
−
c
1
)
2
+
m
i
n
c
2
∑
x
i
∈
R
2
(
j
,
s
)
(
y
i
−
c
2
)
2
]
mathop{min}limits_{j,s}[mathop{min}limits_{c_1}sum_{x_iin R_1(j,s)}(y_i-c_1)^2+mathop{min}limits_{c_2}sum_{x_iin R_2(j,s)}(y_i-c_2)^2]
j,smin[c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2]
前面已经知道c1,c2为区间上的平均:
c
1
^
=
a
v
e
(
y
i
∣
x
i
∈
R
1
(
j
,
s
)
)
和
c
2
^
=
a
v
e
(
y
i
∣
x
i
∈
R
2
(
j
,
s
)
)
hat{c_1}=ave(y_i|x_iin R_1(j,s)) 和 hat{c_2}=ave(y_i|x_iin R_2(j,s))
c1^=ave(yi∣xi∈R1(j,s)) 和 c2^=ave(yi∣xi∈R2(j,s))
那么对固定的 j 只需要找到最优的s,然后通过遍历所有的变量,我们可以找到最优的j,这样我们就可以得到最优对(j,s),并得到两个区间。
quad quad
这样的回归树通常称为最小二乘回归树。算法具体流程如下:
算法5.5 (最小二乘回归树生成算法)
输入:训练数据集D
输出:回归树 f ( x ) f(x) f(x)
quad quad 在训练数据集所在的输入空间中,递归地将每一个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
(1)选择最优切分变量 j 和切分点 s,求解
m i n j , s [ m i n c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + m i n c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] mathop{min}limits_{j,s}[mathop{min}limits_{c_1}sum_{x_iin R_1(j,s)}(y_i-c_1)^2+mathop{min}limits_{c_2}sum_{x_iin R_2(j,s)}(y_i-c_2)^2] j,smin[c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2]
遍历变量j,对固定的切分变量j扫描切分点s,选择使上式达到最小值的对(j,s)
(2)用选定的对 (j,s) 划分区域,并决定相应的输出值 c:
R 1 ( j , s ) = { x ∣ x ( j ) ≤ s } , R 2 ( j , s ) = { x ∣ x ( j ) > s } c m ^ = 1 N m ∑ x i ∈ R m ( j , s ) y i x ∈ R m , m = 1 , 2 R_1(j,s)={x|x^{(j)}leq s} , R_2(j,s)={x|x^{(j)}> s}\ hat{c_m}=frac{1}{N_m}sum_{x_iin R_m(j,s)}y_i,xin R_m,m=1,2 R1(j,s)={x∣x(j)≤s} , R2(j,s)={x∣x(j)>s}cm^=Nm1xi∈Rm(j,s)∑yix∈Rm,m=1,2
(3)继续对两个子区域调用步骤(1)(2),直至满足停止条件。
(4)将输入空间划分为M个区域 R 1 , R 2 , . . . , R M R_1,R_2,...,R_M R1,R2,...,RM,生成决策树:
f ( x ) = ∑ m = 1 M c m ^ I ( x ∈ R m ) f(x)=sum_{m=1}^Mhat{c_m}I(xin R_m) f(x)=m=1∑Mcm^I(x∈Rm)
quad quad 除此之外,我们再定义两个参数,tolS和tolN,分别用于控制误差变化限制和切分特征最少样本数。这两个参数的意义是什么呢?就是防止过拟合,提前设置终止条件,实际上是在进行一种所谓的预剪枝(prepruning)操作,在下一小节会进行进一步讲解。
【python代码实现CART回归树】
1、创建小数据集并可视化
#-*- coding:utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
def loadDataSet(fileName):
"""
函数说明:加载数据
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
"""
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('t')
fltLine = list(map(float, curLine)) #转化为float类型
dataMat.append(fltLine)
return dataMat
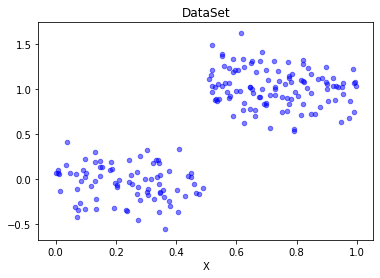
def plotDataSet(filename):
"""
函数说明:绘制数据集
Parameters:
filename - 文件名
Returns:
无
"""
dataMat = loadDataSet(filename) #加载数据集
n = len(dataMat) #数据个数
xcord = []; ycord = [] #样本点
for i in range(n):
xcord.append(dataMat[i][0]); ycord.append(dataMat[i][1]) #样本点
fig = plt.figure()
ax = fig.add_subplot(111) #添加subplot
ax.scatter(xcord, ycord, s = 20, c = 'blue',alpha = .5) #绘制样本点
plt.title('DataSet') #绘制title
plt.xlabel('X')
plt.show()
if __name__ == '__main__':
filename = 'E:jupyter-notebookCARTdata.txt'
plotDataSet(filename)
2、找到最佳切分函数
#-*- coding:utf-8 -*-
import numpy as np
def loadDataSet(fileName):#加载数据集
"""
函数说明:加载数据
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
"""
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('t')
fltLine = list(map(float, curLine)) #转化为float类型
dataMat.append(fltLine)
return dataMat
def binSplitDataSet(dataSet, feature, value):# 二元法划分数据集
"""
函数说明:根据特征切分数据集合
Parameters:
dataSet - 数据集合
feature - 带切分的特征
value - 该特征的值
Returns:
mat0 - 切分的数据集合0
mat1 - 切分的数据集合1
"""
mat0 = dataSet[np.nonzero(dataSet[:,feature] > value)[0],:]
mat1 = dataSet[np.nonzero(dataSet[:,feature] <= value)[0],:]
return mat0, mat1
def regLeaf(dataSet):
"""
函数说明:生成叶结点
Parameters:
dataSet - 数据集合
Returns:
目标变量的均值
"""
return np.mean(dataSet[:,-1])
def regErr(dataSet):
"""
函数说明:误差估计函数
Parameters:
dataSet - 数据集合
Returns:
目标变量的总方差
"""
return np.var(dataSet[:,-1]) * np.shape(dataSet)[0]
def chooseBestSplit(dataSet, leafType = regLeaf, errType = regErr, ops = (1,4)):
"""
函数说明:找到数据的最佳二元切分方式函数
Parameters:
dataSet - 数据集合
leafType - 生成叶结点
regErr - 误差估计函数
ops - 用户定义的参数构成的元组
Returns:
bestIndex - 最佳切分特征
bestValue - 最佳特征值
"""
import types
#tolS允许的误差下降值,tolN切分的最少样本数
tolS = ops[0]; tolN = ops[1]
#如果当前所有值相等,则退出。(根据set的特性)
if len(set(dataSet[:,-1].T.tolist()[0])) == 1:
return None, leafType(dataSet)
#统计数据集合的行m和列n
m, n = np.shape(dataSet)
#默认最后一个特征为最佳切分特征,计算其误差估计
S = errType(dataSet)
#分别为最佳误差,最佳特征切分的索引值,最佳特征值
bestS = float('inf'); bestIndex = 0; bestValue = 0
#遍历所有特征列
for featIndex in range(n - 1):
#遍历所有特征值
for splitVal in set(dataSet[:,featIndex].T.A.tolist()[0]):
#根据特征和特征值切分数据集
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
#如果数据少于tolN,则退出
if (np.shape(mat0)[0] < tolN) or (np.shape(mat1)[0] < tolN): continue
#计算误差估计
newS = errType(mat0) + errType(mat1)
#如果误差估计更小,则更新特征索引值和特征值
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
#如果误差减少不大则退出
if (S - bestS) < tolS:
return None, leafType(dataSet)
#根据最佳的切分特征和特征值切分数据集合
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
#如果切分出的数据集很小则退出
if (np.shape(mat0)[0] < tolN) or (np.shape(mat1)[0] < tolN):
return None, leafType(dataSet)
#返回最佳切分特征和特征值
return bestIndex, bestValue
if __name__ == '__main__':
myDat = loadDataSet('E:jupyter-notebookCARTdata.txt')
myMat = np.mat(myDat)
feat, val = chooseBestSplit(myMat, regLeaf, regErr, (1, 4))
print(feat)
print(val)
3、创建回归树
#-*- coding:utf-8 -*-
import numpy as np
def loadDataSet(fileName):
"""
函数说明:加载数据
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
"""
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('t')
fltLine = list(map(float, curLine)) #转化为float类型
dataMat.append(fltLine)
return dataMat
def binSplitDataSet(dataSet, feature, value):
"""
函数说明:根据特征切分数据集合
Parameters:
dataSet - 数据集合
feature - 带切分的特征
value - 该特征的值
Returns:
mat0 - 切分的数据集合0
mat1 - 切分的数据集合1
"""
mat0 = dataSet[np.nonzero(dataSet[:,feature] > value)[0],:]
mat1 = dataSet[np.nonzero(dataSet[:,feature] <= value)[0],:]
return mat0, mat1
def regLeaf(dataSet):
"""
函数说明:生成叶结点
Parameters:
dataSet - 数据集合
Returns:
目标变量的均值
"""
return np.mean(dataSet[:,-1])
def regErr(dataSet):
"""
函数说明:误差估计函数
Parameters:
dataSet - 数据集合
Returns:
目标变量的总方差
"""
return np.var(dataSet[:,-1]) * np.shape(dataSet)[0]
def chooseBestSplit(dataSet, leafType = regLeaf, errType = regErr, ops = (1,4)):
"""
函数说明:找到数据的最佳二元切分方式函数
Parameters:
dataSet - 数据集合
leafType - 生成叶结点
regErr - 误差估计函数
ops - 用户定义的参数构成的元组
Returns:
bestIndex - 最佳切分特征
bestValue - 最佳特征值
"""
import types
#tolS允许的误差下降值,tolN切分的最少样本数
tolS = ops[0]; tolN = ops[1]
#如果当前所有值相等,则退出。(根据set的特性)
if len(set(dataSet[:,-1].T.tolist()[0])) == 1:
return None, leafType(dataSet)
#统计数据集合的行m和列n
m, n = np.shape(dataSet)
#默认最后一个特征为最佳切分特征,计算其误差估计
S = errType(dataSet)
#分别为最佳误差,最佳特征切分的索引值,最佳特征值
bestS = float('inf'); bestIndex = 0; bestValue = 0
#遍历所有特征列
for featIndex in range(n - 1):
#遍历所有特征值
for splitVal in set(dataSet[:,featIndex].T.A.tolist()[0]):
#根据特征和特征值切分数据集
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
#如果数据少于tolN,则退出
if (np.shape(mat0)[0] < tolN) or (np.shape(mat1)[0] < tolN): continue
#计算误差估计
newS = errType(mat0) + errType(mat1)
#如果误差估计更小,则更新特征索引值和特征值
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
#如果误差减少不大则退出
if (S - bestS) < tolS:
return None, leafType(dataSet)
#根据最佳的切分特征和特征值切分数据集合
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
#如果切分出的数据集很小则退出
if (np.shape(mat0)[0] < tolN) or (np.shape(mat1)[0] < tolN):
return None, leafType(dataSet)
#返回最佳切分特征和特征值
return bestIndex, bestValue
def createTree(dataSet, leafType = regLeaf, errType = regErr, ops = (1, 4)):
"""
函数说明:树构建函数
Parameters:
dataSet - 数据集合
leafType - 建立叶结点的函数
errType - 误差计算函数
ops - 包含树构建所有其他参数的元组
Returns:
retTree - 构建的回归树
"""
#选择最佳切分特征和特征值
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)
#r如果没有特征,则返回特征值
if feat == None: return val
#回归树
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
#分成左数据集和右数据集
lSet, rSet = binSplitDataSet(dataSet, feat, val)
#创建左子树和右子树
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree
if __name__ == '__main__':
myDat = loadDataSet('E:jupyter-notebookCARTdata.txt')
myMat = np.mat(myDat)
print(createTree(myMat))
{‘spInd’: 0, ‘spVal’: 0.48813, ‘left’: 1.0180967672413792, ‘right’: -0.04465028571428572}
2.1.2 分类树的生成
分类树用基尼指数选择最优特征,同时决定该特征的最优二值切分点。
定义(基尼指数):
quad quad
分类问题中,假设有
K
K
K个类别,样本点属于第
k
k
k类别的概率为
p
k
p_k
pk, 则概率分布的基尼指数定义为:
G
i
n
i
(
p
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
K
p
k
2
Gini(p)=sum_{k=1}^{K}p_k(1-p_k)=1-sum_{k=1}^{K}p_k^2
Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
quad quad
对于二分类问题,若样本点属于第1个类的概率是p,则概率分布的基尼指数为
G
i
n
i
(
p
)
=
2
p
(
1
−
p
)
Gini(p)=2p(1-p)
Gini(p)=2p(1−p)
quad quad
对于给定的样本集合
D
D
D,假设有
K
K
K个类别, 第k个类别的数量为
C
k
C_k
Ck,则样本D的基尼系数表达式为:
G
i
n
i
(
D
)
=
1
−
∑
k
=
1
K
(
∣
C
k
∣
∣
D
∣
)
2
Gini(D)=1-sum_{k=1}^{K}(frac{|C_k|}{|D|})^2
Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
quad quad 特别的,对于样本 D D D,如果根据特征 A A A的某个值a,把 D D D分成 D 1 D_1 D1和 D 2 D_2 D2两部分,则在特征 A A A的条件下, D D D的基尼指数表达式为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A)=frac{|D_1|}{|D|}Gini(D_1)+frac{|D_2|}{|D|}Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
quad quad 基尼指数 G i n i ( D ) Gini(D) Gini(D)表示集合 D D D的不确定性,基尼指数 G i n i ( D , A ) Gini(D,A) Gini(D,A)表示经 A = a A=a A=a分割后集合 D D D的不确定性。基尼指数越大,样本集合的不确定性也就越大,这一点与熵相似。
quad quad
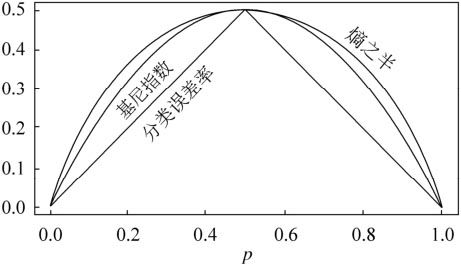
对于二类分类,基尼指数和熵之半以及分类误差率的曲线如下:
quad quad
从上图可以看出,基尼系数和熵之半的曲线非常接近,仅仅在45度角附近误差稍大。因此,基尼系数可以做为熵模型的一个近似替代。而CART分类树算法就是使用的基尼系数来选择决策树的特征。同时,为了进一步简化,CART分类树算法每次仅仅对某个特征的值进行二分,而不是多分,这样CART分类树算法建立起来的是二叉树,而不是多叉树。这样一可以进一步简化基尼系数的计算,二可以建立一个更加优雅的二叉树模型。
quad quad 分类树生成算法具体如下:
输入:训练数据集,停止计算的条件
输出:CART决策树即分类树
根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树
(1)训练数据集为D,计算现有特征对训练数据集的基尼指数,此时对于每一个特征A,对其可能取得每一个值a,根据此值将训练样本切分为 D 1 D_1 D1和 D 2 D_2 D2两部分,然后根据上式计算A=a基尼指数。
(2)在所有可能的特征A以及所有可能的切分点a中,选择基尼指数最小的特征及其对应的切分点作为最优的特征及切分点,从结点生成两个子结点,将训练数据集分配到子结点中去。
(3)递归的调用(1 ),(2), 直到满足停止的条件
(4)生成分类决策树
quad quad 算法停止计算的条件是节点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类),或者没有更多特征。
【python手写实现CART分类树】
from math import log
import operator
def createDataSet1():
"""
创造示例数据/读取数据
@param dataSet: 数据集
@return dataSet labels:数据集 特征集
"""
# 数据集
dataSet = [('青年', '否', '否', '一般', '不同意'),
('青年', '否', '否', '好', '不同意'),
('青年', '是', '否', '好', '同意'),
('青年', '是', '是', '一般', '同意'),
('青年', '否', '否', '一般', '不同意'),
('中年', '否', '否', '一般', '不同意'),
('中年', '否', '否', '好', '不同意'),
('中年', '是', '是', '好', '同意'),
('中年', '否', '是', '非常好', '同意'),
('中年', '否', '是', '非常好', '同意'),
('老年', '否', '是', '非常好', '同意'),
('老年', '否', '是', '好', '同意'),
('老年', '是', '否', '好', '同意'),
('老年', '是', '否', '非常好', '同意'),
('老年', '否', '否', '一般', '不同意')]
# 特征集
labels = ['年龄', '有工作', '有房子', '信贷情况']
return dataSet,labels
def calcProbabilityEnt(dataSet):
"""
样本点属于第1个类的概率p,即计算2p(1-p)中的p
@param dataSet: 数据集
@return probabilityEnt: 数据集的概率
"""
numEntries = len(dataSet) # 数据条数
feaCounts = 0
fea1 = dataSet[0][len(dataSet[0]) - 1]
for featVec in dataSet: # 每行数据
if featVec[-1] == fea1:
feaCounts += 1
probabilityEnt = float(feaCounts) / numEntries
return probabilityEnt
def splitDataSet(dataSet, index, value):
"""
划分数据集,提取含有某个特征的某个属性的所有数据
@param dataSet: 数据集
@param index: 属性值所对应的特征列
@param value: 某个属性值
@return retDataSet: 含有某个特征的某个属性的数据集
"""
retDataSet = []
for featVec in dataSet:
# 如果该样本该特征的属性值等于传入的属性值,则去掉该属性然后放入数据集中
if featVec[index] == value:
reducedFeatVec = featVec[:index] + featVec[index+1:] # 去掉该属性的当前样本
retDataSet.append(reducedFeatVec) # append向末尾追加一个新元素,新元素在元素中格式不变,如数组作为一个值在元素中存在
return retDataSet
def chooseBestFeatureToSplit(dataSet):
"""
选择最优特征
@param dataSet: 数据集
@return bestFeature: 最优特征所在列
"""
numFeatures = len(dataSet[0]) - 1 # 特征总数
if numFeatures == 1: # 当只有一个特征时
return 0
bestGini = 1 # 最佳基尼系数
bestFeature = -1 # 最优特征
for i in range(numFeatures):
uniqueVals = set(example[i] for example in dataSet) # 去重,每个属性值唯一
feaGini = 0 # 定义特征的值的基尼系数
# 依次计算每个特征的值的熵
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value) # 根据该特征属性值分的类
# 参数:原数据、循环次数(当前属性值所在列)、当前属性值
prob = len(subDataSet) / float(len(dataSet))
probabilityEnt = calcProbabilityEnt(subDataSet)
feaGini += prob * (2 * probabilityEnt * (1 - probabilityEnt))
if (feaGini < bestGini): # 基尼系数越小越好
bestGini = feaGini
bestFeature = i
return bestFeature
def majorityCnt(classList):
"""
对最后一个特征分类,出现次数最多的类即为该属性类别,比如:最后分类为2男1女,则判定为男
@param classList: 数据集,也是类别集
@return sortedClassCount[0][0]: 该属性的类别
"""
classCount = {}
# 计算每个类别出现次数
for vote in classList:
try:
classCount[vote] += 1
except KeyError:
classCount[vote] = 1
sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse = True) # 出现次数最多的类别在首位
# 对第1个参数,按照参数的第1个域来进行排序(第2个参数),然后反序(第3个参数)
return sortedClassCount[0][0] # 该属性的类别
def createTree(dataSet,labels):
"""
对最后一个特征分类,按分类后类别数量排序,比如:最后分类为2同意1不同意,则判定为同意
@param dataSet: 数据集
@param labels: 特征集
@return myTree: 决策树
"""
classList = [example[-1] for example in dataSet] # 获取每行数据的最后一个值,即每行数据的类别
# 当数据集只有一个类别
if classList.count(classList[0]) == len(classList):
return classList[0]
# 当数据集只剩一列(即类别),即根据最后一个特征分类
if len(dataSet[0]) == 1:
return majorityCnt(classList)
# 其他情况
bestFeat = chooseBestFeatureToSplit(dataSet) # 选择最优特征(所在列)
bestFeatLabel = labels[bestFeat] # 最优特征
del(labels[bestFeat]) # 从特征集中删除当前最优特征
uniqueVals = set(example[bestFeat] for example in dataSet) # 选出最优特征对应属性的唯一值
myTree = {bestFeatLabel:{}} # 分类结果以字典形式保存
for value in uniqueVals:
subLabels = labels[:] # 深拷贝,拷贝后的值与原值无关(普通复制为浅拷贝,对原值或拷贝后的值的改变互相影响)
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels) # 递归调用创建决策树
return myTree
if __name__ == '__main__':
dataSet, labels = createDataSet1() # 创造示列数据
print(createTree(dataSet, labels)) # 输出决策树模型结果
2.2 CART剪枝
quad quad 由于决策时算法很容易对训练集过拟合,而导致泛化能力差,为了解决这个问题,我们需要对CART树进行剪枝,即类似于线性回归的正则化,来增加决策树的泛化能力。但是,有很多的剪枝方法,我们应该这么选择呢?CART采用的办法是后剪枝法,即先生成决策树,然后产生所有可能的剪枝后的CART树,然后使用交叉验证来检验各种剪枝的效果,选择泛化能力最好的剪枝策略。
quad quad CART回归树和CART分类树的剪枝策略除了在度量损失的时候一个使用均方差,一个使用基尼系数,算法基本完全一样。
quad quad CART剪枝算法由两步组成:
-
首先从生成算法产生的决策树 T 0 T_0 T0底端开始不断的剪枝,直到 T 0 T_0 T0的根结点,形成子树序列 { T 0 , T 1 , T 2 , T 3 . . . . . . T n } {T_0,T_1,T_2,T_3......T_n} {T0,T1,T2,T3......Tn} T 0 T_0 T0就是没剪的,T1就是剪了一个叶结点的,T2就是又剪了一点的这样子哦!
-
然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树,具体操作如下。
2.2.1 剪枝,形成一个子树序列
quad quad
在剪枝的过程中,对于任意的一刻子树T,其损失函数为:
C
α
(
T
)
=
C
(
T
)
+
α
∣
T
∣
C_alpha(T)=C(T)+alpha|T|
Cα(T)=C(T)+α∣T∣
quad quad
其中,
T
T
T为任意子树,C(T)为训练数据的预测误差,分类树是用基尼系数度量,回归树是均方差度量,
∣
T
∣
|T|
∣T∣为子树的叶节点个数,
α
≥
0
alphageq0
α≥0为正则化参数,权衡训练数据的拟合程度与模型的复杂度。
quad quad
当α=0时,即没有正则化,原始的生成的CART树即为最优子树。当α=∞时,即正则化强度达到最大,此时由原始的生成的CART树的根节点组成的单节点树为最优子树。当然,这是两种极端情况。一般来说,α越大,则剪枝剪的越厉害,生成的最优子树相比原生决策树就越偏小。对于固定的α,一定存在使损失函数
C
α
(
T
)
C_α(T)
Cα(T)最小的唯一子树。
剪枝的思路:
quad quad
可以用递归的方法对树进行剪枝。将
α
alpha
α从小增大,
0
=
α
0
<
α
1
<
.
.
.
<
α
n
<
+
∞
0=alpha_0<alpha_1<...<alpha_n<+∞
0=α0<α1<...<αn<+∞,产生一系列的区间
[
α
i
,
α
i
+
1
)
,
i
=
0
,
1
,
.
.
.
,
n
[alpha_i,alpha_{i+1}),i=0,1,...,n
[αi,αi+1),i=0,1,...,n;剪枝得到的子树序列对应着区间
α
∈
[
α
i
,
α
i
+
1
)
,
i
=
0
,
1
,
.
.
.
,
n
alphain[alpha_i,alpha_{i+1}),i=0,1,...,n
α∈[αi,αi+1),i=0,1,...,n的最优子树序列
{
T
0
,
T
1
,
.
.
.
,
T
n
}
{T_0,T_1,...,T_n}
{T0,T1,...,Tn},序列中的子树是嵌套的。
quad quad 具体地,从整体数 T 0 T_0 T0开始剪枝。
- 对
T
0
T_0
T0的任意内部结点t,以t为单结点树的损失函数为
C α ( t ) = C ( t ) + α C_alpha(t)=C(t)+alpha Cα(t)=C(t)+α - 以t为根节点的子树
T
t
T_t
Tt的损失函数是
C α ( T t ) = C ( T t ) + α ∣ T t ∣ C_alpha(T_t)=C(T_t)+alpha|T_t| Cα(Tt)=C(Tt)+α∣Tt∣ - 当α=0或者α很小时,
C
α
(
T
t
)
<
C
α
(
t
)
C_α(T_t)<C_α(t)
Cα(Tt)<Cα(t) , 当α增大到一定的程度时,在某一
α
alpha
α有
C α ( T t ) = C α ( t ) C_α(T_t)=C_α(t) Cα(Tt)=Cα(t)
当α继续增大时不等式反向,也就是说,如果满足下式:
α
=
C
(
T
)
−
C
(
T
t
)
∣
T
t
∣
−
1
α=frac{C(T)−C(T_t)}{|T_t|−1}
α=∣Tt∣−1C(T)−C(Tt)
T
t
T_t
Tt和t有相同的损失函数,但是t节点更少,因此t比
T
t
T_t
Tt更可取,对
T
t
T_t
Tt进行剪枝。
quad quad
为此,对
T
0
T_0
T0中每一内部结点t,计算
g
(
t
)
=
C
(
T
)
−
C
(
T
t
)
∣
T
t
∣
−
1
g(t)=frac{C(T)−C(T_t)}{|T_t|−1}
g(t)=∣Tt∣−1C(T)−C(Tt)
它表示剪枝后整体损失函数减少的程度。在
T
0
T_0
T0中剪去
g
(
t
)
g(t)
g(t)最小的
T
t
T_t
Tt,将得到的子树作为
T
1
T_1
T1,同时将最小的
g
(
t
)
g(t)
g(t)设为
α
1
alpha_1
α1。
T
1
T_1
T1为区间
[
α
1
,
α
2
)
[alpha_1,alpha_2)
[α1,α2)的最优子树。
quad quad 如此剪枝下去,直至得到根结点。在这一过程中,不断地增加 α alpha α的值,产生新的区间。
2.2.2 在剪枝得到的子树序列 T 0 , T 1 , T 2 , T 3 . . . . . . T n T_0,T_1,T_2,T_3......T_n T0,T1,T2,T3......Tn中通过交叉验证选取最优子树 T α T_alpha Tα
quad quad 利用平方误差准则或者是基尼指数准则,在新的验证集中分别测试子树序列,选取里面最优的子树进行输出,便是裁剪之后的子树,即得到最优决策树
2.2.3 CART剪枝算法
算法 5.7 (CART 剪枝算法)
输入:CART算法生成的决策树
输出:最优决策树 T α T_alpha Tα
(1)设 k = 0 k=0 k=0, T = T 0 T=T_0 T=T0
(2)设 α = + ∞ alpha=+∞ α=+∞(正无穷)
(3)自下而上的对内部结点t进行计算 C ( T t ) C(T_t) C(Tt), ∣ T t ∣ |T_t| ∣Tt∣和 g ( t ) = C ( t ) − C ( T t ) ∣ T t ∣ − 1 , α = m i n ( α , g ( t ) ) g(t)=frac{C(t)-C(T_{t})}{|T_{t}|-1},alpha=min(alpha,g(t)) g(t)=∣Tt∣−1C(t)−C(Tt),α=min(α,g(t))
其中, T t T_t Tt表示以t为根结点的子树, C ( T t ) C(T_t) C(Tt)是对训练数据的预测误差, ∣ T t ∣ |T_t| ∣Tt∣是 T t T_t Tt的叶结点个数。
(4)自上而下地访问内部结点t,如果有 g ( t ) = α g(t)=alpha g(t)=α的内部结点,则进行剪枝,并对叶结点t以多数表决法决定其类,得到树T
(5) 设 k = k + 1 , α k = α , T k = T k=k+1,alpha_k=alpha,T_k=T k=k+1,αk=α,Tk=T
(6 )如果T不是由根结点单独构成的树,回到步骤4,
(7 )采用交叉验证法在子树序列上进行验证选取最优子树 T α T_alpha Tα
# -*- coding: utf-8 -*-
import numpy as np
import pickle
import treePlotter
def loadDataSet(filename):
'''
输入:文件的全路径
功能:将输入数据保存在datamat
输出:datamat
'''
fr = open(filename)
datamat = []
for line in fr.readlines():
cutLine = line.strip().split('t')
floatLine = map(float,cutLine)
datamat.append(floatLine)
return datamat
def binarySplitDataSet(dataset,feature,value):
'''
输入:数据集,数据集中某一特征列,该特征列中的某个取值
功能:将数据集按特征列的某一取值换分为左右两个子数据集
输出:左右子数据集
'''
matLeft = dataset[np.nonzero(dataset[:,feature] <= value)[0],:]
matRight = dataset[np.nonzero(dataset[:,feature] > value)[0],:]
return matLeft,matRight
#--------------回归树所需子函数---------------#
def regressLeaf(dataset):
'''
输入:数据集
功能:求数据集输出列的均值
输出:对应数据集的叶节点
'''
return np.mean(dataset[:,-1])
def regressErr(dataset):
'''
输入:数据集(numpy.mat类型)
功能:求数据集划分左右子数据集的误差平方和之和
输出: 数据集划分后的误差平方和
'''
#由于回归树中用输出的均值作为叶节点,所以在这里求误差平方和实质上就是方差
return np.var(dataset[:,-1]) * np.shape(dataset)[0]
def regressData(filename):
fr = open(filename)
return pickle.load(fr)
#--------------回归树子函数 END --------------#
def chooseBestSplit(dataset,leafType=regressLeaf,errType=regressErr,threshold=(1,4)):#函数做为参数,挺有意思
thresholdErr = threshold[0];thresholdSamples = threshold[1]
#当数据中输出值都相等时,feature = None,value = 输出值的均值(叶节点)
if len(set(dataset[:,-1].T.tolist()[0])) == 1:
return None,leafType(dataset)
m,n = np.shape(dataset)
Err = errType(dataset)
bestErr = np.inf; bestFeatureIndex = 0; bestFeatureValue = 0
for featureindex in range(n-1):
for featurevalue in dataset[:,featureindex]:
matLeft,matRight = binarySplitDataSet(dataset,featureindex,featurevalue)
if (np.shape(matLeft)[0] < thresholdSamples) or (np.shape(matRight)[0] < thresholdSamples):
continue
temErr = errType(matLeft) + errType(matRight)
if temErr < bestErr:
bestErr = temErr
bestFeatureIndex = featureindex
bestFeatureValue = featurevalue
#检验在所选出的最优划分特征及其取值下,误差平方和与未划分时的差是否小于阈值,若是,则不适合划分
if (Err - bestErr) < thresholdErr:
return None,leafType(dataset)
matLeft,matRight = binarySplitDataSet(dataset,bestFeatureIndex,bestFeatureValue)
#检验在所选出的最优划分特征及其取值下,划分的左右数据集的样本数是否小于阈值,若是,则不适合划分
if (np.shape(matLeft)[0] < thresholdSamples) or (np.shape(matRight)[0] < thresholdSamples):
return None,leafType(dataset)
return bestFeatureIndex,bestFeatureValue
def createCARTtree(dataset,leafType=regressLeaf,errType=regressErr,threshold=(1,4)):
'''
输入:数据集dataset,叶子节点形式leafType:regressLeaf(回归树)、modelLeaf(模型树)
损失函数errType:误差平方和也分为regressLeaf和modelLeaf、用户自定义阈值参数:
误差减少的阈值和子样本集应包含的最少样本个数
功能:建立回归树或模型树
输出:以字典嵌套数据形式返回子回归树或子模型树或叶结点
'''
feature,value = chooseBestSplit(dataset,leafType,errType,threshold)
#当不满足阈值或某一子数据集下输出全相等时,返回叶节点
if feature == None: return value
returnTree = {}
returnTree['bestSplitFeature'] = feature
returnTree['bestSplitFeatValue'] = value
leftSet,rightSet = binarySplitDataSet(dataset,feature,value)
returnTree['left'] = createCARTtree(leftSet,leafType,errType,threshold)
returnTree['right'] = createCARTtree(rightSet,leafType,errType,threshold)
return returnTree
#----------回归树剪枝函数----------#
def isTree(obj):#主要是为了判断当前节点是否是叶节点
return (type(obj).__name__ == 'dict')
def getMean(tree):#树就是嵌套字典
if isTree(tree['left']): tree['left'] = getMean(tree['left'])
if isTree(tree['right']): tree['right'] = getMean(tree['right'])
return (tree['left'] + tree['right'])/2.0
def prune(tree, testData):
if np.shape(testData)[0] == 0: return getMean(tree)#存在测试集中没有训练集中数据的情况
if isTree(tree['left']) or isTree(tree['right']):
leftTestData, rightTestData = binarySplitDataSet(testData,tree['bestSplitFeature'],tree['bestSplitFeatValue'])
#递归调用prune函数对左右子树,注意与左右子树对应的左右子测试数据集
if isTree(tree['left']): tree['left'] = prune(tree['left'],leftTestData)
if isTree(tree['right']): tree['right'] = prune(tree['right'],rightTestData)
#当递归搜索到左右子树均为叶节点时,计算测试数据集的误差平方和
if not isTree(tree['left']) and not isTree(tree['right']):
leftTestData, rightTestData = binarySplitDataSet(testData,tree['bestSplitFeature'],tree['bestSplitFeatValue'])
errorNOmerge = sum(np.power(leftTestData[:,-1] - tree['left'],2)) +sum(np.power(rightTestData[:,-1] - tree['right'],2))
errorMerge = sum(np.power(testData[:,1] - getMean(tree),2))
if errorMerge < errorNOmerge:
print 'Merging'
return getMean(tree)
else: return tree
else: return tree
#---------回归树剪枝END-----------#
#-----------模型树子函数-----------#
def linearSolve(dataset):
m,n = np.shape(dataset)
X = np.mat(np.ones((m,n)));Y = np.mat(np.ones((m,1)))
X[:,1:n] = dataset[:,0:(n-1)]
Y = dataset[:,-1]
xTx = X.T * X
if np.linalg.det(xTx) == 0:
raise NameError('This matrix is singular, cannot do inverse,n
try increasing the second value of threshold')
ws = xTx.I * (X.T * Y)
return ws, X,Y
def modelLeaf(dataset):
ws,X,Y = linearSolve(dataset)
return ws
def modelErr(dataset):
ws,X,Y = linearSolve(dataset)
yHat = X * ws
return sum(np.power(Y - yHat,2))
#------------模型树子函数END-------#
#------------CART预测子函数------------#
def regressEvaluation(tree, inputData):
#只有当tree为叶节点时,才会输出
return float(tree)
def modelTreeEvaluation(model,inputData):
#inoutData为采样数为1的特征行向量
n = np.shape(inputData)
X = np.mat(np.ones((1,n+1)))
X[:,1:n+1] = inputData
return float(X * model)
def treeForeCast(tree, inputData, modelEval = regressEvaluation):
if not isTree(tree): return modelEval(tree,inputData)
if inputData[tree['bestSplitFeature']] <= tree['bestSplitFeatValue']:
if isTree(tree['left']):
return treeForeCast(tree['left'],inputData,modelEval)
else:
return modelEval(tree['left'],inputData)
else:
if isTree(tree['right']):
return treeForeCast(tree['right'],inputData,modelEval)
else:
return modelEval(tree['right'],inputData)
def createForeCast(tree,testData,modelEval=regressEvaluation):
m = len(testData)
yHat = np.mat(np.zeros((m,1)))
for i in range(m):
yHat = treeForeCast(tree,testData[i],modelEval)
return yHat
#-----------CART预测子函数 END------------#
if __name__ == '__main__':
trainfilename = 'e:\python\ml\trainDataset.txt'
testfilename = 'e:\python\ml\testDataset.txt'
trainDataset = regressData(trainfilename)
testDataset = regressData(testfilename)
cartTree = createCARTtree(trainDataset,threshold=(1,4))
pruneTree=prune(cartTree,testDataset)
treePlotter.createPlot(cartTree)
y=createForeCast(cartTree,np.mat([0.3]),modelEval=regressEvaluation)
3、基于scikit-learn决策树算法类库实现CART算法
3.1 scikit-learn决策树算法类库概述
官方文档
quad quad
scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。两者的参数定义几乎完全相同,但是意义不全相同。下面就对DecisionTreeClassifier和DecisionTreeRegressor的重要参数做一个总结,重点比较两者参数使用的不同点和调参的注意点。
中文详情见此博客
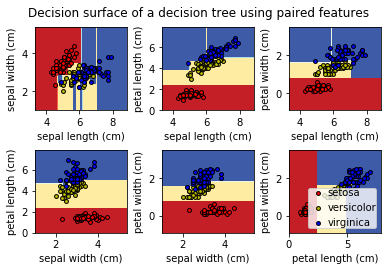
3.2 实战1—分类树
具体参数使用方法参考官方文档
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
# Parameters
n_classes = 3
plot_colors = "ryb"
plot_step = 0.02
# Load data
iris = load_iris()
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3],
[1, 2], [1, 3], [2, 3]]):
# We only take the two corresponding features
X = iris.data[:, pair]
y = iris.target
# Train
clf = DecisionTreeClassifier().fit(X, y)
# Plot the decision boundary
plt.subplot(2, 3, pairidx + 1)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu)
plt.xlabel(iris.feature_names[pair[0]])
plt.ylabel(iris.feature_names[pair[1]])
# Plot the training points
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i],
cmap=plt.cm.RdYlBu, edgecolor='black', s=15)
plt.suptitle("Decision surface of a decision tree using paired features")
plt.legend(loc='lower right', borderpad=0, handletextpad=0)
plt.axis("tight")
plt.figure()
clf = DecisionTreeClassifier().fit(iris.data, iris.target)
plot_tree(clf, filled=True)
plt.show()
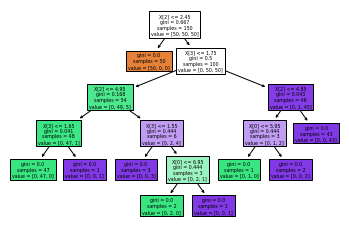
3.3 实战2—回归树
具体参数参考官方文档
from sklearn.datasets import load_diabetes
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
X, y = load_diabetes(return_X_y=True)
regressor = DecisionTreeRegressor(random_state=0)
cross_val_score(regressor, X, y, cv=10)
4、决策树算法小结
首先我们看看决策树算法的优点:
1)简单直观,生成的决策树很直观。
2)基本不需要预处理,不需要提前归一化,处理缺失值。
3)使用决策树预测的代价是O(log2m)。 m为样本数。
4)既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。
5)可以处理多维度输出的分类问题。
6)相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
7)可以交叉验证的剪枝来选择模型,从而提高泛化能力。
8) 对于异常点的容错能力好,健壮性高。
我们再看看决策树算法的缺点:
1)决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
2)决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
3)寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4)有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
5)如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
参考资料:
1、李航《统计学习方法》
2、https://www.cnblogs.com/pinard/p/6053344.html
最后
以上就是从容招牌最近收集整理的关于机器学习笔记21——决策树之CART算法原理及python实现案例引言1、概述2、CART算法3、基于scikit-learn决策树算法类库实现CART算法4、决策树算法小结的全部内容,更多相关机器学习笔记21——决策树之CART算法原理及python实现案例引言1、概述2、CART算法3、基于scikit-learn决策树算法类库实现CART算法4、决策树算法小结内容请搜索靠谱客的其他文章。








发表评论 取消回复