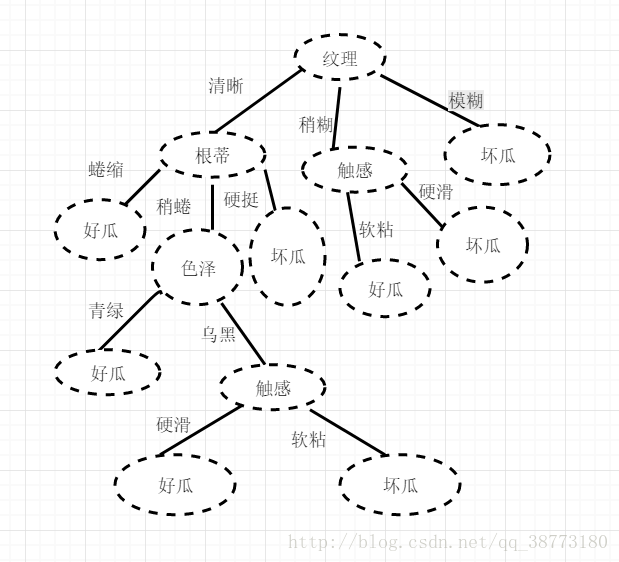
首先来看下本次案例创建得到的决策树长什么样
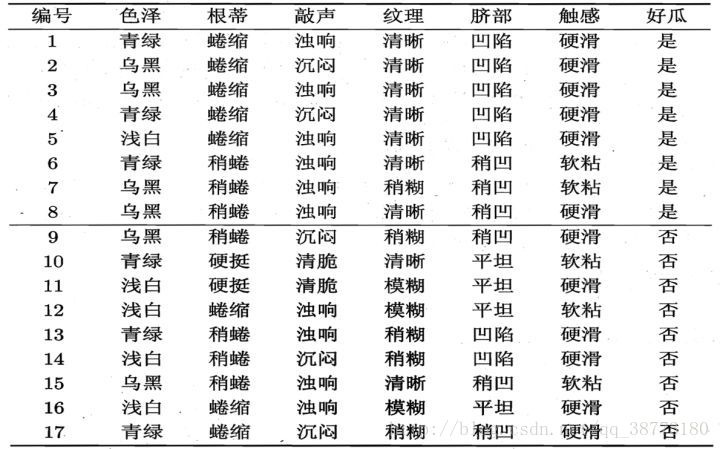
用于创建这棵决策树的数据如下(第一行的每一列为特征名称,最后一列为分类)
色泽,根蒂,敲声,纹理,脐部,触感,好瓜
青绿,蜷缩,浊响,清晰,凹陷,硬滑,好瓜
乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,好瓜
乌黑,蜷缩,浊响,清晰,凹陷,硬滑,好瓜
青绿,蜷缩,沉闷,清晰,凹陷,硬滑,好瓜
浅白,蜷缩,浊响,清晰,凹陷,硬滑,好瓜
青绿,稍蜷,浊响,清晰,稍凹,软粘,好瓜
乌黑,稍蜷,浊响,稍糊,稍凹,软粘,好瓜
乌黑,稍蜷,浊响,清晰,稍凹,硬滑,好瓜
乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,坏瓜
青绿,硬挺,清脆,清晰,平坦,软粘,坏瓜
浅白,硬挺,清脆,模糊,平坦,硬滑,坏瓜
浅白,蜷缩,浊响,模糊,平坦,软粘,坏瓜
青绿,稍蜷,浊响,稍糊,凹陷,硬滑,坏瓜
浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,坏瓜
乌黑,稍蜷,浊响,清晰,稍凹,软粘,坏瓜
浅白,蜷缩,浊响,模糊,平坦,硬滑,坏瓜
青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,坏瓜我们引入“信息熵”来作为度量样本集合不确定度(纯度)的指标,采用信息增益这个量来作为纯度的度量,选取信息增益最大的特征进行分裂(即作为结点)。
信息增益是=信息熵-条件熵
信息熵代表随机变量的复杂度(不确定度),条件熵代表在某一个条件下,随机变量的复杂度(不确定度)。
那这两个量的计算公式是什么呢?
如果当前样本集合D中第K类样本所占的比例为pk,那么D的信息熵定义为:
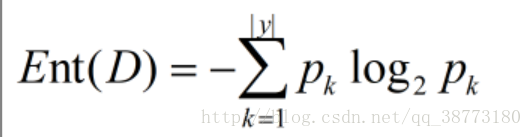
离散属性a有V个可能取值{a1,a2,...,av},样本集合中,属性a上取值为av的样本集合,记为Dv。则用属性a对样本集D进行划分所获得的“信息增益”为:

我们计算得到的信息增益表示得知属性a的信息而使得样本集合不确定度减少的程度。
所以在构建决策树的过程中,我们的关键就是每次选择什么进行决策树的构建。什么样的特征作为结点,那么如何在这么多的特征中进行一个选择呢,我们采用最大信息增益(信息不确定性减少的程度最大)来度量。好了,现在我们知道怎么选择特征作为结点的指标是什么了。
我们可以对下面给出的数据集进行决策树的构建了。
正例(好瓜)占8/17,反例(坏瓜)占9/17,则根结点的信息熵为:
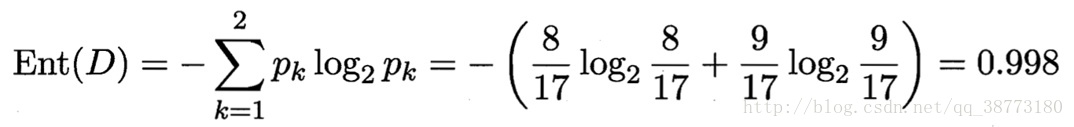
计算当前属性集合{色泽,根蒂,敲声,纹理,脐带,触感}中每个属性的信息增益。
色泽有三个可能的取值:青绿、乌黑、浅白
D1{色泽=青绿}={1,4,6,10,13,17},正例3/6,反例3/6
D2{色泽=乌黑}={2,3,7,8,9,15},正例4/6,反例2/6
D3{色泽=浅白}={5,11,12,14,16},正例1/5,反例4/5
这三个分支结点的信息熵为:
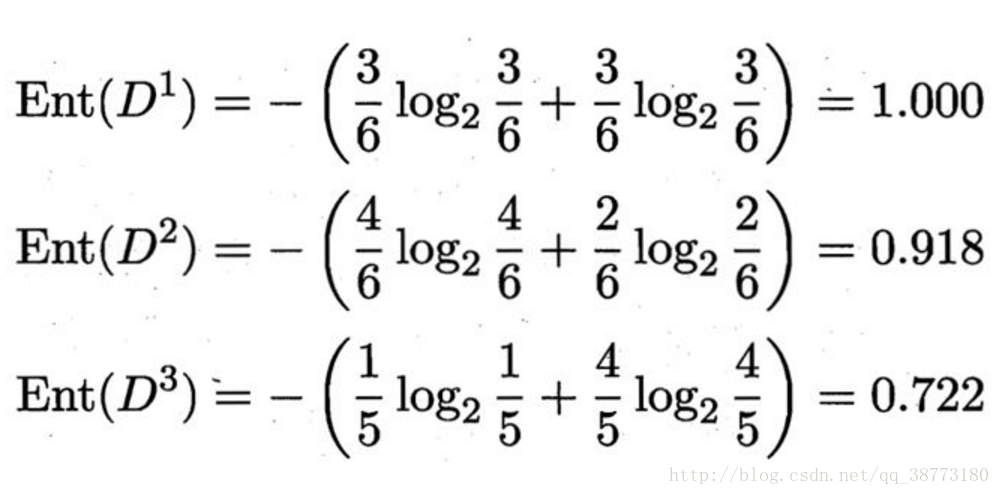
由此我们可以计算出色泽属性的信息增益是:
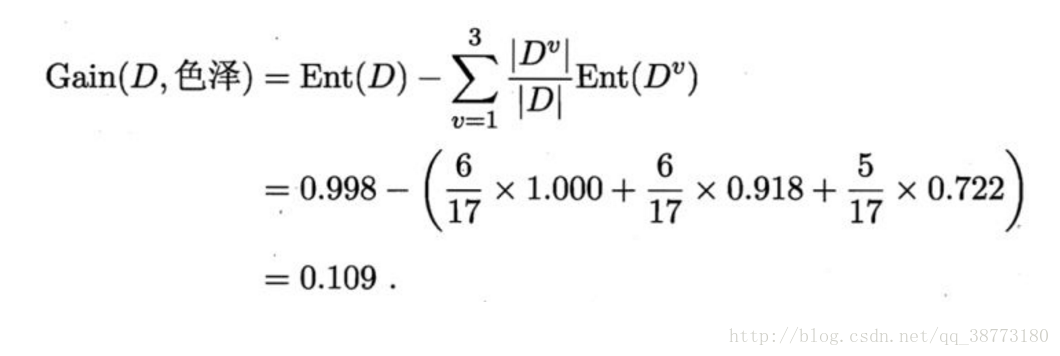
同理,按照一样的方法我们可以求出其他属性的信息增益,分别如下:

经过比较,我们得出信息增益最大的属性为纹理,于是我们得到第一个划分属性结点(纹理)。
到现在可得出如下初步构建的决策树:
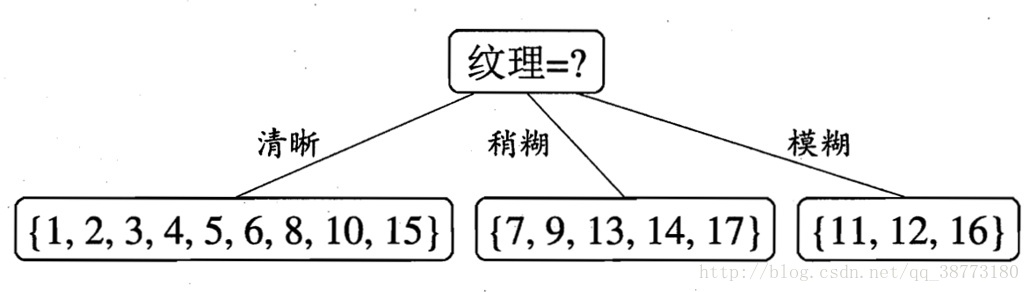
我们依据结点标签(清晰、稍糊、模糊)划分了三个子结点对应的集合。这里的3个子集合相当于一个类似总集合D一样的地位。重复上面找的纹理结点的方法进行递归。利用信息增益最大的方法来进行特征选择。
比如;D1{纹理=清晰}={1,2,3,4,5,6,8,10,15},第一个分支结点可用属性集合为{色泽、根蒂、敲声、脐部、触感},则基于集合D1计算出的各属性信息增益分别如下;

于是我们可以选择根蒂、脐部、触感这3个特征属性中的任何一个(因为他们的信息增益值相等且最大),其他两个结点同理。这样就可以得到新一层的结点。通过递归就能构建出整个决策树了。
到这里,我们应该知道了如何创建决策树了。然后遍历决策树就可以进行预测分类了。
呐,决策树我们知道怎么去构建了,但我们还没有算是大功告成。对于决策树我们还需要进行一些适当的剪枝来应对实际中参差不齐的数据。我这里用的数据是比较好的数据,所以没有进行剪枝代码的编写。以下附上java构建决策树算法的实现代码:
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
class treeNode{//树节点
private String sname;//节点名
public treeNode(String str) {
sname=str;
}
public String getsname() {
return sname;
}
ArrayList<String> label=new ArrayList<String>();//和子节点间的边标签
ArrayList<treeNode> node=new ArrayList<treeNode>();//对应子节点
}
public class ID3 {
private ArrayList<String> label=new ArrayList<String>();//特征标签
private ArrayList<ArrayList<String>> date=new ArrayList<ArrayList<String>>();//数据集
private ArrayList<ArrayList<String>> test=new ArrayList<ArrayList<String>>();//测试数据集
private ArrayList<String> sum=new ArrayList<String>();//分类种类数
private String kind;
public ID3(String path,String path0) throws FileNotFoundException {
//初始化训练数据并得到分类种数
getDate(path);
//获取测试数据集
gettestDate(path0);
init(date);
}
public void init(ArrayList<ArrayList<String>> date) {
//得到种类数
sum.add(date.get(0).get(date.get(0).size()-1));
for(int i=0;i<date.size();i++) {
if(sum.contains(date.get(i).get(date.get(0).size()-1))==false) {
sum.add(date.get(i).get(date.get(0).size()-1));
}
}
}
//获取测试数据集
public void gettestDate(String path) throws FileNotFoundException {
String str;
int i=0;
try {
//BufferedReader in=new BufferedReader(new FileReader(path));
FileInputStream fis = new FileInputStream(path);
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
BufferedReader in = new BufferedReader(isr);
while((str=in.readLine())!=null) {
String[] strs=str.split(",");
ArrayList<String> line =new ArrayList<String>();
for(int j=0;j<strs.length;j++) {
line.add(strs[j]);
//System.out.print(strs[j]+" ");
}
test.add(line);
//System.out.println();
i++;
}
in.close();
}catch(Exception e) {
e.printStackTrace();
}
}
//获取训练数据集
public void getDate(String path) throws FileNotFoundException {
String str;
int i=0;
try {
//BufferedReader in=new BufferedReader(new FileReader(path));
FileInputStream fis = new FileInputStream(path);
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
BufferedReader in = new BufferedReader(isr);
while((str=in.readLine())!=null) {
if(i==0) {
String[] strs=str.split(",");
for(int j=0;j<strs.length;j++) {
label.add(strs[j]);
//System.out.print(strs[j]+" ");
}
i++;
//System.out.println();
continue;
}
String[] strs=str.split(",");
ArrayList<String> line =new ArrayList<String>();
for(int j=0;j<strs.length;j++) {
line.add(strs[j]);
//System.out.print(strs[j]+" ");
}
date.add(line);
//System.out.println();
i++;
}
in.close();
}catch(Exception e) {
e.printStackTrace();
}
}
public double Ent(ArrayList<ArrayList<String>> dat) {
//计算总的信息熵
int all=0;
double amount=0.0;
for(int i=0;i<sum.size();i++) {
for(int j=0;j<dat.size();j++) {
if(sum.get(i).equals(dat.get(j).get(dat.get(0).size()-1))) {
all++;
}
}
if((double)all/dat.size()==0.0) {
continue;
}
amount+=((double)all/dat.size())*(Math.log(((double)all/dat.size()))/Math.log(2.0));
all=0;
}
if(amount==0.0) {
return 0.0;
}
return -amount;//计算信息熵
}
//计算条件熵并返回信息增益值
public double condtion(int a,ArrayList<ArrayList<String>> dat) {
ArrayList<String> all=new ArrayList<String>();
double c=0.0;
all.add(dat.get(0).get(a));
//得到属性种类
for(int i=0;i<dat.size();i++) {
if(all.contains(dat.get(i).get(a))==false) {
all.add(dat.get(i).get(a));
}
}
ArrayList<ArrayList<String>> plus=new ArrayList<ArrayList<String>>();
//部分分组
ArrayList<ArrayList<ArrayList<String>>> count=new ArrayList<ArrayList<ArrayList<String>>>();
//分组总和
for(int i=0;i<all.size();i++) {
for(int j=0;j<dat.size();j++) {
if(true==all.get(i).equals(dat.get(j).get(a))) {
plus.add(dat.get(j));
}
}
count.add(plus);
c+=((double)count.get(i).size()/dat.size())*Ent(count.get(i));
plus.removeAll(plus);
}
return (Ent(dat)-c);
//返回条件熵
}
//计算信息增益最大属性
public int Gain(ArrayList<ArrayList<String>> dat) {
ArrayList<Double> num=new ArrayList<Double>();
//保存各信息增益值
for(int i=0;i<dat.get(0).size()-1;i++) {
num.add(condtion(i,dat));
}
int index=0;
double max=num.get(0);
for(int i=1;i<num.size();i++) {
if(max<num.get(i)) {
max=num.get(i);
index=i;
}
}
//System.out.println("<"+label.get(index)+">");
return index;
}
//构建决策树
public treeNode creattree(ArrayList<ArrayList<String>> dat) {
int index=Gain(dat);
treeNode node=new treeNode(label.get(index));
ArrayList<String> s=new ArrayList<String>();//属性种类
s.add(dat.get(0).get(index));
//System.out.println(dat.get(0).get(index));
for(int i=1;i<dat.size();i++) {
if(s.contains(dat.get(i).get(index))==false) {
s.add(dat.get(i).get(index));
//System.out.println(dat.get(i).get(index));
}
}
ArrayList<ArrayList<String>> plus=new ArrayList<ArrayList<String>>();
//部分分组
ArrayList<ArrayList<ArrayList<String>>> count=new ArrayList<ArrayList<ArrayList<String>>>();
//分组总和
//得到节点下的边标签并分组
for(int i=0;i<s.size();i++) {
node.label.add(s.get(i));//添加边标签
//System.out.print("添加边标签:"+s.get(i)+" ");
for(int j=0;j<dat.size();j++) {
if(true==s.get(i).equals(dat.get(j).get(index))) {
plus.add(dat.get(j));
}
}
count.add(plus);
//System.out.println();
//以下添加结点
int k;
String str=count.get(i).get(0).get(count.get(i).get(0).size()-1);
for(k=1;k<count.get(i).size();k++) {
if(false==str.equals(count.get(i).get(k).get(count.get(i).get(k).size()-1))) {
break;
}
}
if(k==count.get(i).size()) {
treeNode dd=new treeNode(str);
node.node.add(dd);
//System.out.println("这是末端:"+str);
}
else {
//System.out.print("寻找新节点:");
node.node.add(creattree(count.get(i)));
}
plus.removeAll(plus);
}
return node;
}
//输出决策树
public void print(ArrayList<ArrayList<String>> dat) {
System.out.println("构建的决策树如下:");
treeNode node=null;
node=creattree(dat);//类
put(node);//递归调用
}
//用于递归的函数
public void put(treeNode node) {
System.out.println("结点:"+node.getsname()+"n");
for(int i=0;i<node.label.size();i++) {
System.out.println(node.getsname()+"的标签属性:"+node.label.get(i));
if(node.node.get(i).node.isEmpty()==true) {
System.out.println("叶子结点:"+node.node.get(i).getsname());
}
else {
put(node.node.get(i));
}
}
}
//用于对待决策数据进行预测并将结果保存在指定路径
public void testdate(ArrayList<ArrayList<String>> test,String path) throws IOException {
treeNode node=null;
int count=0;
node=creattree(this.date);//类
try {
BufferedWriter out=new BufferedWriter(new FileWriter(path));
for(int i=0;i<test.size();i++) {
testput(node,test.get(i));//递归调用
//System.out.println(kind);
for(int j=0;j<test.get(i).size();j++) {
out.write(test.get(i).get(j)+",");
}
if(kind.equals(date.get(i).get(date.get(i).size()-1))==true) {
count++;
}
out.write(kind);
out.newLine();
}
System.out.println("该次分类结果正确率为:"+(double)count/test.size()*100+"%");
out.flush();
out.close();
}catch(IOException e) {
e.printStackTrace();
}
}
//用于测试的递归调用
public void testput(treeNode node,ArrayList<String> t) {
int index=0;
for(int i=0;i<this.label.size();i++) {
if(this.label.get(i).equals(node.getsname())==true) {
index=i;
break;
}
}
for(int i=0;i<node.label.size();i++) {
if(t.get(index).equals(node.label.get(i))==false) {
continue;
}
if(node.node.get(i).node.isEmpty()==true) {
//System.out.println("分类结果为:"+node.node.get(i).getsname());
this.kind=node.node.get(i).getsname();//取出分类结果
}
else {
testput(node.node.get(i),t);
}
}
}
public static void main(String[] args) throws IOException {
String data="C:\Users\zfw\Desktop\data1.txt";//训练数据集
String test="C:\Users\zfw\Desktop\test.txt";//测试数据集
String result="C:\Users\zfw\Desktop\result.txt";//预测结果集
ID3 id=new ID3(data,test);//初始化数据
id.print(id.date);//构建并输出决策树
//id.testdate(id.test,result);//预测数据并输出结果
}
}
构建的决策树如下:
结点:纹理
纹理的标签属性:清晰
结点:根蒂
根蒂的标签属性:蜷缩
叶子结点:好瓜
根蒂的标签属性:稍蜷
结点:色泽
色泽的标签属性:青绿
叶子结点:好瓜
色泽的标签属性:乌黑
结点:触感
触感的标签属性:硬滑
叶子结点:好瓜
触感的标签属性:软粘
叶子结点:坏瓜
根蒂的标签属性:硬挺
叶子结点:坏瓜
纹理的标签属性:稍糊
结点:触感
触感的标签属性:软粘
叶子结点:好瓜
触感的标签属性:硬滑
叶子结点:坏瓜
纹理的标签属性:模糊
叶子结点:坏瓜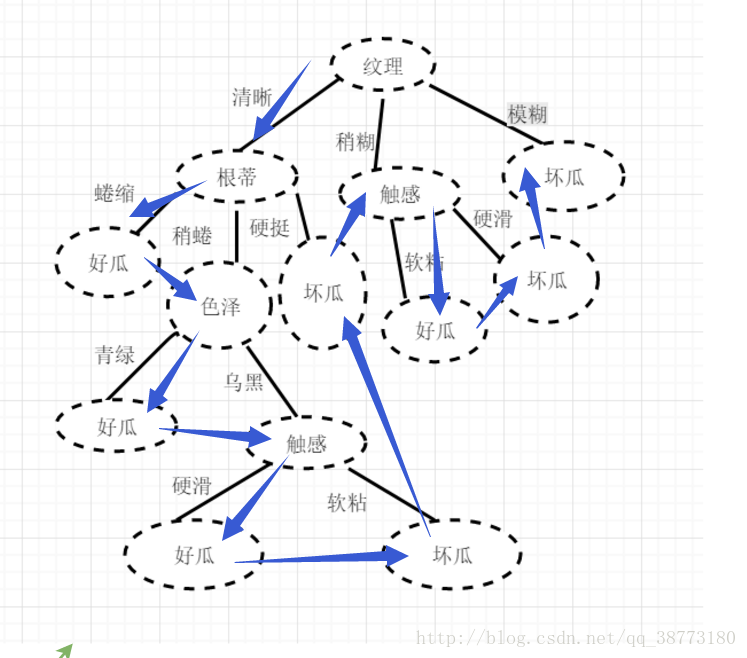
比如说数据如果是如下:
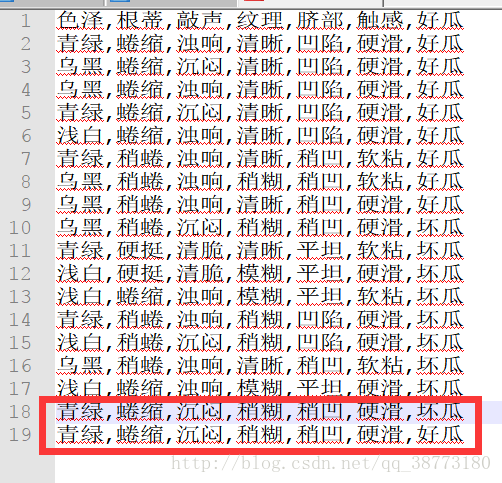
将数据集的最后一条数据添加并改结果为好瓜。然后放到程序去跑,发现程序报错。这样程序就需要修改来处理这种数据冲突的矛盾数据了。这就是决策树的优化问题了。
最后
以上就是忧伤糖豆最近收集整理的关于一看就懂的决策树算法(java实现)的全部内容,更多相关一看就懂内容请搜索靠谱客的其他文章。








发表评论 取消回复