5.3. CPU多级缓存
5.3.1. CPU缓存基本介绍
1)CPU缓存出现的原因
CPU的频率太快,快到主存跟不上,这样在处理器时钟周期内,CPU经常需要等待主存,浪费资源。所以缓存的出现,是为了缓解CPU和内存间速度的不匹配问题。(结论:CPU>缓存>主存)
2)CPU缓存的意义
1)时间局部性:如果某个数据被访问,那么在不久的将来它很有可能会被再次访问。
2)空间局部性:如果某个数据被访问,那么与它相邻的数据很快也能被访问。
3)多核系统中的缓存设置意义
在典型的多核系统中,每一个核心都会有自己的缓存来共享主存总线,每一个CPU都会发出读写请求,而缓存的目的就是为了减少CPU读写共享主存的次数。
5.3.2. 缓存行
1)缓存行的定义
缓存是由缓存行组成的,CPU读取缓存都是以缓存行的形式读取,通常是 64 字节(常用处理器的缓存行是 64 字节的,比较旧的处理器缓存行是 32 字节),并且它有效地引用主内存中的一块地址。在程序运行的过程中,缓存每次更新都从主内存中加载连续的 64 个字节。因此,如果访问一个 long 类型的数组时,当数组中的一个值被加载到缓存中时,另外 7 个元素也会被加载到缓存中。
注:a. 一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。b.如果使用的数据结构中的项在内存中不是彼此相邻的,比如链表,那么将得不到免费缓存加载带来的好处。
2)伪共享问题
a.定义:当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享问题。
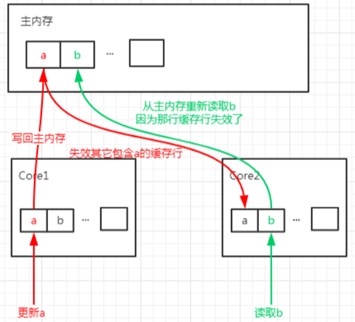
b.样例介绍:设想如果有个 long 类型的变量 a,它不是数组的一部分,而是一个单独的变量,并且还有另外一个 long 类型的变量 b 紧挨着它,那么当加载 a 的时候将免费加载 b。看起来似乎没有什么毛病,但是如果一个 CPU 核心的线程在对 a 进行修改,另一个 CPU 核心的线程却在对 b 进行读取。当前者修改 a 时,会把 a 和 b 同时加载到前者核心的缓存行中,更新完 a 后其它所有包含 a 的缓存行都将失效,因为其它缓存中的 a 不是最新值了。而当后者读取 b 时,发现这个缓存行已经失效了,需要从主内存中重新加载。缓存都是以缓存行作为一个单位来处理的,所以失效 a 的缓存的同时,也会把 b 失效,反之亦然。这样就出现了一个问题,b 和 a 完全不相干,每次却要因为 a 的更新需要从主内存重新读取,它被缓存未命中给拖慢了。
c.解决方案
以解决两个long类型变量的伪缓存问题为例:
方法1:由于一个缓存行是 64 个字节,一个 long 类型是 8 个字节,所以可以在两个 long 类型的变量之间再加 7 个 long 类型,如下所示:
class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
}
方法2:重新创建自己的 long 类型,而不是 java 自带的 long:
class Pointer {
MyLong x = new MyLong();
MyLong y = new MyLong();
}
class MyLong {
volatile long value;
long p1, p2, p3, p4, p5, p6, p7;
}
方法3:使用 @sun.misc.Contended 注解(java8),默认使用这个注解是无效的,需要在JVM启动参数加上-XX:-RestrictContended才会生效。
@sun.misc.Contended
class MyLong {
volatile long value;
}
注意,避免伪共享的主要思路就是让不相干的变量不要出现在同一个缓存行中,以上三种方式中的前两种是通过加字段的形式实现的,加的字段又没有地方使用,可能会被jvm优化掉,所以建议使用第三种方式。
3)缓存行的优势
使用缓存行能够有效提高程序运行效率,尤其是处理数组。
5.3.3. 缓存一致性(MESI)
1)缓存一致性的核心思想
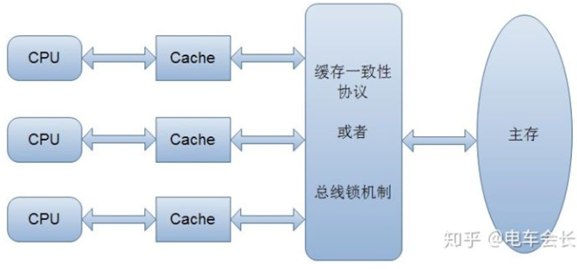
保证了每个缓存中使用的共享变量的副本是一致的。核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
CPU、Cache、缓存一致性协议、主存之间的关系如下图所示:
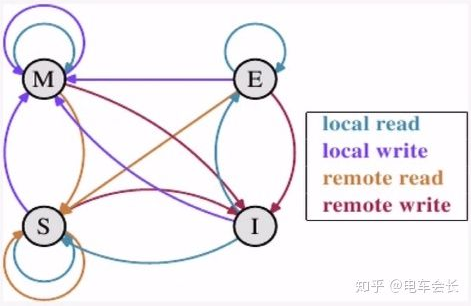
2)缓存行的状态
缓存行的状态可分为四类:Modified 被修改状态、 Exlusive独享状态、 Share共享状态、 Invalid无效状态。
a.Modified (被修改)
该缓存行只被缓存在该CPU的缓存中且是被修改过的,因此其与主存中的数据是不一致的。该缓存行的内存需要在未来的某个时间点写回主存,这个时间点是允许其他CPU读取主存中相应的内存之前,但该状态的值被写回主存后,该缓存行的状态就会变成独享状态。
b.Exlusive(独享)
该缓存行只被缓存在该CPU的缓存中且是未被修改过的,与主存中的数据一致,此种状态可以在任何时刻,在有其他CPU读取该内存时变成共享状态。同样地,当有CPU修改该缓存行内容时,该状态可以变成被修改状态。
c.Share(共享)
该缓存行可能被多个CPU进行缓存,且各缓存中的数据与主存中的数据是一致的,但某个CPU修改该缓存行时,其他CPU存储的该缓存行就会被作废,变成无效状态。
Invalid(无效)
该缓存行可能被其他CPU修改。
3) 对CPU缓存的四种操作
Local read: 读本地缓存中的数据
Local write: 将数据写入本地的缓存中
Remote read: 将内存的数据读取过来
Remote write: 将数据写回到主存中
4) 四种缓存状态的相互转换
一个缓存,除了Invalid状态外,都可以满足CPU的读请求(Local read和Remote read)。
一个写请求只有在该缓存行是Modified或者Exlusive状态时才能被执行,如果当前缓存行处于Share状态,则必须先将该缓存行变成无效的状态,这个操作通常通过广播的方式来完成,此时既不允许不同的CPU同时修改同一个缓存行,即使修改该缓存行不同位置的数据也不允许。
处于Modified状态的缓存行必须时刻监听所有试图读该缓存行相对主存的操作,这种操作必须在CPU将该缓存写回到主存并将状态变为Share状态之后才可以执行,之前必须要延迟执行。
一个处于Share状态的缓存行必须监听其他缓存使该缓存行无效或者独享该缓存行的请求,并将缓存行变成无效。
处于Exlusive状态的缓存行要监听其他缓存读该缓存中缓存行的操作,一旦有操作,需要将其变为Share状态,因此对于Modified和Exlusive,数据总是精确的,它们和缓存行的真正状态是一致的。
Share状态下各缓存行中的数据可能是非一致的,如果一个缓存将处于Share状态的缓存行作废了,另一个缓存可能已经独享了该缓存行,但该缓存却不会将该缓存行升迁为Exlusive状态,这是因为其他缓存不会广播它们作废掉该缓存行的通知,同样,由于缓存并没有保存该缓存行复制的数量,也没有办法确定自身是否已经独享了该缓存行。从这点来看,Exlusive状态更像一种投机性优化,因为如果CPU想修改一个处于Share状态的缓存行,总线需要将所有该缓存行复制的值变成Invalid状态才行,而修改Exlusive状态却不需要总线事务,因为处于Exlusive状态时就仅有该缓存拥有该缓存行。
最后
以上就是温暖发箍最近收集整理的关于运行时内存-CPU多级缓存的全部内容,更多相关运行时内存-CPU多级缓存内容请搜索靠谱客的其他文章。








发表评论 取消回复