
引言
Aliware
长久以来,RocketMQ 易于部署、高性能、高可用的架构,支撑了数十年来集团内外海量的业务场景。时至今日,为了迎接如今云原生时代的新挑战,我们重磅推出了 RocketMQ 5.0 新架构。
在 5.0 新架构中,我们更新了整个 RocketMQ 的网络拓扑模型,着眼于将更上层的业务逻辑从 broker 中剥离到无状态的 proxy ,这样独立的计算节点可以无损地承担日后的升级发布任务,与此同时将 broker 解放出来承担纯粹的存储任务,为未来打造更强的消息存储引擎做好铺垫。通信层方面,出于标准化,多语言的考虑我们摒弃了 RocketMQ 使用多年的 RemotingCommand 协议,采用了 gRPC 来实现客户端与服务端之间的通信逻辑。
针对于用户侧,我们希望尽可能少的叨扰客户进行升级,维持逻辑轻量,易于维护,可观测性良好,能够可以达到“一次性把事情做对”。
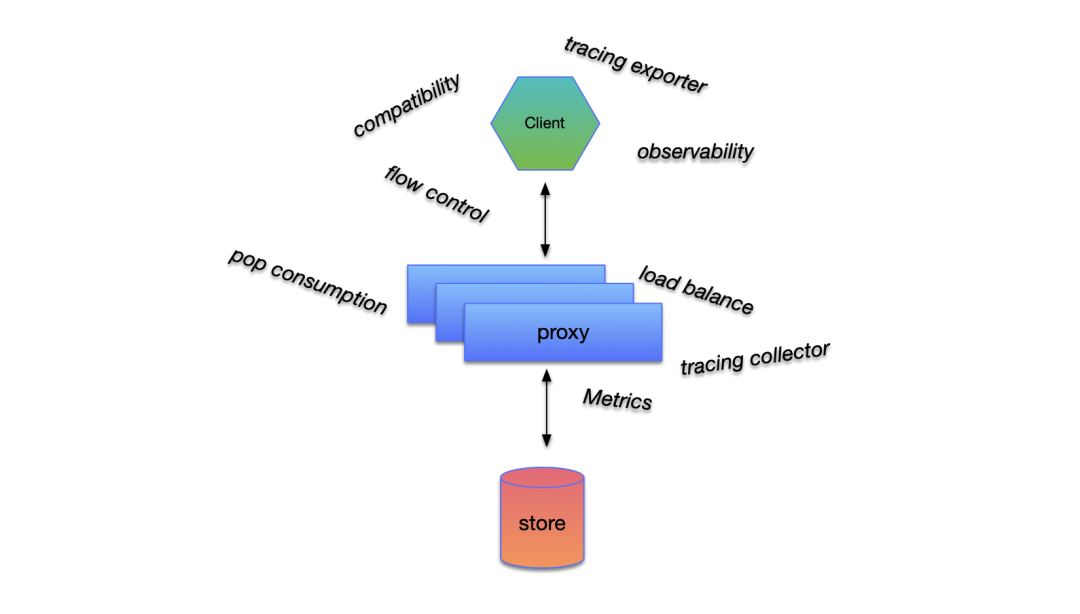
目前,保证了接口完全兼容的,基于 RocketMQ 5.0 的商业化版本 Java SDK 已经在公有云 release 完成,开源版本也即将 release。SDK 将同时支持云上 proxy 架构的云上版本和开源版本的 Broker。下面将展开叙述 RocketMQ 5.0 新架构下的 SDK 做了哪些迭代与演进。
全面异步化
Aliware
1
异步的初衷
由于涉及诸多的网络 IO,因此 RocketMQ 对消息发送开放了同步和异步两套 API 提供给用户使用。旧有架构从 API 针对于同步和异步维护了两套类似的业务逻辑,非常不利于迭代。考虑到这一点,此次新架构 SDK 希望在底层就可以将它们统一起来。
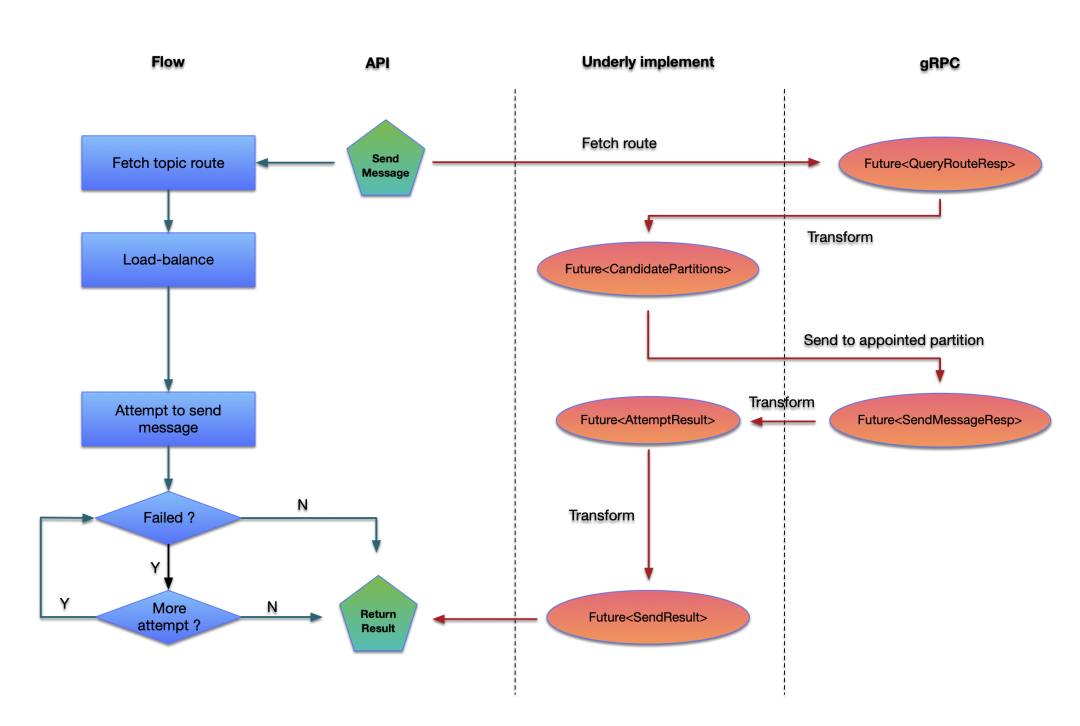
以消息发送为例,一个完整的消息发送链路包括获取:
获取 topic 对应的路由;
根据路由选择对应的分区;
发送消息到指定的分区,如果发送到该分区失败,则对下一个分区进行发送重试直到达到最大重试次数;如果发送成功,则返回发送结果。
其中从远端获取 topic 对应的路由是一个重 IO 操作,而发送消息本身也是一个重 IO 操作。在以往的发送实现中,即使是异步发送,对于路由的获取也是同步的,路由的获取本身并没有计入用户的发送耗时中,用户本身是可以自主设置消息发送的超时时间的,而由于本身消息的发送是同步的,无法做到超时时间的精准控制,而在使用异步 Future 之后,可以非常方便地通过控制 Future 的超时时间来做到。
2
异步统一所有实现
本质上 RocketMQ 里所有的重 IO 操作都可以通过异步来进行统一。得益于 gRPC 本身提供了基于 Future 的 stub,我们将网络层的 Future 一层层串联到最终的业务层。当用户需要同步 API 时,则进行同步等待;当用户需要异步 API 时,则在最外层的 Future 添加回调进行监听。
实际上基于 Future 设计的思想是贯穿整个客户端实现的。譬如,消息消费也是通过唯一的基于 Future 的实现来完成的:
/**
* Deliver message to listener.
*
* @param messageExtList message list to consume
* @param delay message consumption delay time
* @param timeUnit delay time unit.
* @return future which contains the consume status.
*/
public ListenableFuture<ConsumeStatus> consume(List<MessageExt> messageExtList, long delay, TimeUnit timeUnit) {
// Omit the implement
}针对于顺序消息消费失败这种需要本地 suspend 一段时间重新投递的情况,消费接口增加了延时参数。然而无论是普通消息还是顺序消息,都只会返回含有消费状态的 Future 。上层再针对含有消费状态的 Future 来进行消息的 ACK/NACK 。特别地,针对于服务端向客户端投递特定消息进行消费验证的场景,也是调用当前 Future 接口,再对消费结果进行包装向服务端响应消费结果。
RocketMQ 本身的发送和消费过程中充斥着大量的异步逻辑,使用 Future 使得大量的接口实现得到了精简和统一。尤其在我们的基于 gRPC 新架构协议的 IDL 中,为了保持简单全部都是使用 unary rpc(非流式),使得我们全部可以使用 gRPC 的 Future stub 来完成通信请求。
可观测性增强
Aliware
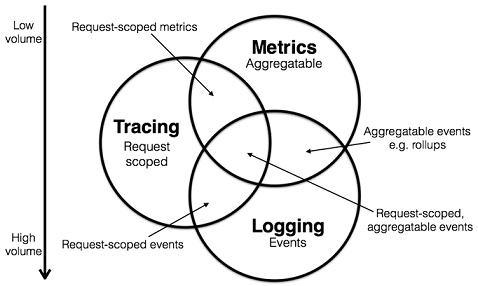
上面这张图来自于 Peter Bourgon 2017 年的一篇重要博文,系统且详细地阐述了 metrics、tracing 和 logging 三者之间的特征与定义,以及他们之间的关联。
Metrics:具体聚合同类数据的统计信息,用于预警和监控。
Tracing:关联和分析同一个调用链上的元数据,判断具体调用链上的异常和阻塞行为。
Logging:记录离散的事件来分析程序的行为。
云原生时代,可观测性是云产品的核心竞争力之一。因而可观测性增强的基调是整个新架构开发之初就已经确定的。旧有架构客户端逻辑复杂的同时,可观测性的缺失也导致我们在面临客户工单时更加缺乏足够直观简便的手段,因此新架构中我们围绕 Tracing、Logging 和 Metrics 这三个重要方面进行了全方位的可观察性提升。
1
全链路 Tracing
Tracing 体现在消息中间件中,最基本的,即对每条消息本身的发送、拉取、消费、ACK/NACK、事务提交、存储、删除等过程进行全生命周期的监控记录,在 RocketMQ 中最基本的实现就是消息轨迹。
旧有的消息轨迹采用私有协议进行编解码,对于消息生命周期的观测也仅限于发送、消费和事务相关等阶段。没有和开源规范进行统一,也不具备消息自身的轨迹和用户链路的 trace 共享上下文的能力。
新的实现中,拥抱了最新的 CNCF OpenTelemetry 社区协议规范,在客户端中嵌入了一个 OTLP exporter 将 tracing 数据批量发送至 proxy,proxy 侧的方案则比较多样了,既可以本身作为一个 collector 将数据进行整合,也可以转发至其他的 collector,proxy 侧也会有相对应的 tracing 数据,会和客户端上报来的 tracing 数据合并进行处理。
由于采用开源标准的 OTLP exporter 和协议,使得用户自己定义对应的 collector 地址成为可能。在商业版本中我们将用户客户端的 tracing 数据和服务端的 tracing 数据进行收集整合后进行托管存储,开源版本中用户也可以自定义自己的 collector 地址将 tracing 数据上报到自己的平台进行分析和处理。
针对于整个消息的生命周期,我们重新设计了所有的 span 拓扑模型。以最简单的消息发送、接受、消费和 ACK/NACK 过程为例:
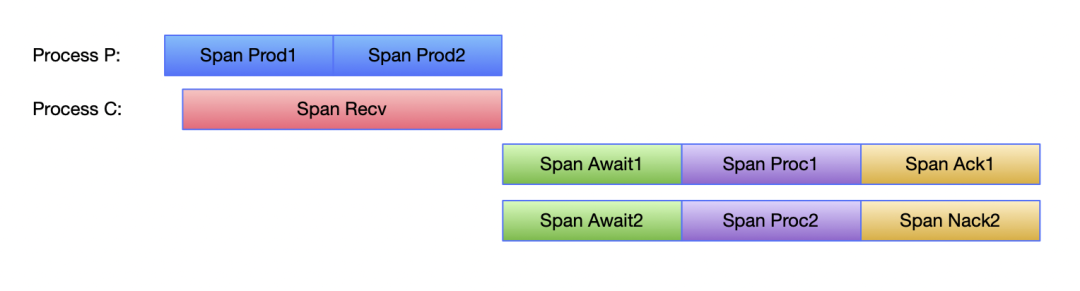
其中:
Prod :Produce, 表示消息的发送,即起始时间为消息开始发送,结束时间为收到消息发送结果(消息内部重试会单独进行记录一条 span);
Recv :Receive,表示消息的接收,即起始时间为客户端发起接受消息的请求,结束时间为收到对应的响应;
Await :表示消息到达客户端直到消息开始被消费;
Proc :Process,表示消息的消费过程;
Ack/Nack 表示消息被 Ack/Nack 的过程。
这个过程,各个 Span 之间的关系如下:
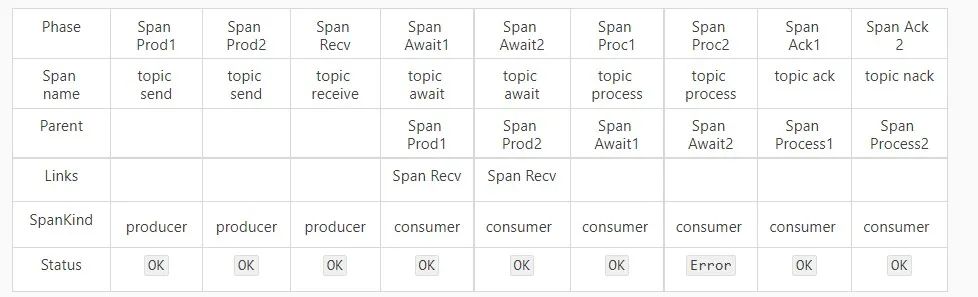
商业版的 RocketMQ 在管控侧也对新版本 Trace 进行了支持,针对于用户关心的消息生产耗时、具体消费状况、消费耗时、等待耗时,消费次数等给出了更加详尽的展示。
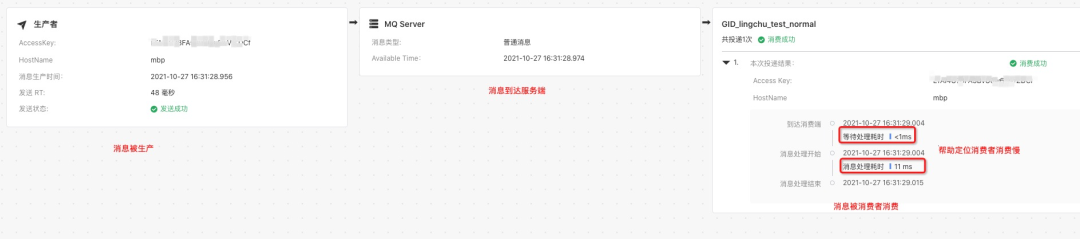
通过 SLS 的 trace 服务观察生产者和消费者 span 的拓扑关系(link 关系没有进行展示,因此图中没有 receive 相关的 span):

OpenTelemetry 关于 messaging span 相关的 specification 也在社区不断迭代,这涉及到具体的 tracing 拓扑,span 属性定义(即 attribute semantic conventions)等等。我们也在第一时间将 RocketMQ 相关的内容向社区 OpenTelemetry specification 发起了初步的 Pull Request,并得到了社区的收录和肯定。也得益于 OpenTelemetry specification 详尽和规范的定义,我们在 tracing 数据增加了包括且不限于程序运行时、操作系统环境和版本等
(即 resource semantic conventions)大量有利于线上问题发现和排查的信息。
关于 tracing context propagation ,我们采用了 W3C 的标准对 trace context 进行序列化和反序列化在客户端和服务端之间来回传递,在下个版本中也会提供让用户自定义 trace context 的接口,使得用户可以很方便地关联 RocketMQ 和自己的 tracing 数据。
新架构中我们针对于消息生命周期的不同节点,暴露了很多 hook point ,tracing 的逻辑也基于这些 hook point 进行实现,因此也能保持相对独立。在完整的新架构推向开源之后,整个 tracing 的相关逻辑也会被抽取成专门的 instrumentation library 贡献给 openTelemetry 社区。
2
准确多样的 Metrics
Tracing 更多地是从调用链的角度去观察消息的走向,更多的时候对于有共性的数据,我们希望可以有聚合好的 Metrics 和对应 dashboard 可以从更加宏观的角度来进行观测。如果说 tracing 可以帮助更好更快地发现问题和定位问题,那么 Metrics 则提供了重要的多维观察和预警手段。
在收集到足够多的 tracing 数据之后,服务端会对这些数据进行二次聚合,计算得出用户发送、等待以及消费时间等数据的百分位数,对很多毛刺问题能很好地做出判断。
3
规范化的 Logging
我们在开发实践中严格地按照 Trace、Debug、Info、Warn、Error 的级别进行日志内容的定义,譬如 Trace 级别就会对每个 RPC 请求和响应,每条消息从进入客户端到进行记录,Error 级别的日志一旦被打印,必然是值得我们和客户关注的。在去除大量冗余信息的同时,关键节点,譬如负载均衡,发送失败重试等关键链路也补全了大量信息,单行日志的信息密度大大增加。
另外,关于日志模块的实现,RocketMQ 原本是自行开发的,相比较于 logback,log4j2 等外部实现而言,功能相对单一,二次开发成本也相对较高。选型时没有使用 logback 根本上其实只是想要避免与用户日志模块冲突的问题,在调研了诸多方案之后,选择了 shade logback 的方式进行了替换。这里的 shade 不仅仅只是替换了包名和坐标,同时也修改了 logback 官方的日志配置文件名和诸多内部环境参数。
比如默认配置文件:
库 | 默认配置文件 |
standard logback | logback.groovy/logback-test.xml/logback.xml |
logback for rocketmq | rocketmq.logback.groovy/rocketmq.logback-test.xml/rocketmq.logback.xml |
如果用户在引用 rocketmq 的同时自己也引入了 logback ,完整的配置文件和环境参数的隔离保证了两者是相互独立的。特别的,由于新架构 SDK 中引入了 gRPC,我们将 gRPC 基于 JUL 的日志桥接到了 slf4j ,并通过 logback 进行输出。
// redirect JUL logging to slf4j.
// see https://github.com/grpc/grpc-java/issues/1577
SLF4JBridgeHandler.removeHandlersForRootLogger();
SLF4JBridgeHandler.install();消费模型的更新
Aliware
RocketMQ 旧有架构的消费模型是非常复杂的。topic 中的消息本身按照 MessageQueue 进行存储,消费时客户端按 MessageQueue 对消息进行拉取、缓存和投递。
ProcessQueue 与 RocketMQ 中的
MessageQueue 一一对应,也基本上是客户端消费端逻辑中最为复杂的结构之一。在旧架构的客户端中,拉取到消息之后会先将消息缓存到 ProcessQueue 中,当需要消费时,会从 ProcessQueue 中取出对应的消息进行消费,当消费成功之后再将消息从 ProcessQueue 中 remove 走。其中重试消息的发送,位点的更新在这个过程中穿插。
1
设计思路
在新客户端中, pop 消费模式的引入使得单独处理重试消息和位点更新的逻辑被去除。用户的消费行为变为
拉取消息
消费消息
ACK/NACK 消息到远端
因为拉取到的消息在客户端内存是会先进行缓存,因此还要在消费和拉取的过程中计算消息缓存的大小来对程序进行保护,因此新客户端中每个 ProcessQueue 分别维护了两个队列:cached messages 和 pending messages 。消息在到达客户端之后会先放在 cached messages 里,准备消费时会从 cached messages 移动到 pending messages 中,当消息消费结束并被 Ack 之后则会从 pending messages 中移除。
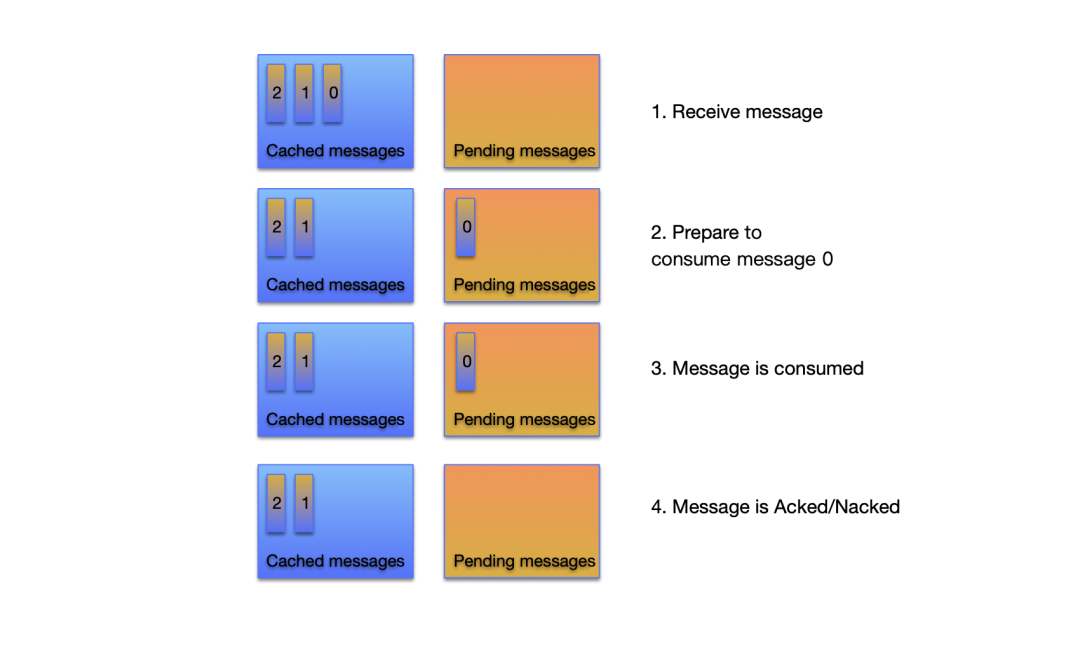
新架构的客户端精简了 ProcessQueue 的实现,封装性也做到了更好。对于消费者而言,最为核心的接口其实只有四个。
public interface ProcessQueue {
/**
* Try to take messages from cache except FIFO messages.
*
* @param batchMaxSize max batch size to take messages.
* @return messages which have been taken.
*/
List<MessageExt> tryTakeMessages(int batchMaxSize);
/**
* Erase messages which haven been taken except FIFO messages.
*
* @param messageExtList messages to erase.
* @param status consume status.
*/
void eraseMessages(List<MessageExt> messageExtList, ConsumeStatus status);
/**
* Try to take FIFO message from cache.
*
* @return message which has been taken, or {@link Optional#absent()} if no message.
*/
Optional<MessageExt> tryTakeFifoMessage();
/**
* Erase FIFO message which has been taken.
*
* @param messageExt message to erase.
* @param status consume status.
*/
void eraseFifoMessage(MessageExt messageExt, ConsumeStatus status);
}对于普通消费者(非顺序消费)而言,ProcessQueue#tryTakeMessages 将从 Cached messages 中取出消息(取出之后消息会自动从 Cached messages 移动至
Pending messages),当消息消费结束之后再携带好对应的消费结果去调用
ProcessQueue#eraseMessages ,对于顺序消费者而言,唯一不同的是对应的方法调用替换成
ProcessQueue#tryTakeFifoMessage
和 ProcessQueue#eraseFifoMessage 。
而 ProcessQueue#tryTakeMessages
和 ProcessQueue#tryTakeFifoMessage 本身已经包含了消费限流和顺序消费时为了保证顺序对队列上锁的逻辑,即做到了:一旦
ProcessQueue#tryTakeMessages/ProcessQueue#tryTakeFifoMessage 可以取到消息,那么消息一定是满足被消费条件的。当消费者获取到消费结果之后,再带上消费结果执行
ProcessQueue#eraseMessage
和 ProcessQueue#eraseFifoMessage ,
erase 的过程会完成消息的 ACK/NACK 和顺序消费时队列解锁的逻辑。
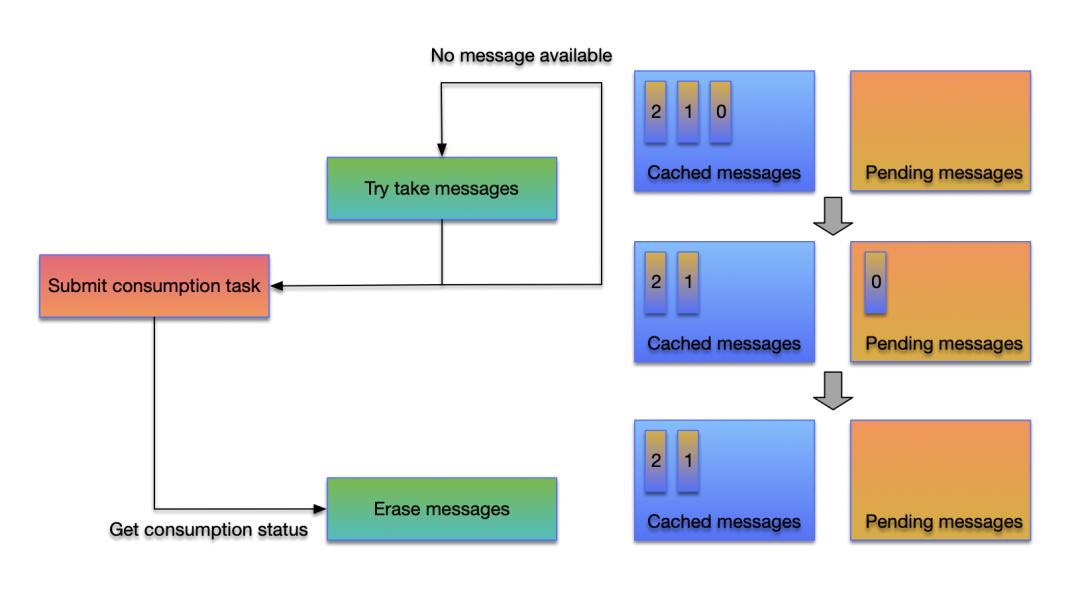
简化之后,上层的消费逻辑基本上只需要负责往消费线程中提交消费任务即可了,任何说得上是 'Process' 的逻辑都在新的 ProcessQueue 完成了闭环。
兼容性与质量保障
Aliware
整个新架构的 SDK 依赖了protocol buffers, gRPC-java, openTelemetry-java 等诸多类库。在简化 RocketMQ 本身代码的同时也带来了一些兼容性问题。RocketMQ 本身保持着对 Java 1.6 的兼容性,然而:
gRPC-java 在 2018 年的 1.15 版本之后不再支持 Java1.6;
openTelemetry-java 只支持 Java8 及以上版本。
在此期间,我们也调研了 AWS、Azure 等友商相关 SDK 的现状,发现放弃对 Java 1.6 的支持已经是业内标准做法。但囿于老客户固守 Java 1.6 的情况,我们也进行了一些改造:
对 protocol buffers 的代码进行了 Java 1.6 的等义替换,并通过了 protocol buffers 所有的单测;
对 gRPC 的代码进行了 Java 1.6 的等义替换,并通过了 gRPC 所有的单测;
对于 openTelemetry ,在进行等义替换的同时进行了大量的功能性测试;
单测方面,目前客户端保证了 75% 以上的行覆盖率,不过相比较优秀的开源项目还有比较长的距离,这一点我们也会在后续的迭代中不断完善。
最后
Aliware
RocketMQ 5.0 是自开源以来架构升级最大的一次版本,具体实现过程还有非常多的细节没有披露,碍于篇幅无法面面俱到,后续开源过程中也欢迎大家在社区中提出更多更宝贵的意见。
相关链接
Pull Request
https://github.com/open-telemetry/opentelemetry-specification/pull/1904
Metrics, Tracing, and Logging
https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
Apache rocketmq apis
https://github.com/apache/rocketmq-apis
OpenTelemetry specification
https://github.com/open-telemetry/opentelemetry-specification
阿里巴巴云原生消息中间件团队招聘中,强烈欢迎大家自荐和推荐!
有意者请联系:
@凌楚 (yangkun.ayk@alibaba-inc.com)
@尘央 (xinyuzhou.zxy@alibaba-inc.com)
点击“阅读原文”,查看更多招聘详情!
﹀
﹀
﹀
解决方案咨询技术交流群:搜索钉钉群号 31704055 加入,可获取云原生详细解决方案资料与专家答疑。


最后
以上就是清新小霸王最近收集整理的关于全面升级 —— Apache RocketMQ 5.0 SDK 的新面貌的全部内容,更多相关全面升级内容请搜索靠谱客的其他文章。








发表评论 取消回复