采用GPU加速时,如遇for循环,则很容易增加代码在GPU上运行的时间开销。在编程时,使用矩阵和向量操作或arrayfun,bsxfun,pagefun替换循环操作来向量化代码。
1 arrayfun函数
[A, B,...] = arrayfun(fun, C, ..., Name, Value)
其中:
1) fun是函数的句柄。
2) C和其他输入是包含函数fun所需输入的数组。每个数组必须具有相同的维度,可以是数值型、字符型、逻辑型、元胞数组、结构体或用户定义的对象数组。如果是用户定义的对象数组,并且重载了subsref或size方法,那么arrayfun具有以下要求:
- size 方法返回需要是double类型的数组。
- 对象数组支持线性索引。
- size方法返回的大小的乘积不能超过数组的限制,这是由数组的线性索引所定义的。
3)Name 是参数名称,Value是相应的值,其中Name是字符串,需加(’ ')。用户可按任意顺序指定多个名称和数值对。
4) A、B和其他输出是fun函数的输出数组,每个数组的大小与每个输入的大小相同。可以返回不同类的输出参数。
例如,定义以下函数:
function [D,E] = myFun(A,B,C)
D = A.*B +C;
E = A + B.*C +50.68;
end
将myFun函数与三个gpuArray对象一起使用,如下:
A = rand(1000,'gpuArray');
B = rand(1000,'gpuArray');
C = rand(1000,'gpuArray');
gd = gpuDevice();
tic;
[D,E] = arrayfun(@myFun, A, B ,C);
wait(gd);
toc
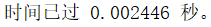
2 bsxfun函数
C = bsxfun(fun, A, B)
- fun函数是任何二元逐元素函数的句柄。
2)fun函数支持标量扩展,但此时A和B的相应维度必须相等或是一维的。
例如,使用bsxfun函数将数组的每一列减去对应列中的最大值。
A = randi(10, 3, 4, 'gpuArray')
C = bsxfun(@minus, A, max(A))
max(A)
注意:
1) 矩阵的指数幂、乘法和除法(^, *, /, )等运算过程仅支持逐元素计算,如arrayfun等函数。
2) 不支持更改输入或输出数组尺寸的操作,例如reshape函数。
3)使用rand,randi 或randn生成随机数组时,无须指定数组的大小。
如下列函数将会报错
function Y = myFunRand(X)
R = rand(size(X));
Y = R .*X;
end
A = rand(5);
B = arrayfun(@myFunRand,A)
%执行上述代码,不会报错
C = rand(5,'gpuArray');
D = arrayfun(@myFunRand,C)
% 执行该处代码,会报错
3 pagefun函数
三种格式语法:
A = pagefun(fun, B)
相当于A(:,:,I,J,...) = fun(B(:,:,I,J,...))fun 是一个带有二维输入参数的函数句柄A = pagefun(fun, B, C, ...)
相当于A(:,:,I,J,...) = fun(B(:,:,I,J,...),C(:,:,I,J,...) ,...)。输入B、C中至少有一个必须是gpuArray,其他输入参数会在调用GPU函数之前自动转换为gpuArray参数。[A, B, ...] = pagefun(fun, C, ...)
pagefun函数有多少输出就调用了多少次fun函数。A的所有元素必须是同一个类,B可以与A不同类。
例如, 利用pagefun对gpuArray的页面执行多个矩阵乘法。假设第一个数组大小是M×K,将其与具有P个页面的第二个K×N阵列执行矩阵乘法。并比较时间:
M = 1000; % output number of rows
K = 2000; % matrix multiply inner dimension
N = 1000; % output number of coloumns
P = 200; %number of pages
A = rand(M, K, 'gpuArray');
B = rand(K, N, P,'gpuArray');
gd = gpuDevice();
tic;
% perform matrix multiplication of A and B on every page of B without
% using pagefun
for i = 1:P
D(:, :, i) = A * B(:,:,i);
end
wait(gd)
toc
gd = gpuDevice();
tic;
% perform matrix multiplication of A and B on every page of B with
% using pagefun
D = pagefun(@mtimes,A, B);
wait(gd);
toc
注意:在执行代码时,将无关D变量清除。
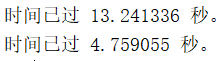
页面越多,pagefun的优势越突出。
4 代码示例
代码优化示例: 使用快速卷积过滤信号
使用低通FIR滤波器对信号列执行快速卷积。该信号是振动信号,采样频率25600。Matlab代码名为fastConvolution,文件名为data.mat。
4.1 CPU运行
load data.mat;
[N M] = size(data);
t=1:N;
%采样频率
fs=25600;
%时域波形
figure
plot(t/fs,data(:,1),'k');
filter1 = [10,9,8,7,6,5,4,1,0,-1,-2,-3,-4,-5,-6,-7,-8,-9,-10];
tic;filteredData = fastConvolution(data, filter1'); toc
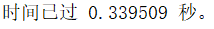
4.2 GPU运行(不做优化)
load data.mat;
gd = gpuDevice();
tic;filteredData = fastConvolution(gpuArray(data), filter1');
wait(gd);
toc
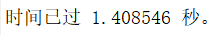
可以看到CPU比GPU快5倍左右。
4.3 GPU运行(函数优化)
利用bsxfun对上述函数进行优化,优化函数命名为fastConvolutionVectorized, 文件名为fastConvolutionVectorized.m
function filteredData = fastConvolutionVectorized(data,filter)
% Filename: fastConvolutionVectorized.m
% Description: This function performs convolution on the columns
% of a signal(array data) using a filter
% (vector filter)(vectorized version using a bsxfun)
% Authors: Ploskas, N., & Samaras, N.
% Syntax: filteredData = fastConvolutionVectorized(data, filter)
% Input:
% -- data: the signal (array)
% -- filter: the filter (vector)
% Output:
% --filteredData: the filtered signal (array)
[m,~] = size(data); % get the size of the signal
% pad filter with zeros and calculate its DFT
filterf = fft(filter,m);
% transform each column of the signal
dataf = fft(data);
% multiply each column of the signal by the filter and
% compute the inverse transform
filteredData = ifft(bsxfun(@times,dataf,filterf));
end
优化后CPU上运行
load data.mat;
filter1 = [10,9,8,7,6,5,4,1,0,-1,-2,-3,-4,-5,-6,-7,-8,-9,-10];
tic;filteredData = fastConvolutionVectorized(data, filter1'); toc
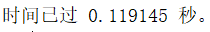
比不改进是快了将近3倍
优化后GPU上运行
load data.mat;
gd = gpuDevice();
tic;filteredData = fastConvolutionVectorized(gpuArray(data), filter1');
wait(gd);
toc
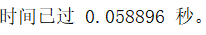
比未优化前的1.4秒快了28倍。
因此,向量化代码有助于CPU和GPU版本的Matlab程序高效地运行,而向量化程序在GPU上的优化效果比在CPU上更明显。
本文相关数据链接:
链接:https://pan.baidu.com/s/1kKIsse9f4d4s4REMWzhUCw
提取码:1c7x
有帮助的话,请帮忙点赞支持,谢谢!
最后
以上就是明理大白最近收集整理的关于基于Matlab的GPU加速---for循环处理的全部内容,更多相关基于Matlab内容请搜索靠谱客的其他文章。








发表评论 取消回复