
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
本文主要是基于LSTM(Long Short-Term Memory)长短期记忆神经网络来实践多变量序列预测,并完成对未来指定步长时刻数据的预测、分析和可视化,手把手教你去搭建属于自己的预测分析模型。
本文主要分为:LSTM模型简介、数据探索分析、模型构建测试三个部分。
一、LSTM模型简介
既然说到了LSTM,就要简单的介绍一下RNN(Recurrent Neural Network,RNN)循环神经网络了,LSTM神经网络模型可以看做是RNN的一种,RNN是一类专门用于处理时序数据样本的神经网络,它的每一层不仅输出给下一层,同时还输出一个隐状态,给当前层在处理下一个样本时使用。
RNN可以根据之前出现的信息对当前的信息进行推断,特别是在语言处理中,RNN可用于根据上文预测下一个将要出现的词。但是它只能处理一定间隔的信息,如果上文间隔过远,就有可能出现难以联想的情况。这时候LSTM就应运而生了。LSTM的展开结构中与RNN的不同主要是存在控制存储状态的结构,如下图是经典的RNN模型和LSTM模型的展开结构示意图:
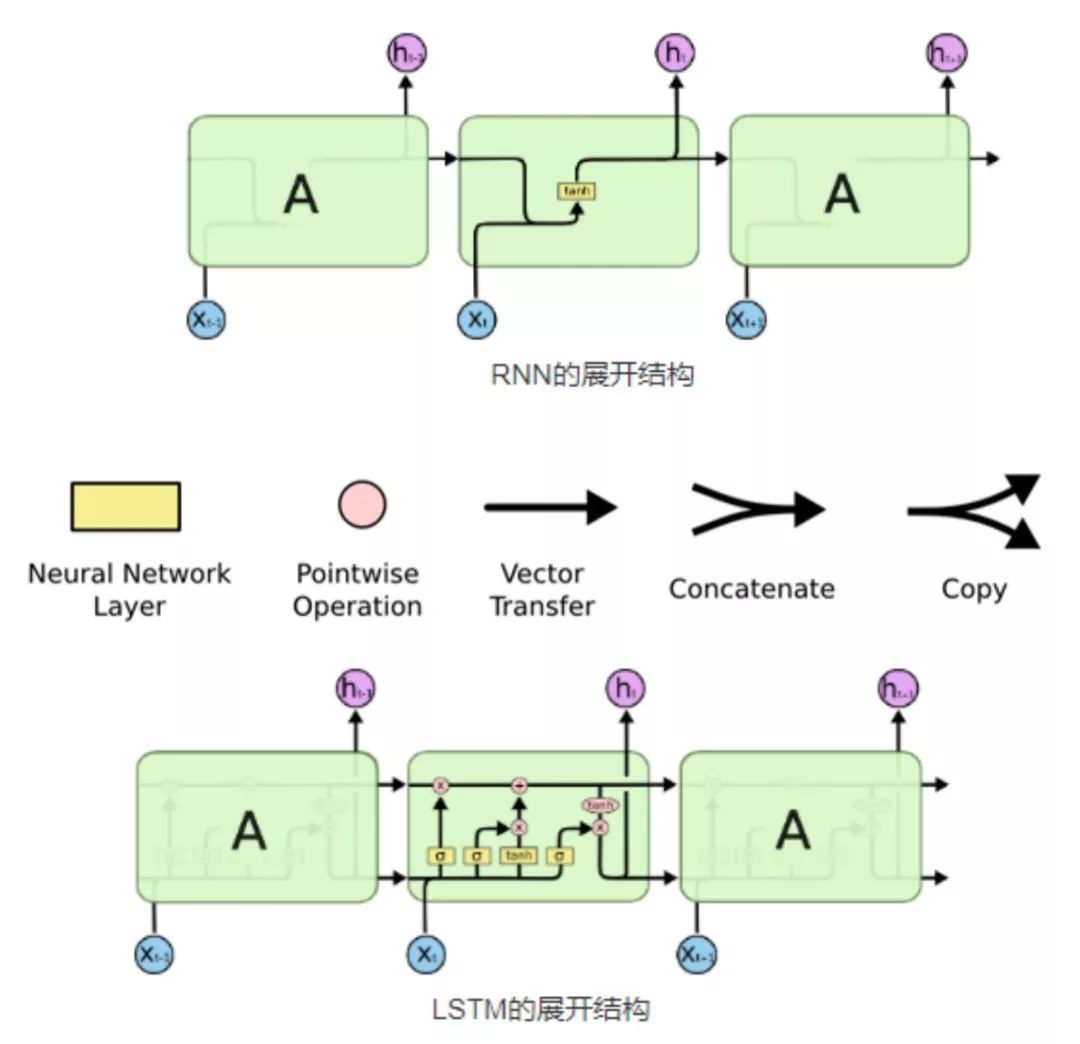
想要深入理解LSTM的机理模式,弄清楚LSTM中的三种门是非常重要的,LSTM模型中主要包含了:忘记门、输入层门和输出层门。各个门的简单介绍说明如下表所示:

这里关于LSTM模型详细的原理介绍说明就到这里,想要深入搞明白其中的运行机制还是需要花一定的时间去消化理解才可以的。
本文今天主要是借助于LSTM这一深度学习模型来对手中的时序序列数据进行建模分析,构建我们的序列数据预测模型,来对未来多步时刻进行预测分析。
二、数据探索分析
这里我们使用到的数据集来源于中央监测站某地公开的大气常规六因子的监测数据,数据集部分截图如下所示:
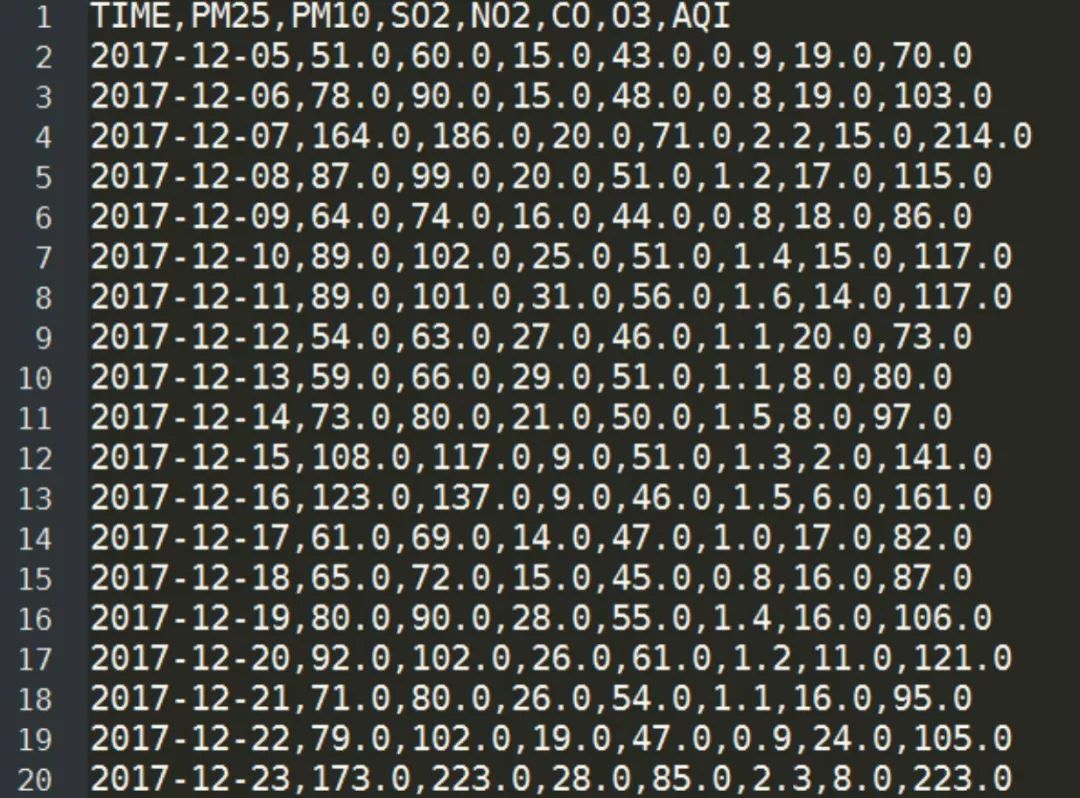
其中,TIME,PM25,PM10,SO2,NO2,CO,O3和AQI分别表示:监测时间、pm2.5、pm10、so2、no2、co、o3和空气质量指数。
为了对现有的数据集做一个简单的数据探索分析,一些必要的统计计算和可视化分析是比不可少的,这里我推荐一款数据概览分析工具pandas_profile,顾名思义,就是基于pandas开发的一款数据概览分析工具,使用非常地方便,下面我们基于该模块进行数据探索,具体的代码量很少,如下所示:
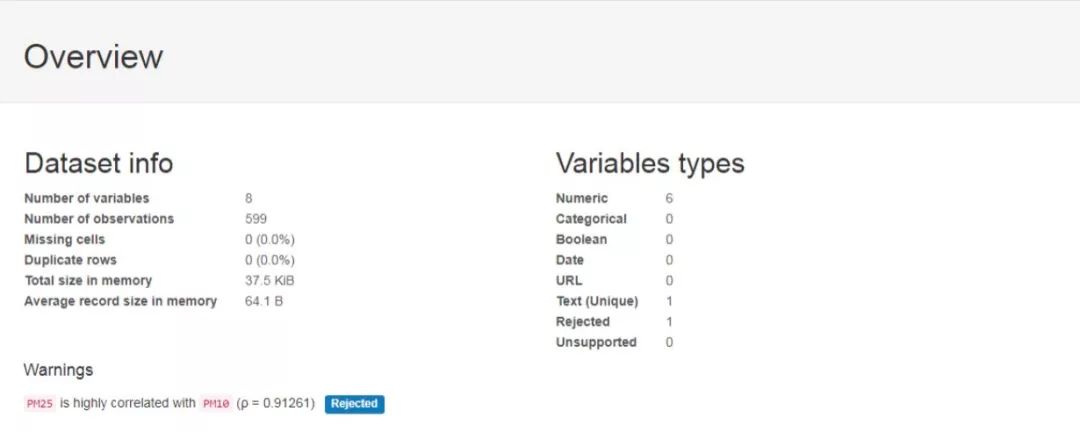
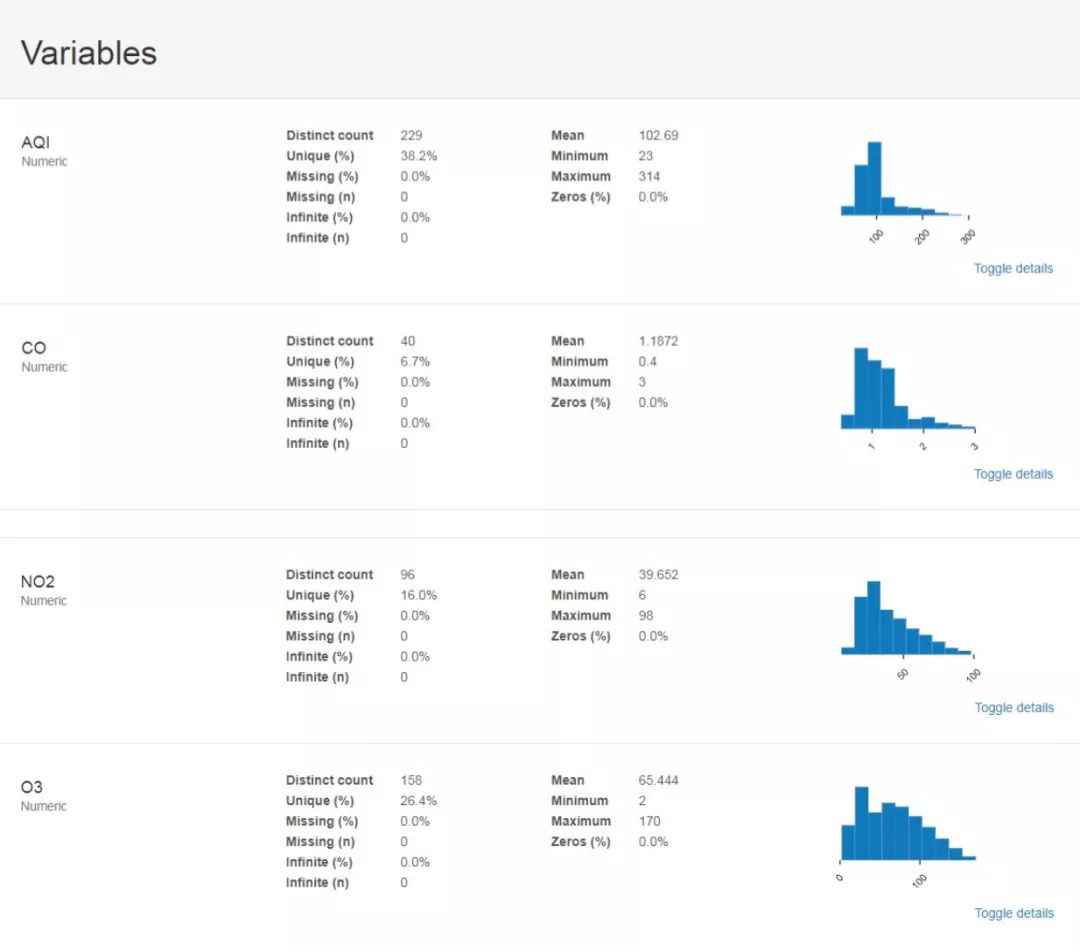
#encoding:utf-8 import pandas as pd import pandas_profiling df = pd.read_csv('dataset.csv') profile=pandas_profiling.ProfileReport(df) profile.to_file('dataset.html') 运行结束后,本地的dataset.html中已经存储了我们所需要的相关分析结果了,内容截图如下。首先是数据集的整体概览性的介绍以及各个因子的统计计算与分布计算结果展示:
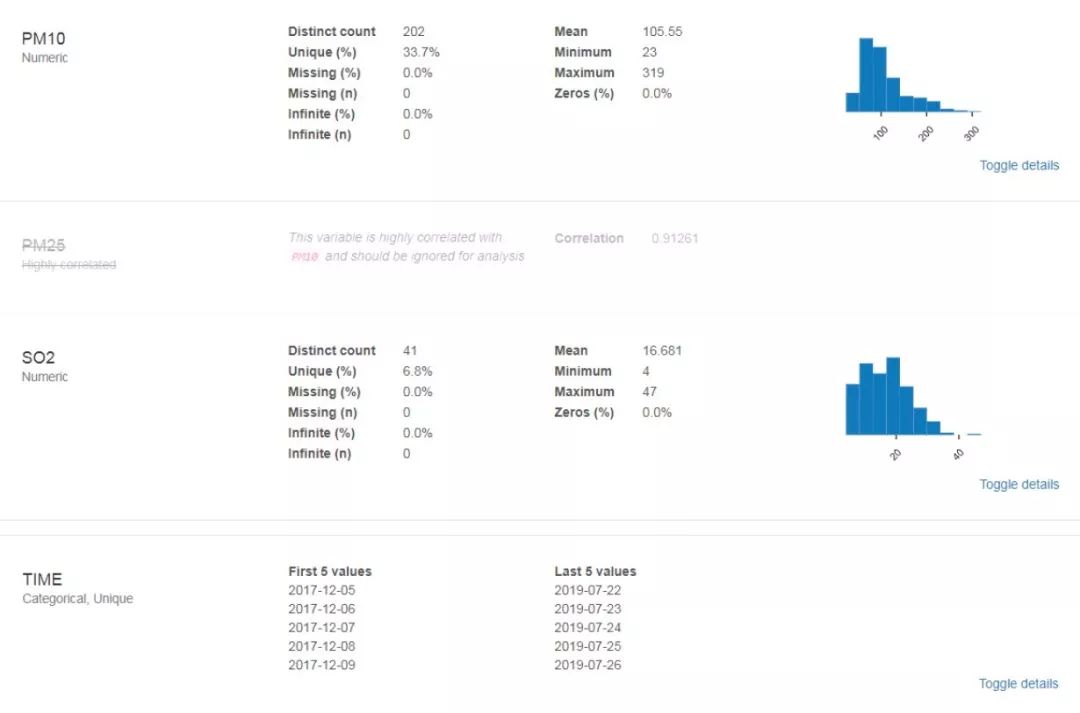
接下来是因子相关性计算结果,这里一共提供了四种计算方式下得到的分析结果,其中,前三种就是统计学中的相关性度量的三种手段,最后一种我也不太清楚是什么算法,希望了解的大佬能够指点一下,不胜感激。
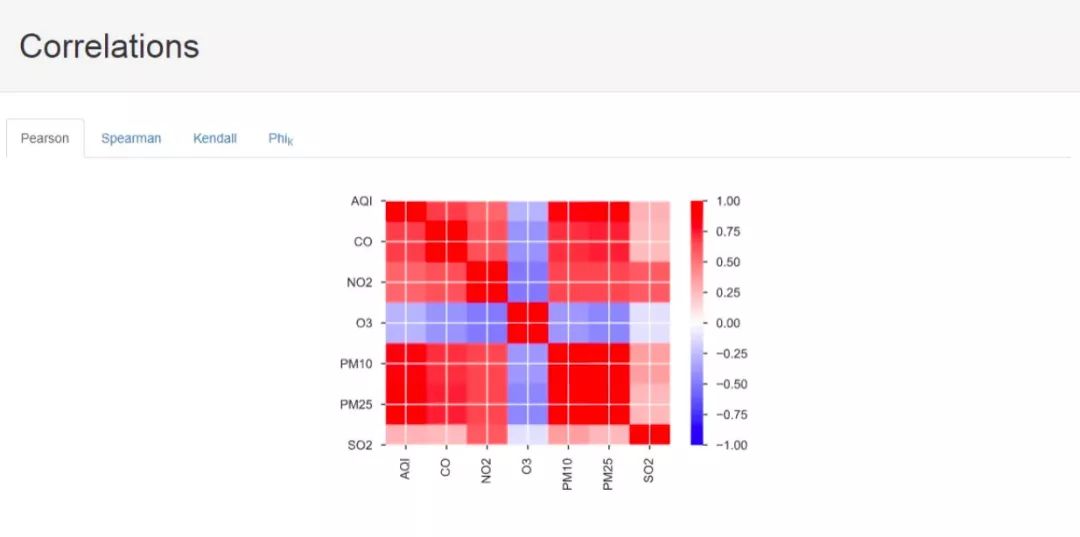
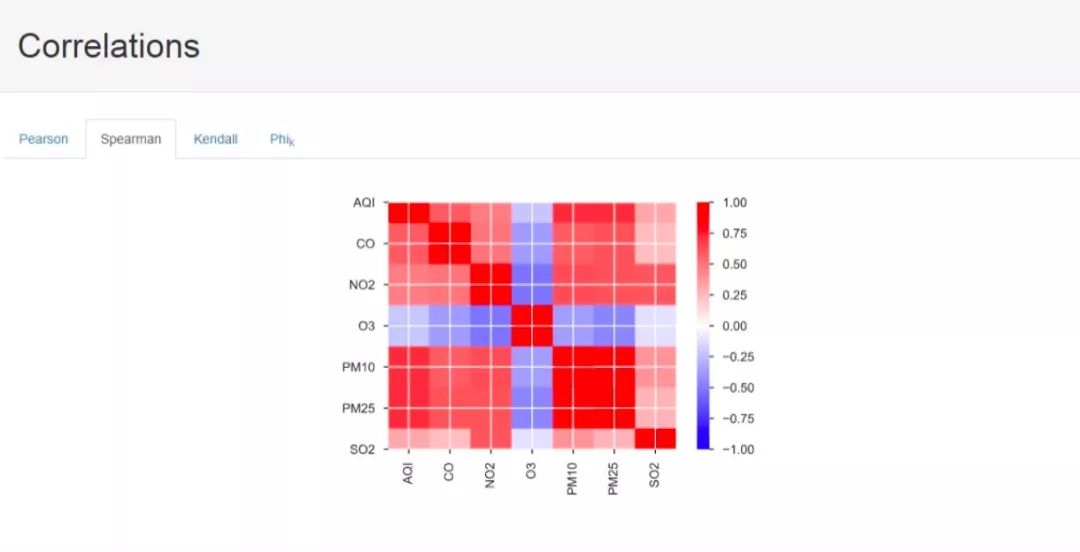
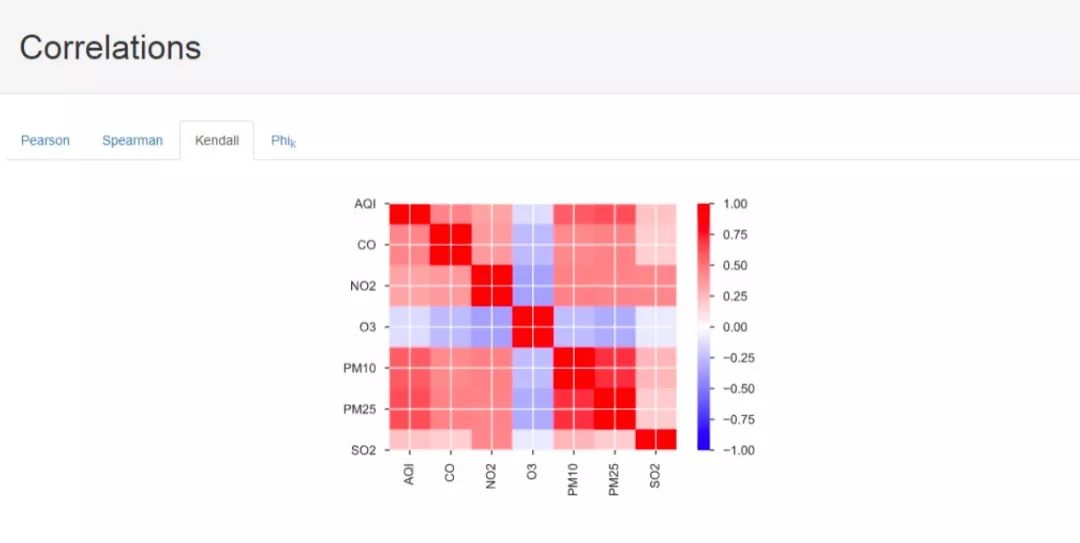
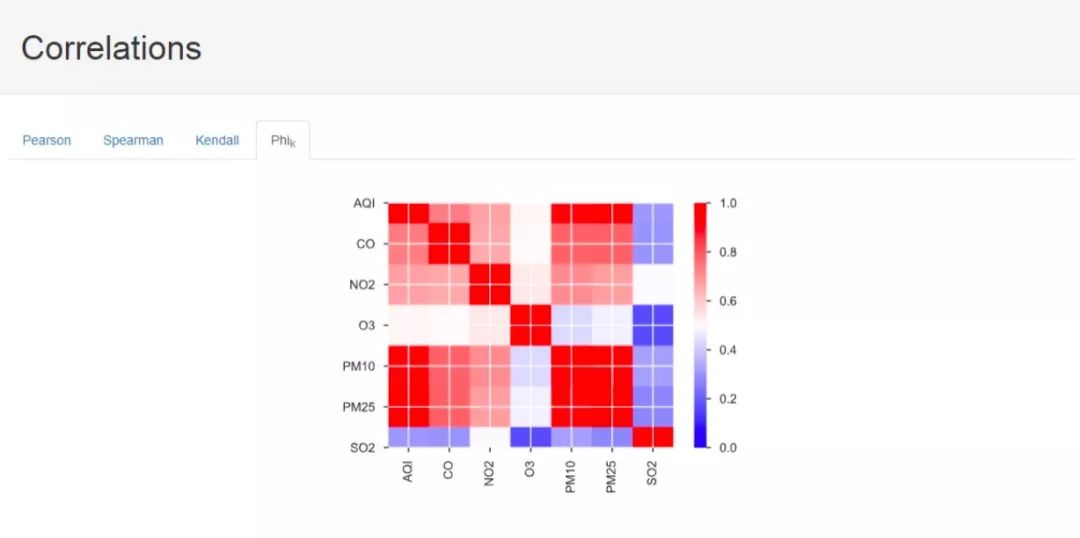
接下来是缺失值等信息:
完成了上述的数据概览分析后,为了能够更加直观地看到不同因子的变化趋势,我们基于交互式的可视化手段进行了可视化分析,数据截图如下所示:
个人感觉这种交互式的可视化展示手段相比matplotlib静态的展现形式要好点。
到这里,我们的数据探索分析差不多就结束了,我想说的是,完成好整个机器学习或者是深度学习过程,每一步都是不可或缺的。数据探索分析有助于我们掌握数据集中不同因子的统计分布特征,数据可视化分析能够帮助我们发现数据集的整体趋势与异常点等特征。
三、模型构建测试
接下来就进入到了我们的核心实战环节,模型的搭建,这里模型的搭建主要分为几个步骤:
1、移动滑窗数据集构建
2、训练集、测试集分割
3、模型搭建
4、多步序列滚动预测功能实现
5、结果数据可视化展示
接下啦,我们针对上述的5个步骤进行一一说明和介绍:
1、移动滑窗数据集构建
想要对时序序列的数据进行值预测,数据集的构建是很重要的一步,我们需要基于原始的数据集来构建得到一个有监督的数据集来让我们的模型学习到原始时序序列数据中的特点,从而实现对未来时刻的预测,滑窗数据集构建原理示意图如下:
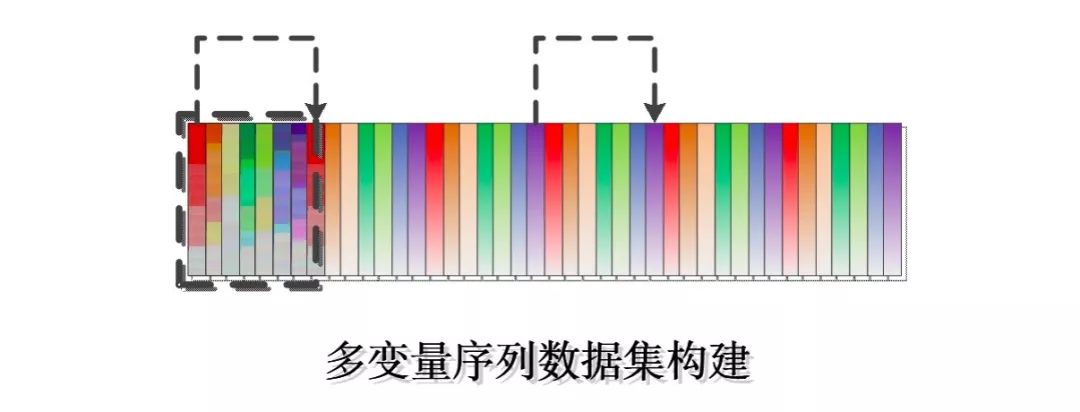
这里具体实现如下:
1.def sliceWindow(data,step): 2. ''''' 3. 移动滑窗创建数据集 4. ''' 5. X,y=[],[] 6. for i in range(0,len(data)-step,1): 7. end=i+step 8. oneX,oney=data[i:end,:],data[end, :] 9. X.append(oneX) 10. y.append(oney) 11. return np.array(X),np.array(y) 上述10行左右的代码实现了我们所需数据集的创建工作。
2、训练集、测试集分割
在有监督模型的训练过程中,我们会将原始的数据集进行划分,得到训练数据集和测试数据集,其中,训练数据集用于模型的训练学习,测试数据集用于模型的评估和测试,这里没有基于sklearn中的数据集划分函数train_test_split来做主要是因为:我们要做的是时序序列数据的预测分析,而train_test_split是随机对原始的数据集划分的,我们需要保留原始数据集的时序性,这也是时序序列数据预测不同于其他数据值预测的一个地方。我们划分数据集的具体实现如下:
1.def dataSplit(dataset,step,ratio=0.70): 2. ''''' 3. 数据集分割 4. ''' 5. datasetX,datasetY=sliceWindow(dataset,step) 6. train_size=int(len(datasetX)*ratio) 7. X_train,y_train=datasetX[0:train_size,:],datasetY[0:train_size,:] 8. X_test,y_test=datasetX[train_size:len(datasetX),:],datasetY[train_size:len(datasetX),:] 9. X_train=X_train.reshape(X_train.shape[0],step,-1) 10. X_test=X_test.reshape(X_test.shape[0],step,-1) 11. print('X_train.shape: ',X_train.shape) 12. print('X_test.shape: ',X_test.shape) 13. print('y_train.shape: ',y_train.shape) 14. print('y_test.shape: ',y_test.shape) 15. return X_train,X_test,y_train,y_test 其中,ratio表示的是训练集数据集所占的比例。
3、模型搭建
自从Keras出现以后,深度学习模型的搭建变得很容易,这里我们基于Keras实现了LSTM模型的搭建,具体实现如下:
1.def seq2seqModel(X,step): 2. ''''' 3. 序列到序列堆叠式LSTM模型 4. ''' 5. model=Sequential() 6. model.add(LSTM(256, activation='relu', return_sequences=True,input_shape=(step,X.shape[2]))) 7. model.add(LSTM(256, activation='relu')) 8. model.add(Dense(X.shape[2])) 9. model.compile(optimizer='adam', loss='mse') 10. return model 从上面可以看到,模型的搭建即为简化,我们专门把模型的搭建拆解为单独的函数,最主要的考虑就是:解耦合。模型需要修改的时候不需要去修改整体的功能,可以单独处理这个函数,也可以新增一个模型函数都是非常简单的。
比如,我们基于Keras同样实现了双向LSTM神经网络模型,如下:
隐藏层的层数和隐藏层的神经单元数都是可以依据自己的实际需要进行调整的。
4、多步序列滚动预测功能实现
很多博客文章里面都有关于LSTM时序序列的预测,但是很多都是只停留在单个时刻的预测上,在实际情况中我们往往需要的是对未来一段时间内的数据进行预测,也就是我们常说的多步预测模型,这里我们同样实现了多步预测功能,具体如下:
和模型搭建处理的思想一致,我们将单独的功能都拆解为独立的处理函数,方便后面的功能修改与增加等操作。
5、结果数据可视化展示
结果数据可视化展示同样是非常重要的一环,我们通过预测数据与真实数据的拟合程度以及走势来分析模型的性能,可视化分析实现代码如下:
1.def dataCruvePloter(data_list,future_list,save_path='dataCruvePloter.png'): 2. ''''' 3. 结果曲线可视化 4. ''' 5. plt.clf() 6. plt.figure(figsize=(20,12)) 7. factor=['PM25','PM10','SO2','NO2','CO','O3','AQI'] 8. dataset=[] 9. for i in range(len(data_list)): 10. dataset.append([float(O) for O in data_list[i][1:]]) 11. for j in range(7): 12. D1,D2=[one[j] for one in dataset],[one[j] for one in future_list] 13. plt.subplot(2,4,j+1) 14. plt.plot(list(range(len(D1))),D1,label=factor[j]+' True') 15. plt.plot(list(range(len(D1),len(D1)+len(D2))),D2,label=factor[j]+' Predict') 16. plt.legend(loc='best',ncol=2) 17. plt.savefig(save_path) 完成了上述5步的所有工作,接下来就可以调用我们的模型进行训练、预测和分析使用了。代码实现如下所示:
1.#数据集加载 2.with open('dataset.txt') as f: 3. data_list=[one.strip().split(',') for one in f.readlines()[1:] if one] 4.dataset=[] 5.for i in range(len(data_list)): 6. dataset.append([float(O) for O in data_list[i][1:]]) 7.dataset=np.array(dataset) 8.step=7 9.X_train,X_test,y_train,y_test=dataSplit(dataset,step) 10.#model=bidirectionalModel(X_train,step) 11.model=seq2seqModel(X_train,step) 12.model.fit(X_train,y_train,epochs=50,verbose=0) 13.#模型测试样例 14.test=[ 15. [30.0,58.0,7.0,24.0,0.9,83.0,103.0], 16. [43.0,72.0,6.0,23.0,1.1,85.0,103.0], 17. [66.0,105.0,6.0,22.0,1.3,134.0,103.0], 18. [54.0,94.0,7.0,27.0,1.1,125.0,103.0], 19. [64.0,90.0,6.0,19.0,1.2,127.0,103.0], 20. [59.0,92.0,6.0,20.0,1.1,126.0,103.0], 21. [61.5,91.0,6.0,19.5,1.15,134.0,103.0] 22. ] 23.#真实值 [38.0,66.0,5.0,17.0,1.2,138.0,103.0] 24.test=np.array(test) 25.test=test.reshape((1,step,7)) 26.y_pre=model.predict(test,verbose=0) 27.print('y_pre: ',y_pre) 28.future_list=predictFuture(model,dataset,7,step,60) 29.dataCruvePloter(data_list,future_list,save_path='dataCruvePloter.png') 结果输出如下:
1.y_pre: [40.86961,65.5033,4.8647,30.08823,1.16613,136.06862,100.5173] 在我之前的博文里面写过有关于回归模型评价指标计算相关的文章,这里贴出来,如果需要计算相应的指标来评估模型性能的时候可以使用,具体实现如下:
1.#!usr/bin/env python 2.#encoding:utf-8 3.from __future__ import division 4. 5. 6.''''' 7.__Author__:沂水寒城 8.功能:计算回归分析模型中常用的四大评价指标 9.''' 10. 11.from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_score 12. 13. 14. 15.def calPerformance(y_true,y_pred): 16. ''''' 17. 模型效果指标评估 18. y_true:真实的数据值 19. y_pred:回归模型预测的数据值 20. explained_variance_score:解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因变量 21. 的方差变化,值越小则说明效果越差。 22. mean_absolute_error:平均绝对误差(Mean Absolute Error,MAE),用于评估预测结果和真实数据集的接近程度的程度 23. ,其其值越小说明拟合效果越好。 24. mean_squared_error:均方差(Mean squared error,MSE),该指标计算的是拟合数据和原始数据对应样本点的误差的 25. 平方和的均值,其值越小说明拟合效果越好。 26. r2_score:判定系数,其含义是也是解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因 27. 变量的方差变化,值越小则说明效果越差。 28. ''' 29. model_metrics_name=[explained_variance_score, mean_absolute_error, mean_squared_error, r2_score] 30. tmp_list=[] 31. for one in model_metrics_name: 32. tmp_score=one(y_true,y_pred) 33. tmp_list.append(tmp_score) 34. print ['explained_variance_score','mean_absolute_error','mean_squared_error','r2_score'] 35. print tmp_list 36. return tmp_list 37. 38. 39.if __name__=='__main__': 40. y_pred=[22, 21, 21, 21, 22, 26, 28, 28, 33, 41, 93, 112, 119, 132, 126] 41. y_true=[23, 23, 23, 22, 23, 26, 28, 28, 32, 37, 56, 64, 68, 74, 75] 42. calPerformance(y_true,y_pred) 模型预测结果的可视化分析曲线如下图所示:
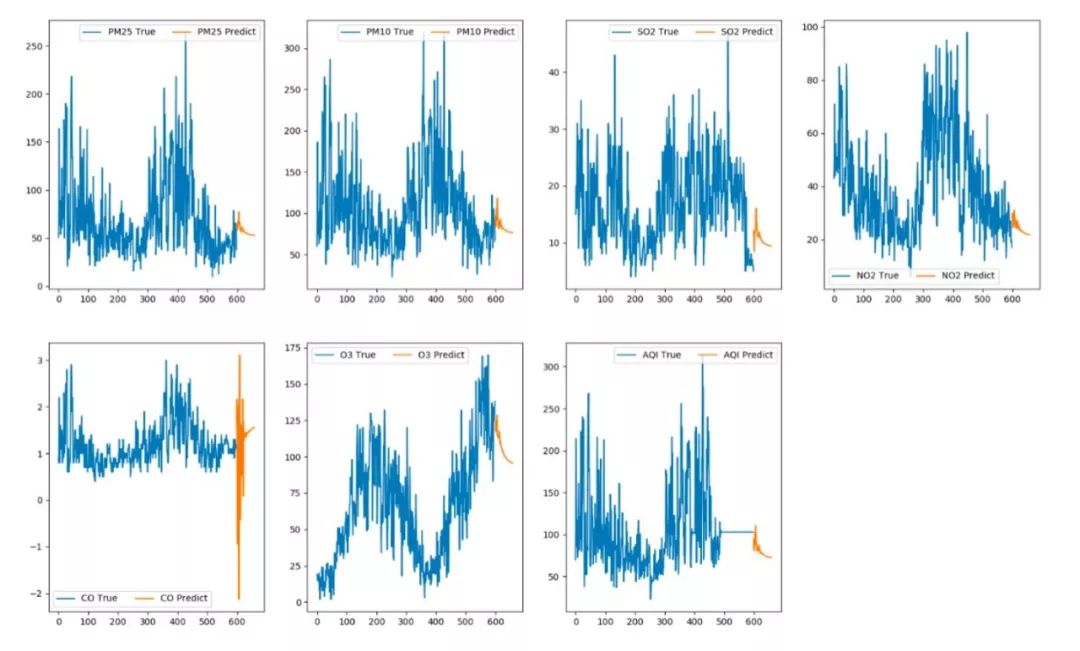
综合业务背景和预测结果来说:co的预测出现了负数这是不正确的,可能跟模型中数据量有关系,毕竟我们数据集一共只有几百条的数据记录,这点数据量对于深度学习模型来说实在是少得可怜,我们今天的工作主要就是完整地去实践LSTM多变量多步序列预测模型,手把手教你去搭建属于自己的预测分析模型。
感兴趣的话可以拿我们提供的代码去实地跑一下,熟悉一下整个建模处理分析的过程。
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
2019全球移动开发者技术峰会
送 限 时 免 费 门 票 50 张


(扫码报名-点击免费票-邀请码填写:Python中文社区-提交审核)
最后
以上就是飞快发带最近收集整理的关于基于LSTM的多变量多步预测模型的全部内容,更多相关基于LSTM内容请搜索靠谱客的其他文章。





![[深度学习] 使用LSTM实现股票预测](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)


发表评论 取消回复