TinyML无疑大大拓展了机器学习和嵌入式应用的疆界。自此,机器学习不再囿于云端超级计算机,而是可以被隐藏于众多小到可以忽略的电子零件中;嵌入式应用也不再局限于简单的信号处理,而是可以“看懂”“听懂”“感受到”周围的世界。
——魏兰
随着物联网数据的爆发,物联终端迎来了“幸福的小烦恼”。
众所周知,在物联网架构中,传感终端负责收集感知数据、处理并传输至 “云端”,由云平台统一进行数据存储、可视化和算法驱动决策的过程,人工智能和机器学习在其中扮演着不可或缺的角色。但面对物联数据的爆发式增长和对数据时效性要求越来越高等现状,传统物联构架存在终端功耗高、应用延迟大、数据安全隐患等问题,在一定程度上限制了物联场景落地进程和应用拓展。
在此背景下,“节能、高效、智能”已然成为物联市场最直接的需求。最明显的是,近年“端智能”成为行业热词,边缘计算以及TinyML(微型机器学习)等技术相继走进人们的视野。尤其是TinyML(微型机器学习)被业界人士誉为是AI和IoT技术的终极融合,甚至可推动人工智能“新一轮革命”,它能把数据“采集+推理+决策”融为一体,使海量的物联设备也能在电池供电下连续数年运行机器学习模型,进一步拓展端侧人工智能的“新疆界”。
01
什么是TinyML
TinyML是Tiny Machine Learning的缩写,即微型机器学习,是机器学习、嵌入式物联网(IoT)和边缘计算等学科的融合,指在微控制器上部署、运行机器学习推理模型的技术,属于超低功耗端侧人工智能应用。
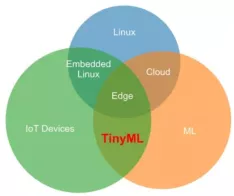
TinyML的微型体现在以下几个方面:
TinyML模型的终端功耗一般在几mW级别,甚至更低;
TinyML模型占用的内存一般在几百kB以下;
TinyML推理时间在ms级别,一般在1s内完成。
02
TinyML能解决什么问题
TinyML的爆发正是源起于物联网场景中的实时数据需求。根据全球移动通信系统协会(GSMA)和国际数据公司(IDC)发布的报告显示:预计2025年全球物联网总连接数将由2019年的120亿上升到246亿,全球的物联数据量将达到163ZB,机器学习所触及的分析数据总量将增长至原来的100倍,达到1.4ZB,且物联网实时数据占比高到95%。数据的爆发式增长和硬件处理能力的提升使得“端侧机器学习算法”的规模在最近几年呈指数级增长, TinyML也因此应运而生。
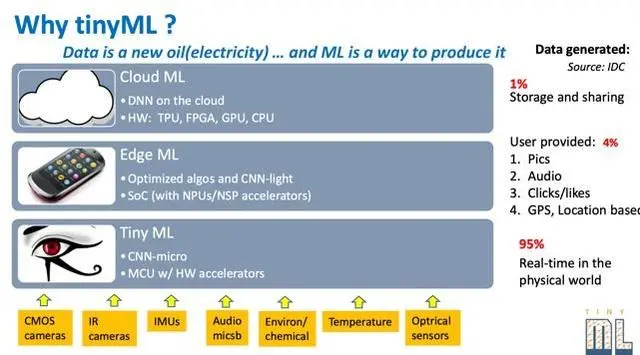
传统的机器学习一般是将数据传输到云端,并在云端进行存储、训练和推理。但这种方式并不适用于物联网领域:
电量消耗。无线物联终端具有体积小、分布广、数量众多等特点,一般由电池驱动供电,大量实时数据传输将大幅消耗有限的电量资源,使得“低功耗”物联网形同虚设。
应用延迟。数据传输到云端、进行计算会造成一定的延时,因此无法保证数据的实时性。这对于某些场景是致命的,尤其是在一些大型生产场景中,一秒的延时将带来巨大的经济损失。
隐私泄露风险。在数据传输和云端集中存储过程中存在数据泄露的风险,“端智能”则能降低这种风险。
带宽和存储资源浪费。在传统的机器学习中,90%以上的无效数据占据着大部分的传输带宽和云端存储空间,造成了极大的资源浪费。
TinyML的出现很大程度上降低了传统机器学习方式对计算资源和电量的依赖,帮助数量众多的端侧微控制器实现高效数据传输和智能升级,这极大拓展了物联设备的应用场景。比如,城市中的摄像头加装AI端侧推理模型,选择仅“异常数据上传”模式,不仅能大幅提升数据传输效率,还能降低运行功耗,这使得原本需要“高功耗、高成本“技术实现的物联场景可以广泛应用“低功耗、低成本”的LPWAN技术,从而降低成本推动更多物联应用落地。
03
TinyML的工作方式
与传统机器学习一致,TinyML在云端收集数据并训练,最大的不同在于训练后期模型的优化和部署。为了适配嵌入式终端有限的计算资源,TinyML必须“深度压缩”自己,一般包含模型蒸馏(Distillation)、量化(Quantization)、编码(Encoding)3个过程,并在编译后才能部署到终端上。
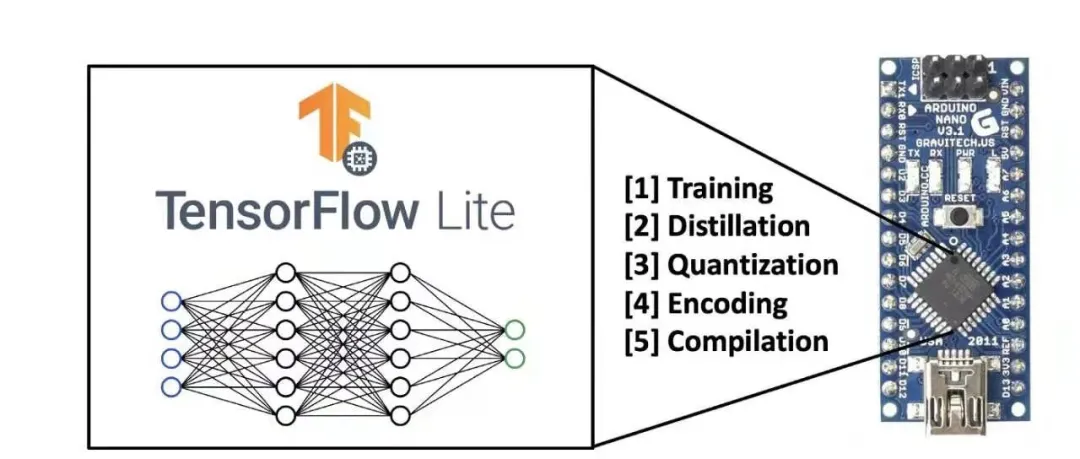
TinyML模型生成过程
模型蒸馏是为了创建一个更紧凑、占用内存更小的模型,包含剪枝和知识蒸馏两种方式。剪枝试图去除对输出预测影响较小的神经元,网络在剪枝后的架构上重新训练,并微调输出。知识蒸馏是通过复制大网络的输出路径来引导小网络的准确行为,以此简化模型。
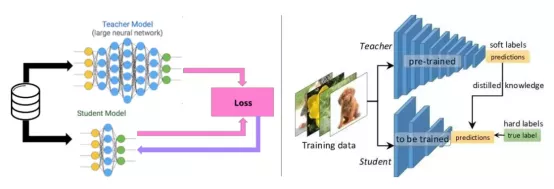
知识蒸馏过程示意图
量化(Quantization) 是将连续取值(或大量可能的离散取值)的浮点型模型权重或流经模型的张量数据定点近似为有限多个离散值的过程,以更少位数的数据类型用于近似表示32位浮点型数据,从而达到减少模型尺寸大小、内存消耗及加快模型推理速度等目标。例如,在可接受的精度损失范围之内, 8位整型量化可减少75%的模型大小,推理速度快4倍。
编译是模型能在嵌入式终端上运行的最后一步。一旦模型被量化和编码,它就被转换成一种格式,该格式可以被某种形式的小型神经网络解释器解释,其中最流行的可能是 TF Lite(大小约 500kb)和 TF Lite Micro(大小约 20kb)。然后将该模型被编译成 C 或 C++(大多数微控制器都能有效地使用内存),并由设备上的解释器运行。
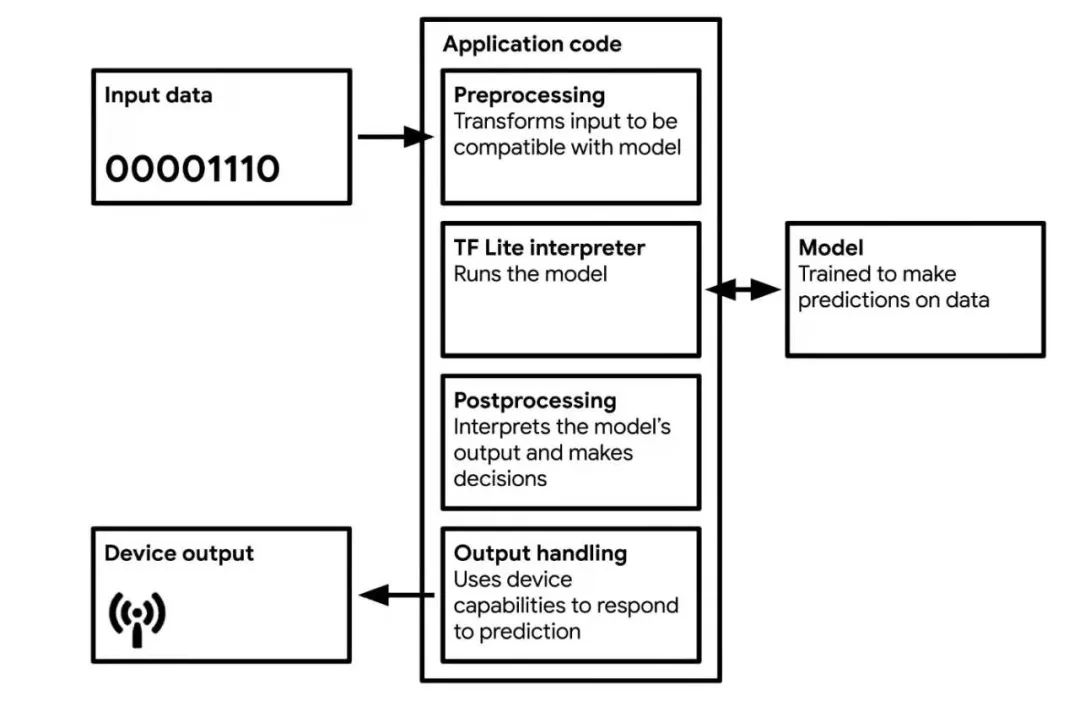
TinyML应用程序工作流
04
TinyML的应用场景
根据Silent Intelligence的预测,在未来5年,TinyML将触发超过700亿美元的经济价值,并且保持超过27.3%的复合年均增长率(CAGR)。2020年2月在硅谷举行的TinyML峰会吸引了英伟达、ARM、高通、谷歌、微软、三星等公司参加,纷纷展示各自在该领域的最新成果。除了巨头公司,众多初创公司也纷纷立足于该领域,试图加速TinyML的落地。
高通推出超低功耗的always-on计算机视觉解决方案,使用系统电源小于1mA标准锂电池,典型帧率为1-30 fps。
Eta Compute公司的ECM3532适用于低功耗IoT,该芯片具有512KB闪存和256KB SRAM,可实现长待机状态下的图像处理和传感聚合,功耗仅为100uW。Eta Compute展示的案例包括语音、图像和视频识别,以及在工业传感场景中的应用。
QuickLogic的子公司SensiML将TinyML用于工业预测性维护的相关场景中,可以帮助客户快速构建智能传感方案。
Edge Impluse、Always.AI等公司通过提供端到端的TinyML as a service服务,将数据收集、模型训练验证、模型压缩和编译部署等一系列过程标准化,加速TinyML应用的开发。
语音和视觉唤醒是TinyML的最典型应用,非常适合提供隐私保护、高效、迅速且离线的判断。一旦检测到了所需的唤醒词,比如“Siri”“小爱同学”,该应用就会唤醒后续的处理程序,而无需一直将用户的语音上传到云端。同样的原理,视觉唤醒一直检查特定的图像特征是否出现,这可以是有缺陷的产品、破碎的玻璃、漏油的管道,一旦检测到这些异常,立即触发后续的报警和其他操作。
TinyML的应用场景
放眼整个物联网市场,TinyML还有更多的应用价值。数以亿计的微控制器和各种各样的传感器结合在一起,在未来会激发一些非常有创意、更具实用价值的TinyML应用,极大的拓展LPWAN等低功耗技术的应用,从而推动泛在物联的部署。与此同时,TinyML也会以意想不到的方式彻底颠覆我们的生活习惯,跟“5G、WIFI”等技术一样助力构建更加智能化的世界。
除了模型压缩和算法结构优化之外,TinyML还涉及模型部署和远程升级需要。下一篇文章将介绍TinyML与LPWAN网络的有机融合,解读ZETA Server如何携手TinyML打造端到端的泛在物联新生态。
最后
以上就是落后小蝴蝶最近收集整理的关于终端遇到AI:TinyML如何拓展端侧人工智能和LPWAN的“新疆界”的全部内容,更多相关终端遇到AI:TinyML如何拓展端侧人工智能和LPWAN内容请搜索靠谱客的其他文章。








发表评论 取消回复