我是靠谱客的博主 俊秀诺言,这篇文章主要介绍联邦学习-区块链论文笔记:FLChain: A Blockchain for Auditable Federated Learning with Trust and Incentive,现在分享给大家,希望可以做个参考。
链接:
IEEE Xplore Full-Text PDF:ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8905038
作者:Xianglin Bao(中科大团队)
Motivation:
1)FL链缺乏对恶意训练节点的审计,不诚实的合作会扰乱模型的训练效果;
2)中心化服务器容易受到单点失误的攻击并且会将损失带给所有的训练节点;
3)在没有奖励制度的情况下,训练节点不情愿去训练本地模型。同时,由于担心不诚实的合作节点会窃取信息,训练节点也不愿意合作。 Idea:
梯度生成:该过程中,FL的训练节点在本地独立训练它们的模型。在每个本地机器学习迭代结束后,可验证并且加密后的本地梯度将被上传至FLChain链上;
备注:加密算法使用秘密共享机制。每一个加密以及解密的梯度部分都需要可审计的证明来阻止不诚实的行为。常用的秘密共享机制为加性秘密共享,便于梯度聚合。
梯度聚合:该过程中,中心server聚合本地上传的所有梯度值并将聚合结果上传至FLChain链,当然所有server中只有leader节点才能将聚合结果最终上传至FLChain链,leader节点的选取标准是选择可信度最高的节点。
协同解密:该过程中,本地训练节点从FLChain链下载聚合结果,并且协同解密。解密获得最新global model后,本地训练节点然后更新模型参数并且开始下一轮的本地模型训练。
强制结束:该过程中,FLChain模型会结束有问题的合作模型训练。仅当诚实节点在FL内的确发现了错误行为才会发生。 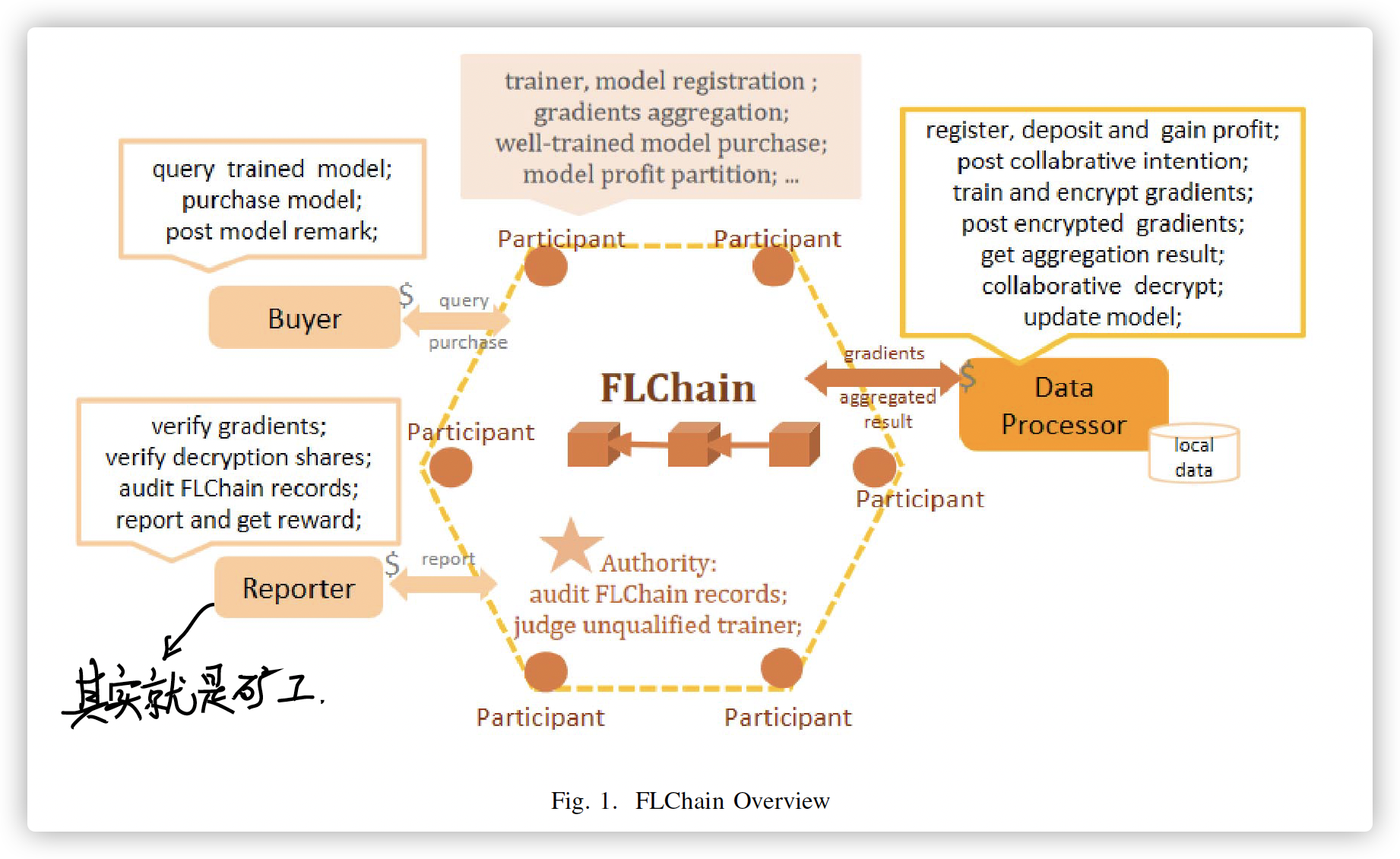
FLChain结构图
Thoughts:
1)本论文的一个创新点是:提出了一个公共市场来出售训练好的模型,所获利润将按比例分配给local node和miner. 分配标准则是节点的可信度和贡献度
2)每个节点想要入链,必须提前存入一笔depoist,相当于保证金。如果该节点违法了,直接冻结并且发送给诚实的reporter.
3)本地训练节点的可信度不仅由所持有的本地数据量决定,还由其合作伙伴的检验以及FL买家评论所决定 最近重新翻这篇文章的时候,发现我好像错过了一个重点:布隆过滤器!!!
本文个亮点就是引入了布隆过滤器的数据检索方法。布隆过滤器是一个很长的二进制向量和一系列随机映射函数,所需的存储空间比传统的Hash表要少很多,并不会存储元素本身,而是仅返回元素是否存在的结果。本文采用的DDCBF方案,其主体是CBF(计数布隆过滤器)结构。思路就是将布隆过滤器中的bitmap更换成数组,当数组某位置被映射一次就+1,元素删除时就-1,这样就避免了普通布隆过滤器删除数据后需要重新计算其余数据包hash的位置了。
当然继续延伸下去,就还有布谷鸟过滤器。这其实就是为了查词频的,如果你是单单想判断某元素是否存在,倒也不需了解。
插播一点广告,如果也有做联邦学习+区块链,或者是隐私保护计算这块,热烈欢迎交流!!!
最后
以上就是俊秀诺言最近收集整理的关于联邦学习-区块链论文笔记:FLChain: A Blockchain for Auditable Federated Learning with Trust and Incentive的全部内容,更多相关联邦学习-区块链论文笔记:FLChain:内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复