鸿蒙os liteos-m版,是面向嵌入式的分支,看代码 arch 目录下,有 cortex m4 架构的支持的代码。
cortex m4相对于其他mcu芯片的优势,支持浮点、dsp等运算,适合某些需要一定计算量的领域。但是,需要说明的是,cortex m4的浮点运算,也只是“单精度”浮点运算;“双精度”的浮点运算,就需要通过函数模拟了,可以说效率非常的低下。以下利用keil,选择cortex m4芯片,生成的“双精度”和“单精度”除法代码比对,箭头处的函数可以非常清楚的看出两者的性能差别。
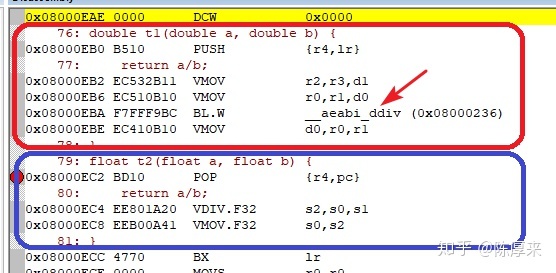
接下来要说到本文的重点,鸿蒙os的时钟计算函数。注意下图红框中的代码。仅这一行代码,就需要至少两次双精度浮点除法运算,这还不包括UINT64转DOUBLE的代码。可以说,又占代码空间、效率又低。要知道,在mcu领域,蚊子腿肉也是肉,能省一点是一点。有时候一个疏忽,原本电池能支持3个月的小设备,到你这儿就只能工作一周了。
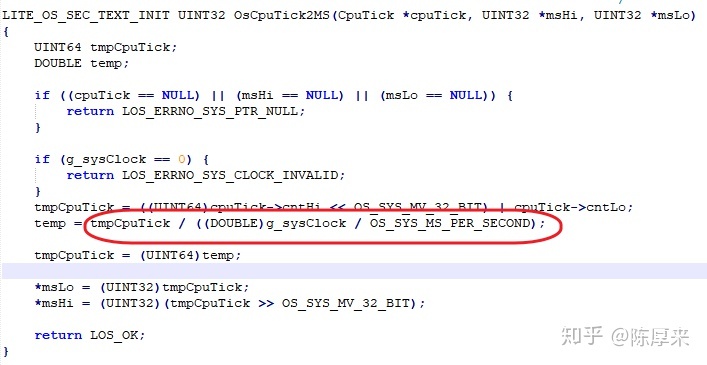
那么,为什么会写出这样的函数呢,显然跟UINT64有关,这里cpuTick输入的参数合起来就是64位的,为了不丢失精度,作者不得不用DOUBLE计算,然后再转回UINT64去。
这个问题显然是可以避免的。下面提供两种办法供参考 ---
一、最省时间空间的办法,就是不要用毫秒数作为时间计量单位。32位整数的最大毫秒数为0.136年,如果以10毫秒作为时间计量单位,那么用32位整数可以表达1.36年,这个在绝大部分情况是足够用的,因为你的系统很可能延迟不了这么久。
另外,cpuTick传入参数也是总共64位,为什么呢,看代码发现,传入参数其实是SysTick中断递增计数 * 每个周期总共SysTick数,再加上SysTick->VAL当前值。这个值显然无比巨大,不得不用64位。如果仔细构造并初始化SysTick时钟周期数,让每1毫秒出现一个SysTick中断,那么cpuTick传入参数将和毫秒数相等,这个低效的函数 OsCpuTick2MS 也就彻底不需要了!
这么做改动比较大,而且需要一些精巧的时钟设定,不一定适合所有场合。如果继续沿用原鸿蒙os的思路,可以用下面二的方式。
二、这个方式改造很简单,就是改造这一行代码:
temp = tmpCpuTick / ((DOUBLE)g_sysClock / OS_SYS_MS_PER_SECOND);需要明确的是,尽管笔者翻遍了鸿蒙liteos-m的代码,也没发现 g_sysClock 被赋值的地方,但笔者丰富的经验打败。。哦,照样可以得出结论,g_sysClock是一个近乎常量的存在。这个值是什么呢,是cpu在初始化或修改硬件时钟设定时,计算出跟时钟频率相关联的一个数。只要时钟频率不变,这个值是不会变的。那么,优化方案呼之欲出 --
1)在修改时钟设定时,预先计算好
DOUBLE g_preDiv = ((DOUBLE)g_sysClock / OS_SYS_MS_PER_SECOND);然后OsCpuTick2MS 函数里面,就可以直接用这个g_preDiv,减少一次双精度浮点运算
temp = tmpCpuTick / g_preDiv;2)更进一步,转除法为乘法加位移
#define DIV 4096
UINT32 g_preMul = (UINT32) (DIV/g_preDiv);
temp = temCpuTick * g_preMul / DIV; 以上4096这个值为2的整数幂,编译器会将除法优化成位移,效率非常高。这样不管Cortex-M4,M3, 甚至没有硬件除法的Cortex-M0都可以高效的实现。
(注:DIV取值4096,或者16或者65536,或者其他什么值,可能都没问题。具体数值要g_preDiv的值估算,保障 g_preMul 能有较大的数值,看官实际调试看看吧)
最后题外话,鸿蒙liteos-m 目前只有cortex m4的代码,arm下面cortex-a, risc-v目录也没实质代码。实际上,因为成本和功耗的考虑,在嵌入式mcu领域,除 cortex m4外,业界更是大量的使用 cortex m0, m3 的芯片,这部分目前没有支持,不能说一点的遗憾。如果在m0/m3/m4芯片只是需要简单多任务的支持,可以使用笔者自撸的 s_task 库,协作式多任务,不是操作系统,但在mcu里用,好用又方便!(夹带私货,逃了。。。)
最后
以上就是开心煎蛋最近收集整理的关于未定义与 double 类型的输入参数相对应的函数 eval_点评一下鸿蒙os的时钟计算函数...的全部内容,更多相关未定义与内容请搜索靠谱客的其他文章。








发表评论 取消回复