spring boot 整合爬虫框架webmagic,并将数据存储到数据库
文末附测试业务代码链接,供学习使用
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic主要由Downloader(下载器)、PageProcesser(解析器)、Schedule(调度器)和Pipeline(管道)四部分组成。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
这里关于Webmagic不做过多介绍,想了解更多可去官网查阅:http://webmagic.io/docs/zh/
操作数据源:
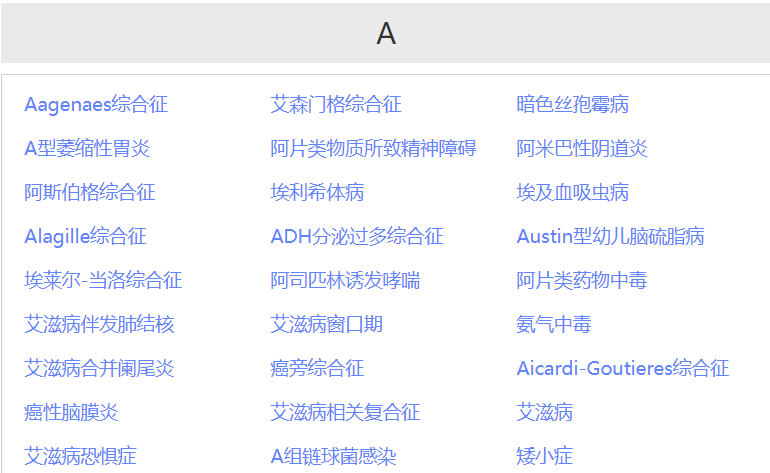
https://www.baikemy.com/disease/list/0/0?diseaseContentType=A
项目核心依赖
<!-- 爬虫相关代码 -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
获取数据示例
获取所有的疾病 及 详情信息,示例信息如下图所示

项目结构业务
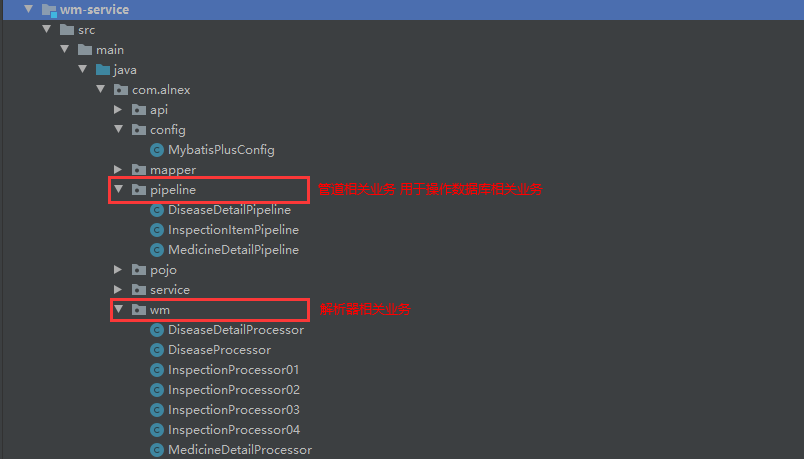
下面将分步骤解析
步骤一:
定义 DiseaseProcessor.java 获取所有的 疾病详情链接
@Component
public class DiseaseProcessor implements PageProcessor {
private Logger LOGGER = LoggerFactory.getLogger(DiseaseProcessor.class);
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数、超时时间等
private static Site site = Site.me().setSleepTime(3000).setTimeOut(10000).setRetryTimes(0);
private static DiseaseDetailService diseaseDetailService;
@Override
// process 是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public void process(Page page) {
Html html = page.getHtml();
// 抽取页面 疾病详情链接
List<String> links = html.xpath("//*[@id="theLeft"]/div[2]/div/div[2]/ul/li/a").links().all();
for (String link : links) {
// 单体链接操作
diseaseDetailService.executeDiseaseDetailProcessor(link);
}
}
@Override
public Site getSite() {
return site;
}
// 注入 DiseaseDetailService bean对象,否则单体链接操作会报错
@Autowired
public void setDiseaseDetailService(DiseaseDetailService diseaseDetailService) {
DiseaseProcessor.diseaseDetailService = diseaseDetailService;
}
}
html.xpath("//*[@id=“theLeft”]/div[2]/div/div[2]/ul/li/a").links().all(); 路径解析
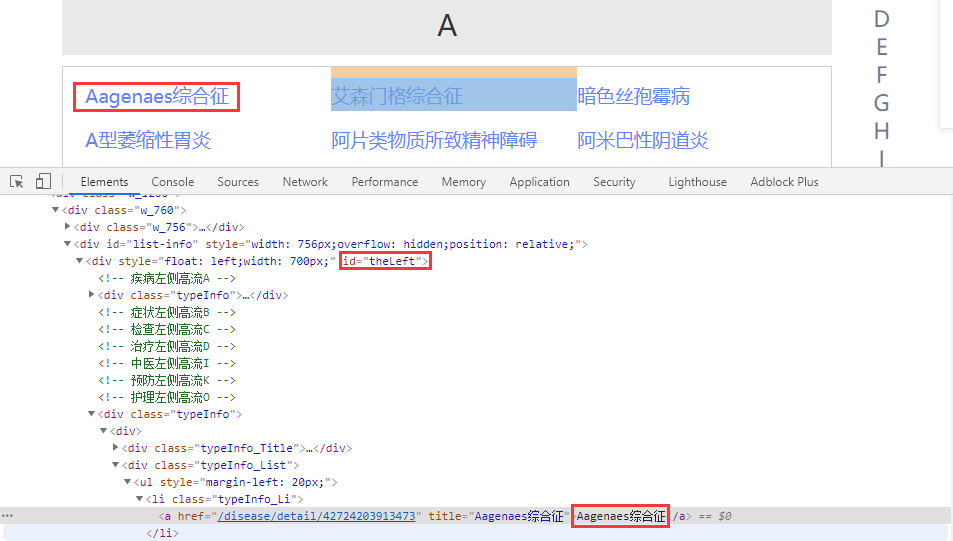
关于 xpath 中元素获取的方法有很多种,也可以通过下main的方式直接获取(简便)
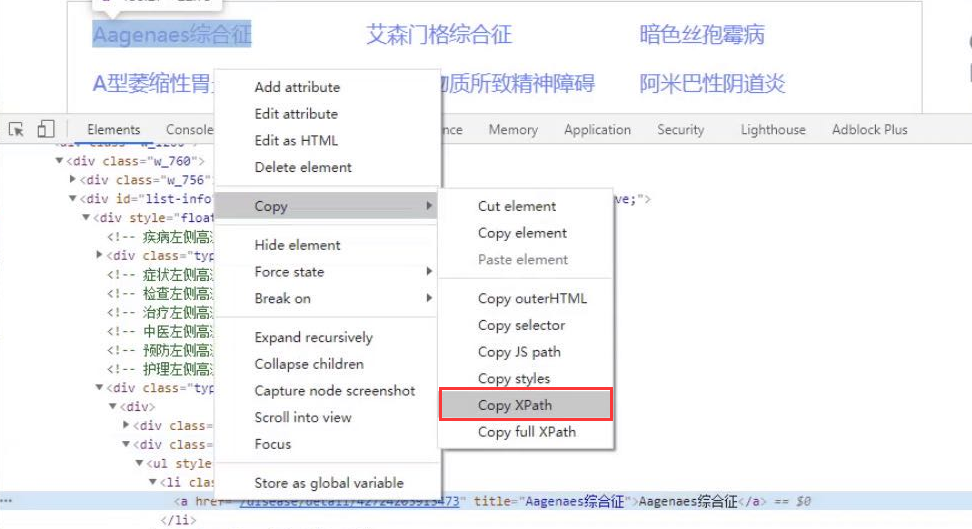
上图 可以根据需要做出适当修改。
在 DiseaseDetailServiceImpl 中定义一个方法,通过 Spider 去执行 DiseaseProcessor 处理器
// Spider 启动爬虫,指定规则
public void executeDiseaseWm() {
Spider.create(new DiseaseProcessor())
.addUrl(WebMagicConstant.DISEASE_LIST_URL) // 要爬取的url路径
.thread(10) // 定义线程数
.run(); // 启动
}
步骤二:
根据步骤一所得的疾病详情去获取我们所需的数据
定义 疾病详情 处理器
@Component
public class DiseaseDetailProcessor implements PageProcessor {
// 抓取网站的相关配置
private static Site site = Site.me().setSleepTime(300).setTimeOut(10000).setRetryTimes(0);
@Override
public void process(Page page) {
Html html = page.getHtml();
// 定义初始化数据容器
Map<String, Object> map = new ConcurrentHashMap<>();
// 疾病名称抓取 text()代表获取标签内的内容
String sickName = html.xpath("/html/body/div[2]/div[2]/div[1]/div[1]/div[1]/text()").toString();
map.put("sickName",sickName);
// 获取当前要抓取数据的url
map.put("detailUrl",page.getUrl().toString());
int count = 1;
while (true) {
String d1 = "//*[@id="specialityVersion"]/div[" + count + "]/h1/text()";
String d2 = "//*[@id="specialityVersion"]/div[" + count + "]/p/text()";
String key = html.xpath(d1).toString();
String value = html.xpath(d2).toString();
if (StringUtils.isEmpty(key) && StringUtils.isEmpty(value)) {
break;
}
map.put(DiseaseCatalogueEnum.getName(key),value);
count++;
}
// 将抽取页面信息,保存下来
page.putField("diseaseDetail",map);
}
@Override
public Site getSite() {
return site;
}
}
步骤三:
通过步骤二我们已经获得想要的数据,现在就是将数据存储到数据库中
在 DiseaseDetailServiceImpl 中定义一个方法,通过 Spider 去执行 DiseaseDetailProcessor 处理器去获取数据并存储到page中; 详情如下
public void executeDiseaseDetailProcessor(String url) {
// Spider 启动爬虫,指定规则
Spider.create(new DiseaseDetailProcessor()) // 定义疾病详情处理器,抓取疾病详情数据
.addUrl(url) // 抓取路径
.thread(10) // 定义线程数量
.addPipeline(new DiseaseDetailPipeline()) // 定义管道 进行数据存储操作处理
.run(); // 项目启动
}
在 上述代码块中有一个 addPipeline() 方法,在这里我们可以定义操作数据库的相关业务操作,示例代码如下
@Component
public class DiseaseDetailPipeline implements Pipeline {
private Logger LOGGER = LoggerFactory.getLogger(DiseaseDetailPipeline.class);
private static DiseaseDetailService diseaseDetailService;
@Override
public void process(ResultItems resultItems, Task task) {
// 获取 DiseaseDetailProcessor 执行器中 page.putField("diseaseDetail",map) 存储的数据
Map<String, Object> map = resultItems.get("diseaseDetail");
// 调用远程服务 存储数据
diseaseDetailService.saveMapData(map);
}
// bean 对象注册
@Autowired
public void setDiseaseDetailService(DiseaseDetailService diseaseDetailService) {
DiseaseDetailPipeline.diseaseDetailService = diseaseDetailService;
}
}
数据库存储业务代码如下
public void saveMapData(Map<String, Object> map) {
LOGGER.info("爬虫 获取的封装信息为 {}", map);
DiseaseDetail detail = diseaseDetailMapper.selectByUrl(map.get("detailUrl").toString());
if (ObjectUtil.isEmpty(detail)) {
// 数据转换
DiseaseDetail diseaseDetail = JSONUtil.toBean(JSONUtil.toJsonStr(map), DiseaseDetail.class);
LOGGER.info("map 转换成 DiseaseDetail 的数据为 {}", diseaseDetail);
diseaseDetailMapper.insert(diseaseDetail);
}
}
注意:
note 01:
在存储数据库的过程中,需要注意的是在 @Component 定义的配置文件中,需要获取 @Service 定义的 bean 对象,若通过在对象中直接通过 @Autowired 会出现获取不到 bean 对象(为 null)。
上述代码也作出了相关的处理操作。可以参考上述代码进行测试。
关于 @Component 下 @Autowired 注解为空 可以通过下面方法获取
// 方法 一
@Component
public class Test{
private static TestService testService;
// 其他业务代码
... ...
@Autowired
public void setTestService (TestService testService) {
Test.testService= testService;
}
}
// 方法 二
@Component
public class TimingTaskController{
public static TimingTaskController timingTaskController;
@Autowired
private OrderService orderService;
@PostConstruct
public void init() {
timingTaskController = this;
timingTaskController.orderService = this.orderService;
}
//调用的时候
timingTaskController.orderService.*****************
}
关注公众号回复 “ WebMagic ” 即可获取相关Demo,Demo包含多个页面的爬取数据,提供学习参考

最后
以上就是神勇春天最近收集整理的关于spring boot 整合爬虫框架webmagic,并将数据存储到数据库的全部内容,更多相关spring内容请搜索靠谱客的其他文章。








发表评论 取消回复