1、内核哈希表冲突解决方法
hash 最重要的是选择适当的hash函数,从而平均的分配关键字在桶中的位置,从而优化查找 插入和删除所用的时间。然而任何hash函数都会出现冲突问题。内核采用的解决哈希冲突的方法是:拉链法,拉链法解决冲突的做法是:将所有关键字为同义词的 结点链接在同一个链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针(struct hlist_head name)组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α(装填的元素个数/数组长度)可以大于 1,但一般均取α≤1。当然,用拉链法解决hash冲突也是有缺点的,指针需要额外的空间。
2、结构定义
其代码位于include/linux/list.h中,其数据结构定义放在了include/linux/types.h中:
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
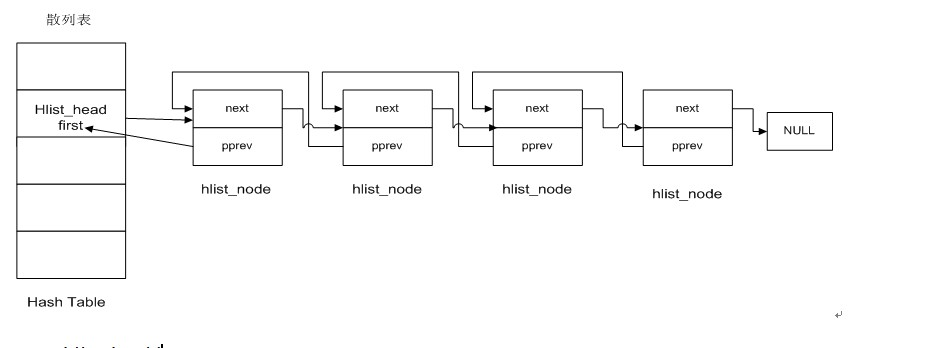
};- hlist_head表示哈希表的头结点。哈希表中每一个entry(list_entry)所对应的都是一个链表(hlist).hlist_head结构体只有一个域,即first。First指针指向该hlist链表的第一个结点。
- hlist_node结构体有两个域,next和pprev。(1)next指向下个hlist_node结点,倘若改结点是链表的最后一个节点,next则指向NULL。(2)pprev是一个二级指针,它指向前一个节点的next指针。
问题1:为什么需要一个专门的哈希表头?
因为哈希链表并不需要双向循环的技能,它一般适用于单向散列的场景。所以,为了减少开销,并没有用struct hlist_node{}来代表哈希表头,而是重新设计struct hlist_head{}这个数据结构。此时,一个哈希表头就只需要4Byte了,相比于struct hlist_node{}来说,存储空间已经减少了一半。这样一来,在需要大量用到哈希链表的场景,其存储空间的节约是非常明显的,特别是在嵌入式设备领域。
问题2:使用pprev二级指针的意义?
在hlist中,表头中没有prev,只有一个first,为了能统一地修改表头的first指针hlist就设计了pprev。node节点里的pprev其实指向的是其前一个节点里的第一个指针元素的地址。对于hlist_head来说,它里面只有一个指针元素,就是first指针;而对于hlist_node来说,第一个指针元素就是next。
所以,当在代码中看到类似与 *(hlist_node->pprev) 这样的代码时,表示此时正在哈希表里操作当前节点前一个节点里的第一个指针元素所指向的内存地址。
3、初始化
(a)表头初始化
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)1.HLIST_HEAD_INIT 宏只进行初始化;
如:struct hlist_head my_hlist = HLIST_HEAD_INIT
调用HLIST_HEAD_INIT对my_hlist哈希表头结点只进行初始化,将表头结点的fist指向空。
2.HLIST_HEAD(name) 函数宏进行声明并且初始化。
如:HLIST_HEAD(my_hlist);
调用HLIST_HEAD函数宏对my_hlist哈希表头结点进行声明并进行初始化。将表头结点的fist指向空。
3.INIT_HLIST_HEAD 在运行时进行初始化
如:INIT_HLIST_HEAD(&my_hlist);
调用INIT_HLIST_HEAD俩my_hlist进行初始化,将其first域指向空即可。
(b)节点初始化
1.static iniline void INIT_HLIST_NODE(struct hlist_node *h)
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}该内联函数实现了对struct hlist_node 结点进行初始化操作,将其next域和pprev都指向空,实现其初始化操作。
4、基本操作(插入,删除,判空)
1、插入
// 将结点n插在头结点h之后。
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h);
// 将结点n插在next结点的前面(next在哈希链表中)
static inline void hlist_add_before(struct hlist_node *n, struct hlist_node *next);
// 将结点next插在n之后(n在哈希链表中)
static inline void hlist_add_after(struct hlist_node *n, struct hlist_node *next);static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first; // 指向下一个节点或NULL
if (first) // first指向非空,则后继节点的pprev指向前驱节点的next地址
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
/* next must be != NULL */
static inline void hlist_add_before(struct hlist_node *n, struct hlist_node *next)
{
n->pprev = next->pprev;
n->next = next;
next->pprev = &n->next;
*(n->pprev) = n;
}
static inline void hlist_add_after(struct hlist_node *n, struct hlist_node *next)
{
next->next = n->next;
n->next = next;
next->pprev = &n->next;
if(next->next)
next->next->pprev = &next->next;
}2、删除
static inline void hlist_del(struct hlist_node *n);/*
* These are non-NULL pointers that will result in page faults
* under normal circumstances, used to verify that nobody uses
* non-initialized list entries.
*/
#define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
#define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
*pprev = next;
if (next)
next->pprev = pprev;
}
static inline void hlist_del(struct hlist_node *n)
{
__hlist_del(n);
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}LIST_POISON就是一段无效的地址区,当开发者误用到这个地址时,会产生页错误。
3、哈希链表的移动
// 将以个哈希聊表的头结点用new结点代替,将以前的头结点删除。
static inline void hlist_move_list(struct hlist_head *old,struct hlist_head *new);/*
* Move a list from one list head to another. Fixup the pprev
* reference of the first entry if it exists.
*/
static inline void hlist_move_list(struct hlist_head *old,
struct hlist_head *new)
{
new->first = old->first;
if (new->first)
new->first->pprev = &new->first;
old->first = NULL;
}4、哈希链表其它操作
// 判断结点是否已经存在hash表中。
static inline int hlist_unhashed(const struct hlist_node *h);
// 函数判断哈希链表是否为空
static inline int hlist_empty(const struct hlist_head *h);static inline int hlist_unhashed(const struct hlist_node *h)
{
return !h->pprev;
}
static inline int hlist_empty(const struct hlist_head *h)
{
return !h->first; // 通过判断头结点中的first域来判断其是否为空。如果first为空则表示该哈希链表为空。
}通过判断该结点的pprev是否为空来判断该结点是否在哈希链表中。 h->pprev等价于h节点的前一个节点的next域。如果前一个节点的next域为空,说明该节点不在哈希链表中。
5、哈希链表的遍历
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)和container_of功能一样,通过成员指针获得整个结构体的指针 。
#define hlist_for_each(pos, head)
#define hlist_for_each_safe(pos, n, head)内核为哈希链表遍历提供了两个接口,这两个接口只是在链表内部沿着链表往下遍历,没有对外部的数据进行任何处理, 一般和hlist_entry结合使用。
#define hlist_for_each(pos, head)
for (pos = (head)->first; pos ; pos = pos->next)
#define hlist_for_each_safe(pos, n, head)
for (pos = (head)->first; pos && ({ n = pos->next; 1; });
pos = n)pos: pos是一个辅助指针(即链表类型struct hlist_node),用于链表遍历
n :n是一个临时哈希结点指针(struct hlist_node),用于临时存储pos的下一个链表结点。
head:链表的头指针(即结构体中成员struct hlist_head).
hlist_for_each 是通过移动pos指针来达到遍历的目的。但如果遍历的操作中包含删除pos指针所指向的节点,pos指针的移动就会被中断,因为 hlist_del(pos)将把pos的next、prev置成LIST_POSITION2和LIST_POSITION1的特殊值。当然,调用者完全可以自己缓存next指针使遍历操作能够连贯起来,但为了编程的一致性,Linxu内核哈希链表要求调用者另外提供一个与pos同类型的指针n,在for循环中暂存pos下一个节点的地址,避免因pos节点被释放而造成的断链。
此循环判断条件为pos && ({n = pos->next;1;});
这条语句先判断pos是否为空,如果为空则不继续进行判断。如果pos为真则进行判断({n=pos->next;1;})—》该条语句为复合语句表 达式,其数值为最后一条语句,即该条语句永远为真,并且将post下一条结点的数值赋值给n。即该循环判断条件只判断pos是否为真,如果为真,则继续朝 下进行判断。
6、哈希链表宿主结构的遍历
Linux提供了从三种方式进行遍历,一种是从哈希链表第一个哈希结点开始遍历;第二种是从哈希链表中的pos结点的下一个结点开始遍历;第三种是从哈希链表中的当前结点开始进行遍历。
(1)从哈希链表的第一个哈希结点开始进行遍历
#define hlist_for_each_entry(tpos, pos, head, member);
#define hlist_for_each_entry_safe(tpos, pos, n, head, member); 另外,list和hlist的遍历都实现了safe版本,因在遍历时,没有任何特别的东西来阻止对链表执行删除操作。安全版本的遍历函数使用临时存放的方法使得检索链表时能不被删除操作所影响。
tpos是hlist_node所属宿主结构体类型的指针,pos是hlist_node类型的指针,tpos和pos都充当游标的作用。n是一个hlist_node类型的另一个指针,这个指针指向pos所在元素的下一个元素,它由hlist_for_each_entry_safe本身进行维护,使用者不用修改它。
/**
* hlist_for_each_entry - iterate over list of given type
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry(tpos, pos, head, member)
for (pos = (head)->first;
pos &&
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;});
pos = pos->next)
/**
* hlist_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @n: another &struct hlist_node to use as temporary storage
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_safe(tpos, pos, n, head, member)
for (pos = (head)->first;
pos && ({ n = pos->next; 1; }) &&
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;});
pos = n)(2)从哈希链表中pos结点的下一个结点开始遍历
/**
* hlist_for_each_entry_continue - iterate over a hlist continuing after current point
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_continue(tpos, pos, member)
for (pos = (pos)->next;
pos &&
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;});
pos = pos->next)(3)从哈希链表中的pos结点的当前结点开始遍历
/**
* hlist_for_each_entry_from - iterate over a hlist continuing from current point
* @tpos: the type * to use as a loop cursor.
* @pos: the &struct hlist_node to use as a loop cursor.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_from(tpos, pos, member)
for (; pos &&
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;});
pos = pos->next)5 hash函数
评估hash函数优劣的基准主要有以下两个指标:
(1) 散列分布性
即桶的使用率backet_usage = (已使用桶数) / (总的桶数),这个比例越高,说明分布性良好,是好的hash设计。
(2) 平均桶长
即avg_backet_len,所有已使用桶的平均长度。理想状态下这个值应该=1,越小说明冲突发生地越少,是好的hash设计。
hash函数计算一般都非常简洁,因此在耗费计算时间复杂性方面判别甚微,这里不作对比。
当然,最好实际测试一下,毕竟应用特点不大相同。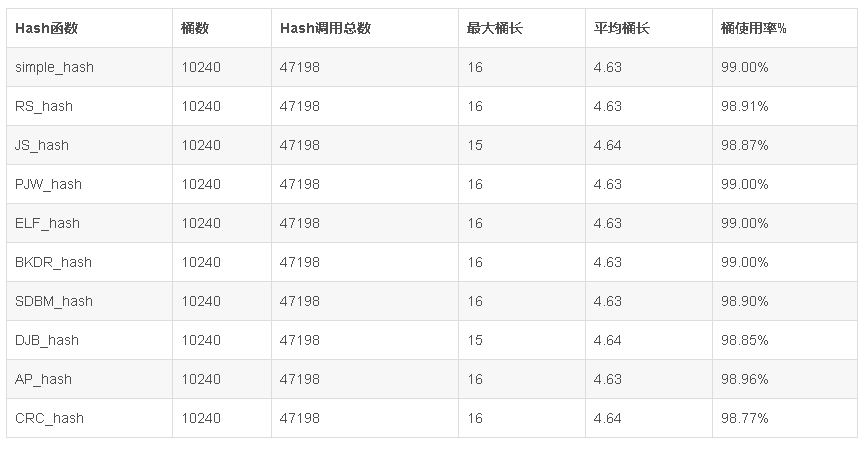
其中hash_long在<linux/hash.h>中定义如下:
/* 2^31 + 2^29 - 2^25 + 2^22 - 2^19 - 2^16 + 1 */
#define GOLDEN_RATIO_PRIME_32 0x9e370001UL
/* 2^63 + 2^61 - 2^57 + 2^54 - 2^51 - 2^18 + 1 */
#define GOLDEN_RATIO_PRIME_64 0x9e37fffffffc0001UL
#if BITS_PER_LONG == 32
#define GOLDEN_RATIO_PRIME GOLDEN_RATIO_PRIME_32
#define hash_long(val, bits) hash_32(val, bits)
#elif BITS_PER_LONG == 64
#define hash_long(val, bits) hash_64(val, bits)
#define GOLDEN_RATIO_PRIME GOLDEN_RATIO_PRIME_64
#else
#error Wordsize not 32 or 64
#endif
static inline u64 hash_64(u64 val, unsigned int bits)
{
u64 hash = val;
/* Sigh, gcc can't optimise this alone like it does for 32 bits. */
u64 n = hash;
n <<= 18;
hash -= n;
n <<= 33;
hash -= n;
n <<= 3;
hash += n;
n <<= 3;
hash -= n;
n <<= 4;
hash += n;
n <<= 2;
hash += n;
/* High bits are more random, so use them. */
return hash >> (64 - bits);
}
static inline u32 hash_32(u32 val, unsigned int bits)
{
/* On some cpus multiply is faster, on others gcc will do shifts */
u32 hash = val * GOLDEN_RATIO_PRIME_32;
/* High bits are more random, so use them. */
return hash >> (32 - bits);
}
static inline unsigned long hash_ptr(const void *ptr, unsigned int bits)
{
return hash_long((unsigned long)ptr, bits);
}
#endif /* _LINUX_HASH_H */上面的函数很有趣,我们来仔细看一下。
首先,hash的方式是,让key乘以一个大数,于是结果溢出,就把留在32/64位变量中的值作为hash值,又由于散列表的索引长度有限,我们就取这hash值的高几为作为索引值,之所以取高几位,是因为高位的数更具有随机性,能够减少所谓“冲突”。什么是冲突呢?从上面的算法来看,key和hash值并不是一一对应的。有可能两个key算出来得到同一个hash值,这就称为“冲突”。
那么,乘以的这个大数应该是多少呢?从上面的代码来看,32位系统中这个数是0x9e370001UL,64位系统中这个数是0x9e37fffffffc0001UL。这个数是怎么得到的呢?
“Knuth建议,要得到满意的结果,对于32位机器,2^32做黄金分割,这个大树是最接近黄金分割点的素数,0x9e370001UL就是接近 2^32*(sqrt(5)-1)/2 的一个素数,且这个数可以很方便地通过加运算和位移运算得到,因为它等于2^31 + 2^29 - 2^25 + 2^22 - 2^19 - 2^16 + 1。对于64位系统,这个数是0x9e37fffffffc0001UL,同样有2^63 + 2^61 - 2^57 + 2^54 - 2^51 - 2^18 + 1。”
从程序中可以看到,对于32位系统计算hash值是直接用的乘法,因为gcc在编译时会自动优化算法。而对于64位系统,gcc似乎没有类似的优化,所以用的是位移运算和加运算来计算。首先n=hash, 然后n左移18位,hash-=n,这样hash = hash * (1 - 2^18),下一项是-2^51,而n之前已经左移过18位了,所以只需要再左移33位,于是有n <<= 33,依次类推,最终算出了hash值。
最后
以上就是听话钢铁侠最近收集整理的关于linux kernel hash详解1、内核哈希表冲突解决方法2、结构定义5 hash函数的全部内容,更多相关linux内容请搜索靠谱客的其他文章。








发表评论 取消回复