文章目录
- 前言
- 一、传统RNN
- 二、RNN带来的缺陷
- 1、梯度爆炸和梯度弥散
- 2、memory记忆不足
- 三、LSTM理解
- 1、LSTM原理
- 2、LSTM公式
- 前向传播
- 反向传播
- 四、LSTM实践(Python)
- 训练minist数据集
- IMDB电影评论数据集进行文本分类
- 五、参考
前言
参照网上资料对LSTM的理解和总结,如文章内容有错误和不足之处,烦请读者联系作者修改。
一、传统RNN
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络,可以解决训练样本输入是连续且长短不一的序列的问题,比如基于时间序列的问题。
基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层与层之间的神经元之间也建立了权连接。
RNN神经网络的结构如下:
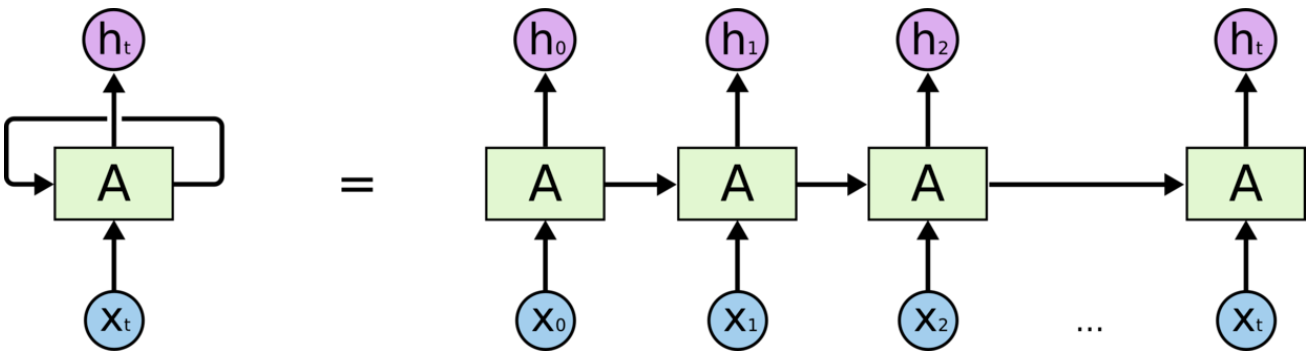
二、RNN带来的缺陷
1、梯度爆炸和梯度弥散
虽然在某些情况下,RNN神经网络的参数比卷积网络要少很多。但是,随着循环次数的叠加,很容易出现梯度爆炸或梯度弥散。而导致这个缺陷产生的主要原因是,传统RNN在计算梯度时,其公式中存在一个 ω h h ω_{hh} ωhh 的k次方。
由于其梯度求解公式中有
ω
h
h
ω_{hh}
ωhh 的k次方的存在,所以会出现下面的极限情况:
ω
h
h
>
1
ω_{hh}>1
ωhh>1,
ω
h
h
k
ω_{hh}^k
ωhhk 接近于
∞
∞
∞ ——出现梯度爆炸
ω
h
h
<
1
ω_{hh}<1
ωhh<1,
ω
h
h
k
ω_{hh}^k
ωhhk 接近于
0
0
0 ——出现梯度弥散
2、memory记忆不足
虽然RNN使用了一个全局的memory去记录全局的语境信息,但实际上,memory只能记住很短的全局信息,随着迭代次数的增加,memory会逐渐遗忘前面的语境信息。
三、LSTM理解
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度爆炸或梯度弥散问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
1、LSTM原理
LSTM 结构如下图,不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
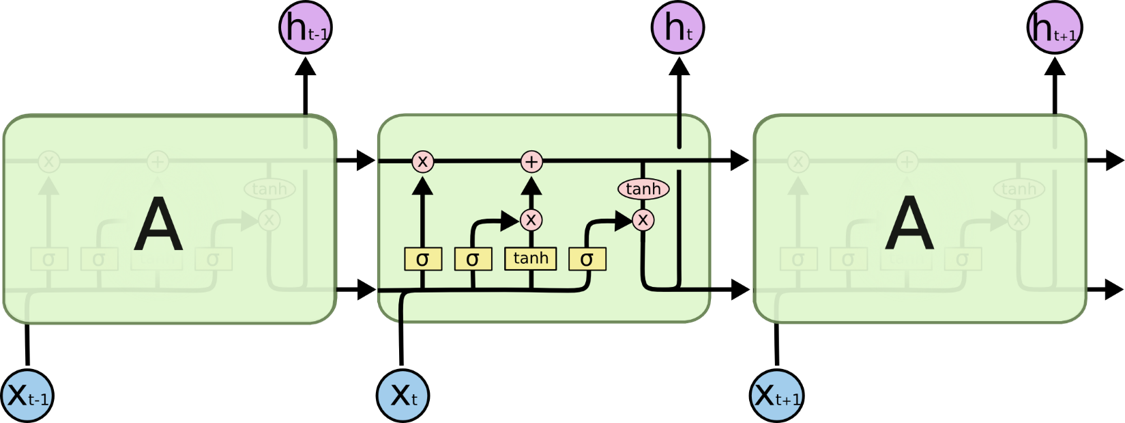
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
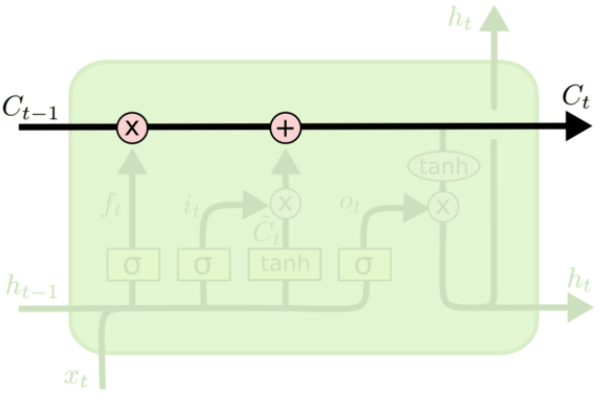
若只有上面的那条水平线是没办法实现添加或者删除信息的。LSTM网络在传统RNN网络中设置了三道闸门——输入门(Input Gate)、遗忘门(Forget Gate)、输出门(Output Gate)用于控制不同对象的输出量,达到选择性记忆的目的。
2、LSTM公式
前向传播
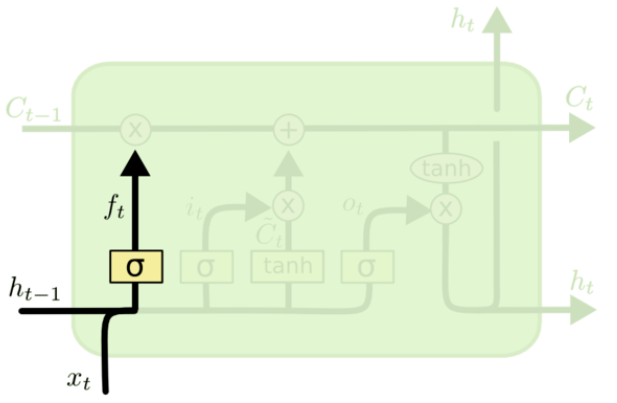
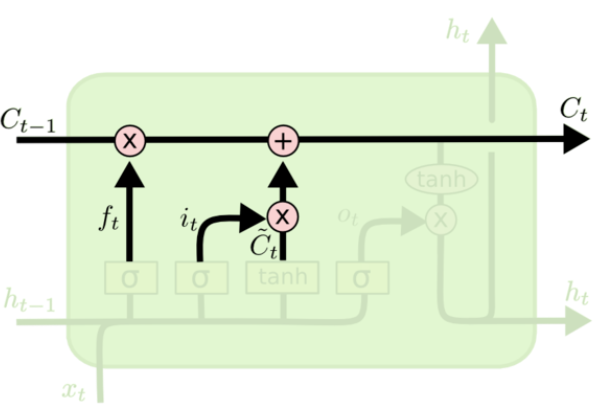
遗忘门:
f
t
=
δ
(
W
f
⋅
[
h
t
−
1
,
x
t
]
+
b
f
)
f_t=δ(W_f·[h_{t-1},x_t]+b_f)
ft=δ(Wf⋅[ht−1,xt]+bf)
遗忘门决定上一时刻细胞状态
C
t
−
1
C_{t-1}
Ct−1 中的多少信息(由
f
t
f_t
ft 控制,值域为
(
0
,
1
)
(0,1)
(0,1) )可以传递到当前时刻
C
t
C_{t}
Ct 中,1 表示“完全保留”,0 表示“完全舍弃”。
输入门:
i
t
=
δ
(
W
i
⋅
[
h
t
−
1
,
x
t
]
+
b
i
)
i_t=δ(W_i·[h_{t-1},x_t]+b_i)
it=δ(Wi⋅[ht−1,xt]+bi)
C
t
~
=
t
a
n
h
(
W
C
⋅
[
h
t
−
1
,
x
t
]
+
b
C
)
tilde{C_t}=tanh(W_C·[h_{t-1},x_t]+b_C)
Ct~=tanh(WC⋅[ht−1,xt]+bC)
输入门用来控制当前输入新生成的信息
C
t
C_{t}
Ct 中有多少信息(由
i
t
i_t
it 控制,值域为
(
0
,
1
)
(0,1)
(0,1) )可以加入到细胞状态
C
t
C_{t}
Ct 中。
t
a
n
h
tanh
tanh 层用来产生当前时刻新的信息,
δ
δ
δ 层用来控制有多少新信息可以传递给细胞状态。
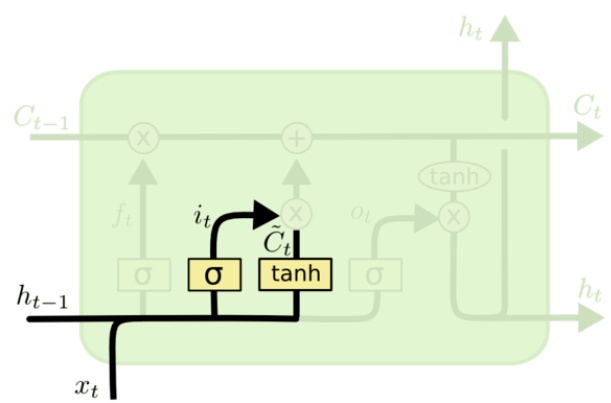
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
C
t
~
C_t=f_t*C_{t-1}+i_t*tilde{C_t}
Ct=ft∗Ct−1+it∗Ct~
基于遗忘门和输入门的输出,来更新细胞状态。更新后的细胞状态有两部分构成:一、来自上一时刻旧的细胞状态信息
C
t
−
1
C_{t-1}
Ct−1 ;二、当前输入新生成的信息
C
t
C_t
Ct 。
把旧状态
C
t
−
1
C_{t-1}
Ct−1与
f
t
f_t
ft相乘,丢弃掉确定需要丢弃的信息,接着加上
i
t
∗
C
~
t
i_t * tilde{C}_t
it∗C~t,这就是新的状态。
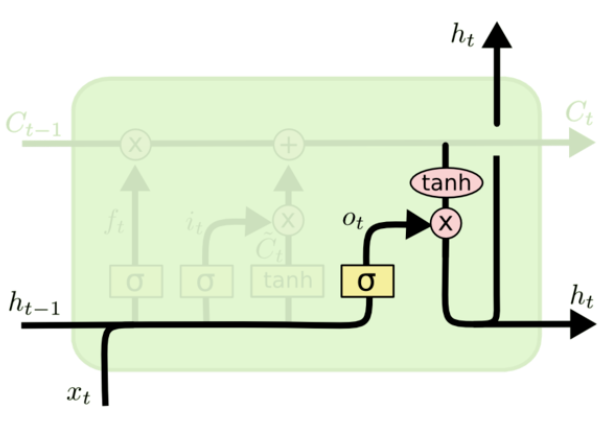
输出门:
o
t
=
δ
(
W
o
⋅
[
h
t
−
1
,
x
t
]
+
b
o
)
o_t=δ(W_o·[h_{t-1},x_t]+b_o)
ot=δ(Wo⋅[ht−1,xt]+bo)
h
t
=
o
t
∗
t
a
n
h
(
C
t
)
h_t=o_t*tanh(C_t)
ht=ot∗tanh(Ct)
最后,基于更新的细胞状态,输出隐藏状态
h
t
h_t
ht 。这里依然用
δ
δ
δ 层 (输出门,
o
t
o_t
ot ) 来控制有多少细胞状态信息(
t
a
n
h
(
C
t
)
tanh(C_t)
tanh(Ct),将细胞状态缩放至
(
0
,
1
)
(0,1)
(0,1) ) 可以作为隐藏状态的输出
h
t
h_t
ht。
反向传播
如有不懂之处可前往
https://blog.csdn.net/lrs1353281004/article/details/81188250
博客查看细节。

四、LSTM实践(Python)
训练minist数据集
import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
import numpy as np
import time
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
# Mnist数据集加载
(x_train_all, y_train_all), (x_test, y_test) = keras.datasets.mnist.load_data()
# Mnist数据集简单归一化
x_train_all, x_test = x_train_all / 255.0, x_test / 255.0
x_train, x_test = x_train_all[:50000], x_train_all[50000:]
y_train, y_test = y_train_all[:50000], y_train_all[50000:]
print(x_train.shape)
# 构建模型
inputs = layers.Input(shape=(x_train.shape[1], x_train.shape[2]), name='inputs')
print(inputs.shape)
lstm = layers.LSTM(units=128, return_sequences=False)(inputs)
print(lstm.shape)
outputs = layers.Dense(10, activation='softmax')(lstm)
print(outputs.shape)
lstm = keras.Model(inputs, outputs)
# 查看模型
lstm.compile(optimizer=keras.optimizers.Adam(0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
lstm.summary()
# 训练模型
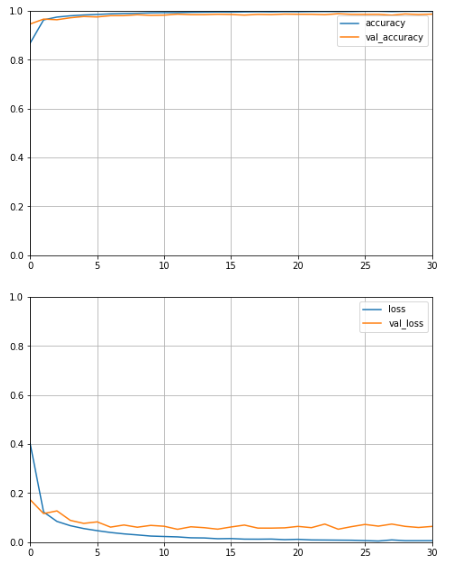
history = lstm.fit(x_train, y_train, batch_size=32, epochs=50, validation_split=0.1)
# 绘制准确率图像
data = {}
data['accuracy'] = history.history['accuracy']
data['val_accuracy'] = history.history['val_accuracy']
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, 30, 0, 1])
plt.show()
# 绘制损失图像
data = {}
data['loss'] = history.history['loss']
data['val_loss'] = history.history['val_loss']
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, 30, 0, 1])
plt.show()


IMDB电影评论数据集进行文本分类
#加载数据
#参数 num_words=10000 保留了训练数据中最常出现的 10000 个单词。为了保持数据规模的可管理性,低频词将被丢弃。
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
#首条评论
print(train_data[0])
#将整数转换回单词
# 一个映射单词到整数索引的词典
word_index = imdb.get_word_index()
# 保留第一个索引
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
#显示首条评论的文本
decode_review(train_data[0])
#将训练和测试数据处理成相同长度
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
#构建模型
# 输入形状是用于电影评论的词汇数目(10,000 词)
vocab_size = 10000
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
#编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
#从原始训练数据中分离 10,000 个样本来创建一个验证集
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
#训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
#模型评估
results = model.evaluate(test_data, test_labels, verbose=2)
print(results)
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.show()
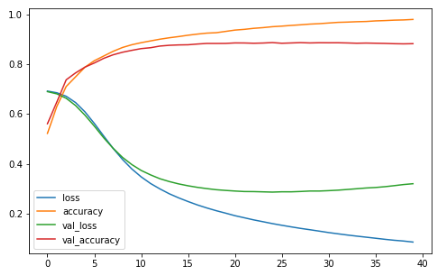
plot_learning_curves(history)


五、参考
- Christopher Olah 的博文:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://zhuanlan.zhihu.com/p/32085405
- https://blog.csdn.net/flyinglittlepig/article/details/72229041
- https://blog.csdn.net/lrs1353281004/article/details/81188250
最后
以上就是欢喜哑铃最近收集整理的关于理解LSTM网络+Python实现前言一、传统RNN二、RNN带来的缺陷三、LSTM理解四、LSTM实践(Python)五、参考的全部内容,更多相关理解LSTM网络+Python实现前言一、传统RNN二、RNN带来内容请搜索靠谱客的其他文章。



![[干货]深入浅出LSTM及其Python代码实现](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)

![[转载] 基于LSTM的股票预测模型_python实现_超详细](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)


发表评论 取消回复