图数据库选型对比:HugeGraph、JanusGraph、Neo4j
图数据库是NoSQL Database的一种类型,它应用图形理论存储实体之间的关系信息。它应用图形理论存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。
现在市面上经常有的图库有: Titan、neo4j、OrientDB、JanusGraph、HugeGraph、Trinity、TigerGraph 等。随着业务场景的增多,现在图数据库在市面上变得越来越火爆。
个人因为公司业务需要曾对相关图库进行选型调研,主要工作是对HugeGraph、JanusGraph、Neo4jj 三种图数据库在各个维度进行的分析包括功能和性能方面,现总结一下希望对大家有一定的参考价值。
从性能的方面考虑(涉及到数据量大小、是否为集群等因素)
1、Neo4j:单机性能明显,企业版是集群模式(非分布式)
2、hugegraph:单机性能(rocksdb后端)和neo4j相近甚至较好;同时还可以通过配置存储引擎,适用集群存储可支持大数据超千亿级以上(性能相对单机会有所降低)。
3、 JanusGraph:开源的分布式图数据库,单机性能较差。但是分布式可支持大数据超千亿级以上,和apache下的spark、hbase等结合度高
从功能的完备度、易用性等方面考虑
1、Neo4j:功能比较齐全,但是功能都比较独立。和别的存储引擎耦合性低,不能相互组合使用。有可视化操作系统,简单功能可以实现。支持灾备,支持事务锁等。
2、huegraph:功能支持健最齐全,导入组件支持各种数据源。可视化操作组件 hubble 支持功能齐全,存储后端引擎支持宽泛,能和相关的数据库搭配使用,更适合刚上手的用户。整体上常用算法都进行封装过,易用性强。有HA组件支持灾备,事务方面的支持较弱
3、JanusGraph:功能方面支持(不支持可视化界面、HA灾备)其他相关功能都具备。整体上各功能使用没有hugegraph便捷易用。
分析结果
接下来会从功能的支持方面和性能测试方面对neo4j 、 janusgraph 、hugegraph 图数据库进行详尽的说明,把一些它们的优缺点以表格的形式呈现,话不多说请看下表。
功能实现分析
| 图存储 | Neo4j | JanusGraph | HugeGraph |
|---|---|---|---|
| 容量在线水平扩展 | 不支持 | 支持 | 支持 |
| 后端存储引擎 | 自己独立的存储模式,自定义存储,无法使用集群存储。 | 支持持后端存储转换(hbase、cassandra、Berkeley DB等) | 支持持后端存储转换(hbase、rocksdb、cassandra、postgreSQL、mysql、ScyllaDB) |
| 是否支持事务 | 支持 | 支持 | 支持RC级别事务 |
| 图分区 | 不支持 | 支持 | 支持 |
| 全文检索功能 | Neo4j用的搜索引擎是Lucene。 | 通过ES实现,集成操作复杂。 | 内置支持全文索引,不依赖额外存储,易维护。 |
| 全内存式存储(效率快) | 不支持 | 不支持 | 支持 |
| 持久化存储 | 支持 | 支持 | 支持 |
| 二级索引 | 支持 | 支持 | 支持 |
| 范围索引 | 支持 | 不支持 | 支持 |
| 高级索引(联合索引、全文索引) | 支持 | 支持 | 支持 |
| 图模型 | Neo4j | JanusGraph | HugeGraph |
|---|---|---|---|
| 图查询语言 | cypher | gremlin图存储 | Neo4j gremlin |
| shcema管理 | 手动编写 | 支持自动创建schema,但是自动创建中相关属性、label的数据类型是固定的。一旦自动创建后在一张图里边变不能进行修改,建议用户不使用自动化创建schema。 | 1、 支持手动gremlin语言编写。 2、 可以使用可视化界面进行创建和复用。 |
| 多图实例 | 不支持 | 不支持 | 一个server配置多个图,可以同时应用,互不影响。 |
| 多ID类型(自增、主键、自定义ID) | 不支持 | 不支持 | 支持 |
| 属性类型(数字、字符串、日期、集合) | 支持 | 支持 | 支持 |
| 图查询 | Neo4j | JanusGraph | HugeGraph |
|---|---|---|---|
| RESTFUL API | 支持 | 支持 | 支持 |
| 图处理 | 独立的图处理引擎 | 使用Tinkerpop3 | 使用Tinkerpop3 |
| 高频图算法 | 通过cypher代码自行实现 | 通过Gremlin 代码自行实现 | 封装了(ShortestPath、k-out、k-neighbor等),使用更友好 |
| 大规模查询 | 单机查询,数据到达一定规模,性能会降低 | 支持千亿级数规模查询 | 支持千亿级数据规模查询; 支持 大规模分页查询 |
| 属性图 | 支持 | 支持 | 支持 |
| 工具链 | Neo4j | JanusGraph | HugeGraph |
|---|---|---|---|
| 可视化工具 | 可视化工具,可以创建图,删除图,可以支持图数据查询。不支持数据导入等操作,不支持多图管理。 | 无可视化界面,但是可集成Cytoscape、[Gephi](http://link.zhihu.com/?target=http://tinkerpop.apache.org/docs/current/reference/" l "gephi-plugin) 等(集成操作复杂)。 | 提供原生的可视化界面,支持多图管理、图查询、数据导入、schema复用。易用性强,新手更容易使用。 |
| 高可用及容灾备份 | 支持灾备 | 不支持 | 支持灾备 原生HA组件 |
| 数据导入 | 本地csv文件 | 支持本地csv等文件、hdfs导入。 | 支持本地csv,json,text,hdfs文件导入;也支持常用的数据库mysql、oracle、sqlServer等数据导入 |
| 图管理 | 可实现可视化界面图管理 | 方便从配置文件创建不同的图 1.ConfiguredGraphFactory 2.JanusGraphFactory方式 | 两种方案:1、有tools组件可以实现图的管理 2、可视化界面进行图管理 |
| Spark GraphX | 不支持 | 支持 | 支持 |
| Neo4j | JanusGraph | HugeGraph | |
|---|---|---|---|
| 部署方式 | 部署较复杂(配置项多) | 单节点部署简单,多节点部署复杂(依赖hadoop、hbase /zookeeper ) | 可以一键部署(修改配置可以更换存储引擎) |
| 发展模式 | 开源版和企业版共存 | 开源版 | 有开源版和商业版共存 |
| 社区支持 | Neo4j公司 | IBM | 百度 |
Benchmark测试
测试数据集均为在网上公开数据集,测试结果仅为本人的特定服务器的情况下得到的结果。
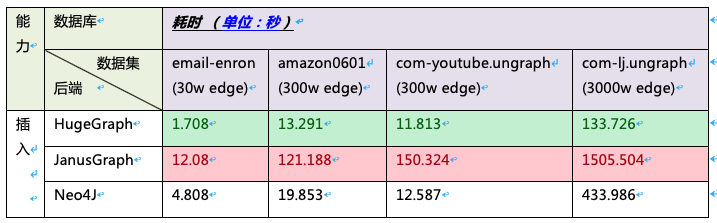
插入测试
对表中的数据集进行导入操作,然后得到其所用时间。
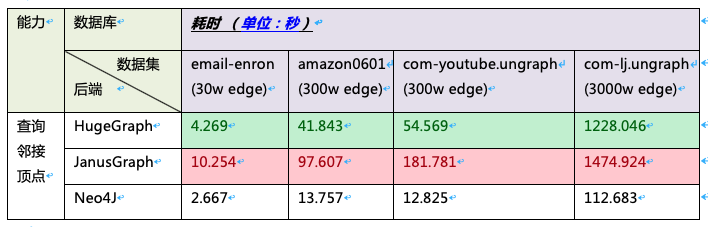
查询测试
1、测试场景:在现有数据集中,通过某些点的信息查询和他直接相连的点的所用的时间。比如:图库中为一批电话通联数据集,想通过某些重点人的信息查询出所有和这些重点人的有通联的人
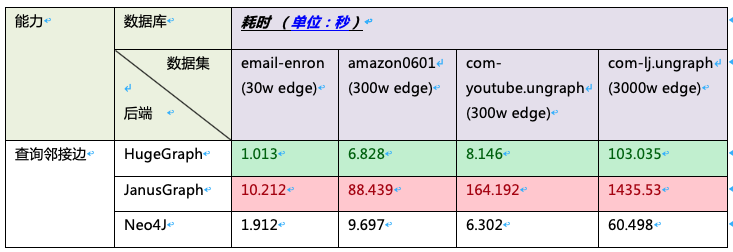
2、测试场景:在现有数据集中,通过某些顶点的信息,查询所有和这些顶点相连的边。例如:有一批员工的相关的数据信息,我们可以通过某个人ID查询出所有与其相关的信息。
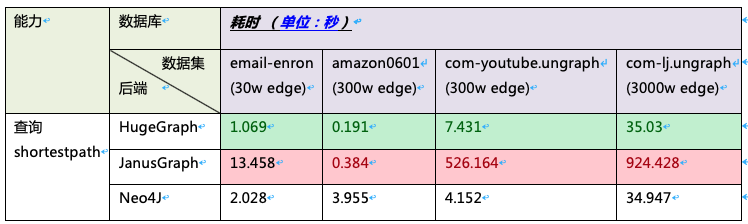
3、测试场景:查询数据集中的任意两个顶点之间的最短路径。比如图库中的信息为所有中国铁路火车停靠站信息,我们可以查询任意两个城市之间停靠站最少的火车班次。
最后
以上就是感性大象最近收集整理的关于图数据库选型对比:HugeGraph、JanusGraph、Neo4j分析结果的全部内容,更多相关图数据库选型对比内容请搜索靠谱客的其他文章。








发表评论 取消回复