一、常见难点
索引:
字符串方法的灵活使用
字符串格式化
Unicode 字符
Python乱码问题
字符串与列表转换问题
列表类型内建函数灵活应用
二、逐一击破
1、字符串方法的灵活使用
Python字符串内建方法在《Python核心编程》列举的很全面,这里不再累述,就总结以下常用的。
(1)、string.capitalize():把字符串的第一个字符大写
capitalize:['kæpitəlaiz],翻译:以大写字母写
(2)、string.count(str, beg=0, end=len(string)):返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数
count模拟:

str = 'my name is BeginMan' print str.count('e') #2 #模拟count: count = len([e for e in str if e =='e']) print count #2
(3)、string.decode(encoding='UTF-8', errors='strict'):以 encoding 指定的编码格式解码 string,如果出错默认报一个ValueError 的 异常 , 除非 errors 指的是 'ignore' 或者 'replace'
(4)、string.encode(encoding='UTF-8', errors='strict') :以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常, 除非 errors 指定的是'ignore'或者'replace'
#!/usr/bin/python str = "this is string example....wow!!!"; str = str.encode('base64','strict'); print "Encoded String: " + str; print "Decoded String: " + str.decode('base64','strict')
#输出:
Encoded String: dGhpcyBpcyBzdHJpbmcgZXhhbXBsZS4uLi53b3chISE=
Decoded String: this is string example....wow!!!
(5)、string.endswith(obj, beg=0, end=len(string)):检查字符串是否以 obj 结束,如果 beg 或者 end 指定则检查指定的范围内是否以 obj 结束, 如果是, 返回 True,否则返回 False.
print str.endswith('Man') #True
(6)、string.find(str, beg=0,end=len(string)) :包含在 string 中,如果 beg 和 end 指定范围, 则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1
不建议使用string.index(str, beg=0,end=len(string)),因为如果没找到则会抛出异常。
(7)、字符判断
string.isalnum():如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
string.isalpha():如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
string.isdecimal():如果 string 只包含十进制数字则返回 True 否则返回 False.
string.isdigit():如果 string 只包含数字则返回 True 否则返回 False.
s.islower() 所有字符都是小写
s.isupper() 所有字符都是大写
s.istitle() 所有单词都是首字母大写,像标题
s.isspace() 所有字符都是空白字符、t、n、r
注意,针对的是字符:
print 'abcd'.isalnum() #True print 'ab cd'.isalnum() #False
(8)、老搭档 join()、split()
参考我另一篇博文:Python零碎知识(6):split 和 join
这里只举例说明:
str = 'my name is BeginMan' lis = str.split(' ') print lis #['my', 'name', 'is', 'BeginMan'] print ' '.join(lis) #my name is BeginMan print '*'.join(lis) #my*name*is*BeginMan
(9)、string.replace(str1, str2,num=string.count(str1)):把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次.
print str.replace('BeginMan', 'SuperMan') #my name is SuperMan
print str.replace('a','A',1) #my nAme is BeginMan
(10)、字符串空格删除
string.rstrip():删除 string 字符串末尾的空格.
lstrip():删除字符串左边的空格
string.strip([obj]) :在 string 上执行 lstrip()和 rstrip()
(11)、大小写转换:
str.lower():小写
str.upper():大写
strip [strɪp]:翻译为 剥去
2、字符串格式化
Python支持两种格式的输入参数:
(1)、元祖:类似C printf()
>>> a=1 >>> b=2 >>> c=3 >>> print a,b,c 1 2 3 >>> print (a,b,c) (1, 2, 3) >>>
(2)、字典形式,其中key:格式字符串;value:对应的转换值
>>>print '%x' %108 '6c'
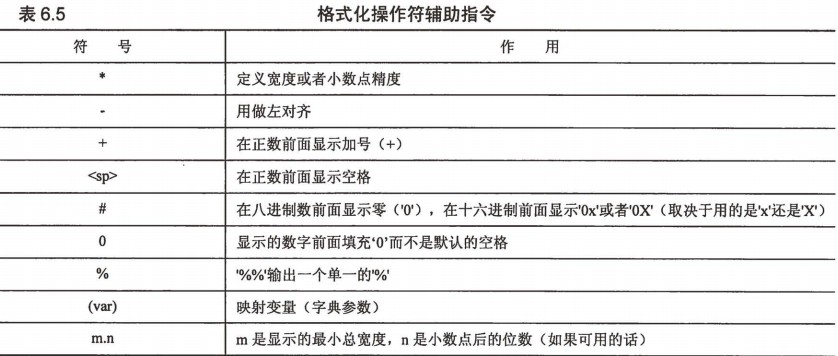
>>> '%.2f'%1234.7589620 '1234.76' >>> '%+d' %4 '+4' >>> '%+d' %-4 '-4' >>> '%d%%' %100 '100%' >>> 'MM/DD/YY=%02d/%02d/%d' %(8,10,13) 'MM/DD/YY=08/10/13'
整型数:%d
无符号整型数:%u
八进制:%o
十六进制:%x %X
浮点数:%f
科学记数法: %e %E
根据数值的不同自动选择%e或%f: %g
根据数值的不同自动选择%E或%f: %G
3、Unicode 字符
具体见《python 核心编程》,这里直接例子
>>> print 'hello'.encode('UTF-8') hello >>> print 'hello'.decode('UTF-8') hello >>>
>>> print unicode('你好','gb2312') 你好 >>> print '你好' 你好 >>> s='你好' >>> print s #str():给人看的 你好 >>> s #repr():给计算机看的 'xc4xe3xbaxc3' >>>
推荐:Unicode和Python的中文处理
更多参考我另一篇博文:Python字符集
4、Python乱码问题
一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢?
在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为
u'u54c8u54c8'
而str,是一个字节数组,这个字节数组表示的是对unicode对象编码(可以是utf-8、gbk、cp936、GB2312)后的存储的格式。这里它仅仅是一个字节流,没有其它的含义,如果你想使这个字节流显示的内容有意义,就必须用正确的编码格式,解码显示。
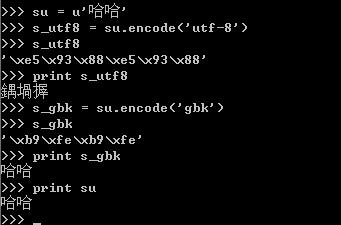
对于unicode对象哈哈进行编码,编码成一个utf-8编码的 str-s_utf8,s_utf8就是是一个字节数组,存放的就是'xe5x93x88xe5x93x88',但是这仅仅是一个字节数组, 如果你想将它通过print语句输出成哈哈,那你就失望了,为什么呢?
因为print语句它的实现是将要输出的内容传送了操作系统,操作系统会根据 系统的编码对输入的字节流进行编码,这就解释了为什么utf-8格式的字符串“哈哈”,输出的是“鍝堝搱”,因为 'xe5x93x88xe5x93x88'用GB2312去解释,其显示的出来就是“鍝堝搱”。这里再强调一下,str记录的是字节数组,只 是某种编码的存储格式,至于输出到文件或是打印出来是什么格式,完全取决于其解码的编码将它解码成什么样子。
这里再对print进行一点补充说明:当将一个unicode对象传给print时,在内部会将该unicode对象进行一次转换,转换成本地的默认编码(这仅是个人猜测)
更多参考:python 中文乱码问题深入分析
5、字符串与列表转换问题
如果将列表list1 = [1,2,3,4]转成str型'1,2,3,4',就很容易了
>>> list1 = [1,2,3,4] >>> list1 [1, 2, 3, 4] #注意********************** >>> ','.join(list1) Traceback (most recent call last): File "<pyshell#3>", line 1, in <module> ','.join(list1) TypeError: sequence item 0: expected string, int found >>> list2 = ['1','2','3','4'] >>> ','.join(list2) '1,2,3,4' #或许版本的问题,我的是Python2.5的,那么我们可以这样做: >>> list2 = ['1','2','3','4'] >>> ','.join(list2) '1,2,3,4' #然后再处理 #方法二: >>> str(list1)[1:-1] '1, 2, 3, 4'
但是如果将st = '["a","b",False,0]' 转换成列表 lis=["a","b",False,0],那该如何呢?
如果我们这样:
>>> st = '["a","b",False,0]' >>> li = list(st) >>> li ['[', '"', 'a', '"', ',', '"', 'b', '"', ',', 'F', 'a', 'l', 's', 'e', ',', '0', ']'] >>>
太恐怖了,那么该如何处理呢?
>>> lis = eval(st) >>> lis ['a', 'b', False, 0] >>>
哇,尼玛太强的了!!
那么就来看看这个eval()函数吧:
eval(str [,globals [,locals ]])函数将字符串str当成有效Python表达式来求值,并返回计算结果。
print eval('3'+'4') #34 print eval('3+4') #7 print eval('["1","2","3","4"]') #['1', '2', '3', '4']
啊,终于找到解决方案了,但是别高兴过头了,要知道eval()存在很大的潜在危险!
Python的eval()函数可以把字符串“123”变成数字类型的123,PP3E上说它很危险,还可以执行其他命令!
那么我们可以这样:
2.6的话可以用json
import json s='[1,2,3,4]' json.loads(s)
问题来源:http://bbs.chinaunix.net/thread-1757739-1-1.html
6、列表类型内建函数灵活应用
列表用的特别多,熟悉其内建函数也很重要,由于教程详尽,这里举例说明:
>>> lis = [] >>> lis.append('a') >>> lis.extend('seq') >>> lis ['a', 's', 'e', 'q'] >>> lis.insert(1,'indexValue') >>> lis ['a', 'indexValue', 's', 'e', 'q'] >>> lis.insert(-1,'a') >>> lis ['a', 'indexValue', 's', 'e', 'a', 'q'] >>> lis.count('a') 2 >>> lis.index('a',0,len(lis)) 0 >>> lis.pop() 'q' >>> lis.pop(-3) 's' >>> lis.remove('e') >>> lis ['a', 'indexValue', 'a'] >>> lis.sort() >>> lis ['a', 'a', 'indexValue'] >>> lis.reverse() >>> lis ['indexValue', 'a', 'a']
三、总结与反思
很多知识都是来源教材,这里大部分都是重新摘录教材,耗时耗力,效果寥寥,由此可见,一定要把教材从厚读薄,厚积薄发,最起码不下10编为宜!
最后
以上就是迷人草丛最近收集整理的关于python常见错误的全部内容,更多相关python常见错误内容请搜索靠谱客的其他文章。








发表评论 取消回复