103. HIN(异构信息网络)
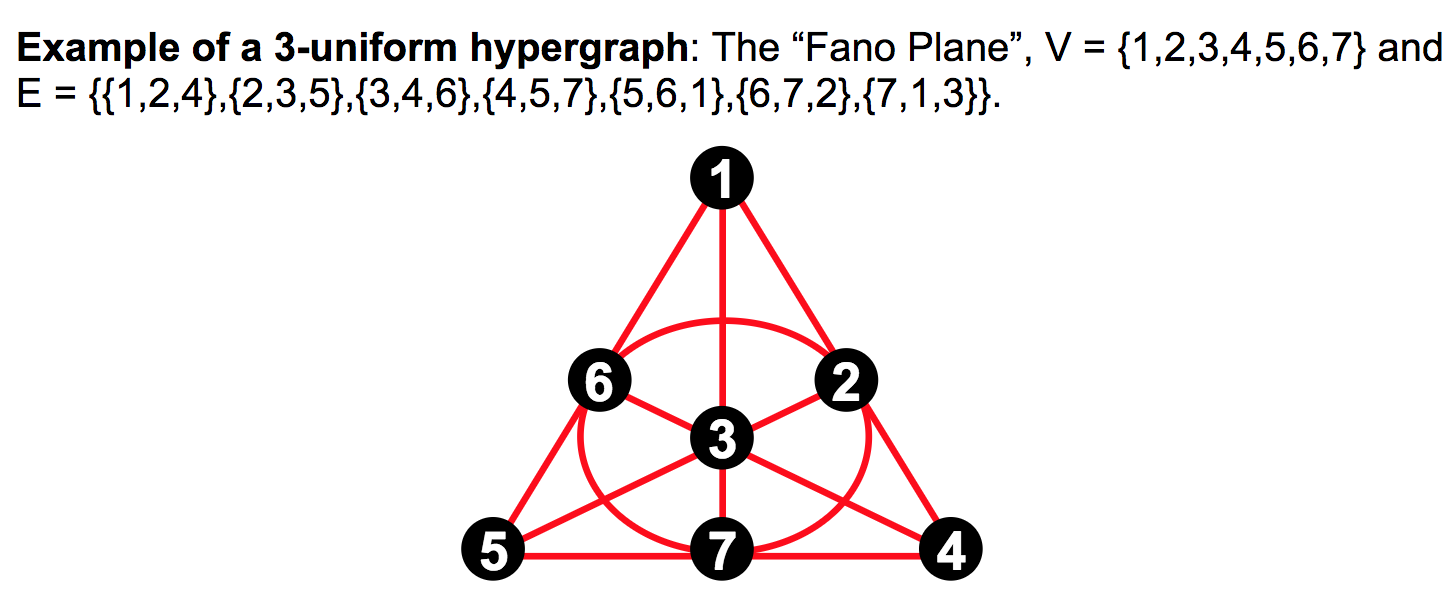
102. Hypergraph(超图):
- 一条边上有多个点的图
- 二阶超图: 平时使用的图
- 三阶超图:
101.hard sample mining:
- 取那些识别不好的样本再次进行模型微调
100.ground truth:
- 直述:有监督学习里的真值,有效值,标准值
90.范数:
- 范数主要是对矩阵和向量的一种描述,有了描述那么“大小就可以比较了”,从字面理解一种比较构成规范的数。有了统一的规范,就可以比较了。
- 例如:1比2小我们一目了然,可是(3,5,3)和(6,1,2)哪个大?不太好比吧
- 矩阵范数:描述矩阵引起变化的大小,AX=B,矩阵X变化了A个量级,然后成为了B。
- 向量范数:描述向量在空间中的大小。更一般地可以认为范数可以描述两个量之间的距离关系。
- L-0范数:用来统计向量中非零元素的个数。
- L-1范数:向量中所有元素的绝对值之和。可用于优化中去除没有取值的信息,又称稀疏规则算子。
- L-2范数:典型应用——欧式距离。可用于优化正则化项,避免过拟合。
- L-∞范数:计算向量中的最大值。
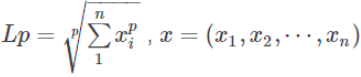
89.梯度裁剪:
- 直述:使得梯度不超过一个阈值
- 目的:解决梯度消失,梯度爆炸问题
- 公式:
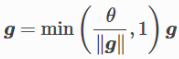
- 把所有梯度接成一个向量g
- 假设裁剪的阈值是
- 则,裁剪使得||g||不会超过
88.核范数:
- 矩阵奇异值的和,用于约束矩阵的低秩
- 对于稀疏性质的数据而言,其矩阵是低秩且会包含大量冗余信息
- 冗余信息可被用于恢复数据和提取特征
87.奇异值:
- 矩阵里的概念
- 一般通过奇异值分解定理求得
- 定义:设A为m*n阶矩阵,q=min(m,n), A*A的q个非负特征值的算数平方根,叫做A的奇异值
- 奇异值分解是线性代数和矩阵论中一种重要的矩阵分解法,适用于信号处理和统计学等领域
86.拉普拉斯矩阵:
- L=D-A: D----度矩阵,A----领接矩阵
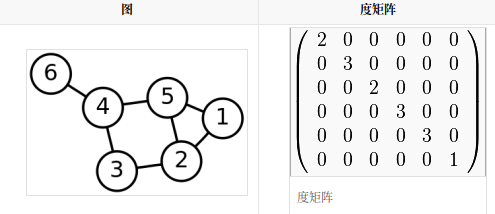
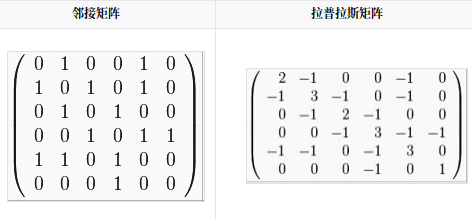
- 拉普拉斯矩阵是半正定矩阵
- 特征值中0出现的次数就是图连同区域的个数
- 最小特征值是0, 因为拉普拉斯矩阵每一行的和均为0
- 最小非零特征值是图的代数连通度
85.弱监督学习:
- 已知:数据和其一一对应的弱标签
- 目的:学习映射,将数据映射到更强的一组标签
- 解释:标签的强弱是指标签蕴含信息量的多少
- 例:已知图中有一只猪,学习住在哪,猪和背景的分界线
84.Benchmark
- 基准
83.Monocular Depth Estimation:单目深度估计
- 直述:从二维图像中,估计出三维空间
分割线:倒着来。。。。。。。。。。。。。。。
1.Memory:
- 我的出处:ECN。元学习时提及此方式。
- 原理:目标域的图片经网络题取出特征向量,存储到memory中;下一次新的即可和上次的做聚类;
- 公式:
(其中
是随着epoch不断线性增加的:
PS:但为什么新特征的影响会越来越大?)
- 用处:
- 1.Domain Adaptation,用新提取出的特征向量和旧的做聚类,可使模型在目标域上的泛化能力增强
- 2.因为是在整个训练过程中不断积累,所以能够很好地传递全局性质,不仅仅只在一个batch中。
2.Domain Adaptation:域适应
- 我的出处:ECN的主题。老师提及。语义分割也有此问题。
- 描述:用源域训练数据得到模型,在目标域上的泛化能力不强。
- 背景:常常出现在无监督和半监督学习。
3.Semantic Segmentation:语义分割
4.GCN:图卷积
- 我的出处:师兄提到过,CVPR19的工作中,不仅有可以做多标签识别,还有做半监督的,所以有必要~
- 背景:可以把图(邻阶矩阵)做输入,以探究信息训练模型
- 原理:
(1)输入:
1)特征矩阵 (节点数,每个结点的特征数)
2)邻阶矩阵A
(2) 隐藏层的传播规则: (
:非线性激活函数,W:权重矩阵,决定了下一层的特征数)
- (补)拉普拉斯矩阵:

1)
2)(GCN很多论文中用这种)
3)
- 相关名词:谱聚类,拉普拉斯矩阵,传播规则
5.Residual Network:残差网络(大名鼎鼎的ResNet)
- 我的出处:ECN修改预训练模型的时候,作者提及未懂。接下来时间又见到很多次。
- 背景:用深度网络比用浅层网络在训练集上的效果更差(不是过拟合:注意因为不是在测试集而是在训练集上)
- 作用:解决网络退化问题。即又保持了深的网络的高准确度,又避免了它会退化的问题。
- 实现:shortcut(identity mapping)
(其实很简单:每一层不仅取决于上一层,还要取决于很久之前的层)
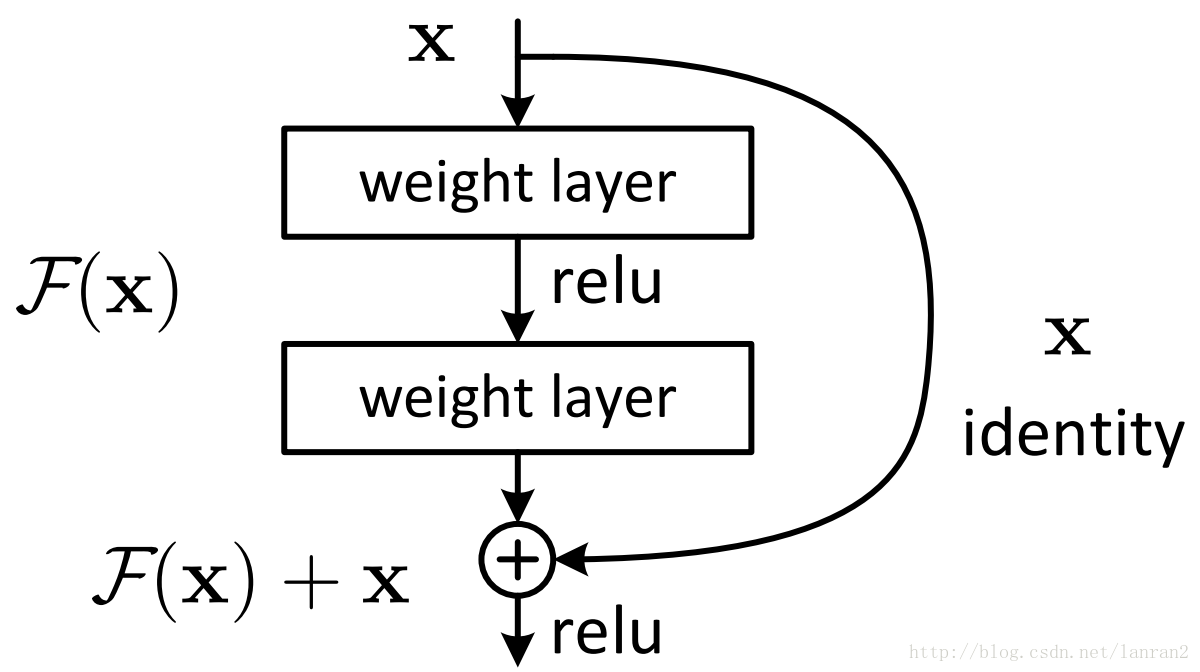
- 存在的问题:如果
和
的维度不一样怎么办? 那就
- 相关名词:shortcut
6.Learning Rate:学习率
- 我的出处:论文实验部分。pytorch有多种调节学习率的函数。
- 作用:调节梯度下降快慢。一般最开始值大,后续会减小。(太大会超过最优值,太小会下降得过慢)
- 相关名词:weight-decay(减小不重要参数对结果影响,即网络中有用的权重不会受到它的影响);momentum(当误差曲面在平坦区域,就可以更快学习);learning rate decay(提高SGD的寻优能力,学习率随着epoch的增大而减小)
8.Baseline
- 我的出处:ECN的时候,作者在实验部分阐述用到的名词。还有郑哲东那篇baseline的文章。
- 我的理解:不加作者的技巧,干干净净的基础网络。
9.Data Augmentation:数据增强
- 我的出处:ECN看实验的时候,提及对数据做的处理。pytorch有专门函数调用。
- 主要方法:
(1)flip:翻转变换
(2)random crop:随机修剪
(3)color jitterjing:色彩抖动
(4)shift:平移变换
(5)scale:尺度变换
(6)constrast:对比度变换
(7)noise:噪声扰动
(8) rotation/reflection:旋转变换/反射变换
(9)random erasing:随机擦除
10.temprature fact:
- 我的出处:ECN在做softmax时在指数项上加的分母
- 作用:平衡数据的分布
11.semi-supervised learning:半监督学习
-
我的出处:ECN的整个训练模式
-
描述:用标签数据和未标签数据共同训练模型
-
过程:
step1:用标签数据训练模型
step2:用无标签数据训练上述模型,并打上伪标签
step3:用标签数据和伪标签数据共同训练模型
- 好处:
(1)有标签数据太过昂贵
(2)精确决策边界以改变模型的鲁棒性
-
相关名词:pseudo labelling(伪标签)
12.pseudo labelling:伪标签
- 我的出处:ECN的memory损失函数计算
- 描述:使用某种方法未无标签的数据贴上标签,然后训练模型
- 方法:memory
13.finetune:迁移学习
- 我的出处:pytorch使用時涉及
14.NPLM:(一种 根据前几个词预测下一个词的语言模型)
- 我的出处:word2vec前的词向量语言模型
- 作用:用前几个词预测下一个词。词向量(输入层的参数)是这个过程重要的副产品。
- 具体:
(1)输入:根据词典进行one-hot编码,输入。(不是输入好几个词预测下一个词吗?)
(2)过程:循环输入前几个词,预测值,训练网络。
- 缺点:训练过程过慢(和Word2Vec比起來)
15.Word2Vec:(一种 产生词向量的模型,以无监督方式学习语义)
- 我的出处:NPL第一个接触的重要名词
- 作用:用前几个词预测下一个词。词向量(输入层的参数)是这个过程重要的副产品。
- 结构:CBOW + Skip-gram
(1)CBOW:(连续词袋模型)用上下文预测当前词。(将向量简单地加到一起,中间只有一层,迫使网络更加有效地生成词向量)
(2)Skip-gram:用当前词词预测上下文
- 增加效率的方式(和NPLM比起来):Hierarchical Softmax
- 增加Loss效果的方式:负采样
- 调用库:gensim
16.Hierarchical Softmax:(一种 输入层数据结构)
- 我的出处:word2vec中CBOW的输入层的数据结构
- 作用:增加训练效率。查询变快,训练也变快。
- 原理:将输入层原来的扁平结构变成Huffman树。(NPLM只是更新一个词节点的权重,而Hierarchical Softmax从叶节点到连边的所有权重。)
17.negtive sample:负采样
- 我的出处:word2vec中CBOW的损失函数
- 公式:
(这个思想很多地方用到)
18.RNN:循环神经网络
- 我的出处:为什么粲要选这里
- 特点:同层之间有循环,使信息能够保留,使网络具有记忆能力
- 公式(最简单的,以便理解):
(1)输入层到隐含层: (激励函数的项不仅有函数本身的,还有记忆遗留的)
(2)隐含层到输出层: (激励函数的还是普通的项)
- 缺点:
(1)记忆能力有限
(2)梯度消失,梯度爆炸(难以训练收敛)
- 序列生成问题:需要种子,训练和预测都需要循环
- 相关名词:LSTM(比起RNN神经元多了 输入门,输出门,遗忘门),GRU
- 补充:RNN既可关注到词语的含义也可关注到词语间的联系。
- 拓展:音乐生成模型网络
网络架构:
(1)输入输出:多输入多输出(如曲调的旋律,节奏,强弱等等)
(2)隐藏层:不分多段,可以帮助更好地捕捉序列间的微妙关系。
使用工具:MIDII音乐
19.Encoder-Decoder(seq2seq):编码器和解码器
- 我的出处:文本翻译时遇到的模型
- 背景:人类在进行翻译的时候,定然不是一字一句进行翻译的。一般都是先理解整个语义,然后按照自己的理解翻译出来。而编码器就像是先“理解语义”,解码器就像“翻译出来”。
- 结构:
(1)编码器:输入文本经过几层RNN,输出内部状态(向量)
(2)解码器:只是比编码器多一个输出层(直接用编码器的权重初始化解码器!!!理解:其实这种方式也是网络连接的过程)。用SOS循环生成。
- 相关名词:Attention
- 拓展:encoder和decoder不仅仅可以用RNN,还可以用CNN等各种网络。这里就会提到一个广义的翻译的问题了,不仅仅是文本转文本,还有图片转文本等等。
20.Attention:注意力
- 我的出处:组会时师兄多次提及。Encoder和Decoder模型优化的一种方式。
- 背景:Encoder和Decoder翻译模型在较短的句子变现较好,但是长的句子不佳。
- 直述:一种前馈式神经网络,输出词的权重。
- 原理:
(1)在encoder过程中,会生成每个词的内部状态(向量)
(2)在decoder的时候,不仅要产生翻译结果,还要将内部状态(向量)输入到Attention网络里,该网络会输出一个权重向量。
(3)在下次内部状态(向量)要使用decoder之前:使用内部状态(向量)和Attention的输出做点乘(理解:表示重点关注某个词),然后做decoder的输入。
21.Reinforcement Learning:强化学习
- 我的出处:转专业友喜欢,学校有老师研究
- 强调:不止是被动地学习神经网络,还有完整的intelligent agent和环境的互动。
- 组成:
(1)Agent:主体(动作的执行者)
(2)Environment:环境(环境无法操控主体,但是会给主体反馈)
(3)Action:动作
(4)Reward:奖励
(5)Q(s,a):一个评价函数,用以给当前状态下的动作打分。主导Agent的动作,做分高者。
- 原理:神经网络拟合Q函数
- 过程:(如Flappy Bird游戏)
1.随机执行,积累数据:此时状态,动作,环境反馈,下时刻的状态
2.神经网络训练Q函数:(开始训练,不再随机,逐渐清醒)
(1) 输入:游戏一帧的图像画面
(2)经过:卷积,池化,全连接等等操作。
(3)输出:
神经元的个数:可以执行的动作的个数。
数值:Q函数的值,分高者,即为应该执行的值。
- 难点:在觉大部分时间环境都不会给出即时反馈。在没有反馈的阶段应该如何?将下一时刻的状态输入,得到的Q函数作为此次的Q函数,如此,即可保证动作的选择会倾向与未来想要的状态一致。
- 启发:
(1)大的算法框架,它的思维往往主导者一个非常大的学习方向(如CNN,RNN,GAN, Encoder 和 Decoder, Reinforcement Learnning等等)。
(2)其他问题向深度学习的转换。
- 相关名词:DQN
20.SlowFast Network:(一种视频分类网络)
- 我的出处:2019ICCV口头文章
- 原理:快慢双通道网络。快捕捉动作,慢捕捉语义。
21.Batch Normalization
22.Internal Covariate Shift
https://blog.csdn.net/hjimce/article/details/50866313
https://www.zhihu.com/question/38102762
https://zhuanlan.zhihu.com/p/39918971
https://www.jianshu.com/p/5977ea170322
https://blog.csdn.net/mao_xiao_feng/article/details/54317852
https://blog.csdn.net/guoyuhaoaaa/article/details/80236500
23.Distillation:知识蒸馏(KD)
- 我的出处:2019CVPR涉及的主题知识点
- 背景:
(1)提高机器学习算法表现的一个简单方法就是:训练不同模型然后对预测结果取平均
(2)但是要训练多个模型会带来过高的计算复杂度和部署难度。
(3)
- 作用:
(1)distillation:把大网络的知识压缩成小网络的一种方法
(2) specialist models:对于一个大网络,可以训练多个专用网络来提升大网络的模型表现
- 相关名词:
(1)teacher:原始模型或模型ensemble(一种集成模型一个完整和多个专用,能够学习区分完整模型容易混淆的细粒度的类别)
(2) student:新模型
(3) transfer set:用来迁移teacher知识,训练student的数据集合
(4) soft target:teacher输出的预测结果(一般是softmax预测之后的概率)
(5) hard target:样本原本的标签
(6) temperature:蒸馏目标函数中的超参数
(7) born-again network(BAN):蒸馏的一种,指student和teacher的结构和尺寸完全一样。既然老师和学生一样就可以不断地迭代下去,就新出来的student又可以当下一个的老师。这样,student甚至可以青出于蓝而胜于蓝。
(8) teacher annealing:防止student的表现被teacher限制,在蒸馏时逐渐减少soft targets的权重。
(9) dark knowledge:捕捉类和类之间的关系(主要是soft-target的作用吧)
(10)secondary information:捕捉图片中,除标签以外其他的信息。即“Tolerant Teacher”,就降低teacher的top1,teacher会就此差一点,但是因此训练出来的student会好很多。
24.Lable Smoothing:标签平滑
- 我的出处:Re-ID Baseline的时候好像提过,然后Teacher-Student Learning中的BAN加速好像也有它。
- 作用:解决one-hot导致的过拟合问题
- 公式:new_lables=(1.0-lable_smoothing)*one_hot_lables+lable_smoothing/num_classes
25.AutoML
- 我的出处:CVPR2019分享会的一个点,开组会的时候师兄也提过
- 直述:尽量不通过人来设定超参数,而是使用某些学习机制,调节这些超参数
- 分类:
(1)传统AutoML:
贝叶斯优化:
多臂老虎机:
进化算法:
强化学习:
(2) 深度AutoML:
1)Hyperparameter optimization(ho)(训练超参数)
learning rate:
regularzation:
momentum:
2)Neural architecture search(nas)(网络结构超参数)
26.Space Subspace Clustering(SSC):子空间聚类
-
我的出处:CVPR2019论文
-
背景:高维数据聚类是聚类技术的重点和难点。其思想是将搜索局部化在相关维中进行。
-
传统聚类方法分类:
(1)划分方法:将数据集随机划分为k个子集,随后通过迭代重定位技术试图将数据对象从一个簇移到另一个簇来不断改进聚类的质量。
(2)层次方法:对给定的数据对象集合进行层次分解,根据层次的形成方法又可分为凝聚和分裂两大类。
(3)基于密度方法:根据领域对象的密度或者密度函数生成聚类,使得每个类在给定范围的区域内至少包含一定数目的点。
(4)基于网络方法:将对象空间量化为有限数目的单元,形成一个网格结构,使所有聚类操作都在这个网络结构上进行,使聚类速度得到较大提高。
(5)基于模型方法:为每个类假定一个模型,寻找数据对给定模型的最佳拟合。
- 聚类问题的难点:
(1)聚类方法的可伸缩性
(2)对复杂形状和类型数据进行聚类的有效性
(3)高维聚类分析技术
(4)混合数据的聚类
- 高维数据聚类的难点和解决:
1)难点
(1)高维数据集中存在大量无关的属性使得在所有维中存在簇的可能性几乎为零。
(2)高维空间较低维空间中数据分布要稀疏,数据间距离几乎相等是普遍现象,而传统聚类方法是基于距离进行聚类的,因此在高维空间中无法基于距离来构建簇。
2)解决:
(1)特征转换
(2)特征选择/子空间聚类:特征选择只在相关子空间上执行挖掘任务,因此它比特征转换更有效地减少维。特征选择一般使用贪心策略等搜索方法搜索不同特征子空间,然后使用一些标准来评价子空间,以找到所需要的簇。
- 子空间搜索分类:自顶向下,自底向上。
27.Decomposition:矩阵分解
- 直述:将矩阵拆解为数个矩阵的乘积。
- 方法:
1)三角(LU)分解法:分解为上三角和下三角
2)QR分解法:分解为上三角和正规正交矩阵
3)奇异值分解法:分解为正交矩阵
28.Spectral clustering:谱聚类
29.Fourier Transformation:傅里叶变换
- 直述:将满足条件的的某个函数表示成三角函数或者它们积分的线性组合。
30.Spectral decomposition:谱分解/Eigendecomposition:特征分解
- 直述:将矩阵分解为由其特征值和特征向量表示的矩阵之积的方法
31.Semi-Supervised Learning:半监督学习
- 我的出处:ECN及CVPR2019香港理工大学用图网络做半监督的工作。
- 方法:
32.Graph Signal Processing(GSP):图信号处理
33.Hidden Markov Model(HMM):隐马尔可夫模型
34.Conditional Random Field(CRF):条件随机场
- 我的出处:NLP涉及的概念
- 直述:一种序列预测模型(有人说它是逻辑回归的序列版)
- 原理:
Step1:
序列情况矩阵
参数矩阵
Step2:
用上两者列出又像逻辑回归,又像贝叶斯的公式,进行最大化后即可求得参数矩阵。
然后就可以用之前的序列预测下一个。
35.Bayes' theorem:贝叶斯定理
- 直述:
已知:
(1)H[1],H[2]...H[3]互斥,且构成完全事件
(2)各时间概率:P(H[I]), I=1,2...N
(3)P(A|H[i])
求:
P(H(i)|A)
- 公式:P(H[i]|A)=
36.Long-Short Term Memory(LSTM)
37.Logistic:逻辑回归
- 我的出处:在看似然估计的时候突然牵扯到
- 用处:预测问题,二分类问题
- 原理:
Step1:hypothesis: (亦称sigmoid函数。其中,z=
)
Step2:Loss:
(上为对数似然函数,从似然函数推导而来:)
Step3: 用梯度下降法不断更新的值,直到使
的值为最大,即为所求的回归。
38.Markov Model:马尔可夫模型
- 我的出处:第一次数学建模交通流预测的时候
- 直述:一种统计模型
- 作用:在语音识别,词性标注,语音转换,概率文法等NLP领域作用甚大。
39.HMM:隐马尔可夫模型
- 我的出处:在学随机条件场的时候被进行对比
- 直述:一个统计模型。
- 作用:用来描述一个含有隐含未知参数的马尔可夫过程。
40.Viterbi Alorithm:维特比算法
- 我的出处:条件随机场时见。(好像是深度学习常见的底层算法)
- 一种动态规划算法
- 作用:寻找最有可能产生观测事件序列的”维特比路径“隐含状态序列。(特别是在马尔可夫信息源上下文和隐马尔可夫模型中)
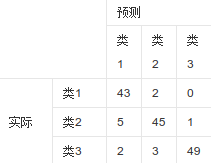
41.Confusion Matrix:混淆矩阵
- 我的出处:在做RNN实例时,评估处用的
- 直述:一个表示真实和预测关系的矩阵。(常用在人工智能领域)
- 原理:
行:真实(每一行总数:这一类真实有多少个)
列:预测(每一列总数:这一类预测有多少个)
对角线:每一类对的个数
- 例:
42.Instance Segmentation:实例分割
- 我的出处:CVPR一篇文章用Mask-R-CNN做实例分割
- 直述:圈出物体的轮廓,比目标检测更进一步(目标检测只是框框)。
43.ULMFiT:通用语言模型微调
44.ELMo:语言模型的词嵌入
45.BERT:(一种NLP模型)
46.BigGAN:(生成的图片十分逼真,真假难辨。但是需要很大算力。是算力的提升,不是算法的提升)
47.Fast.ai:(可以在18min内训练完image net)
48.vid2vid:(一个可以生成超逼真视频的生成对抗网络)
49.Pytext:(FaceBook工程师开源自家工程师在用的工业级NLP建模框架)
50.Duplex:AI打电话(谷歌I/O开发者大会上的)
51.Spining Up:(OpenAI的一个强化学习教程,完全在初学者视角)
52.Dopamine:多巴胺(谷歌的一个强化学习开源框架)
53.R-CNN/fast R-CNN/faster R-CNN+RPN/YOLO/SSD/R-FCN
- 我的出处:目标检测,语义分割,实例分割了解
- 详情:
54.PCA/Tracking-by-Detection/SAE/DLT/FCNT/MD Net
55.VGG
56.DBN:深度信念网络
57.FCN:全卷积网络
-
相关名词:SegNet
58.Dilated Convolutiona(空洞卷积),DeepLab, RefineNet
59.Mask R-CNN
60.T-SNE
61.DCN:(一种自编码器方法,在聚类的时候使用)
62.Deep Cluster:(聚类时使用)
63.Associative Deep Clustering:(聚类时使用)
64.Invarient Information Clustering CNN(IIC-CNN):(聚类,于网络本身)
65.SVD:
- 我的出处:在学Fast RCNN的时候,提到全链接如何使用SVD加速。之前也听到过。
66.Bilinear Interpolation:双线性插值
67.IoU Net:
- 我的出处:CVPRS实例分割提到的可以改变做某个工作的网络
68.Inception:
69.NAS:Architecture Search with Reinforcement Learning
70.BERT
71.Multi-Task Learning
- 我的出处:在了解半监督学习的时候,提到解决数据量不够的方法
- 相关名词:权重转换矩阵
72.MixMatch:
- 我的出处:了解半监督学习时,说到谷歌用的一个新方法
73.UDA:无监督数据增强
74.pseudo labels:伪标签
- 我的出处:ECN的时候师兄第一次提及。之后常见却反映不过来。
- 直述:半监督,无监督模型总归还是要用标签训练模型的,但这个标签又不是真的,而是通过聚类等方法得到的。
75.Leaky ReLUs:
- 我的出处:WMCT
- 直述:原来的ReLU在x为负数的时候为零,但是Leaky ReLUs是赋一个斜率。
76.weight-ratio:源域和目标域之间的权重比
- 我的出处:WMCT里提到伪标签好坏里说的。
- 直述:网上没有资料,自己的理解就是源域初始化的效果对之后的影响。
77.DBSCAN:一种基于密度的聚类算法
- 我的出处:WMCT里提到的
- 直述:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/(动画)
- 优点:
1.与K-means方法相比:无需事先知晓形成簇类的数量。
2.与K-means方法相比:可以发现任意形状的簇类。(?)
3.能够识别出噪声点。(?)
4.对样本数据不敏感。
- 缺点:
1.不能很好地反映高维数据。
2.不能很好地反映数据集变化的密度。
3.如果样本集密度不均匀,聚类的间距相差较大时,聚类质量较差。
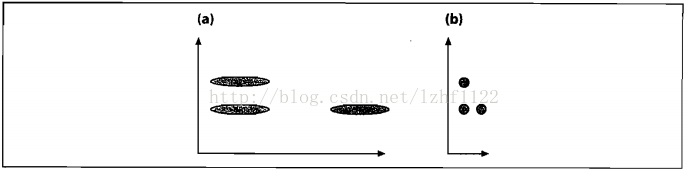
78.Mahalanobis distance:马式距离
- 我的出处:WMCT提到用K-reciprocal Encoding Distance来度量距离在Re-ID十分有用,由马氏和杰卡德组成
- 直述:
(即在欧式距离中间添了一个协方差矩阵)
- 作用:将量纲做归一化,如图:
79.Jaccard Distance:杰卡德距离
- 我的出处:WMCT中提到K-reciprocal Encoding Distance的组成部分
- 直述:样本间不同值所占的比例:

80. k-reciprocalEncoding
- 我的出处:WMCT里提到用KRE做相似度度量,提高re-ranking准确度的一种方式。
- 直述:有马式距离和杰卡德距离一起,如图:
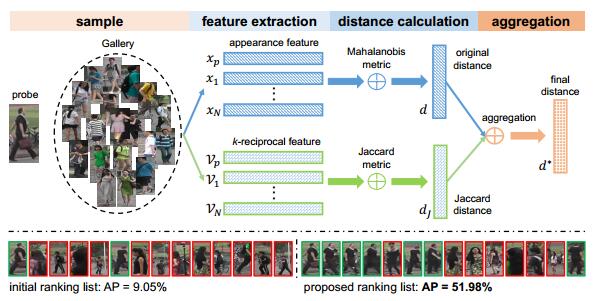
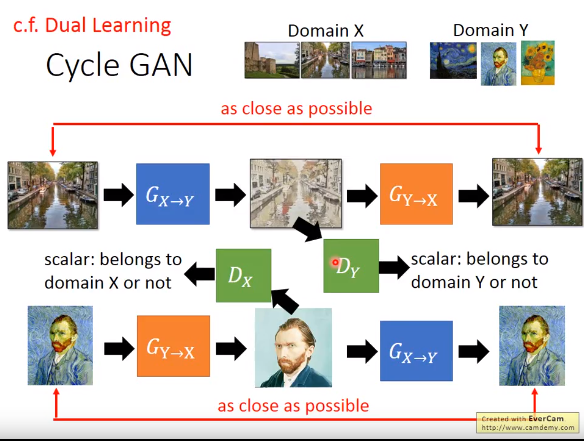
81.CycleGAN
- 我的出处:WMCT提到相关工作的时候,有篇文章和CycleGAN是相同的架构,只不过换成了特征
- 直述:
82.Co-Train:协同训练
- 我的出处:WMCT受Co-Train的启发
- 直述:一种MultiView算法。有多个数据集,训练出多个模型(分类器)。然后,用各自对无标签数据打标。选取前K个置信度的数据,扔到对方的数据集里面。
83.trip
最后
以上就是尊敬故事最近收集整理的关于深度学习——名词总结篇103. HIN(异构信息网络)102. Hypergraph(超图): 101.hard sample mining: 100.ground truth: 90.范数:89.梯度裁剪: 88.核范数: 87.奇异值:86.拉普拉斯矩阵:85.弱监督学习:84.Benchmark83.Monocular Depth Estimation:单目深度估计分割线:倒着来。。。。。。。。。。。。。。。1.Memory:2.Domain Adaptation:域适应3.Semanti的全部内容,更多相关深度学习——名词总结篇103.内容请搜索靠谱客的其他文章。








发表评论 取消回复