前言
刷豆瓣看到《深入理解 JVM》出第三版了,遂买之更新 JVM 知识,本文为笔记,仅供个人 Review
ch02. Java 内存区域与内存溢出
2.1 运行时数据区域
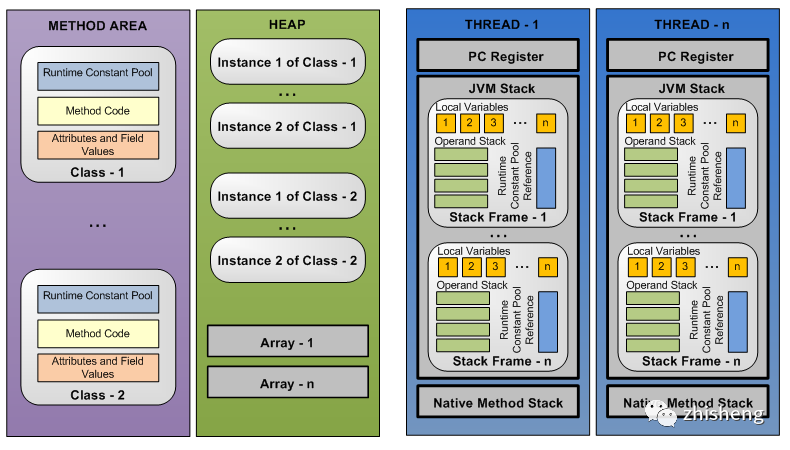
参考:JVM 规范,Memories of a Java Runtime
堆:JVM 启动时按-Xmx, -Xms大小创建的内存区域,用于分配对象、数组所需内存,由 GC 管理和回收
方法区:存储被 JVM 加载的类信息(字段、成员方法的字节码指令等)、运行时常量池(字面量、符号引用等)、JIT 编译后的 Code Cache 等信息;JDK8 前 Hotspot 将方法区存储于永久代堆内存,之后参考 JRockit 废弃了永久代,存储于本地内存的 Metaspace 区
直接内存:JDK1.4 引入 NIO 使用 Native/Unsafe 库直接分配系统内存,使用 Buffer,Channel 与其交互,避免在系统内存与 JVM 堆内存之间拷贝的开销
线程私有内存
程序计数器:记录当前线程待执行的下一条指令位置,上下文切换后恢复执行,由字节码解释器负责更新
JVM 栈
描述 Java 方法执行的内存模型:执行新方法时创建栈帧,存储局部变量表、操作数栈等信息
存储单位:变量槽 slot,
long, double占 2 个 slot,其他基本数据类型、引用类型占 1 个,故表的总长度在编译期可知
本地方法栈:执行本地 C/C++ 方法
2.2 JVM 对象
1. 创建对象
分配堆内存:类加载完毕后,其对象所需内存大小是确定的;堆内存由多线程共享,若并发创建对象都通过 CAS 乐观锁争夺内存,则效率低。故线程创建时在堆内存为其分配私有的分配缓冲区(TLAB:Thread Local Allocation Buffer)
内存模型
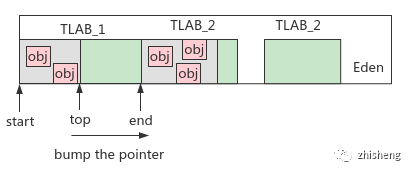
分配流程
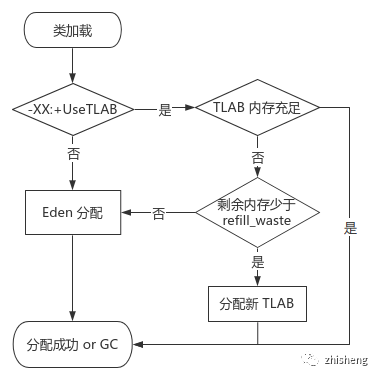
注:当 TLAB 剩余空间不足以分配新对象,但又小于最大浪费空间阈值时,才会加锁创建新的 TLAB
零值初始化对象的堆内存、设置对象头信息、执行构造函数 <init>()V
2. 对象的内存布局
对象头
Mark Word:记录对象的运行时信息,如 hashCode,GC 分代年龄,尾部 2 bit 用于标记锁状态
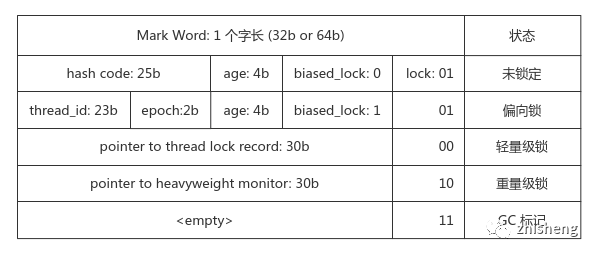
Class Pointer:指向所属的类信息
数组长度(可选,对象为数组):4 字节存储其长度
对象数据:各种字段的值,按宽度分类紧邻存储
对齐填充:内存对齐为 1 个字长整数倍,减少 CPU 总线周期
验证:openjdk/jol 检查对象内存布局
|
2.3 内存溢出
堆内存:-Xms指定堆初始大小,当大量无法被回收的对象所占内存超出-Xmx上限时,将发生内存溢出 OutOfMemoryError
排查:通过 Eclipse MAT 分析
-XX:+HeapDumpOnOutOfMemory生成的 *.hprof 堆转储文件,定位无法被回收的大对象,找出其 GC Root 引用路径解决:若为内存泄露,则修改代码用
null显式赋值、虚引用等方式及时回收大对象;若为内存溢出,大对象都是必须存活的,则调大-Xmx、减少大对象的生命周期、检查数据结构使用是否合理等// -Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError public class HeapOOM { static class OOMObject {} public static void main(String[] args) { List<OOMObject> vs = new ArrayList<>(); while (true) vs.add(new OOMObject()); } }分析 GC Root 发现
com.ch02.HeapOOM对象间接引用了大量的OOMObject对象,共占用 15.4MB 堆内存,无法回收最终导致 OOM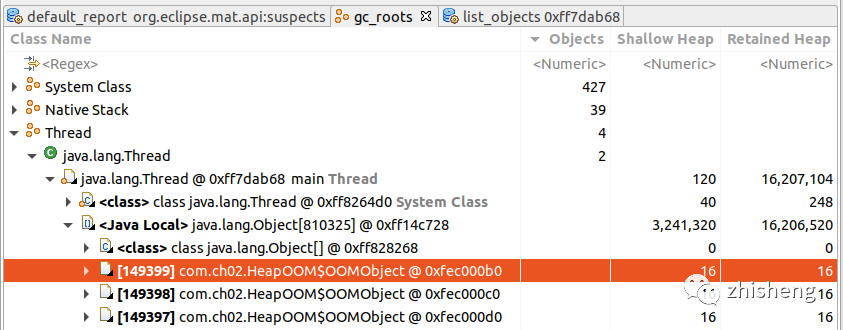
栈内存:-Xss指定栈大小,当栈深度超阈值(比如未触发终止条件的递归调用)、本地方法变量表过大等,都可能导致内存溢出 StackOverflowError
方法区:-XX:MetaspaceSize指定元空间初始大小,-XX:MaxMetaspaceSize指定最大大小,默认 -1 无限制,若在运行时动态生成大量的类,则可能触发 OOM
运行时常量池:strObj.intern()动态地将首次出现的字符串对象放入字符串常量池并返回,JDK7 前会拷贝到永久代,之后则直接引用堆对象
|
直接内存:-XX:MaxDirectMemorySize指定大小,默认与-Xmx一样大,不被 GC 管理,申请内存超阈值时 OOM
ch03. 垃圾回收与内存分配
GC 可分解为 3 个子问题:which(哪些内存可被回收)、when(什么时候回收)、how(如何回收)
3.1 GC 条件
1. 引用计数算法(reference counting)
原理:每个对象都维护一个引用计数器rc,当通过赋值、传参等方式引用它时rc++,当引用变量修改指向、离开函数作用域等方式解除引用时rc--,递减到 0 时说明对象无法再被使用,可回收。伪代码:
|
优点:思路简单,对象无用即回收,延迟低,适合内存少的场景
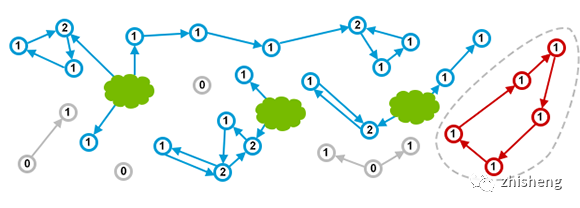
缺点:此算法中对象是孤立的,无法在全局视角检查对象的真实有效性,循环引用的双方对象需引入外部机制来检测和回收,如下图红色圈(图源:what-is-garbage-collection)
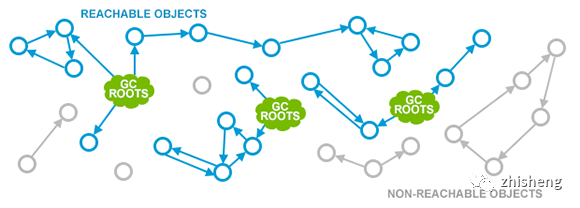
2. 可达性分析算法(reachability analysis)
原理:从肯定不会被回收的对象(GC Roots)出发,向外搜索全局对象图,不可达的对象即无法再被使用,可回收;常见可作为 GC Root 的对象有:
执行上下文:JVM 栈中参数、局部变量、临时变量等引用的堆对象
全局引用:方法区中类的静态引用、常量引用(如 StringTable 中的字符串对象)所指向的对象
优点:无需对象维护 GC 元信息,开销小;单次扫描即可批量识别、回收对象,吞吐高
缺点:多线程环境下对象间的引用关系随时在变化,为保证 GC Root 标记的准确性,需在不变化的 snapshot 中进行,会产生 Stop The World(以下简称 STW) 卡顿现象
3. 四种引用类型
| 引用类型 | 类 | 回收时机 |
|---|---|---|
| 强引用 | - | 只要与 GC Root 存在引用链,则不被回收 |
| 软引用 | SoftReference | 只被软引用所引用的对象,当 GC 后内存依然不足,才被回收 |
| 弱引用 | WeakReference | 只被弱引用所引用的对象,无论内存是否足够,都将被回收 |
| 虚引用 | PhantomReference | 被引用的对象无感知,进行正常 GC,仅在回收时通知虚引用(回调) |
示例:限制堆內存 50MB,其中新生代 30MB,老年代 20MB;依次分配 5 次 10MB 的byte[]对象,仅使用软引用来引用,观察 GC 过程
|
4. finalize
原理:若对象不可达,被标记为可回收后,会进行finalize()是否被重写、是否已执行过等条件筛选,若通过则对象会被放入 F-Queue 队列,等待低优先级的后台 Finalizer 线程触发其finallize() 的执行(不保证执行结束),对象可在finalize中建立与 GC Root 对象图上任一节点的引用关系,来逃脱 GC
使用:finalize 机制与 C++ 中的析构函数并不等价,其执行结果并不确定,不推荐使用,可用try-finally替代
3.2 GC 算法
分代收集理论
两个分代假说:符合大多数程序运行的实际情况
弱分代假说:绝大多数对象是朝生夕灭,生存时间极短
强分代假说:熬过越多次 GC 的对象,越可能被继续使用,越难以回收
对应地,JVM 堆被划分为 2 个不同区域,将对象按年龄分类,兼顾了 GC 耗时与内存利用率
新生代:大量对象将被回收,只关注仍存活的对象,逐步晋升
老年代:大量对象不被回收,只关注要被回收的对象
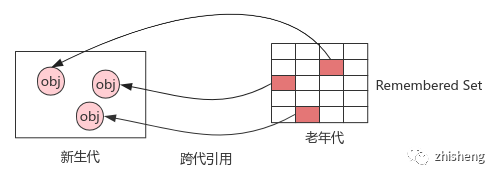
跨代引用
问题:老年代会引用新生代,新生代 GC 时需遍历老年代中大量的存活对象,分析可达性,时间复杂度高
背景:相互引用的对象倾向于同时存亡,比如跨代引用关系中的新生代必然会逐步晋升,最终消除跨代关系
假说:跨代引用相比同代引用只占极少数,无需全量扫描老年代
实现:新生代维护全局数据结构:记忆集(Remembered Set),将老年代分为多个子块,标记存在跨代引用的子块,等待后续扫描;代价:为保证记忆集的正确性,需在跨代引用建立或断开时保持同步
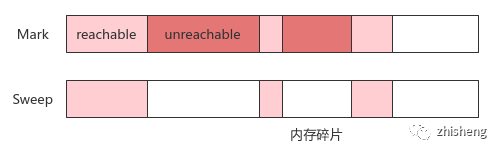
1. 标记清除:Mark-Sweep
原理:标记不可达对象,统一清理回收,反之亦可
缺点:执行效率不稳定,回收耗时取决于活跃对象的数量;内存碎片多,会出现内存充足但无法分配过大的连续内存(数组)
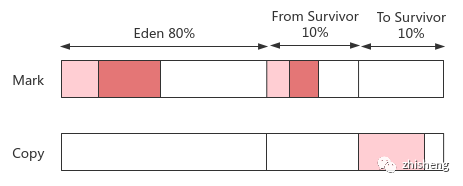
2. 标记复制:Mark-Copy
理论:将堆内存切为两等份 A, B,每次仅使用 A,用完后标记存活对象复制到 B,清空 A 后执行 swap
优点:直接针对半区回收,无内存碎片问题;分配内存只需移动堆顶指针,高效顺序分配
缺点:当 A 区有大量存活对象时,复制开销大;B 区长时间闲置,内存浪费严重
实践:对于存活对象少的新生代,无需按 1:1 分配,而是按 8:1:1 的内存布局,其中 Eden 和 From 区同时使用,只有 To 区会被闲置(担保机制:若 To 区不够容纳 Minor GC 后的存活对象,则晋升到老年区)
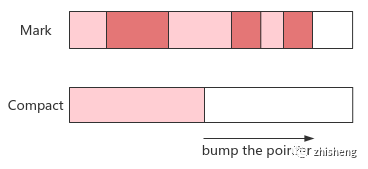
3. 标记整理:Mark-Compact
原理:标记存活对象后统一移动到内存空间一侧,再回收边界之外的内存
优点:内存模型简单,无内存碎片,降低内存分配和访问的时间成本,能提高吞吐
缺点:对象移动需 STW 同步更新引用关系,会增加延迟
3.3 HotSpot GC 算法细节
1. 发起 GC:安全点与安全区域
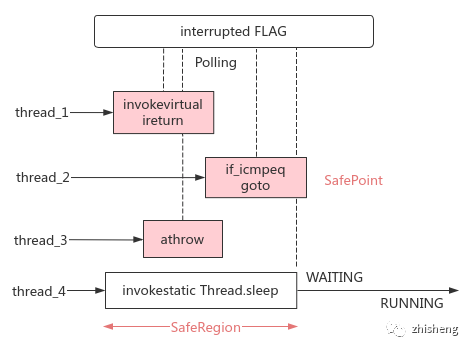
问题:为保证可达性分析结果的准确性,需挂起用户线程(STW),再从各线程的执行上下文中收集 GC Root,如何通知线程挂起?
安全点:HotSpot 内部有线程中断标记;在各线程的方法调用、循环跳转、异常跳转等会长时间执行的指令处,额外插入检查该标记的
test高效指令;若轮询发现标记为真,线程会主动在最近的 SafePoint 处挂起,此时其栈上对象的引用关系不再变化,可收集 GC Root 对象安全区域:引用关系不会变化的指令区域,可安全地收集 GC Root;线程离开此区域时,若 GC Root 收集过程还未结束,则需等待
示意图
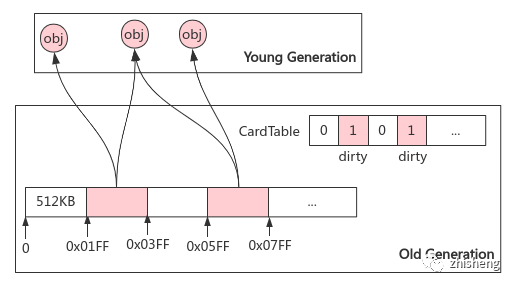
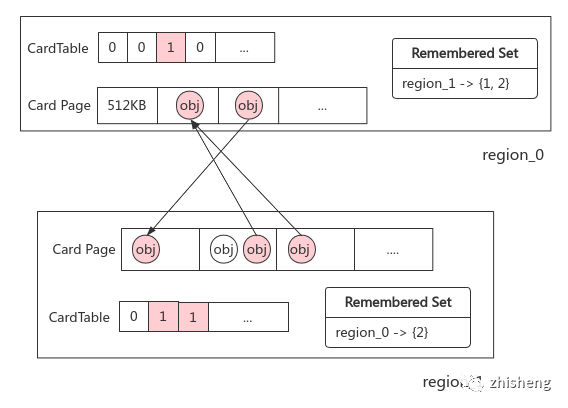
2. 加速 GC:CardTable
问题:非收集区域(老年代)会存在到收集区域(新生代)的跨代引用,如何避免对前者的全量扫描?
卡表:记忆集的字节数组实现;将老年代内存划分为 Card Page(512KB)大小的子内存块,若新建跨代引用,则将对应的 Card 标记为 dirty,GC 时只需扫描老年代中被标记为 dirty 的子内存块
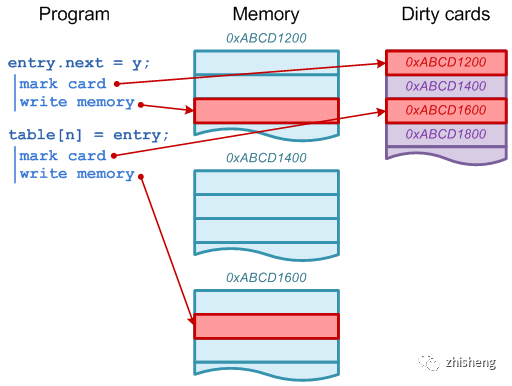
写屏障:有别于volatile禁用指令重排的内存屏障,GC 中的写屏障是在对象引用更新时执行额外 hook 动作的机制。简单实现:
|
使用写屏障保证 CardTable 的实时更新(图源:The JVM Write Barrier - Card Marking)
3. 正确 GC:并发可达性分析
参考演讲:Shenandoah: The Garbage Collector That Could by Aleksey Shipilev
问题:GC Roots 的对象源固定,故枚举时 STW 时间短暂且可控。但后续可达性分析的时间复杂度与堆中对象数量成正相关,即堆中对象越多,对象图越复杂,堆变大后 STW 时间不可接受
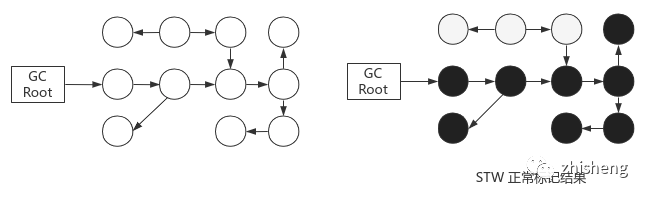
解决:并发标记。引出新问题:用户线程动态建立、解除引用,标记过程中图结构发生变化,结果不可靠;证明:用三色法描述对象状态
白色:未被回收器访问过的对象;分析开始都是白色,分析结束还是白色则不可达
灰色:被回收器访问过,但其上至少还有 1 个引用未被扫描(中间态)
黑色:被回收器访问过,其上引用全部都已被扫描,存在引用链,为存活对象;若其他对象引用了黑色对象,则不必再扫描,肯定也存活;黑色不可能直接引用白色
STW 无并发的正确标记:顶部 3 个对象将被回收
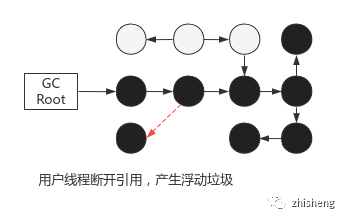
用户线程并发修改引用,会导致标记结果无效,分 2 种情况:
少回收,对象标记为存活,但用户解除了引用:产生浮动垃圾,可接受,等待下次 GC
误回收,对象标记为可回收,但用户新建了引用:实际存活对象被回收,内存错误
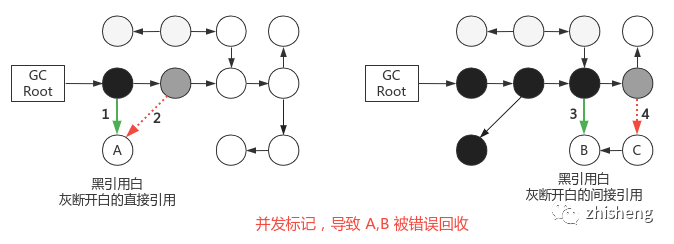
论文《Uniprocessor Garbage Collection Techniques - Paul R. Wilson》§3.2 证明了「实际存活的对象被标记为可回收」必须同时满足两个条件(有时间序)
插入一条或多条从黑色到白色的新引用
删除所有灰色到该白色的直接、间接引用
为正确实现标记,打破其中一个条件即可(类比打破死锁四个条件之一的思想),分别对应两种方案:
增量更新 Increment Update:记录黑到白的引用关系,并发标记结束后,以黑为根,重新扫描;A 直接存活
原始快照 SATB(Snapshot At The Begining):记录灰到白的解引用关系,并发标记结束后,以灰为根,重新扫描;B 为灰色,最后变为黑色,存活。需注意,若没有步骤 3,则 B,C 变为浮动垃圾
3.4 经典垃圾回收器
搭配使用示意图:
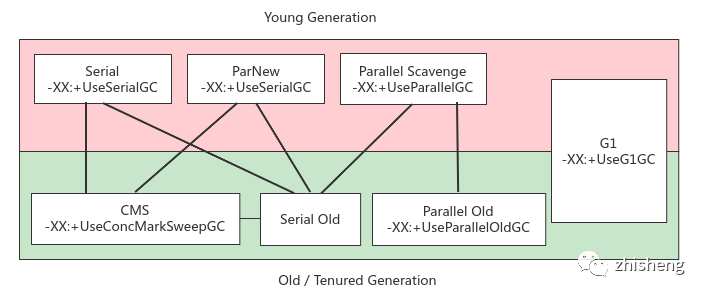
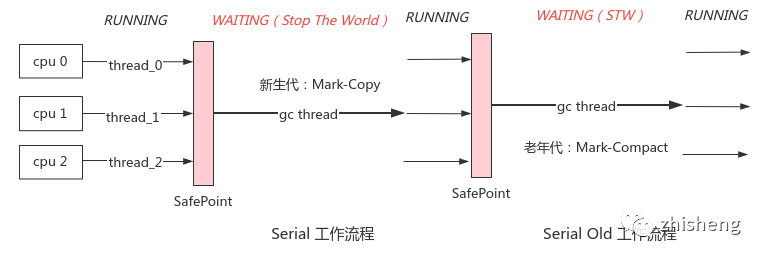
1. Serial, SerialOld
原理:内存不足触发 GC 后会暂停所有用户线程,单线程地在新生代中标记复制,在老年代中标记整理,收集完毕后恢复用户线程
优点:全程 STW 简单高效
缺点:STW 时长与堆对象数量成正相关,且 GC 线程只能用到 1 core 无法加速
场景:单核 CPU 且可用内存少(如百兆级),JDK1.3 之前的唯一选择
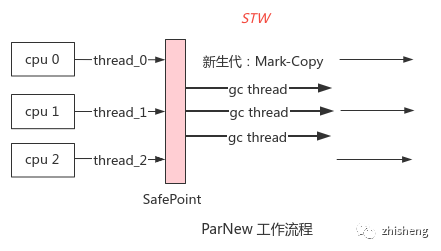
2. ParNew
原理:多线程并行版的 Serial 实现,能有效减少 STW 时长;线程数默认与核数相同,可配置
场景:JDK7 之前搭配老年代的 CMS 回收器使用
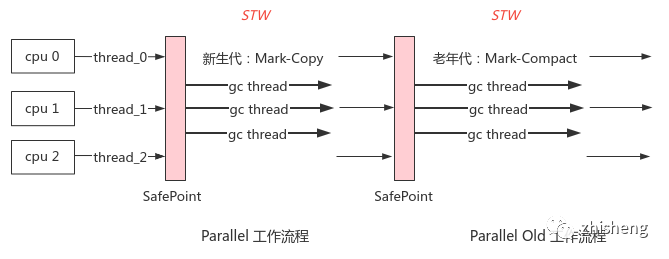
3. Parallel, Parallel Old
垃圾回收有两个通常不可兼得的目标
低延迟:STW 时长短,响应快;允许高频、短暂 GC,比如调小新生代空间,加快收集延迟(吞吐下降)
高吞吐量:用户线程耗时 /(用户线程耗时 + GC 线程耗时)高,GC 总时间低;允许低频、单次长时间 GC,(延迟增加)
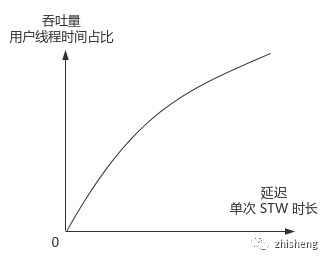
原理:与 ParNew 类似都是并行回收,主要增加了 3 个选项(倾向于提高吞吐量)
-XX:MaxGCPauseTime:控制最大延迟-XX:GCTimeRatio:控制吞吐(默认 99%)-XX:+UseAdaptiveSizePolicy:启用自适应策略,自动调整 Eden 与 2 个 Survivor 区的内存占比-XX:SurvivorRatio,老年代晋升阈值-XX:PretenureSizeThreshold
4. CMS
CMS:Concurrent Mark Sweep,即并发标记清除,主要有 4 个阶段
初始标记(initial mark):STW 快速收集 GC Roots
并发标记(concurrent mark):从 GC Roots 出发检测引用链,标记可回收对象;与用户线程并发执行,通过增量更新来避免误回收
重新标记(remark):STW 重新分析被增量更新所收集的 GC Roots
并发清除(concurrent sweep):并发清除可回收对象
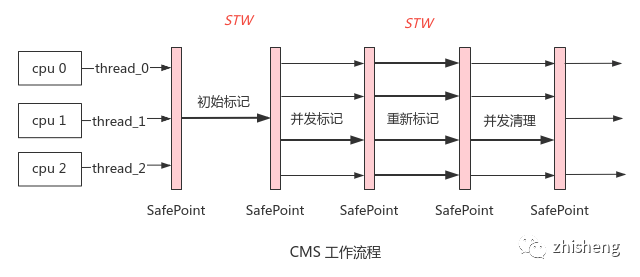
优点:两次 STW 时间相比并发标记耗时要短得多,相比前三种收集器,延迟大幅降低
缺点
CPU 敏感:若核数较少(< 4core),并发标记将占用大量 CPU 时间,会导致吞吐突降
无法处理浮动垃圾:
-XX:CMSInitiatingOccupancyFration(默认 92%)指定触发 CMS GC 的阈值;在并发标记、并发清理的同时,用户线程会产生浮动垃圾(引用可回收对象、产生新对象),若浮动垃圾占比超过-XX:CMSInitiatingOccupancyFration;若 GC 的同时产生过多的浮动垃圾,导致老年代内存不足,会出现 CMS 并发失败,退化为 Serial Old 执行 Full GC,会导致延迟突增无法避免内存碎片:
-XX:CMSFullGCsBeforeCompaction(默认 0)指定每次在 Full GC 前,先整理老年代的内存碎片
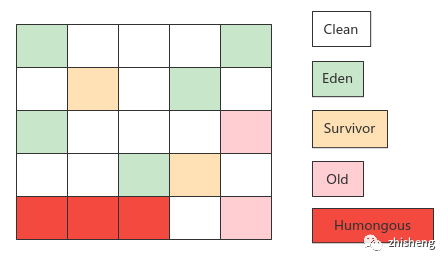
5. G1
特点:基于 region 内存布局实现局部回收;GC 延迟目标可配置;无内存碎片问题
| G1 | 之前回收器 | |
|---|---|---|
| 堆内存划分方式 | 多个等大的 region, 各 region 分代角色并不固定,按需在 Eden, Survivor, Old 间切换 | 固定大小、固定数量的分代区域 |
| 回收目标 | 回收价值高的 region 动态组成的回收集合 | 新生代、整个堆内存 |
跨代引用:各 region 除了用卡表标记各卡页是否为 dirty 之外,还用哈希表记录了各卡页正在被哪些 region 引用,通过这种“双向指针”机制,能直接找到 Old 区,避免了全量扫描(G1 自身内存开销大头)
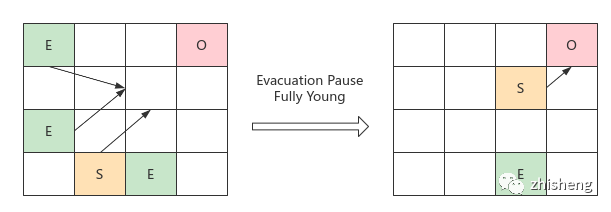
G1 GC 有 3 个阶段(参考其 GC 日志)
新生代 GC:Eden 区占比超阈值触发;标记存活对象并复制到 Survivor 区,其内可能有对象会晋升到 Old 区
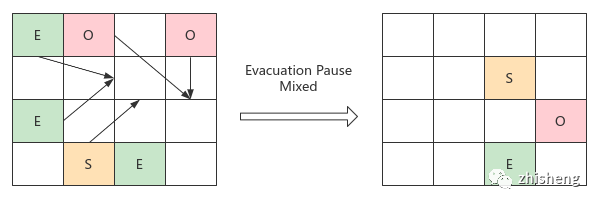
老年代 GC:Old 区占比达到阈值后触发,执行标记整理
初始标记:枚举 GC Roots,已在新生代 GC 时顺带完成
并发标记:并发执行可达性分析,使用 SATB 记录引用变更
重新标记:SATB 分析,避免误回收
筛选回收:将 region 按回收价值和时间成本筛选组成回收集,STW 将存活对象拷贝到空 regions 后清理旧 regions,完成回收
混合 GC
参数控制(文档:HotSpot GC Tuning Guide)
| 参数及默认值 | 描述 |
|---|---|
‐XX:+UseG1GC | JDK9 之前手动启用 G1 |
-XX:MaxGCPauseMillis=200 | 预期的最大 GC 停顿时间;不宜过小,避免每次回收内存少而导致频繁 GC |
-XX:ParallelGCThreads=N | STW 并行线程数,若可用核数 M < 8 则 N=1,否则默认 N=M*5/8 |
-XX:ConcGCThreads=N | 并发阶段并发线程数,默认是 ParallelGCThreads 的 1/4 |
-XX:InitiatingHeapOccupancyPercent=45 | 老年代 region 占比超过 45% 则触发老年代 GC |
-XX:G1HeapRegionSize=N | 单个 region 大小,1~32MB |
-XX:G1NewSizePercent=5, -XX:G1MaxNewSizePercent=60 | 新生代 region 最小占整堆的 5%,最大 60%,超出则触发新生代 GC |
-XX:G1HeapWastePercent=5 | 允许浪费的堆内存占比,可回收内存低于 5% 则不进行混合回收 |
-XX:G1MixedGCLiveThresholdPercent=85 | 老年代存活对象占比超 85%,回收价值低,暂不回收 |
-XX:G1MixedGCCountTarget=8 | 单次收集中混合回收次数 |
3.8 内存分配策略
使用 Serial 收集器 -XX:+UseG1GC 演示
1. 对象优先分配在 Eden 区
新对象在 Eden 区分配,空间不足则触发 Minor GC,存活对象拷贝到 To Survivor,若还是内存不足则通过分配担保机制转移到老年区,依旧不足才 OOM
|
2. 大对象直接进入老年区
对于 Serial, ParNew,可配置超过阈值 -XX:PretenureSizeThreshold 的大对象(连续内存),直接在老年代中分配,避免触发 minor gc,导致 Eden 和 Survivor 产生大量的内存复制操作
|
3. 长期存活的对象进入老年代
对象头中 4bit 的 age 字段存储了对象当前 GC 分代年龄,当超过阈值-XX:MaxTenuringThreshold(默认 15,也即 age 字段最大值)后,将晋升到老年代,可搭配-XX:+PrintTenuringDistribution观察分代分布
|
4. 分代年龄动态判定
-XX:MaxTenuringThreshold并非晋升的最低硬性门槛,当 Survivor 中同龄对象超 50% 后,大于等于该年龄的对象会被自动晋升,哪怕还没到阈值
5. 空间分配担保
老年代作为 To Survivor 区的担保区域,当 Eden + From Survivor 中存活对象的总大小超出 To Survivor 时,将尝试存入老年代。JDK6 之后,只要老年代的连续空间大于新生代对象的总大小,或之前晋升的平均大小,则只会进行 Minor GC,否则进行 Full GC
ch06. 类文件结构
Class 文件实现语言无关性,JVM 实现平台无关性,参考《Java 虚拟机规范》
一个 Class 文件描述了一个类或接口的明确定义,文件内容是一组以 8 字节为单位的二进制流,各数据项间没有分隔符,超过 8 字节的数据项按 Big-Endian 切分后存储。数据项分两种:
无符号数:描述基本类型;用
u1,u2,u4,u8分别表示1,2,4,8字节长度的无符号数;存储数字值、索引序号、UTF-8 编码值等表:由无符号数、其他表嵌套构成的复合类型;约定
_info后缀;存储字段类型、方法签名等
6.1 结构定义
1. 语法
参考文档:The class File Format
|
magic:魔数,简单识别
*.class文件,值固定为0xCAFEBABEminor_version, major_version:Class 文件的次、主版本号
constant_pool_count:常量池大小+1
constant_pool:常量池,索引从 1 开始,0 值被预留表示不引用任何常量池中的任何常量;常量分两类
字面量:如 UTF8 字符串、int、float、long、double 等数字常量
符号引用:类、接口的全限定名、字段名与描述符、方法类型与描述符等
现有常量共计 17 种,常量间除了都使用u1 tag前缀标识常量类型外,结构互不相同,常见的有:CONSTANT_Utf8_info:保存由 UTF8 编码的字符串CONSTANT_Utf8_info { u1 tag; // 值为 1 u2 length; // bytes 数组长度,u2 最大值 65535,即单个字符串字面量不超过 64KB u1 bytes[length]; // 长度不定的字节数组 }CONSTANT_Class_info:表示类或接口的符号引用CONSTANT_Class_info { u1 tag; // 值为 7 u2 name_index; // 指向全限定类名的 Utf8_info // 常量间存在层级组合关系 }CONSTANT_Fieldref_info, CONSTANT_Methodref_info, CONSTANT_NameAndType_info:成员变量、成员方法及其类型描述符CONSTANT_Fieldref_info { u1 tag; // 值为 9 u2 class_index; // 所属类 u2 name_and_type_index; // 字段的名称、类型描述符 } CONSTANT_Methodref_info { u1 tag; // 值为 10 u2 class_index; // 所属类 u2 name_and_type_index; // 方法的名称、签名描述符 } CONSTANT_NameAndType_info { u1 tag; // 值为 12 u2 name_index; // 字段或方法的名称 u2 descriptor_index; // 类型描述符 }如上只列举了其中 5 种常量的结构,可见常量间通过组合的方式,来描述层级关系
access_flags:类的访问标记,有 16bit,每个标记对应一个位,比如
ACC_PUBLIC对应0x0001,表示类被 public 修饰;其他 8 个标记参考Opcodes.ACC_XXXthis_class, super_class:指向本类、唯一父类的 Class_info 符号常量
interface_count, interfaces:描述此类实现的多个接口信息
fields_count, fields:字段表;描述类字段、成员变量的个数及详细信息
field_info { u2 access_flags; // 作用域、static,final,volatile 等访问标记 u2 name_index; // 字段名 u2 descriptor_index; // 类型描述符 u2 attributes_count; // 字段的属性表 attribute_info attributes[attributes_count]; }类型描述符简化描述了字段的数据类型、方法的参数列表及返回值,与 Java 中的类型对于关系如下:
基本类型:
Z:boolean, B:byte, C:char, S:short, I:int, F:float, D:double, J:longvoid 及引用类型:
V:void引用类型:
L:_,类名中的 . 替换为 /,添加 ; 分隔符,如 Object 类描述为Ljava/lang/Object;数组类型:每一维用一个前置
[表示
示例:boolean regionMatch(int, String, int, int)对应描述符为(ILjava/lang/String;II)Z
methods_count, methods:方法表;完整描述各成员方法的修饰符、参数列表、返回值等签名信息
method_info { u2 access_flags; // 访问标记 u2 name_index; // 方法名 u2 descriptor_index; // 方法描述符 u2 attributes_count; // 方法属性表 attribute_info attributes[attributes_count]; }字段表、方法表都可以带多个属性表,如常量字段表、方法字节码指令表、方法异常表等。属性模板:
attribute_info { u2 attribute_name_index; // 属性名 u4 attribute_length; // 属性数据长度 u1 info[attribute_length]; // 其他字段,各属性的结构不同 }属性有 20+ 种,此处只记录常见的三种
Code 属性:存储方法编译后的字节码指令
Code_attribute { u2 attribute_name_index; // 属性名,指向的 Utf8_info 值固定为 "Code" u4 attribute_length; // 剩下字节长度 u2 max_stack; // 操作数栈最大深度,对于此方法的栈帧中操作数栈的深度 u2 max_locals; // 以 slot 变量槽为单位的局部变量表大小,存储隐藏参数 this,实参列表,catch 参数,局部变量等 u4 code_length; // 字节码指令总长度 u1 code[code_length]; // JVM 指令集大小 200+,单个指令的编号用 u1 描述 u2 exception_table_length; // 异常表,描述方法内各指令区间产生的异常及其 handler 地址 { u2 start_pc; // catch_type 类型的异常,会在 [start_pc, end_pc) 指令范围内抛出 u2 end_pc; u2 handler_pc; // 若抛出此异常,则 goto 到 handler_pc 处执行 u2 catch_type; } exception_table[exception_table_length]; u2 attributes_count; // Code 属性自己的属性 attribute_info attributes[attributes_count]; }LineNumberTable 属性:记录 Java 源码行号与字节码行号的对应关系,用于抛异常时显示堆栈对应的行号等信息。可作为 Code 属性的子属性
LineNumberTable_attribute { u2 attribute_name_index; u4 attribute_length; u2 line_number_table_length; { u2 start_pc; // 字节码指令区间开始位置 u2 line_number; // 对应的源码行号 } line_number_table[line_number_table_length]; }LocalVariableTable 属性:记录 Java 方法中局部变量的变量名,与栈帧局部变量表中的变量的对应关系,用于保留各方法有意义的变量名称
LocalVariableTable_attribute { u2 attribute_name_index; u4 attribute_length; u2 local_variable_table_length; { u2 start_pc; // 局部变量生命周期开始的字节码偏移量 u2 length; // 向后生命周期覆盖的字节码长度 u2 name_index; // 变量名 u2 descriptor_index; // 类型描述符 u2 index; // 对应的局部变量表中的 slot 索引 } local_variable_table[local_variable_table_length]; }其他属性直接参考 JVM 文档
2. 示例
源码:com/cls/Structure.java
|
javac -g:lines com/cls/Structure.java 编译后,参考 javap 反编译得到的正确结果,od -x --endian=big Structure.class 得出 class 文件内容的十六进制表示,解读如下:
|
6.2 字节码指令
JVM 面向操作数栈(operand stack)设计了指令集,每个指令由 1 字节的操作码(opcode)表示,其后跟随 0 个或多个操作数(operand),指令集列表参考 Java bytecode instruction listings
大部分与数据类型相关的指令,其操作码符号都会带类型前缀,如 i 前缀表示操作 int,剩余对应关系为
b:byte, c:char, s:short, f:float, d:double, l:long, a:reference由于指令集大小有限(256个),故
boolean, byte, char, short会被转为int运算
字节码可大致分为六类:
加载和存储指令:将变量从局部变量表 slot 加载到操作数栈的栈顶,反向则是存储
// 将 slot 0,1,2,3,N 加载到栈顶,T 表示类型简记前缀,可取 i,l,f,d,a Tload_0, Tload_1, Tload_2, Tload_3, Tload n // 将栈顶数据写回指定的 slot Tstore_0, Tstore_1, Tstore_2, Tstore_3, Tstore n // 将不同范围的常量值加载到栈顶,由于 0~5 常量过于常用,有单独对应的指令,ldc 则加载普通常量 bipush, sipush, Tconst_[0,1,2,3,4,5], aconst_null, ldc运算指令
Tadd, Tsub, Tmul, Tdiv, Trem // 算术运算:加减乘除,取余 Tneg, Tor, Tand, Txor // 位运算:取反、或、与、异或 dcmpg, dcmpl, fcmpg, fcmpl, lcmp // 比较运算:后缀 g 即 greater, l 即 less than iinc // 局部自增运算,与 iload 搭配使用强制类型转换指令:窄化转换为 T 类型(长度为 N)时,会直接丢弃除了低 N 位外的其他位,可能会导致数据溢出、正负号不确定,浮点数转整型则会丢失精度
i2b // int -> byte i2c, i2s; l2i, f2i, d2i; d2l, f2l; d2f对象创建与访问指令:类实例、数组都是对象,存储结构不同,创建和访问指令有所区别
new // 创建类实例 newarray, annewarray, multianewarry // 创建基本类型数组、引用类型数组、多维引用类型数组 getfield, putfield; getstatic, putstatic // 读写类实例字段;读写类静态字段 Taload, Tastore; arraylength // 读写数组元素;计算数组长度 instanceof; checkcast // 校验对象是否为类实例;执行强制转换操作数栈管理指令
pop, pop2 // 弹出栈顶 1,2 元素 dup, dup2; swap // 复制栈顶 1,2 个元素并重新入栈;交换栈顶两个元素控制转移指令:判断条件成立,则跳转到指定的指令行(修改 PC 指向)
if_<icmpeq,icmpne;icmplt,icmple;icmpgt,icmpge;acmpe,acmpne> // 整型比较,引用相等性判断 if<eq,lt,le,gt,ge,null,nonnull> // 搭配其他类型的比较运算指令使用方法调用与返回指令
invokevirtual // 根据对象的实际类型进行分派,调用对应的方法(比如继承后方法重写) invokespecial // 调用特殊方法,如 <cint>()V, <init>()V 等初始化方法、私有方法、父类方法 invokestatic // 调用类的静态方法 invokeinterface // 调用接口方法(实现接口的类对象,但被声明为接口类型,调用方法) invokedynamic // TODO Treturn, return // 返回指定类型,返回 void异常处理指令:
athrow抛出异常,异常处理则由 exception_table 描述同步指令:synchronized 对象锁由
monitorenter, monitorexit搭配对象的 monitor 锁共同实现
ch07. 类加载
7.1 类加载过程

1. 加载
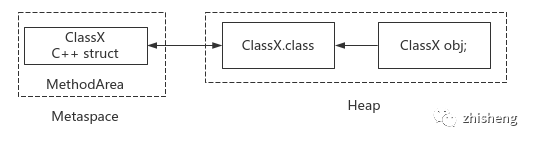
原理:委托 ClassLoader 读取 Class 二进制字节流,载入到方法区内存,并在堆内存中生成对应的java.lang.Class对象相互引用
2. 验证
校验字节流确保符合 Class 文件格式,执行语义分析确保符合 Java 语法,校验字节码指令合法性
3. 准备
在堆中分配类变量(static)内存并初始化为零值,主义还没到执行 putstatic 指令赋值的初始化阶段,但静态常量属性除外:
|
4. 解析
将常量池中的符号引用(Class_info, Fieldref_info, Methodref_info)替换为直接引用(内存地址)
5. 初始化
javac 会从上到下合并类中 static 变量赋值、static 语句块,生成类构造器<cinit>()V,在初始化阶段执行,此方法的执行由 JVM 保证线程安全;注意 JVM 规定有且仅有的,会立即触发对类初始化的六种 case
|
7.2 类加载器
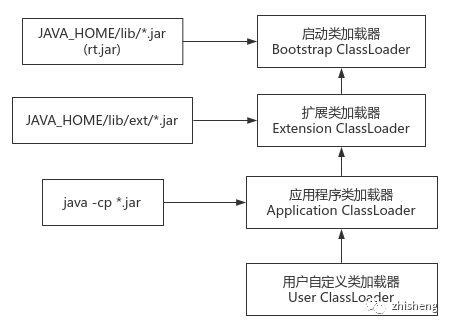
层级关系
双亲委派机制
原理:一个类加载器收到加载某个类的请求时,会先委派上层的父类加载器去加载,逐层向上,当父类加载器逐层向下反馈都无法加载此类后,该类加载器才会尝试自己加载;此模型保证了,诸如 rt.jar 中的
java.lang.Object类,不论在底层哪种类加载器中都一定是被 Bootstrap 类加载器加载, JVM 中仅此一份,保证了一致性实现
// java/lang/ClassLoader protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // 1. 先检查自己的加载器是否已加载此类 Class<?> c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { if (parent != null) { // 2. 还有上层则委派给上层去加载 c = parent.loadClass(name, false); } else { // 3. 如果没有上级,则委派给 Bootstrap 加载 c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // 类不存在 } if (c == null) { // 4. 到自己的 classpath 中查找类,用户自定义 ClassLoader 自定义了查找规则 long t1 = System.nanoTime(); c = findClass(name); } } if (resolve) { resolveClass(c); } return c; } }
ch08. 字节码执行引擎
8.1 运行时栈帧结构
|
对应运行时栈帧结构:
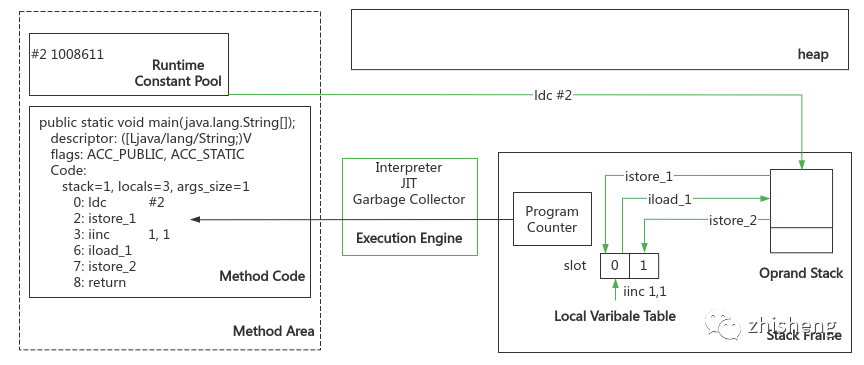
局部变量表:大小在编译期确定,用于存放实参和局部变量,以大小为 32 bit 的变量槽为最小单位
long, double 类型被切分为 2 个 slot 同时读写(单线程操作,无线程安全问题)
类对象调用方法时,slot 0 固定为当前对象的引用,即
this隐式实参变量槽有重用优化,当 pc 指令超出某个槽中的变量的作用域时,该槽会被其他变量重用
public static void main(String[] args) { { byte[] buf = new byte[10 * 1024 * 1024]; } System.gc(); // buf 还在局部变量表的 slot 0 中,作为 GC Root 无法被回收 // int v = 0; // 变量 v 重用 slot 0,gc 生效 // System.gc();
操作数栈:最大深度在编译期确定,与局部变量表配合入栈、执行指令、出栈来执行字节码指令
返回地址:遇到
return族指令则正常调用完成,发生异常但异常表中没有对应的 handler 则异常调用完成;正常退出到上层方法后,若有返回值则压入栈,并将程序计数器恢复到方法调用指令的下一条指令
8.2 方法调用
1. 虚方法、非虚方法
非虚方法:编译期可知(程序运行前就唯一确定)、且运行期不可变的方法,在类加载阶段就会将方法的符号引用解析为直接引用。有 5 种:
静态方法(与类唯一关联):
invokestatic调用私有方法(外部不可访问)、构造器方法、父类方法:
invokespecial调用final 方法(无法被继承):由
invokevirtual调用(历史原因)
|
虚方法:需在运行时动态确定直接引用的方法,由invokevirtual, invokeinterface调用
2. 静态分派、动态分派
背景:方法可被重载(参数类型不同,或数量不同)、可被重写(子类继承后覆盖)
分派:对象可声明为类、父类、实现的接口等类型,当对象作为实参或调用方法时,需根据其静态类型或实际类型,才能确定要调用的方法的版本,进而确定其直接引用。此过程即方法的分派
reference 变量的 2 种类型
静态类型:变量被声明的类型,不会改变,编译期可知
实际类型:变量指向的对象可被替换,运行时随时可能修改
静态分派
原理:方法重载时,依赖参数的静态类型,来确定要使用哪个重载版本的方法
特点:发生在编译阶段,由 javac 确定类型“匹配度最高的”重载版本,来作为
invokevirtual的参数
|
动态分派
原理:方法重写时,依赖 Receiver 对象的实际类型,来确定要使用哪个类版本的方法
特点:发生在运行时,依赖
invokevirtual指令来确定调用方法的版本,进而实现多态,解析流程为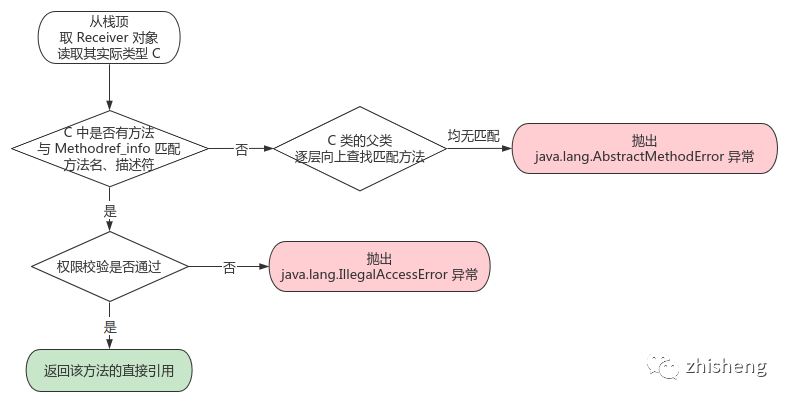
注:类的方法查找是高频操作,JVM 会在方法区中为类建一张虚方法表 vtable,以实现方法的快速查找
public class DynamicDispatch { static abstract class Human { protected abstract void f(); } static class Man extends Human { @Override protected void f() { System.out.println("Man f()"); } } static class Woman extends Human { @Override protected void f() { System.out.println("Woman f()"); } } public static void main(String[] args) { Human man = new Man(); // 虽然静态类型都是 Human Human woman = new Woman(); man.f(); // Man f() // invokevirtual #6 // Method com/ch08/DynamicDispatch$Human.f:()V woman.f(); // Woman f() // 虽然字节码指令的参数,都是静态类型方法的符号引用 man = new Woman(); man.f(); // Woman f() // 但 invokevirtual 会根据 Receiver 实际类型,在运行时解析到实际类的直接引用 } }注意,类的字段读写指令
getfield, putfield没有invokevirtual的动态分派机制,即子类的同名字段会直接覆盖父类的字段。示例:public class FieldHasNoPolymorphic { static class Father { public int money = 1; public Father() { money = 2; showMoney(); } public void showMoney() { System.out.println("Father, money = " + money); } } static class Son extends Father { public int money = 3; // 子类字段在类加载的准备阶段被赋零值 public Son() { // 子类构造器第一行默认隐藏调用 super() money = 4; showMoney(); } public void showMoney() { System.out.println("Son, money = " + money); } } public static void main(String[] args) { Father guy = new Son(); System.out.println("guy, money = " + guy.money); } } // Son, money = 0 // Father 类构造器执行,动态分派执行了 Son::showMoney() // Son, money = 4 // Son 类构造器中访问最新的、自己的 money 字段 // guy, money = 2 // 字段的读写没有动态分派,静态类型是谁,就访问谁的字段
3. 单分派、多分派
方法的 Receiver,与方法的参数,都是方法的宗量,根据一个宗量来选择目标方法称为单分派,需要多个宗量才能确定方法的叫多分派
静态分派机制会让编译器在编译阶段,对重载的多个方法,会选出参数匹配度最高的作为目标方法
动态分派机制在运行时,依赖 Receiver 实际类型,配合
invokevirtual定位唯一的实例方法作为目标方法
综上两点,Java 是静态多分派、动态单分派的语言
注明:第 10,11 章讲 Java 的前后端编译,学习了自动装箱等常见语法糖的字节码实现,其余部分待有空搭配龙书一起学;第 12,13 章内容与《Java Concurrency In Practice》等书重合度较高,此处不再赘述
总结
学习《深入理解 JVM 3ed》,初步掌握了 JVM 内存区域的划分模型、GC 算法理论及常见回收器原理、Class 文件结构中各数据项解释、类加载流程、方法的执行与分派等五大方面的知识,收获颇丰。不过大部分都是理论,若有机会还是要研究下 openjdk 的源码实现 :(
原文地址::https://yinzige.com/2020/03/08/understanding-jvm-3ed/
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统
关于数据中台的深度思考与总结(干干货)
日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。点个赞+在看,少个 bug ????最后
以上就是飞快水蜜桃最近收集整理的关于《深入理解 JVM 3ed》读书笔记的全部内容,更多相关《深入理解内容请搜索靠谱客的其他文章。








发表评论 取消回复