
本文来自大象声科高级算法工程师闫永杰在LiveVideoStackCon2019北京大会上的分享。 闫永杰介绍了深度学习在回声消除(AEC)中的应用。 正如我们所知,AEC是 在线音视频通话(VoIP)领域中一个非常棘手的问题,目前应用比较广泛的AEC方法主要还是基于传统信号处理的方法。 大象声科在成功将深度学习应用于人声和噪声分离的基础上,正在通过引入深度学习技术,解决回声消除问题。文 / 闫永杰 策划 / LiveVideoStack AEC问题定义
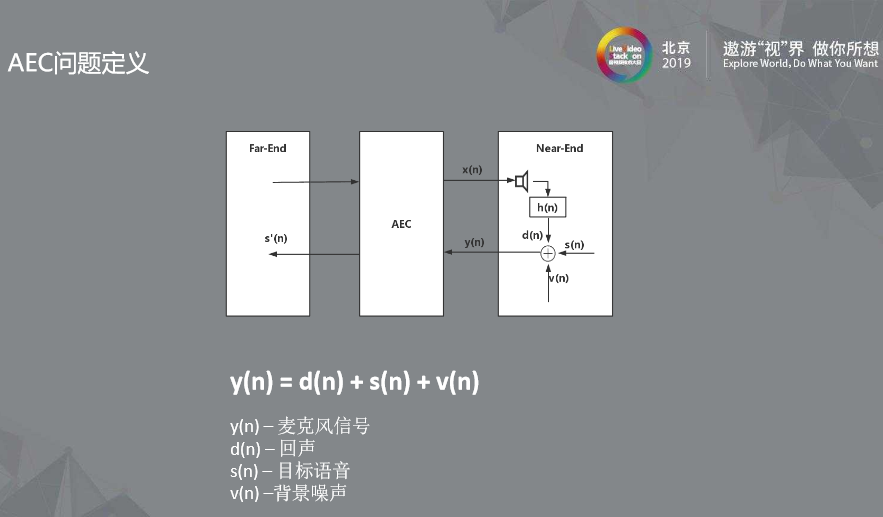 上图是个典型的AEC 系统,我们先看左框和右框。
我们可以想象为两个人通电话,从左框看到的远端信号(Far-End)是指对方传过来的信号x(n),而右框的近端信号(Near-End)指着本地麦克风收到的信号y(n)。
传统意义上,AEC 的问题目标在于去除回声的分量d(n), 如果一个 VOIP 通话系统后面还会有降噪算法将近端语音中的背景噪声v(n)去掉, 使得我们送给对方的信号是纯净的语音s’(n)。
当我们打电话时听到自己讲话的声音,其实是对方的手机AEC算法出现了问题. 在对方设备AEC算法没把你的声音消掉的情况下,就会听到自己的声音。
这里我们强调一点,传统AEC问题定义只针对回声分量去除,对噪音毫无影响。
简单介绍传统自适应算法原理
上图是个典型的AEC 系统,我们先看左框和右框。
我们可以想象为两个人通电话,从左框看到的远端信号(Far-End)是指对方传过来的信号x(n),而右框的近端信号(Near-End)指着本地麦克风收到的信号y(n)。
传统意义上,AEC 的问题目标在于去除回声的分量d(n), 如果一个 VOIP 通话系统后面还会有降噪算法将近端语音中的背景噪声v(n)去掉, 使得我们送给对方的信号是纯净的语音s’(n)。
当我们打电话时听到自己讲话的声音,其实是对方的手机AEC算法出现了问题. 在对方设备AEC算法没把你的声音消掉的情况下,就会听到自己的声音。
这里我们强调一点,传统AEC问题定义只针对回声分量去除,对噪音毫无影响。
简单介绍传统自适应算法原理
 第一,我们必须在近端没有讲话情况下做计算,来估计参考信号到回声的传输路径,也就是常说的回声路径。
回声路径的估计至关重要,如果回声路径估计不准确,后续步骤都会出问题。
第二,如果第一步我们得到了准确的回声路径h(n), 那么我们用得到的远端信号和h(n)进行卷积,就算得了估计的回声分量
第三, 麦克风收到的近端信号减去第二步中估计的回声分量,将会得到AEC 的结果
传统自适应算法存在的问题
第一,我们必须在近端没有讲话情况下做计算,来估计参考信号到回声的传输路径,也就是常说的回声路径。
回声路径的估计至关重要,如果回声路径估计不准确,后续步骤都会出问题。
第二,如果第一步我们得到了准确的回声路径h(n), 那么我们用得到的远端信号和h(n)进行卷积,就算得了估计的回声分量
第三, 麦克风收到的近端信号减去第二步中估计的回声分量,将会得到AEC 的结果
传统自适应算法存在的问题
 第一,算法要求在仅有远端信号段才能做回声路径的估计,因此双讲检测(Double-Talk)要求要非常准确。
如果这一点没有做好检测,会导致滤波器发散, 算得错误的h(n),进而导致目标语音过压、回声漏消等问题。
第二,传统的AEC不考虑背景噪声的,如果在实际场景背景噪声比较大,也会带来性能的下降。
第三, 估计的 回声路径h(n)是线性系统。
但现实场景是有扬声器带来的非线性问题。
如果扬声器非线性很严重,会给AEC带来很大的挑战。
从另一个视角看AEC
第一,算法要求在仅有远端信号段才能做回声路径的估计,因此双讲检测(Double-Talk)要求要非常准确。
如果这一点没有做好检测,会导致滤波器发散, 算得错误的h(n),进而导致目标语音过压、回声漏消等问题。
第二,传统的AEC不考虑背景噪声的,如果在实际场景背景噪声比较大,也会带来性能的下降。
第三, 估计的 回声路径h(n)是线性系统。
但现实场景是有扬声器带来的非线性问题。
如果扬声器非线性很严重,会给AEC带来很大的挑战。
从另一个视角看AEC
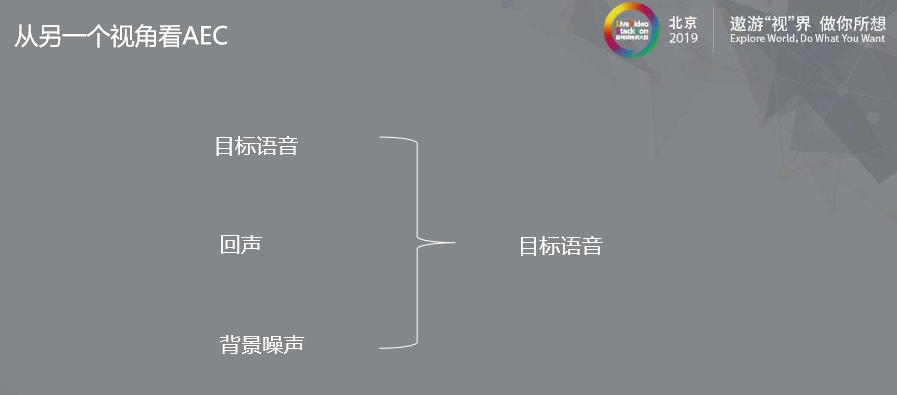 我们在此图中可以从另一个角度看AEC,麦克风分别收到三种信号- 目标语音,回声,背景噪声。
我们的目的是把回声与背景噪声去除(传统意义上,AEC仅仅是将回声分量去除)。
那么,我们就可以将AEC看成一个分离问题,这个任务就可以看成从近端混合信号中分离出目标语音。
计算听觉场景分析
我们在此图中可以从另一个角度看AEC,麦克风分别收到三种信号- 目标语音,回声,背景噪声。
我们的目的是把回声与背景噪声去除(传统意义上,AEC仅仅是将回声分量去除)。
那么,我们就可以将AEC看成一个分离问题,这个任务就可以看成从近端混合信号中分离出目标语音。
计算听觉场景分析
 讲到语音分离问题,就不得不提我们大象声科首席科学家汪德亮老师提出的理想二值掩膜(IBM) 理论。
这个理论将分离任务的目标设定为理想二值掩膜, 只存在两个取值, 0 或者1。
当目标信号大于非目标信号的时候,它会被设置为 1否则是0。
IBM
讲到语音分离问题,就不得不提我们大象声科首席科学家汪德亮老师提出的理想二值掩膜(IBM) 理论。
这个理论将分离任务的目标设定为理想二值掩膜, 只存在两个取值, 0 或者1。
当目标信号大于非目标信号的时候,它会被设置为 1否则是0。
IBM
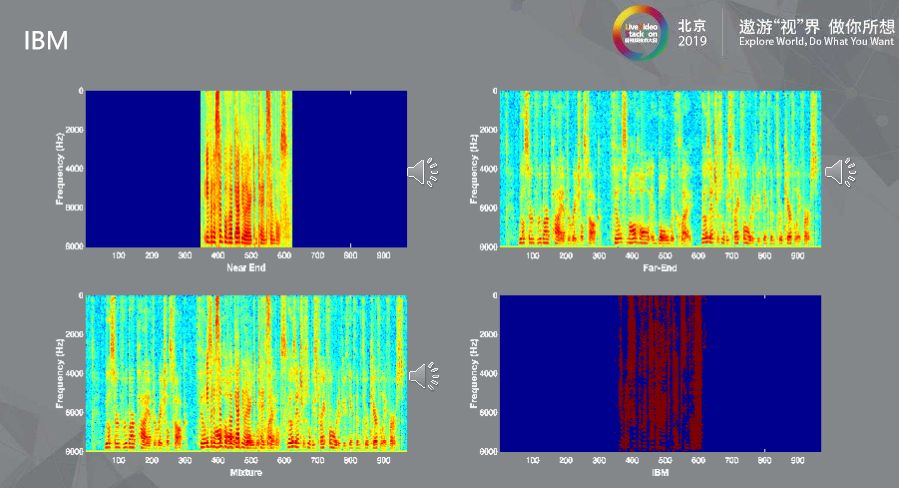 以上有四张图:
以上有四张图:
左上图表示的是近端信号(Near-End),前面和后面都是一段静音。
右上图表示的是远端信号 (Far-End) ,也就是对方传过来的声音,远端一直有人在说话,这路信号会通过扬声器播放出来。这种场景下,麦克风同时收到第一段近端讲话的声音以及第二段扬声器所播放出来的声音,听起来就像两个信号混合在一起,中间那段就是实实在在的Double-Talk。
左下图表示的就是麦克风收到的掺杂了近端信号和远端信号的混合语音。
如果左上图和左下图按照上述IBM公式计算,就会得到目标的Mask ,如右下图。不难想象,如果把右下图盖在左下图,会产生接近第一张图的效果。
 接下来我们讲下深度学习。
我们首先思考一个问题,学习的本质是什么呢?
事实上,学习的本质就是通过构建模型,来拟合一个函数映射,即我们给定模型一个输入以及对应的目标输出,通过模型自动优化调整,使得模型预测的输出不断地逼近目标输出。
当模型预测准确率达到比较高时,我们就可以使用这个模型来做预测了。
构建模型有很多方法,例如高斯混合模型、支持向量机、多层感知机以及深度神经网络(DNN),它们都能完成给定输入来预测一个输出的任务。
随着当前深度神经网络的快速推进,已经取得了卓越的性能提升,因此我们选择深度神经网络来建模。
对于AEC这个任务,前面我们讲到的IBM就是模型的目标y,而我们的输入有两个,一个是混合语音的幅度谱,另一个是远端参考信号的幅度谱,那么这样就建立好了函数映射。
训练数据的构建
接下来我们讲下深度学习。
我们首先思考一个问题,学习的本质是什么呢?
事实上,学习的本质就是通过构建模型,来拟合一个函数映射,即我们给定模型一个输入以及对应的目标输出,通过模型自动优化调整,使得模型预测的输出不断地逼近目标输出。
当模型预测准确率达到比较高时,我们就可以使用这个模型来做预测了。
构建模型有很多方法,例如高斯混合模型、支持向量机、多层感知机以及深度神经网络(DNN),它们都能完成给定输入来预测一个输出的任务。
随着当前深度神经网络的快速推进,已经取得了卓越的性能提升,因此我们选择深度神经网络来建模。
对于AEC这个任务,前面我们讲到的IBM就是模型的目标y,而我们的输入有两个,一个是混合语音的幅度谱,另一个是远端参考信号的幅度谱,那么这样就建立好了函数映射。
训练数据的构建
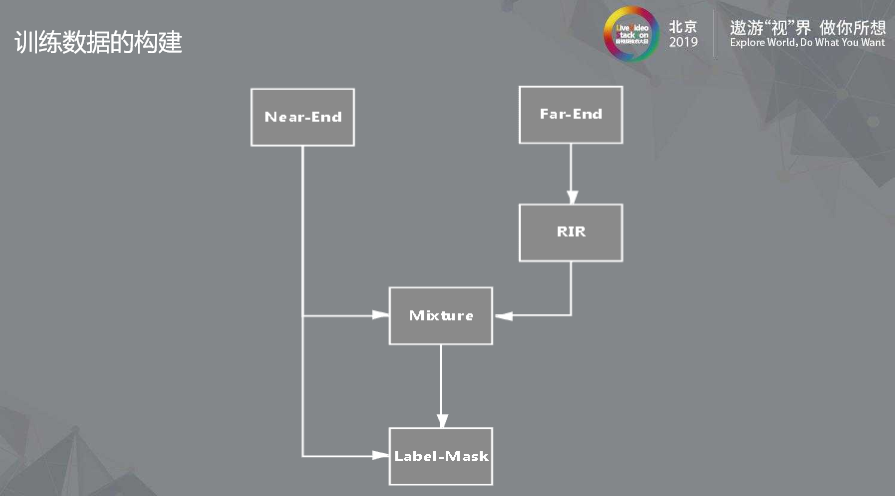 那么,如何生成实验所需的数据呢?
首先我们需要挑一句语音作为近端信号(Near-End),再挑一句为远端信号(Far-End)。
远端信号与房间的冲激响应(RIR)卷积后的结果作为回声信号。
然后,回声信号加上近端信号就得到实验中混合语音信号, 同时根据近端信号和混合语音可以求出我们所说的目标 IBM。
这样我们就有了完整的实验数据,输入:
混合语音,远端参考信号,目标:
近端目标语音与混合语音计算得到的IBM。
深度学习解决AEC问题
那么,如何生成实验所需的数据呢?
首先我们需要挑一句语音作为近端信号(Near-End),再挑一句为远端信号(Far-End)。
远端信号与房间的冲激响应(RIR)卷积后的结果作为回声信号。
然后,回声信号加上近端信号就得到实验中混合语音信号, 同时根据近端信号和混合语音可以求出我们所说的目标 IBM。
这样我们就有了完整的实验数据,输入:
混合语音,远端参考信号,目标:
近端目标语音与混合语音计算得到的IBM。
深度学习解决AEC问题
 下面,总结一下深度学习解决AEC问题:
下面,总结一下深度学习解决AEC问题:
选定训练目标--IBM,此处我们以IBM为例进行讲解,实际中也可以采用IRM(Idea Ratio Mask);
输入网络的特征--混合语音及参考信号STFT 后幅度谱;
训练工具现在都比较成熟了,Tensorflow、Pytorch 都非常好用;
数据驱动,将训练的数据不断送入网络,让它不断地调整参数,就会得到一个不错的效果。
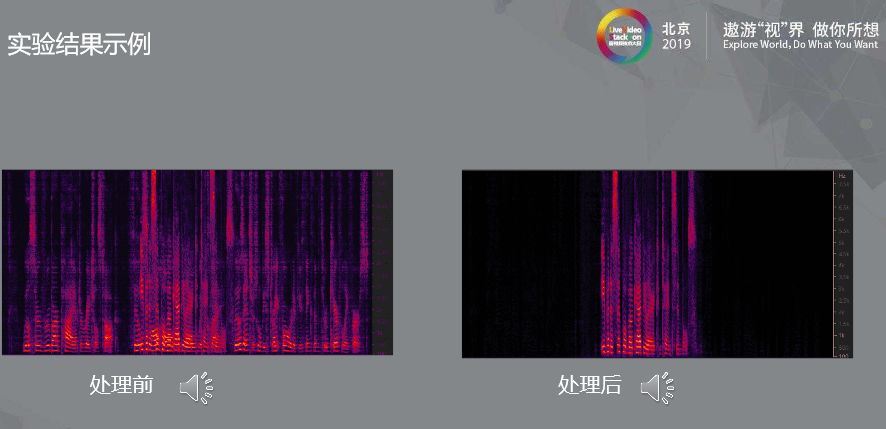 上图是模型收敛后的一组处理前后对比。
我们可以看到混合语音经过处理后,前后两段远端声音信号是完全去掉了,中间双讲部分也完整保留了目标语音,结果还是非常理想的。
上图是模型收敛后的一组处理前后对比。
我们可以看到混合语音经过处理后,前后两段远端声音信号是完全去掉了,中间双讲部分也完整保留了目标语音,结果还是非常理想的。
 上面实验在实验数据上已经取得了不错的结果,但如果处理实际采集的数据,效果就不尽如人意了,我们分析主要有以下几点原因:
上面实验在实验数据上已经取得了不错的结果,但如果处理实际采集的数据,效果就不尽如人意了,我们分析主要有以下几点原因:
现实场景中要考虑噪音的干扰;
非线性带来的不匹配;
现实中的房间冲激响应与实验室生成的存在差异。
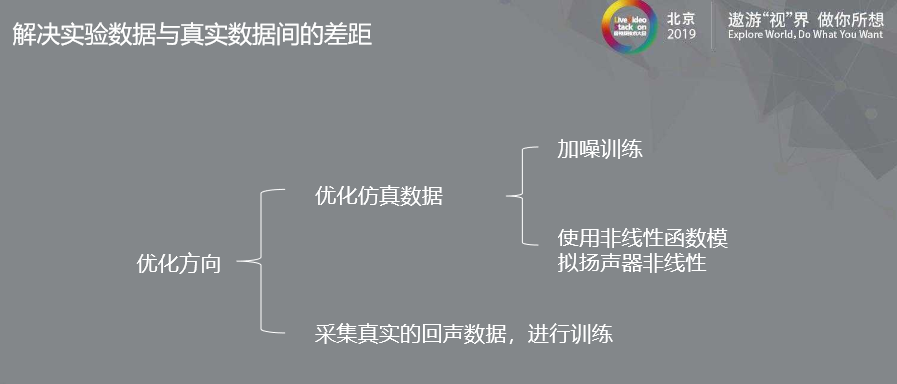 我们可以从两个方向来进行优化:
一方面,从优化仿真数据入手 :
首先,我们可以在训练数据中加入一些噪声干扰,来解决背景噪声带来的数据不匹配问题;
其次我们可以使用一些非线性函数,来模拟扬声器的非线性,以此减少实验数据与真实数据的差异;
另一方面,从采集真实回声数据入手:
我们可以采集真实的回声数据,进行训练。
我们编写了一个 APP, APP会读取 SD 卡内的音频并播放,同时APP将麦克风采集到的数据写入SD卡中。
这样,我们就得到了远端信号以及对应的回声分量。
利用这个方法,我们可以在不同的房间,不同位置,使用不同设备大量采集语料。
实验时,我们再选取近端信号,和采集到的回声分量进行混合,这样我们就能够得到接近真实的数据。
使用这样的数据,能够极大改善训练数据与真实数据之间分布不一致带来的性能下降。
我们可以从两个方向来进行优化:
一方面,从优化仿真数据入手 :
首先,我们可以在训练数据中加入一些噪声干扰,来解决背景噪声带来的数据不匹配问题;
其次我们可以使用一些非线性函数,来模拟扬声器的非线性,以此减少实验数据与真实数据的差异;
另一方面,从采集真实回声数据入手:
我们可以采集真实的回声数据,进行训练。
我们编写了一个 APP, APP会读取 SD 卡内的音频并播放,同时APP将麦克风采集到的数据写入SD卡中。
这样,我们就得到了远端信号以及对应的回声分量。
利用这个方法,我们可以在不同的房间,不同位置,使用不同设备大量采集语料。
实验时,我们再选取近端信号,和采集到的回声分量进行混合,这样我们就能够得到接近真实的数据。
使用这样的数据,能够极大改善训练数据与真实数据之间分布不一致带来的性能下降。
 讲到这里,我们总结下深度学习方法相比传统方法解决回声消除问题的优势:
讲到这里,我们总结下深度学习方法相比传统方法解决回声消除问题的优势:
无需考虑双讲。Double-Talk 是神经网络自己去学习的,因为我们的目标里面隐含Double-Talk 的信息。由于无需检测双讲,避免了传统方法双讲检测不准确时回声消除异常的问题。
深度学习本来就具有非线性拟合能力,能够更好地覆盖AEC 系统中非线性因素。
无需复杂的调参过程。这一点是我们非常看中的优点,可以极大地提高工程效率。

我们目前所用的方法仅恢复了目标语音的幅度,并没有恢复它的相位,合成时使用混合语音的相位进行合成的。这种方法在高信回比下没什么问题,但在低信回比下听感就不太好了;
在低信回比条件下,Masking方式恢复幅度的能力也有限;
即使我们做了大量弭平训练数据与真实数据的工作,但还是会存在分布差异时模型能力下降的问题。
 目前我们能看到可能解决上述问题的思路主要有:
目前我们能看到可能解决上述问题的思路主要有:
同时预测目标语音的幅度谱和相位;
直接在时域上进行预测。
 AEC 的应用领域包括智能家居,云通讯,智能安防,智能车载,耳机,机器人,手机等等。
AEC 的应用领域包括智能家居,云通讯,智能安防,智能车载,耳机,机器人,手机等等。
 我们在手机领域已有一定的落地,手机手持模式下回声回声分量比较小,比较适合目前技术的落地,已经有多款搭载大象声科算法的手机商业落地了。
Q & A
我们在手机领域已有一定的落地,手机手持模式下回声回声分量比较小,比较适合目前技术的落地,已经有多款搭载大象声科算法的手机商业落地了。
Q & A
如何合成含噪声的数据?
一般会采用什么样的网络结构呢?
训练时单讲和双讲数据的比例大概是什么样呢?
LiveVideoStack 秋季招聘
LiveVideoStack正在招募编辑/记者/运营,与全球顶尖多媒体技术专家和LiveVideoStack年轻的伙伴一起,推动多媒体技术生态发展。同时,也欢迎你利用业余时间、远程参与内容生产。了解岗位信息请在BOSS直聘上搜索“LiveVideoStack”,或通过微信“Tony_Bao_”与主编包研交流。

最后
以上就是伶俐黑猫最近收集整理的关于线性系统深度学习_深度学习在AEC中的应用探索的全部内容,更多相关线性系统深度学习_深度学习在AEC中内容请搜索靠谱客的其他文章。








发表评论 取消回复