
作者:蚂蚁
来源:数据中台研习社
长期以来,由于以hadoop为核心的生态系统霸占了大数据的各个角度,以至于我们以为大数据就是hadoop。诚然,自hadoop诞生以来,hive+hbase掀起第一个高潮,而后Spark和Flink更是火爆到不行,声浪一阵盖过一阵。尽管hadoop在高并发、海量数据处理等方面有着无可比拟的优势,但是在OLAP场景下的数据分析方面始终不如人意。
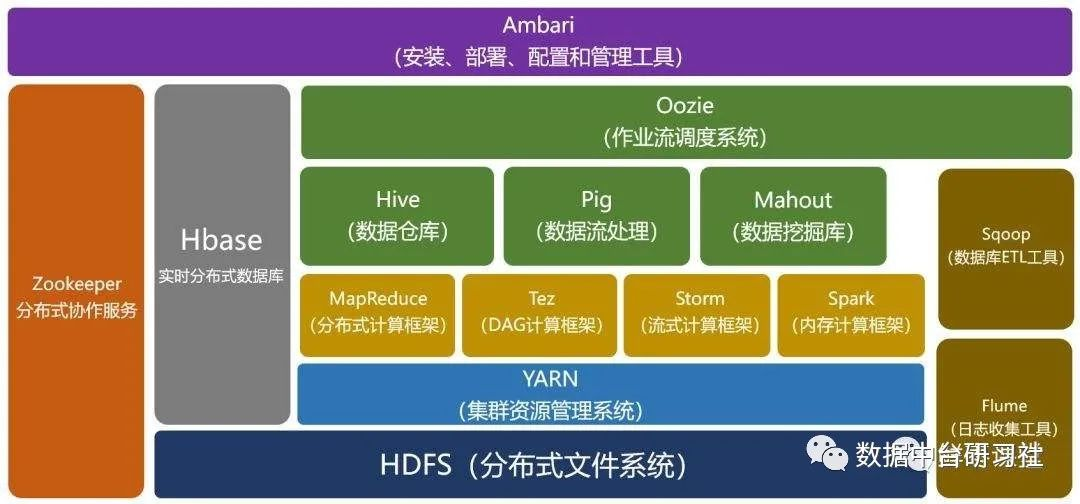
在hadoop生态体系中,可以用作OLAP分析的引擎主要有以下几个:
1)Hive
Hive 最早由 Facebook 开源贡献也是早年应用最广泛的大数据 SQL 引擎,和 MapReduce 一样,Hive 在业界的标签就是慢而稳定。其无私地提供了很多公共组件为其他引擎所使用,堪称业界良心,比如元数据服务 Hive Metastore、查询优化器 Calcite、列式存储 ORC 等。
近年来,Hive 发展很快,例如查询优化方面采用了 CBO,在执行引擎方面用 Tez 来替换 MapReduce,通过 LLAP 来 cache 查询结果做优化,以及 ORC 存储不断演进。不过相比较而言,这些新技术从市场应用来说还不算成熟稳定,Hive 仍然被大量用户定义为可靠的 ETL 工具而非即时查询产品。
Hive的优势是完善的SQL支持,极低的学习成本,自定义数据格式,极高的扩展性可轻松扩展到几千个节点等等。但是Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据库,因此访问延迟较高。
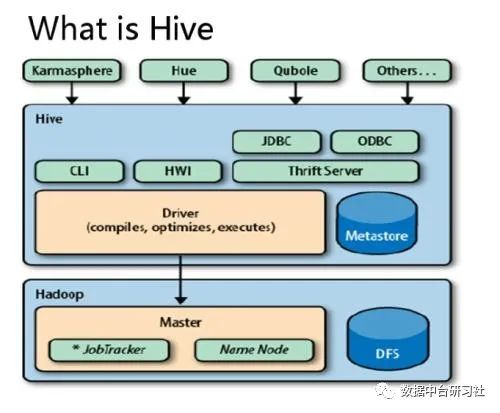
2)HAWQ
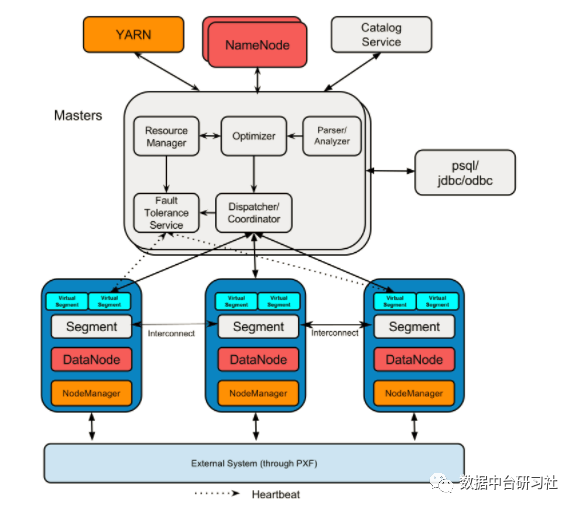
Hawq是一个Hadoop原生大规模并行SQL分析引擎,Hawq采用 MPP 架构,改进了针对 Hadoop 的基于成本的查询优化器。除了能高效处理本身的内部数据,还可通过 PXF 访问 HDFS、Hive、HBase、JSON 等外部数据源。HAWQ全面兼容 SQL 标准,能编写 SQL UDF,还可用 SQL 完成简单的数据挖掘和机器学习。无论是功能特性,还是性能表现,HAWQ 都比较适用于构建 Hadoop 分析型数据仓库应用。
网络上有人对Hawq与Hive查询性能进行了对比测试,总体来看,使用Hawq内部表比Hive快的多(4-50倍)。Hawq是基于GreenPlum实现,缺点是安装配置复杂,技术实现也比较复杂,因此社区活跃度不高。
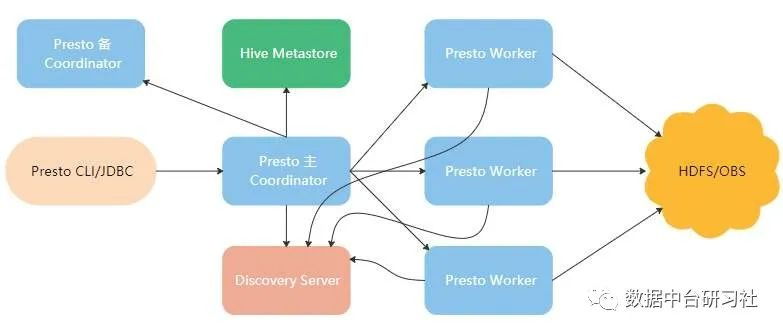
3)Presto
Presto是Facebook推出的基于内存的并行计算的分布式SQL交互式查询引擎 多个节点管道式执行。支持任意数据源 数据规模GB~PB 是一种Massively parallel processing(mpp)(大规模并行处理)模型
数据规模PB 不是把PB数据放到内存,只是在计算中拿出一部分放在内存、计算、抛出、再拿。Presto不仅支持hive,还支持各种jdbc数据源,可以作为一个跨平台的查询计算引擎。
Presto 在前几年应用比较广泛,在Airbnb和JD等企业有过应用,京东还专门为此写了一本书。但是近几年逐步淡出了。这款内存型 MPP 引擎的特点就是处理小规模数据会非常快,数据量大的时候会比较吃力。
由于Presto是基于内存的,而hive是在磁盘上读写的,因此presto比hive快很多,但是由于是基于内存的计算当多张大表关联操作时易引起内存溢出错误。不适合多个大表的join操作。
4)Spark SQL
SparkSQL 这两年发展迅猛,尤其在 Spark 进入 2.x 时代,发展更是突飞猛进。其优秀的 SQL 兼容性(唯一全部 pass TPC-DS 全部 99 个 query 的开源大数据 SQL),卓越的性能、庞大且活跃的社区、完善的生态(机器学习、图计算、流处理等)都让 SparkSQL 从这几个开源产品中脱颖而出,在国内外市场得到了非常广泛的应用。
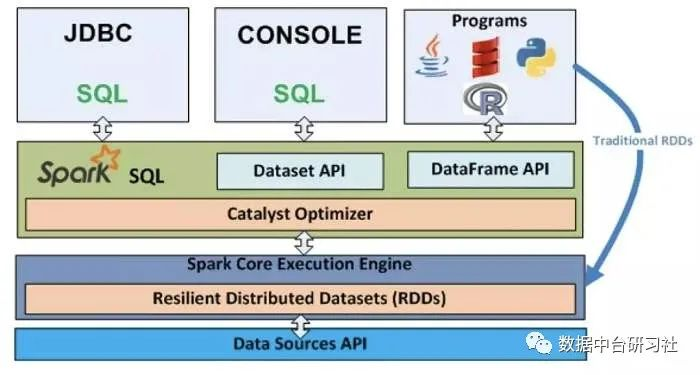
Spark SQL对熟悉Spark的同学来说,很容易理解并上手使用:
相比于Spark RDD API,Spark SQL包含了对结构化数据和在其上运算的更多信息,Spark SQL使用这些信息进行了额外的优化,使对结构化数据的操作更加高效和方便;
SQL提供了一个通用的方式来访问各式各样的数据源,包括Hive, Avro, Parquet, ORC, JSON, and JDBC;
Hive兼容性极好。
5)Kylin
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。
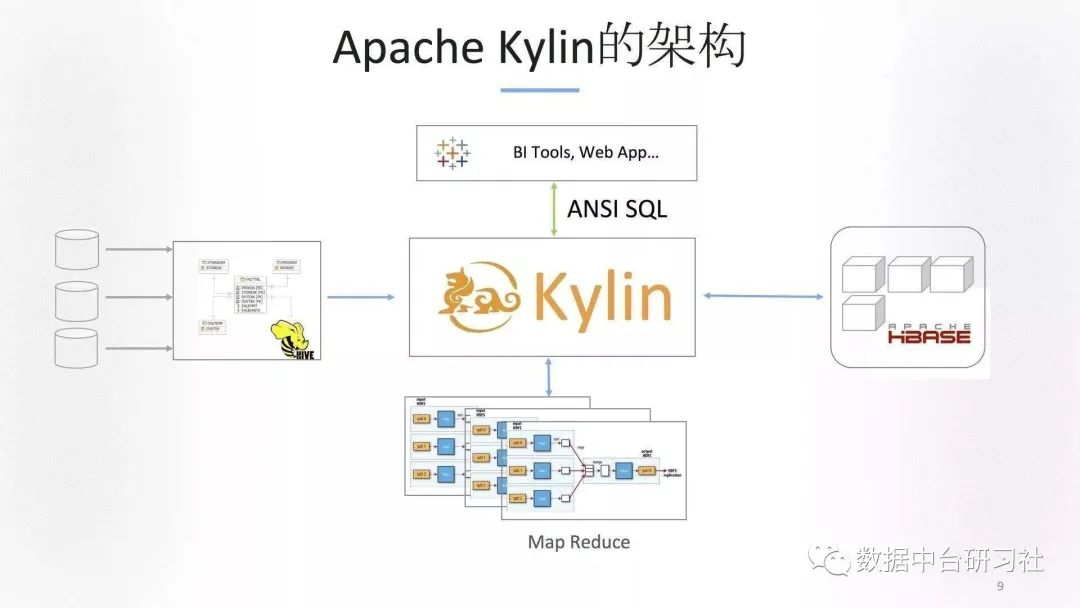
Kylin自身就是一个MOLAP系统,多维立方体(MOLAP Cube)的设计使得用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体进行数据的预聚合。 简单来说,Kylin中数据立方的思想就是以空间换时间,通过定义一系列的纬度,对每个纬度的组合进行预先计算并存储。有N个纬度,就会有2的N次种组合。所以最好控制好纬度的数量,因为存储量会随着纬度的增加爆炸式的增长,产生灾难性后果。原来的kylin是把数据存储在Hbase里面,近些年做了一些改进,尝试用文件存储。
6)Impala
Impala也是一个SQL on Hadoop的查询工具,底层采用MPP技术,支持快速交互式SQL查询。与Hive共享元数据存储。Impalad是核心进程,负责接收查询请求并向多个数据节点分发任务。statestored进程负责监控所有Impalad进程,并向集群中的节点报告各个Impalad进程的状态。catalogd进程负责广播通知元数据的最新信息。
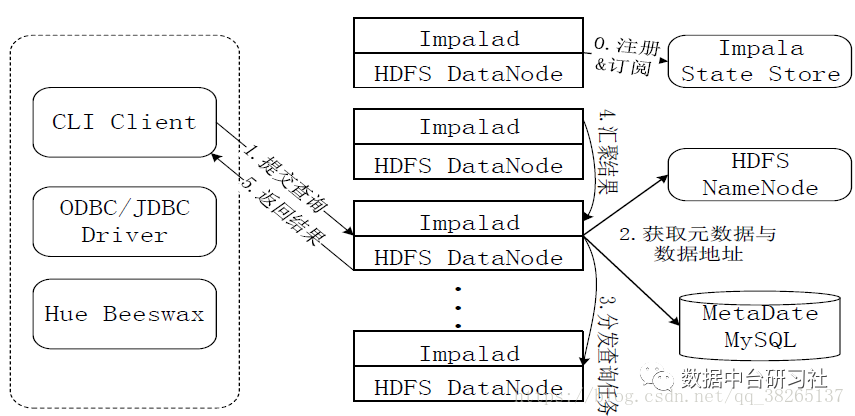
Impala 的性能也非常优异,不过其发展路线相对封闭,社区生态进展比较缓慢,SQL 兼容性也比较差,用户群体相对较小。
Impala的劣势也同样明显:
Impala不提供任何对序列化和反序列化的支持;
Impala只能读取文本文件,而不能读取自定义二进制文件;
每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。这个缺点会导致正在执行的查询sql遇到刷新会挂起,查询不动。
以上开源组件,虽然在某些方面的性能比较卓越,但是总体上欠缺稳定性,使用也不够灵活,优点明细,确定也很明显。在这里我针对OLAP的一些数据库选型要求简单明了的总结一下各组件的评分情况。如有不妥,还请大神指正。
| 查询速度 | SQL支持 | BI集成支持 | 市场活跃度 | |
| Hive | ★ | ★★★★ | ★★★★ | ★★★★★ |
| Presto | ★★★ | ★★★ | ★★ | ★★★ |
| HAWQ | ★★★ | ★★★ | ★ | ★ |
| Spark SQL | ★★★ | ★★★★ | ★★ | ★★★★ |
| Kylin | ★★★★ | ★★★ | ★★★ | ★★★ |
| Impala | ★★★★ | ★★★ | ★★★ | ★★★ |
注:以最高五颗星作为满分要求。
由于以上插件的种种优劣势,我特此推荐以下三个数据库作为大家作为数据中台的一个可选项。其中任何一款都比hadoop平台好用。
1)Greenplum数据库
在此,我向大家非常隆重的推荐Greenplum数据库。Greenplum数据库是基于PostgreSQL开源并行数据库,基于MPP架构的最成熟的应用产品。
Greenplum完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展;从应用编程接口上讲,它支持ODBC和JDBC。完善的标准支持使得系统开发、维护和管理都非常方便。Greenplum支持分布式事务,支持ACID。保证数据的强一致性。作为分布式数据库,拥有良好的线性扩展能力。Greenplum有完善的生态系统,可以与很多企业级产品集成,譬如SAS,Cognos,Informatic,Tableau等;也可以很多种开源软件集成,譬如Pentaho,Kettle等。
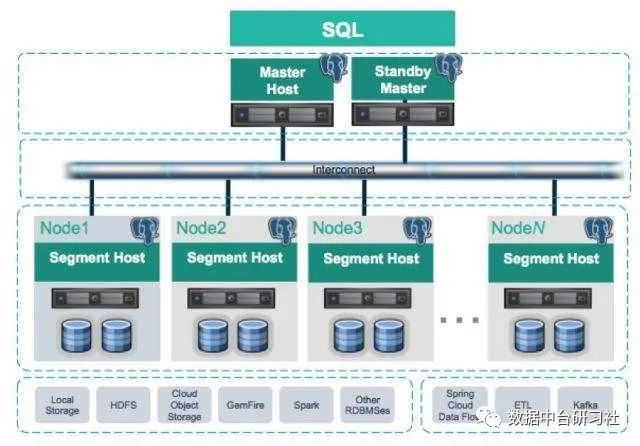
除此以外,Greenplum还有非常丰富的ETL插件功能,例如GPLoad高速并行加载机制、PXF外表,支持Python、C等各种编程语言扩展功能,支持存储过程加工数据(Greenplum里面统称函数),支持MADLIB机器学习插件库。由于Greenplum功能特别强大,所以做OLAP开发也特别简单。另一方面Greenplum的OLTP性能也还可以,支持通过JDBC链接实时更新数据。
同时Greenplum在存储和处理大数据量查询是也毫不逊色。在合理的集群配置和恰当的性能优化场景下,可以实现复杂应用场景5s以下的查询响应。
2)Clickhouse
Clickhouse 由俄罗斯 yandex 公司开发。专为在线数据分析而设计。Yandex是俄罗斯搜索引擎公司。官方提供的文档表名,ClickHouse 日处理记录数"十亿级",在腾讯还有千亿级数据量的应用。
Clickhouse 是OLAP界的一匹黑马,最近几年上升势头特别猛。这个开源的列式存储数据库的跑分要超过很多流行的商业MPP数据库软件,例如Vertica。因此Clickhouse 特别适合超大数量的实时快速查询,在各互联网公司的使用场景下,可以优化到亿级数据5s以内的响应速度,堪称是性能怪兽。

ClickHouse集成了各自优秀的数据库引擎,支持分布式并行计算,把单机性能压榨到极限;支持列式存储数据库和数据压缩;支持关系型SQL语句;支持高可用和PB级数据查询。
当然,ClickHouse也有一些劣势,例如缺少高频率,低延迟的修改或删除已存在数据的能力;仅能用于批量删除或修改数据;没有完整的事务支持;不支持二级索引;有限的SQL支持,join实现与众不同。
所以ClickHouse适合配合hive使用,用作hive批处理结果的查询引擎。在“快”的巨大优势勉强,ClickHouse是超大数量实时查询的首选。
3) HANA
HANA是SAP公司发布的一款内存数据库。根据SAP公司的定义,HANA是一个软硬件结合体,提供高性能的数据查询功能,用户可以直接对大量实时业务数据进行查询和分析。用户拿到的是一个装有预配置软件的设备。至于HANA的云服务,只是对用户而言可以在不购买相关硬件的情况下享受HANA的高性能,而HANA云服务的背后还是需要更高性能的硬件支撑的。

HANA的优势在于快,亿级数据关联都是毫秒级响应结果。HANA也是一款关系型数据库,支持单机部署,也支持多节点部署。HANA也支持云平台部署。
HANA缺点是贵,并且不开源。但是凭良心说,HANA确实是一款非常优秀的数据库,在当前数据比硬件更值钱的趋势下,有些不差钱的企业可以考虑这个方案。
最后,针对以上三款关系型数据库,我也在这里打一下分,用以对比。
| 查询速度 | SQL支持 | BI集成支持度 | 市场活跃度 | |
| Greenplum | ★★★★ | ★★★★★ | ★★★★★ | ★★★★ |
| ClickHouse | ★★★★★ | ★★★★ | ★★ | ★★★★ |
| HANA | ★★★★★ | ★★★★★ | ★★★★★ | ★★★ |
最后统计一下得分,hadoop生态圈,Hive得分14分,Presto11分,HAWQ 8分,Spark SQL 13分,Kylin13分,Impala 13分。非Hadoop生态圈,Greenplum得分18分,ClickHouse15分,HANA18分。
总结一下,除了上述三款关系型数据库以外,大数据平台里面Impala+Kudu的方案在小米有过应用,应该也是可以在一定业务场景慢满足查询和插入数据的均衡;另外,在关系型数据库领域,PingCAP 公司的TiDB、腾讯开源的TBase、阿里巴巴的OceanDB、华为的GaussDB、中兴的GoldenDB都可以引入到OLAP场景中,实现数据插入更新和批量数据分析的均衡,从而更好的满足数据中台的快速查询和实时数据更新需求。
数据中台的目的是让数据持续产生价值,因此,技术不是重点,简单好用才是我们应该把握的关键。不忘初心,才能走得更远。最后再次推荐中小企业搭建数据中台采用Greenplum,Hadoop水太深慎入。

◆ ◆ ◆ ◆ ◆
麟哥新书已经在京东上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前京东正在举行100-50活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:

点击下方小程序即可进入购买页面:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:

猜你喜欢
● 麟哥拼了!!!亲自出镜推荐自己新书《数据分析师求职面试指南》
● 厉害了!麟哥新书登顶京东销量排行榜!
● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!
● 你相信逛B站也能学编程吗

点击阅读原文,即可参与京东100-50购书活动
最后
以上就是儒雅外套最近收集整理的关于大数据≠hadoop,数据中台选型你应该看到这些分布式数据库的全部内容,更多相关大数据≠hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复