下面是听了林海峰老师的视频总结与大家分享~
首先为大家补充一些关于多表查询的知识点
只要是多表查询,就有两种思路
1、联表
2、子查询
为大家举一个1例子:查询平均年龄在25岁以上的部门名称
ps:这里不为大家展示结果和建表过程,只演示sql代码思路
1、联表操作
1、先拿到部门和员工表拼接之后的结果
2、分析语义,得出需要进行分组
select dep.name from emp inner join dep
on emp.dep_id=dep.id
group by dep.name
having avg(age)>25;2、子查询
1、将一个查询语句的结果当作另一个查询语句的条件去使用
ps:表的查询结果可以作为其它表的查询条件,也可以通过起别名的方式把它作为一张虚拟表跟其他表关联
select name from dep where id in
(select dep_id from emp group by dep_id
having avg(age)>25);关键字exists(了解)
只返回布尔值 True False
返回True的时候外层查询语句执行,返回False的时候外层查询语句不执行
例子:判断dep表中是否存在id>3,若存在则返回emp的所有数据,否则不返回任何一个结果
select * from emp where exists
(select id from dep where id>3);一、视图
1、什么是视图?
视图就是通过查询得到一张虚拟表,然后保存下来,下次可以直接使用
视图也是表
2、为什么用视图?
如果要频繁的操作一张虚拟表(拼表组成),你就可以制作成视图,后续直接操作
3、如何创建视图
create view 视图名 as 虚拟表的查询sql语句
具体实例操作(这里我是在navicat上操作 演示):
创建视图book2borrow_books 内容是 books表和borrow_books的拼接内容
CREATE VIEW books2borrow_books as SELECT books.* from books INNER JOIN borrow_books on books.id=borrow_books.book_id;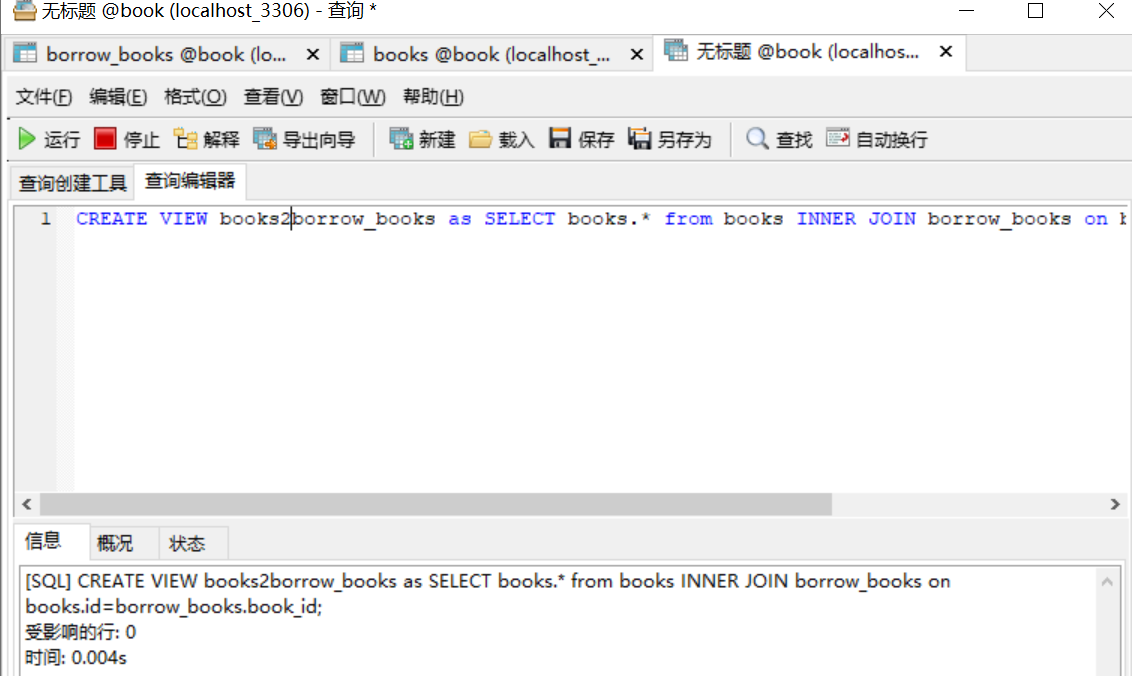
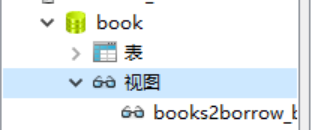
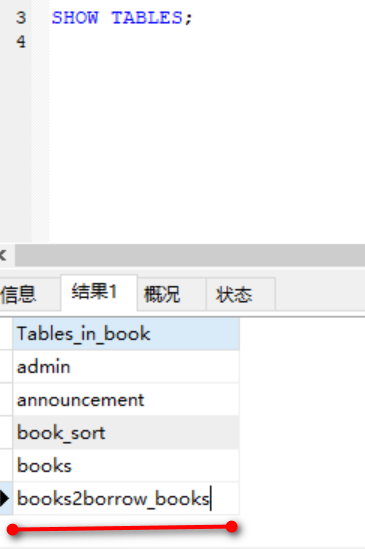
会发现多了一张名为books2borrow_books的表,说明视图也是表
注意:1、创建视图在硬盘上只有表结构,没有表数据(数据还是来自于之前的表)
2、视图一般只用来查询,里面的数据不要修改,可能会影响到真正的表(修改会报错)
3、当你创建了很多视图后,会造成表的不好维护
二、触发器
在满足对表数据进行增删改的情况下,自动触发的功能
使用触发器可以帮助我们实现监控、日志等等......
触发器可以在六种情况下自动触发 增前/增后 删前/删后 改前/改后
基本语法结构:
create trigger 触发器名字 before/after insert/update/delete on 表的名字
for each row
begin
sql语句
end
针对触发器的名字 我们需要做到见名知意
针对增:
1、增前
create trigger tri_before_insert_t1 before insert on t1
for each row
begin
sql语句
end
2、增后
create trigger tri_after_insert_t1 after insert on t1
for each row
begin
sql语句
end
删除与修改与上述增的书写格式一致
ps:修改MYSQL默认的语句结束符 只作用于当前窗口
delimiter $$ 将默认的结束符由;改为$$
delimiter ;重新改回;为结束符
案例:
提前准备了一些表:
create table cmd(
id int primary key auto_increment,
user char(32),
priv char(10),
cmd char(64),
sub_time datetime,#提交时间
success enum('yes','no')# 0表示执行失败
);
create table errlog(
id int primary key auto_increment,
err_cmd char(64),
err_time datetime,
);
小案例:当cmd表中的记录success字段是no那么就触发触发器的执行去errlog表中插入数据
NEW指代的就是一条条数据对象
delimiter $$
create trigger tri_after_insert_cmd after insert on cmd
for each row
begin
if New.success='no'then
insert into errlog(err_cmd,err_time) values(NEW.cmd,NEW.sub_time);
end if;
end $$
delimiter ;
朝cmd表插入数据
INSERT INTO cmd(
USER,
PRIV,
cmd,
sub_time,
success
)
VALUES('jason','0755','ls -l /etc',NOW(),'yes'),
('jason','0755','cat /etc/password',NOW(),'no'),
('jason','0755','useradd xxxx',NOW(),'no'),
('jason','0755','ps aux',NOW(),'yes');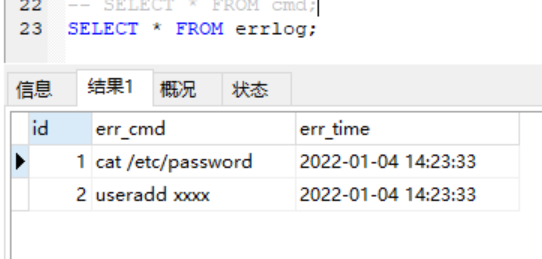
删除触发器:
drop trigger tri_after_insert_cmd
三、事务
1、什么是事务?
开启一个事务可以包含多条sql语句,这些sql语句要么同时成功,要么一个都别想成功
这个特定称为事务的原子性
2、事务的作用:
保证了对数据操作的安全性
3、事务的四大特性:
简称为ACID
A:原子性
一个事务是一个不可分割的单位,事务中包含的诸多操作,要么同时成功,要么同时失败
C:一致性
事务必须是使数据库从一个一致性的状态变到另一个一致性的状态,一致性跟原子性密切相关
I:隔离性
一个事物的执行不能被其它事务干扰,即一个事务内部的操作即使用到的数据对并发的其它事务是隔离的,并发执行的事务之间是互相不干扰的
D:持久性
也叫永久性,一个事物一旦提交成功执行成功,那么它对数据库中数据的修改应该是永久的,接下来的其它操作或者故障不应该对其有任何的影响
如何使用事务:
1、开启事务
start transaction;
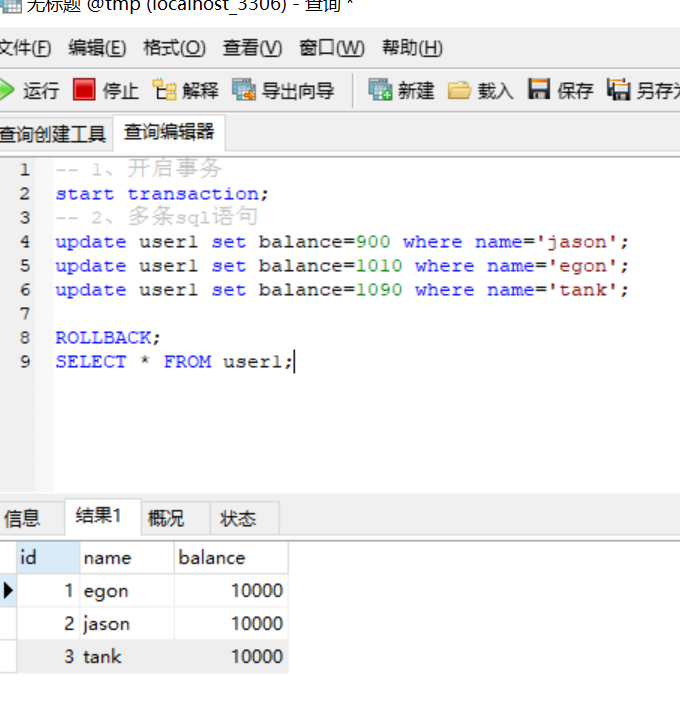
2、回滚操作(回到事务执行之前的状态)
rollback;
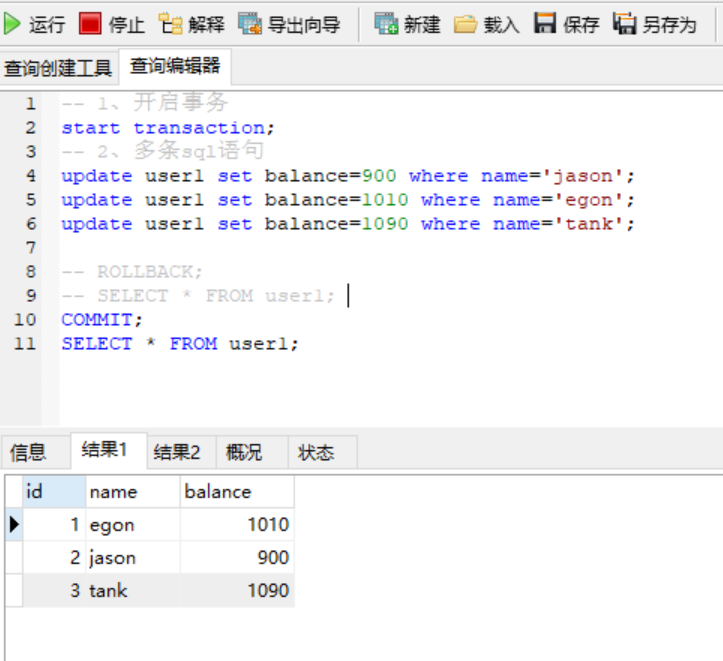
3、确认(确认之后无法回滚)
commit;
案例:模拟转账功能
create table user(
id int primary key auto_increment,
name char(16),
balance int
);
insert into user(name,balance) values('egon',10000),('jason',10000),('tank',10000);
1、开启事务
start transaction;
2、多条sql语句
update user1 set balance=900 where name='jason';
update user1 set balance=1010 where name='egon';
update user1 set balance-1090 where name='tank';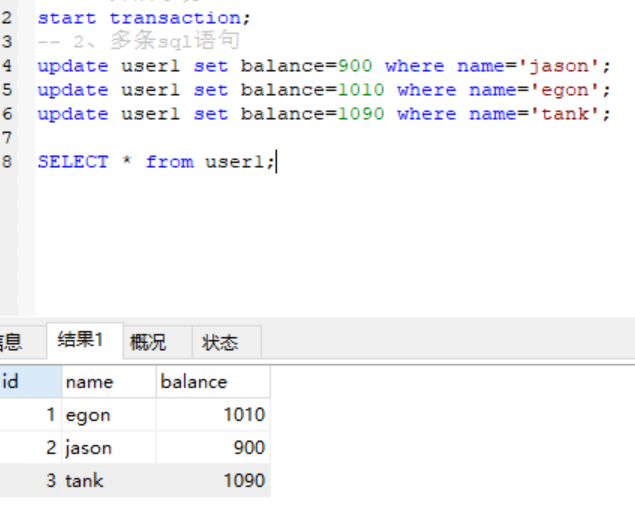
若发现不对,进行回滚操作
永久保存
四、存储过程
存储过程就类似于python中的自定义函数
它的内部包含了一系列可以执行的sql语句,存储过程存放于MYSQL服务端中,你可以直接通过调用存储过程触发内部sql语句的执行
基本使用
create procedure 存储过程名字(形参1,形参2,.....)
begin
sql代码
end
调用
call 存储过程的名字();三种开发模式
第一种:
应用程序:程序员写代码开发
MYSQL:提前编写好存储过程,供应用程序调用
好处:开发效率提升了,执行效率也上去了
缺点:考虑到人为因素、跨部门沟通的问题,后续的存储过程的扩展性较差
第二种:
应用程序:程序员写代码开发外,设计到数据库操作也自己动手写
优点:扩展性高
缺点:开发效率低,编写sql语句太过繁琐,而且后续还要考虑sql优化问题
第三种:
应用程序:只写程序代码,不写sql语句,基于别人写好的操作MYSQL的python框架(ORM框架)直接调用即可
优点:开发效率比上面两种情况都高
缺点:语句的扩展性差,可能会出现效率低下的问题
存储过程具体演示:
delimiter $$
create procedure p1(
in m int, # 只进不出,m不能返回出去
in n int,
out res int # 该形参可以返回出去
)
begin
select tname from teacher where tid>m and tid<n;
set res=66 # 将res变量修改,用来标识当前的存储过程代码确实执行了
end $$
delimiter ;
ps:针对形参res不能直接传数据,应该传一个变量名
定义变量:
set @res=10; #声明一个变量
查看变量对应的值
select @res;# 10
call p1(1,5,@res);
执行成功后res的值改变
select @res;# 66五、函数
跟存储过程是有区别的,存储过程是自定义函数,函数就类似于是内置函数
一、数学函数 ROUND(x,y) 返回参数x的四舍五入的有y位小数的值二、字符串函数 CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 FORMAT(X,D) 将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: '12,332.1000' INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。三、日期和时间函数 CURDATE()或CURRENT_DATE() 返回当前的日期 CURTIME()或CURRENT_TIME() 返回当前的时间 DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7) DAYOFMONTH(date) 返回date是一个月的第几天(1~31) DAYOFYEAR(date) 返回date是一年的第几天(1~366) DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE); FROM_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts HOUR(time) 返回time的小时值(0~23) MINUTE(time) 返回time的分钟值(0~59) MONTH(date) 返回date的月份值(1~12) MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE); NOW() 返回当前的日期和时间 QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE); WEEK(date) 返回日期date为一年中第几周(0~53) YEAR(date) 返回日期date的年份(1000~9999) 重点: DATE_FORMAT(date,format) 根据format字符串格式化date值四、加密函数 MD5() 计算字符串str的MD5校验和 PASSWORD(str) 返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法
六、流程控制
# if 判断
delimiter //
create procedure proc_if()
BEGIN
declare i in default 0;
if i=1 then
select 1;
elseif i=2 then
select 2;
else
select 7;
END IF;
END //
delimiter ;
# while判断
delimiter //
create procedure proc_while()
BEGIN
declare num int;
set num=0;
while num<10 DO
select
num;
set num=num+1;
END while;
七、索引
ps:数据都是存在于硬盘上的,查询数据不可避免的需要进行IO操作
索引:就是一种数据结构,类似于书的目录。意味着以后在查询数据的应该先找目录再找数据,而不是一页一页的翻书,从而提升查询速度降低IO操作
索引在MYSQL中也叫'键',是存储引擎用于快速查找记录的一种数据结构
primary key
unique key
index key
注意foreign key不是用来加速查询的
上面的三种key,前面两种除了可以增加查询速度外各自还具有约束条件,而最后一种index key没有任何约束条件,只是用来帮你快速查询数据
本质:
通过不断的缩小想要的数据范围筛选出最终的结果,同时将随机事件(一页一页的翻)变成顺序事件(先找目录,找数据),也就是说有了索引机制,我们可以总是用一种固定的方式查找数据
一张表中可以有多个索引(多个目录)
索引虽然能够帮助你加快查询速度但是也有缺点
1、当表中有大量数据存在的前提下,创建索引速度会很慢
2、在索引创建完毕后,对表的查询性能会大幅度的提升,但是写的性能会大幅度的降低
总结:索引不要随意创建
B+树
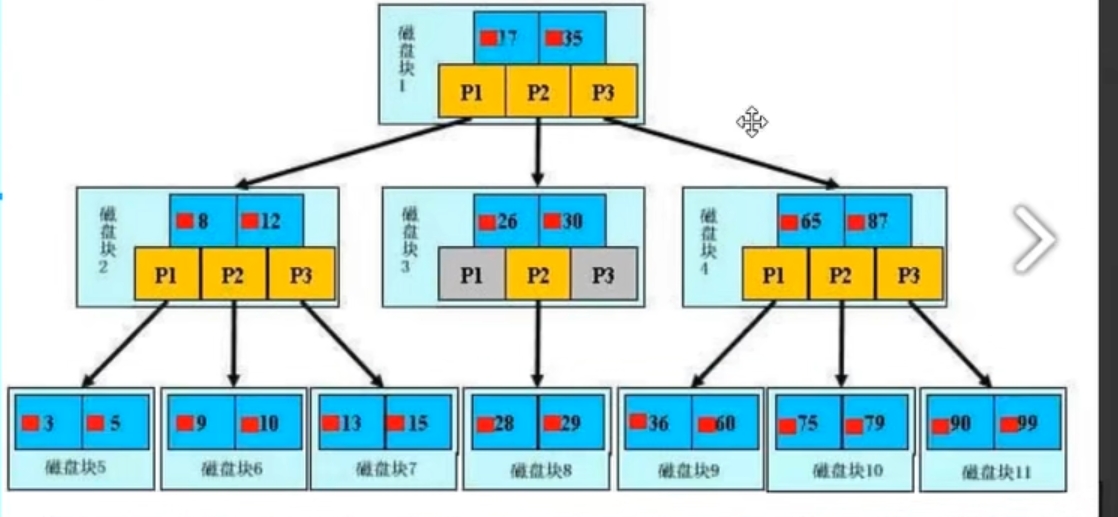
最下层才是叶子节点
只有叶子节点存放的是真实的数据,其它节点存放的是虚拟数据,仅仅用来指路
树的层级越高,查询数据所经历的步骤就越多(树有几层,查询数据就需要几步)
一个磁盘块存储是有限制的
为什么建议你将id字段作为索引
占的空间少,一个磁盘块就能够存储的数据多
那么就降低了树的高度,从而减少查询的次数
聚集索引:primary key
聚集索引指的是主键
INNDODB 只有两个文件 直接将主键存放在了idb表中
MYISAM 三个文件 单独将索引存在一个文件
辅助索引(unique,index)
查询数据的时候不可能一直使用到主键,也有可能会用到name,password等其它字段,那么这个时候你是没有办法利用聚集索引的,这个时候你就可以根据情况给其它字段设置辅助索引(也是一个B+树)
叶子节点存放的是数据对应的主键值
先按照辅助索引拿到数据的主键值
之后还是需要去主键的聚集索引里面查询数据
覆盖索引
在辅助索引的叶子节点就已经拿到了需要的数据
比如:给name设置辅助索引
select name from user where name='jason' ;
非覆盖索引
select age from user where name='egon'
最后
以上就是潇洒小蝴蝶最近收集整理的关于MySQL学习笔记(七)视图,触发器,事务,存储过程,函数,流程控制,索引的全部内容,更多相关MySQL学习笔记(七)视图内容请搜索靠谱客的其他文章。








发表评论 取消回复