一、MySQL基础篇
1. 数据库技术的基本概念和方法
1.1 数据库基本概念
1】 数据
数据(Data)指对客观事物进行描述并可以鉴别的符号,这些符号是可识别的、抽象的,不仅仅指狭义上的数字,而是有多种表现形式:字母、文字、文本、图形、音频、视频等。
2】 数据库
数据库(Database,DB)指的是以一定格式存放、能够实现多个用户共享、与应用程序彼此独立的数据集合。
3】 数据库管理系统
数据库管理系统(Database Management System,DBMS)是用来定义和管理数据的软件,如何科学的组织和存储数据,如何高效的获取和维护数据,如何保证数据的安全性和完整性,这些都需要靠数据库管理系统完成。目前,比较流行的数据库管理系统有:Oracle、MySQL、SQL Server、DB2等。
4】 数据库应用程序
数据库应用程序(Database Application System,DBAS)是在数据库管理系统基础上,使用数据库管理系统的语法,开发的直接面对最终用户的应用程序,如学生管理系统、人事管理系统、图书管理系统等。
5】 数据库管理员
数据库管理员(Database Administrator,DBA)是指对数据库管理系统进行操作的人员,其主要负责数据库的运营和维护。
6】 最终用户
最终用户(User)指的是数据库应用程序的使用者。用户面向的是数据库应用程序(通过应用程序操作数据),并不会直接与数据库打交道。
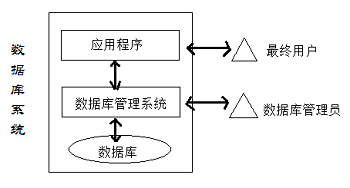
7】 数据库系统
数据库系统(Database System,DBS)一般是由数据库、数据库管理系统、数据库应用程序、数据库管理员和最终用户构成。其中,DBMS是数据库系统的基础和核心。
1.2. 数据库系统的结构
从数据库用户视图的视角来看,数据库系统通常采用三级模式结构,这是数据库管理系统内部的系统结构。
从数据库管理系统的角度,数据库系统的结构分为集中式结构、分布式结构、客户/服务器结构和并行结构,这是数据库系统的外部体系结构。
从数据库系统应用的角度,常见有客户/服务器结构和浏览器/服务器结构,这是数据库系统整体运行结构。
-
客户/服务器结构
数据库系统中,数据库的使用者可以使用命令行客户端、图形化界面管理工具或应用程序等来连接数据库管理系统,并可通过数据库管理系统查询和处理存储在底层数据库中的各种数据。即客户/服务器 (client/server,C/S)结构。 -
浏览器/服务器结构
浏览器/服务器(Brower/Server,B/S)结构是一种基于web应用的客户/服务器结构,也称为三层客户/服务器结构。数据库系统中,他将与数据库管理系统交互的客户端进一步细分为 表示层 和 处理层。
1.3. 数据模型
数据库中的数据是有一定结构的,这种结构用数据模型(Data Model)表示。根据不同的应用目的,数据模型可分为概念模型、逻辑模型和物理模型。
-
概念模型
conceptual model 用来描述现实世界的事物,与具体的计算机系统无关。现实世界是存在于人脑之外的客观世界。最典型的概念模型是实体联系(Entity-Relationship,E-R)模型。
两个实体集之间的联系有一对一(1:1)、一对多(1:N)、多对多(M:N)三种类型。
通常使用E-R图来描述现实世界的概念模型,即描述实体、实体的属性和实体间的联系。 -
逻辑模型
logical model是具体的DBMS所支持的数据模型。任何DBMS都基于某种逻辑数据模型。主要的逻辑数据模型有层次模型、网状模型、关系模型、面向对象模型等。 -
物理模型
物理模型用于描述数据在存储介质上的组织结构。每一种逻辑模型在实现时都有与之对应的物理数据模型。
1.4. 数据库类型和常见的关系型数据库
数据库类型根据数据的组织结构不同,主要分为网状数据库、层次数据库、关系型数据库和非关系型数据库四种。目前最常见的数据库模型主要是:关系型数据库和非关系型数据库。
1】 关系型数据库
关系型数据库是将复杂的数据结构用较为简单的二元关系(二维表)来表示,在该类型数据库中,对数据的操作基本上都是建立在一个或多个表格上,可以采用结构化查询语言(SQL)对数据库进行操作,关系型数据库是目前主流的数据库技术,其中具有代表性的数据库管理系统有:Oracle、DB2、SQL server、MySQL等。

1) 表(Table)也称为关系,由表名、构成表的各个列及若干行数据组成。每个表有一个唯一的表名,表中每行数据描述一个学生的基本信息。表的结构称为关系模式。
2) 列(Field)也称为字段或属性。表中每一列有一个名称,称为字段名、属性名或列名。每一列表示实体的一个属性,具有相同的数据类型。
3) 行(Row)也称作元组(Tuple)或记录。表中一行即为一个元组,每行由若干字段值组成,每个字段值描述该对象的一个属性或特征。
4) 关键字(Key)是表中能够唯一确定一个元组的属性或属性组。关键字也称作码或主键。有些情况下,需要几个属性(即属性集合)才能唯一确定一条记录。
5) 候选键,若一个表中有多个能唯一标识一个元组的属性,则这些属性称为候选键。候选键中任选一个可作为主键。
6) 外部关键字(Foreign Key)也称作外键。若表的一个字段不是本表的主键或候选键,而是另外一个表的主键或候选键,则该字段称为外键。
7) 域(Domain)表示属性的取值范围。
8) 数据类型,表中每个列都有相应的数据类型,它限制该列中存储的数据。每个字段表示同一类信息,具有相同的数据类型。
2】 非关系型数据库
NOSQL(Not Only SQL)泛指非关系型数据库。关系型数据库在超大规模和高并发的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题。NOSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。常见的非关系型数据库管理系统有Memcached、MongoDB、redis、HBase等。
3】 常见的关系型数据库
虽然非关系型数据库优点很多,但由于其并不提供SQL支持,学习和使用成本较高且无事务处理。
常用的关系型数据库管理系统:
1)Oracle
美国甲骨文(Oracle)公司开发的世界上第一款支持SQL语言的关系型数据库。具有很好的开放性,能在所有的主流平台上运行,性能高,安全性好,风险低;但其对硬件的要求很高,管理维护和操作比较复杂且价格昂贵,一般用在满足对银行、金融、保险等行业大型数据库的需求上。
2)DB2
IBM公司著名的关系型数据库产品,无论稳定性、安全性、恢复性等等都无可挑剔,且从小规模到大规模的应用都可以使用,但用起来非常繁琐,比较适合大型的分布式应用系统。
3)SQL server
由Microsoft开发和推广的关系型数据库,功能比较全面、效率高,可以作为中型企业或单位的数据库平台。SQL server可以与windows操作系统紧密继承,无论是应用程序开发速度还是系统事务处理运行速度,都能得到大幅度提升。但是只能在windows系统下运行,毫无开放性。
4)MySQL
一种开放源代码的轻量级关系型数据库。使用最常用的结构化查询语言SQL对数据库进行管理。任何人都可在General Public License的许可下下载并根据个人需要对其缺陷进行修改。
体积小、速度快成本低、开放源码等优点,现已被广泛应用于互联网上的中小型网站,且大型网站也开始使用,如网易,新浪等。
1.5. MySQL简介
最初由瑞典 MySQL AB 公司开发,2008年1月16号被Sun公司收购。2009年Sun被Oracle收购。
MySQL是一个支持多线程高并发多用户的关系型数据库管理系统。
之所以受青睐,有以下优点:
1)开放源代码
2)跨平台
3)轻量级
4)成本低
PS:社区版和企业版的主要区别是:
- 社区版包含所有MySQL的最新功能,企业版只包含稳定之后的功能。可以理解为,社区版是企业版的测试版。
- MySQL官方的支持服务只针对企业版,若用户在使用社区版时出现问题,官方是不负责任的。
1.5.1 MySQL8的安装
查看MySQL的安装结果
1.5.2 MySQL登录、访问、退出操作
1】 登录
打开控制命令台:win+r
登录的命令:mysql -hlocalhost -uroot -p
-h:host主机名。后面跟要访问的数据库服务器的地址;若是登录本机,可以省略。
-u:user用户名。后面跟登录数据的用户名,第一次安装后以root用户来登录,是MySQL的管理员用户。
-p:password密码。一般不直接输入,而是回车后以保密方式输入。
2】 访问数据库
显示MySQL的数据库列表:show databases;
默认有四个自带的数据库,每个数据库中可以有多个数据库表、视图等对象。
切换当前数据库的命令:use mysql;
- MySQL下可以有多个数据库,若要访问那个数据库,需要将其值为当前数据库。
- 该命令的作用就是将数据库mysql(默认提供的四个数据库之一的名字)置为当前数据库。
显示当前数据库的所有数据库表:show tables;
MySQL层次:不同项目对应不同的数据库组成 - 每个数据库中有很多表 - 每个表中有很多数据
3】 退出数据库
可以使用quit 或者exit命令完成,也可使用q;完成退出。
1.5.3 数据库的卸载
1)停止MySQL服务:在命令行模式下执行 net stop mysql 或者在windows服务窗口下停止服务(win10里搜索服务,找到MySQL右键点击停止)。
2)在控制面板中删除MySQL软件
3)删除软件文件夹:直接删除安装文件夹MySQL
4)删除数据文件夹:直接删除文件夹C:ProgramDataMySQL,此步不要忘记,否则会影响MySQL的再次安装。(ProgramDatabase文件夹可能是隐藏的,显示出来即可)
(MySQL文件下的内容才是真正的MySQL中数据)
5)删除path环境变量中关于MySQL安装路径的配置
1.5.4 使用图形客户端navicat12连接MySQL
1】 认识Navicat
Navicat是一套快速、可靠且价格相当便宜的数据库管理工具,专为简化数据库的管理及降低系统管理成本而设。它的设计符合数据库管理员、开发人员及中小企业的需要。 Navicat 是以直觉化的图形用户界面而建的,让你可以以安全且简单的方式创建、组织、访问并共用信息。
Navicat Premium 是一套数据库开发工具,从单一应用程序中同时连接 MySQL、 MariaDB、 Microsoft Azure 、Oracle Cloud、MongoDB Atlas 、 阿里云、腾讯云和华为云等云数据库兼容。可以快速轻松地创建、管理和维护数据库。
2】 安装Navicat
直接解压安装包,拷贝到你定义的目录下,双击其中的 navicat.exe,即可开始运行。打开后选择 连接工具按钮 --连接,输入四个连接连接参数,并进行测试,结果提示连接失败,报2059异常。
该错误原因是在 MySQL8 之前加密规则 mysql_native_password ,而在 MySQL8 以后的加密规则为 caching_sha2_password。
解决方法两种:一种是更新 navicat 驱动来解决,一种是将 mysql 用户登录的加密规则修改为 mysql_native_password 。
第二种操作方法:登录 mysql,
设置密码永不过期: alter user ’root’@’localhost’ identified by ’root’ password expire never;
设置加密规则为 mysql_native_password :
alter user ‘root’@’localhost’ identified with mysql_native_password by ‘root’;
重新访问 avicat , 提示连接成功。
2. SQL语言入门
1】 SQL语言入门
数据库管理人员(DBA)通过数据库管理系统(DBMS)对数据库(DB)中的数据进行操作。
SQL(Structure Query Language)是结构化查询语言的简称,是一种数据库查询和程序设计语言,同时也是目前使用最广泛的关系型数据库操作语言。在数据库管理系统中,使用SQL语言来实现数据的存取、查询、更新等功能。SQL是一种非过程化语言,只需提出“做什么”,而不需要指明“怎么做”。
2】 SQL语言分为五个部分:
- 数据查询语言(Data Query Language,DQL):
DQL主要用于数据的查询,基本结构是使用
SELECT 子句、FROM 子句和 WHERE 子句的组合来查询一条或多条数据。
- 数据操作语言(Data Manipulation Language,DML):
DML主要用于对数据库中的数据进行增加、修改和删除的操作,主要包括:
1)INSERT:增加数据
2)UPDATE:修改数据
3)DELETE:删除数据
- 数据定义语言(Data Definition Language,DDL):
DDL主要针对数据库对象(数据库、表、索引、视图、触发器、存储过程、函数)进行创建、修改和删除操作。其主要包括:
1)CREATE:创建数据库对象
2)ALTER:修改数据库对象
3)DROP:删除数据库对象
- 数据控制语言(Data Control Language,DCL):DCL用来授予或回收访问数据库的权限。主要包括:
1)GRANT:授予用户某种权限
2)REVOKE:回收授予的某种权限
- 事务控制语言(Transaction Control Language,TCL):TCL用于数据库的事务管理。主要包括:
1)START TRANSACTION:开启事务
2)COMMIT:提交事务
3)ROLLBACK:回滚事务
4)SET TRANSACTION:设置事物的属性
3. DDL_DML_创建数据库|表
3.1 数据库表列类型
1】整数类型
MySQL支持选择在该类型关键字后面的括号内指定整数值显示宽度(如,INT(4))。显示宽度并不限制可以在列内保存的值的范围,也不限值超过列的指定宽度的值的显示。
主键自增:不使用序列,通过 auto_increment,要求是整数类型。
2】 浮点数类型
需要注意的是与整数类型不一样的是,浮点数类型的宽度不会自动扩充。
score double(4,1)-- 小数部分为1位,总宽度4位,并且不会自动扩充。
3】 字符串类型
CHAR 和 VARCHAR 类型相似,均用于存储较短的字符串,主要的不同之处在于存储方式。
CHAR 类型长度固定, VARCHAR 类型长度可变。因为 VARCHAR 类型能够根据字符串的实际长度来动态改变所占字节的大小,所以在不能明确该字段具体需要多少字符时,推荐使用 VARCHAR ,这样可以大大节约磁盘空间,提高存储效率。
CHAR 和 VARCHAR 表示的是字符的个数,而不是字节的个数。
BLOB 存储音频视频。
4】 日期和时间类型
TIMESTAMP 类型的数据指定方式与 DATTIME 基本相同,两者的不同之处在于以下几点:
1)数据的取值范围不同, TIMESTAMP 的取值范围更小。
2)若对 TIMESTAMP 的字段没有明确赋值,或是被赋予了 NULL值,MySQL会自动将该字段赋值为系统当前的日期和时间。
3)TIMESTAMP 还可以使用 CURRENT_TIMESTAMP 来获取系统当前时间。
4)TIMESTAMP 有一个很大的特点,就是时间是根据时区来显示的。
3.2 定义数据库
-- 创建数据库
create database [if not exists] db_name
[[default] character set gb2312
[[default] collate gb2312_chinese_ci;
-- []内为可选项
-- if not exists:在创建数据库前进行判断,只有不存在时才可以创建
-- character set:指定数据库字符集(charset)。简体中文字符集名称为gb2312
-- collate:指定字符集的校对规则。简体中文字符集的校对规则为gb2312_chinese_ci
-- default:指定默认的数据库字符集和字符集的校对规则
-- 选择数据库
-- 只有使用use命令指定某个数据库为当前数据库之后,才能对该数据库及其存储的数据对象执行各种操作
use db_name;
-- 查看当前用户可查看的数据库列表
show databases;
-- 修改数据库
-- 数据库的默认字符集为latin1,默认校对规则为latin1_swedish_ci
alter database [db_name]
[default] character set gb2312
[default] collate gb2312_chinese_ci;
-- 删除数据库
drop database [if exists] db_name;
-- 删除整个数据库,该数据库中的所有将被永久删除
3.3 定义表
1】 认识数据库表
表(Table)是数据库中数据存储最常见和最简单的一种形式,数据库可以将复杂的数据结构用较为简单的二维表来表示。二维表是由行和列组成的,分别都包含着数据。
每个表都是由若干行和列组成的,在数据库中,表中的行被称为记录,表中的列被称为是这些记录的字段。
记录也被称为一行数据,是表里的一行。在关系型数据库的表中,一行数据是指一条完整的记录。
字段是表里的一列,用于保存每条记录的特定信息。
2】 创建数据库表 student
-- 创建表
create table tb_name (
字段名1 数据类型 [列级完整性约束条件] [默认值]
[,字段名2 数据类型 [列级完整性约束条件] [默认值]]
[,... ...]
[,表级完整性约束条件]
)[engine=引擎类型];
- 建立一张用来存储学生信息的表
- 字段包含学号、姓名、性别、年龄、入学日期、班级、Email等信息
- 姓名不能为空
- 性别默认值是男
- Email唯一
1)创建数据库:
Navicat中新建数据库,字符集:utf8mb4
2)新建查询:
Navicat菜单点击查询,新建查询
3)创建数据库表:
##、-- :单行注释
/* 内容 */ :多行注释
--创建数据库表:
create table student (
number int(6) not null primary key auto_increment, -- 6显示长度
name varchar(10) not null,
sex char(1) default ‘male’,
age int(3)
enterdate date,
class varchar(10),
email varchar(15) unique
)[engine=InnoDB];
navicat 中选中所写的SQL语言,右键点击运行,ok表示已创建表。
– 表的创建需要选定当前数据库,若表名称被指定为 db_name.tbl_name 的格式,则可在特定的数据库中创建表,而不论是否有当前数据库,都可以通过这种方式来创建表
– 完整性约束条件包括实体完整性约束(primary key、unique)、参照完整性约束(foreign key)和用户自定义约束(not null、default、check 约束等)。若完整性约束条件涉及该表的多个字段,则必须定义在表级上,否则既可以定义在表级,也可定义在列级。
– 关键字 null 和 not null 可以给字段自定义约束。允许null的列也允许在插入记录时不给出该列的值。null为默认设置。null值是没有值,不是空串。指定’ ’(两个单引号,中间没有字符)在not null列是允许的,因为空串是一个有效的值,并非无值。
– auto_increment将字段设置为自增属性,可以给记录一个唯一而又容易确定ID号,该字段可以唯一标识表中的每条记录。MySQL中,只有整型列才能设置。默认初始值为1,当往一个定义为auto_increment 列中插入null值或数字0时,该列的值会被设置为 value+1(默认为加1递增),其中value是当前表中该列的最大值。每个表只能定义一个自增列,且必须在该列上定义主键约束(primary key)或候选键约束(unique)
– default 设置默认值。
– show engines可以查看系统支持的引擎类型和默认引擎。InnoDB是事务型数据库的首选引擎。
-- 查看表的名称
show tables [{from|in} db_name];
-- 使用{from|in} db_name 可显示非当前数据库中的数据库表名称
-- 查看表的基本结构
-- describe,显示表的字段详细信息
desc tb_name;
show columns {from|in} tb_name [{from|in} db_name];
-- 查看表的详细结构,建表语句
show create table tb_name;
show create table studentG;
-- 查看表中数据
select * from student;
3.4 修改表
对已经创建的表做进一步的结构修改与调整。使用alter table 来修改原有表的结构。常用的修改表操作有:修改字段名或字段的数据类型、添加和删除字段、修改字段的排列位置、更改表的引擎类型、增加和删除表的约束等。
-- 修改表结构
-- 添加字段
alter table tb_name add [column] 新字段名 数据类型
[约束条件][first|after 已有字段名]
-- 可选项“约束条件”用于指定字段取值不为空、字段的默认值、主键以及候选键约束等。
-- 可选项“first|after 已有字段名”用于指定新增字段在表中的位置:first表示将新添加的字段设置为表的第一个字段,after 表示将新添加的字段加到指定的已有字段名的后面。若语句中未设置,则默认将新添加的字段设置为数据表的最后一列
alter table student add id int not null unique auto_increment first;
desc student;
alter table student add department varchar(16) default ‘信息学院’ after nation;
-- 增加一列
alter table student add score double(5,2);
update student set score = 132.567 where number = 1;
-- 增加一列(放在最前面)
alter table student add score double(5,2) first;
-- 增加一列(放在sex列的后面)
alter table student add score after sex;
-- 修改字段
alter table tb_name change [column] 原字段名 新字段名 数据类型 [约束条件];
alter table tb_name modify [column] 字段名 数据类型 [约束条件] [first|after 已有字段名];
alter table tb_name alter [column] 字段名 {set|drop} default;
-- change可同时修改列名和列的数据类型。可同时添加多个,用逗号分隔
-- modify只会修改列的数据类型,还可指定列的位置
-- alter可修改或删除默认值
-- 修改一列
alter table student change score scores double(5,1); -- change 修改列名和列的类型
alter table student modify score float(4,1); -- modify 修改的是列的类型,不会改变列的名字
alert table student alter department drop default;
alter table student change birthday age tinyint null default 18;
alter table student modify department varchar(10) not null after sid;
alter table student alter email set dedault ‘XX@gmail.com’;
-- 注意:修改数据类型可能会丢失原有的数据;若数据类型与原来的不兼容,命令不会执行,提示错误,兼容则数据可能会被截断。
-- 删除字段
alter table tb_name drop [column] 字段名;
alter table student drop email;
-- 重命名表
alter table tb_name rename [to] 新表名;
rename table tb_name1 to newname1 [, name2 to newname2] ... ...;
alter table student rename studentstable;
rename table studentstable to student;
-- 删除表
drop table [if exists] tb_name1[,tb_name2] ... ...;
-- 若删除的表不存在且不加if exists,会提示“Error 1051...”;加上if exists,表不存在,语句可顺利执行,但会发出警告 warning
3.5 数据的完整性约束
关系模型的完整性规则是对关系的某种约束条件。对关系模型施加完整性约束,则是为了在数据库应用中保障数据的准确性和一致性,这也是数据库服务器最重要的功能之一。
约束分类
约束从作用上可以分为两类:
1)表级约束:表中所有字段定义后添加。
可以约束表中任意一个或多个字段。与列定义相互独立,不包含在列定义中;与定义用‘,’分隔,必须指出要约束的列的名称。
2)列级约束:表中某个字段定义后添加。
包含在列定义中,直接跟在该列的其他定义之后,用空格分隔;不必指定列名。
3.5.1 定义实体完整性
实体完整性规则(Entity Integrity Rule)是指关系的主属性不能取空值,即主键和候选键在关系中所对应的属性都不能取空值。MySQL中实体完整性就是通过主键约束和候选键约束实现的。
1】 主键约束
主键是表中某一列或某些列所构成的一个组合。由多个列组合而成的主键也称为复合主键。
- 每个表只能定义一个主键
- 键值必须能够唯一标识表中的每一行记录,且不能为null
- 复合主键不能包含不必要的多余列
- 一个列名在复合主键的列表中只能出现一次
-- 列级约束
create table student (
number int(6) primary key auto_increment,
name varchar(10) not null,
sex char(1) default ‘M’ check(sex=’M’||sex=’F’),
age int(3) check(age>17 and age<51),
enterdate date,
class varchar(10),
email varchar(15) unique
);
-- 添加数据
insert into student values (1,’wang’,’F’,28,now(),’class 1’,’wang@126.com’);
-- 部分添加
insert into student (name,enterdate) values (’weisu’,’2011/09/01’);
-- 若主键没有设定值,或者用null default 都可以完成主键自增效果
insert into student values (null,’wan’,’M’,24,now(),’class 1’,’wan@126.com’);
insert into student values (default,’liu’,’M’,33,now(),’class 1’,’liu@126.com’);
-- 若SQL报错,主键可能就浪费了,后续插入的主键是不连号的,主键不要求连号
insert into student values (null,’wan’,’M’,00,now(),’class 1’,’wan@126.com’);-- 报错,后面主键不连号
-- 表级约束
create table students (
number int(6) auto_increment,
name varchar(10) not null,
sex char(1) default ‘M’,
age int(3),
enterdate date,
class varchar(10),
email varchar(15),
primary key(number)
);
create table students (
number int(6) auto_increment,
name varchar(10) not null,
sex char(1) default ‘M’,
age int(3),
enterdate date,
class varchar(10),
email varchar(15)
);
-- ERROR 1075 (42000): Incorrect table definition; there can be only one auto column and it must be defined as a key
-- 该错误的解决方法:去掉自增
2】 完整性约束的命名
可以对完整性约束进行添加、删除和修改等操作。其中,为了删除和修改完整性约束,首先需要在定义约束的同时对其进行命名。在各种完整性约束的定义说明之前加上关键字 constraint 和该约束的名字,
constraint<symbol>
{primary key(主键字段列表)
|unique(候选键字段列表)
|foreign key(外键字段列表) references tb_被参照关系(主键字段列表)
|check(约束条件表达式)
};
-- symbol为指定的约束名字,在完整性约束说明的前面被指定,其在数据库里必须是唯一的。
create table students (
number int(6) auto_increment,
name varchar(10) not null,
sex char(1) default ‘M’,
age int(3),
enterdate date,
class varchar(10),
email varchar(15),
constraint pk_stu primary key(number), -- pk_stu 主键约束的名字,自行定义
constraint ck_stu_sex check (sex = ‘F’|| sex = ‘M’), -- 检查约束
constraint ck_stu_age check (age>=18 and age<=50),
constraint uq_stu_email unique (email) -- 唯一约束
);
-- 在创建表之后 添加约束
alter table students add constraint pk_stu primary key(number); -- 主键约束
alter table students modify number int(6) auto_increment; -- 修改自增条件
alter table students add constraint ck_stu_sex check ( sex = ‘F’ || sex = ‘M’);
alter table students add constraint ck_stu_age check ( age >17 and age <51);
alter table students add constraint uq_stu_email unique(email);
-- 查看表结构
desc students;
3】 候选键约束
可以是表中的某一列,也可以是表中某些列所构成的一个组合。必须唯一且不为null。使用unique定义
create table school (
classid char(6) primary key,
classname varchar(10) not null unique,
grade smallint,
classnum tinyint
)engine=innodb;
create table school (
classid char(6) primary key,
classname varchar(10) not null,
grade smallint,
classnum tinyint,
constraint uq_class unique(classname)
)engine=innodb;
primary key 和 unique 的区别:
- 一个表中只能创建一个primary key,但可以定义若干unique
- 定义为primary key的列不允许有空值,但unique字段允许控制存在
- 定义primary key约束时,系统自动产生primary key 索引,定义unique时,系统自动产生unique索引
3.5.2 定义参照完整性
现实世界中实体之间往往存在某种联系,在关系模型中实体间的联系都是用关系来描述的,因此可能存在着关系与关系间的引用。如,学生实体和班级实体可分别用下面关系模式表示,其中主键用下划线标识。
学生(学号,姓名,性别,出生日期,籍贯,民族,班级编号)
班级(班级编号,班级名称,所属院系,年级,班级最大人数)
这两个关系间存在着属性的引用,即学生关系引用了班级关系的主键“班级编号”。在学生关系中,班级编号是外键。
外键是一个表中的一个或一组属性,不是这个表的主键,但对应另一个表的主键。定义外键后,不允许删除外键引用的另一个表中具有关联关系的记录。外键所属的表称作参照关系,相关联的主键所在的表称作被参照关系。
参照完整性规则(Referential Integrity Rule)定义的是外键与主键之间的引用规则,即外键的取值或者为空,或者等于被参照关系中某个主键的值。
定义外键时,需要遵守以下规则:
- 被参照表必须已经使用create table语句创建,或者必须是当前正创建的表。若是后一种情形,则被参照表与参照表是同一个表,这样的表称为自参照表(self-referencing table),这种结构称为自参照完整性(self-referencial integrity)
- 必须为被参照表定义主键或候选键
- 必须在被参照表的表名后面指定列名或列名的组合,这个列或列组合必须是被参照表的主键或候选键
- 尽管主键是不能够包含空值的,但允许在外建出现空值。这意味着,只要外键的每个非空值出现在指定的主键中,这个外键的内容就是正确的
- 外键对应列的数目必须和被参照表的主键对应列的数目相同
- 外键对应列的数据类型必须和被参照表的主键对应列的数据类型相同
-- 列级完整性约束
create table ondata.student (
stuid char(10),
stuname varchar(20) not null,
sex char(2) not null,
birthday date,
nation varchar(10) default ‘汉’,
classid char(6) references tb_class(classid),
constraint pk_stuid primary key(stuid)
);
-- 表级完整性约束
create table ondata.student (
stuid char(10),
stuname varchar(20) not null,
sex char(2) not null,
birthday date,
nation varchar(10) default ‘汉’,
classid char(6),
constraint pk_stuid primary key(stuid),
constraint fk_classid foreign key(classid) references tb_class(classid)
);
定义外键约束后,只有当某班级里没有学生时,才可以删除该班级信息。MySQL可以通过定义一个参照动作来修改这个规则,即定义外键时可以显示说明参照完整性约束的违约处理策略。
给外键定义参照动作时,需要包括两部分:一是要指定参照动作适用的语句,即update 和delete 语句;二是要指定采取的动作,即 cascade、restrict、set null、no action 和 set default,其中,restrict 为默认值。
具体策略如下:
-
restrict:限制策略,即当要删除或修改被参照表中被参照列上且在外键中出现的值时,系统拒绝对被参照表的删除或修改操作。
-
cascade:级联策略,即从被参照表中删除或修改记录时,自动删除或修改参照表中匹配的记录。
-
set null:置空策略,即当从被参照表中删除或修改记录时,设置参照表中与之对应的外键列的值为null。这个策略需要被参照表中的外键列没有声明限定词 not null。
-
no action:表示不采取实施策略,即当一个相关的外键值在被参照表中时,删除或修改被参照表中键值的动作不被允许。与restrict相同。
-
set default:默认值策略,即当从被参照表中删除或修改记录时,设置参照表中与之对应的外键列的值为默认值。这个策略要求已经为该列定义了默认值。
create table ondata.student (
stuid char(10),
stuname varchar(20) not null,
sex char(2) not null,
birthday date,
nation varchar(10) default ‘汉’,
classid char(6),
constraint pk_stuid primary key(stuid),
constraint fk_classid foreign key(classid) references tb_class(classid)
on update restrict -- 表示当某个班级里有学生时不允许修改班级表中班级编号
on delete cascade -- 要删除班级表中某个班级编号时,若班级里有学生,就将相应学生记录级联删除
);
外键只可以用在使用存储引擎InnoDB创建的表中。
1】 外键约束
外键约束(FOREIGN KEY,缩写FK)是用来实现数据库表的参照完整性的。外键约束可以使两张表紧密结合起来,特别是针对修改或者删除的级联操作时,会保证数据的完整性。
外键是指表中某个字段的值依赖于另一张表中某个字段的值,而被依赖的字段必须具有主键约束或者唯一约束。被依赖的表我们通常称之为父表或者主表,设置外键约束的表称为子表或者从表。
例子:若想要表示学生和班级的关系,首先要有学生表和班级表两张表,然后学生表中有个字段为 stu_class(该字段表示学生所在的班级),而该字段的取值范围由班级表中的主键 cla_id 字段(该字段表示班级编号)的取值决定。那么班级表为主表,学生表为从表,且stu_class字段是学生表的外键,通过stu_class字段就建立了学生表和班级表的关系。
主表(父表):班级表 — 班级编号 — 主键
从表(子表):学生表 — 班级编号 — 外键
2】 SQL展示
-- 先创建父表,班级表
create table class(
cid int(4) primary key auto_increment,
cname varchar(10) not null,
room char(4)
);
-- 添加班级数据
insert into class values (null,’java001’,’r001’),(null,’java002’,’r345’),
(null,’python01’,’r123’);
-- 创建子表
drop table student;
create table student(
sid int(4) primary key auto_increment,
sname varchar(10) not null,
classid int(4) -- 取值参考class表中的cid字段,不要求字段名字完全重复,但是类型定义尽量要求相同!
);
-- 添加学生信息
insert into student values(null,’mark’,1),(null,’Jane’,1),(null,’Jordan’,2);
-- 查看学生表
select * from student;
-- 出现问题
-- 1.添加一个学生对应的班级编号为4
insert into student values (null,’lily’,4);
-- 2.删除班级2
delete from class where cid = 2;
-- 出现问题的原因
-- 现在的外键约束,没有用语法添加进去,只是逻辑上认为班级编号是外键
-- 解决办法:添加外键约束
-- 注意:外键约束只有表级约束!!
create table student(
sid int(4) primary key auto_increment,
sname varchar(10) not null,
classid int(4),
constraint fk_stu_classid foreign key (classid) references class (cid)
);
-- 创建表后添加外键约束
create table student(
sid int(4) primary key auto_increment,
sname varchar(10) not null,
classid int(4)
);
alter table student add constraint fk_stu_classid foreign key (classid) references class (cid);
注意:先删除主表,再删除从表。
3】 外键策略
-- 删除班级2:无法直接删除,有外键约束
-- 加入外键策略:
-- 策略1: no action 不允许操作
-- 通过操作SQL来完成:
-- 先把班级2的学生对应的班级改为NULL
update student set classid = null where classid = 2;
-- 然后再删除班级2
delete from class where cid = 2;
-- 策略2:cascade 级联操作:操作主表的时候,影响从表的外键信息
-- 先删除之前的外键约束:
alter table student drop foreign key fk_stu_classid;
-- 重新添加外键约束:
alter table student add constraint fk_stu_classid foreign key (classid) references class(cid) on update cascade on delete cascade;
-- 试试更新:
update class set cid = 5 where cid = 3;
-- 试试删除:
delete from class where cid = 5;
-- 策略3:set null 置空操作
-- 先删除之前的外键约束:
alter table student drop foreign key fk_stu_classid;
-- 重新添加外键约束:
alter table student add constraint fk_stu_classid foreign key (classid) references class(cid) on update set null on delete set null;
-- 试试更新:
update class set cid = 8 where cid = 1;
-- 注意:
-- 1. 策略2 级联操作 和策略3 删除操作可以混着使用
alter table student add constraint fk_stu_classid foreign key (classid) references class(cid) on update cascade on delete set null;
-- 2.应用场合:
1)朋友圈删除,点赞、留言都删除 -- 级联操作
2)解散班级,对应的学生班级 置为NULL就可以 -- set null
3.5.3 用户定义的完整性
不同数据库系统根据其应用环境的不同,往往还需要定义一些特殊的约束条件,即用户定义的完整性规则 (User-defined Interity Rule),它反映了某一具体应用所涉及的数据应满足的语义要求。
MySQL支持的用户自定义完整性约束:非空约束、check约束和触发器。
1. 设置非空约束
非空约束的定义可以使用create table 或alter table语句,在某个列定义后面加上关键字not null作为限定词,来约束该列的取值不能为空。
2. check约束
check约束需要指定限定条件,可分别定为列级或表级完整性约束。常用语法格式是:
check (expr);
其中,expr是一个表达式,用于指定需要检查的限定条件。如,可在限定条件中加入子查询。
create table tb_course(
courseid char(6),
coursename varchar(20) not null,
credit int not null,
coursehour int not null,
priorcourse char(6),
constraint pk_course primary key (courseid),
constraint fk_course foreign key (priorcourse) references tb_course(courseid),
constraint ck_course check(credit = coursehour/16)
);
check约束定义了字段credit和coursehour间应满足的函数关系,故只能定义为表级约束。
小结
- 主键约束
主键约束(PRIMARY KEY,缩写PK),是数据库中最重要的一种约束,其作用是约束表中的某个字段可以唯一标识一条记录。因此,使用主键约束可以快速查找表中的记录。就像人的身份证、学生学号等,设置为主键的字段取值(唯一)不能重复,也(非空)不能为空,否则无法唯一标识一条记录。
主键可以是单个字段,也可以是多个字段组合。对于单字段主键的添加可使用表级约束,也可使用列级约束;而对于多字段主键的添加,只能使用表级约束。
- 非空约束
非空约束(NOT NULL,缩写NK),规定了一张表中指定的某个字段的值不能为空(NULL)。设置了非空约束的字段,在插入的数据为NULL时,数据库会提示错误,导致数据无法插入。
无论是单个字段还是多个字段,非空约束的添加只能使用列级约束 (非空约束无表级约束)。
为已存在表中的字段添加非空约束
alter table students modify number int(5) not null;
删除非空
alter table students modify number int(5) null;
- 唯一约束
唯一约束(UNIQUE,缩写UK),规定了一张表中指定的某个字段的值不能重复,即这一字段的的每个值都是唯一的。
无论是单个字段还是多个字段,唯一约束的添加都能使用列级约束和表级约束。
-
检查约束
检查约束(CHECK)用来限制某个字段的取值范围,可以定义为列级约束,也可以定义为表级约束。 -
默认值约束
默认值约束(DEFAULT)用来规定字段的默认值。若某个被设置为DEFAULT约束的字段没插入具体值,那么该字段的值将会被默认值填充。
默认值约束的设置与非空约束一样,也只能使用列级约束。
- 字段值自动增加约束
自增约束(AUTO_INCREMENT)可以使表中某个字段的值自动增加。一张表中只能有一个字增长字段,且该字段必须定义了约束(该约束可以使主键约束、唯一约束以及外键约束)。若自增字段没有定义约束,数据库会提示“Incorrect table definition; there can be only one auto column and it must be defined as a key”错误。
由于自增约束会自动生成唯一的ID,所以自增约束通常会配合主键使用,并且只适用于整数类型。一般情况下,设置为自增约束字段的值会从1开始,每增加一条记录,该字段的值加1。
为已存在表中的主键字段设置自增约束
-- 创建表时:
create table students(
id int(10) primary key,
name varchar(5) not null,
age int(3),
sex char(1) default ‘F’
);
-- 表中主键字段添加自增约束
alter table student modify student int(6) auto_increment;
使用ALTER TABLE语句删除自增约束
alter table student modify student int(10);
3.5.4 更新完整性约束
1. 删除约束
1) 删除外键约束
若使用constraint子句命名的表级完整性约束,则用:
alter table <表名> drop foreign key <外键约束名>;
-- 删除表tb_score在 studentid上定义的外键约束 fk_score
alter table tb_score drop foreign key fk_score;
当要删除无命名的外键约束时,可先使用 show create table 语句查看系统给外键约束指定的名称,然后再删除该约束名。
-- 在表tb_score字段studentid上定义一个无命名的外键约束,然后删除它
-- 定义一个无名外键约束
alter table tb_score add foreign key (studentid) references tb_student(studentid);
-- 查看系统给定的外键约束名称
show create table tb_scoreG;
-- 删除该约束
alter table tb_score drop foreign key fk_studentid;
2) 删除主键约束
删除主键约束时,因为一个表只能定义一个主键,所以无论有没给主键约束命名,均使用:
alter table <表名> drop primary key;
3) 删除候选键约束
删除候选键约束时,MySQL实际删除的是唯一性索引,应使用drop index子句删除。若没有给约束命名,MySQL自动将字段名定义为索引名。
alter table <表名> drop {约束名|候选键字段名};
2. 添加约束
数据表定义完成后,可以使用alter table语句添加完整性约束。
1) 添加主键约束
alter table <表名> add [constraint <约束名>] primary key (主键字段);
alter table tb_student add constraint pk_student primary key(studentid);
2) 添加外键约束
alter table <表名> add [constraint <约束名>] foreign key (外键字段名) references 被参照表(主键字段名);
alter table tb_score add constraint foreign key (studentid) references tb_student(studentid);
3) 添加候选键约束
alter table <表名> add [constraint <约束名>] unique key(字段名);
alter table tb_class add constraint uq_class unique key(classname);
4. 数据查询
4.1. select 语句
select [all|distinct|distinctrow] <目标表达式1>[,<目标表达式2>] ...
from <表名1或视图名1>[,<表名2或视图名2>] ...
[where <条件表达式>]
[group by <列名1> [having <条件表达式>]]
[order by <列名2> [asc|desc]]
[limit [m,]n];
– all|distinct|distinctrow:用于指定是否应返回结果集中的重复行。若没有指定,默认all,即返回所有匹配行。distinct和distinctrow一样,会消除结果集中的重复行。
– select子句:用于指定要显示的字段或表达式。
– from子句:指定数据来源于哪些表或视图
– where子句:用于指定对记录的过滤条件
– group by子句:将查询结果集按指定的字段值分组
– having子句:指定分组结果集的过滤条件
– order by子句:将查询结果集按指定字段值的升序或降序排序
– limit子句:指定查询结果集包含的记录数
所有可选子句必须依照select语句的语法格式所罗列的顺序使用。
4.2. 单表查询
1. 选择字段
select 目标表达式1,目标表达式2,...,目标表达式n
from 表名;
-- 查询指定字段
select sid,classname,department from student;
-- 去重
select disctinct department from class;
-- 查询所有字段
select * from student;
-- 查询经过计算的值
select sid,sex,’age:’,’year(now())-year(birthday) from student;
-- ‘age:’字符串常量,直接以列显示在表中
-- 定义字段别名
-- select子句的目标列表达式之后添加,格式: 字段 [as] 字段别名;
select sid,sex,year(now())-year(birthday) age from student;
2. 选择指定记录
用户查询时只需要查询表中的指定数据,即对数据进行过滤。
select 目标表达式1,目标表达式2,...,目标表达式n
from 表名
where 查询条件;
常用查询条件:
比较:=,<>,!=,<,<=,>,>=,!<,!>,not+含比较运算符的表达式
确定范围:between and,not between and
确定集合:in,not in
字符匹配:like,not like
空值:is null,is not null
多重条件:and,or
-- 比较大小
select coursename,credit,coursehour from tb_cousre where coursehour>=48;
select coursename,credit,coursehour from tb_cousre where not coursehour<48;
select sname,sex,nation from tb_student where nation != ‘汉’;
select sname,sex,nation from tb_student where nation <> ‘汉’;
select sname,sex,nation from tb_student where not nation = ‘汉’;
-- 带between..and关键字的范围查询
select sname,sex,birthday from tb_student
where birthday between ’1999-01-01’ and ’2000-01-01’;
select sname,sex,birthday from tb_student
where birthday not between ’1999-01-01’ and ’2000-01-01’;
-- 带in关键字的集合查询
select * from tb_student where nation in (‘beijing’,’shanghai’);
-- 带like关键字的字符串匹配查询
[not] like ‘<匹配串>’[escape ‘<换码字符>’]
-- 通配符:% :任意长度的字符串,甚至包括长度为0的字符;_:任意单个字符。
select * from tb_student where sid like ’23435’;
select * from tb_student where name like ‘w%’;
-- 若匹配的字符串本身就含有通配符%或_,就要使用escape‘<换码字符>’短语对通配符进行转义。
-- 查询含有_的课程信息
select * from course where coursename like ‘%#_%’escape ‘#’;
-- 使用escape指定一个转义符#,匹配串中#后面的_ 不再是通配符,而是普通字符
-- MySQL默认不区分大小写,若要区分,需要更换字符集的校对规则
– 使用正则表达式的查询
– 正则表达式通常被用来检索或替换符合某个模式的文本内容,根据指定的匹配模式查找文本中符合要求的特殊字符
– 如,从一个文本文件中提取电话号码、查找一篇文章中重复的词或替换用户输入的某些敏感词等
[not] [regexp|rlike] <正则表达式>
– 其中,运算符 rlike是 regexp的同义词。
– 正则表达式可以匹配任意一个字符活在指定集合范围内查找某个匹配的字符;可以实现带搜索对象的选择性匹配,即在匹配模式中使用“|”分隔每个供选择匹配的字符串;也可使用定位符匹配处于特定位置的文本。还可以对要匹配的字符或字符串的数目进行控制。
正则表达式常用字符匹配列表
选项 说明 例子 匹配值示例
<字符串> 匹配包含指定字符串的文本 ‘fa’ fan,afa,faad
[] 匹配[]中的任意一个字符 ‘[ab]’ bay,big,app
[^] 匹配不在[]中的任意一个字符 ‘[^ab]’ desk,cool,six
^ 匹配文本的开始字符 ‘^b’ bed,brigde,book
$ 匹配文本的结尾字符 ‘er$’ river,worker,farmer
. 匹配任意单个字符 ‘b.t’ better,bit,bite
* 匹配0个或多个*前面指定的字符 ‘f*n’ fn,fan,begin
+ 匹配+前面的字符1次或多次 ‘ba+’ bat,baa,battle,bala
{n} 匹配前面的字符至少n次 ‘b{2}’ bb,bbbb,bbbbbb
select * from student where sname regexp ‘w;;
等价于
select * from student where sname like ‘%w%’;
– like 和 regexp 区别:
like必须使用通配符,like用于匹配整个字段值,若被匹配的字符串在字段值中出现,like将不会找到,除非是用通配符;regexp是在字段值内匹配,若被匹配的文本在字段值中出现,regexp将会找到,并返回相应的行
-- 查询课程名中含有“管理”“信息”或“系统”中文字符的所有课程信息
select * from tb_course where coursename regexp ‘管理|信息|系统’;
-- 带 is null 关键字的空值查询
-- is 不能用=代替!
select * from tb_course where priorcourse is null;
select * from tb_course where priorcourse is not null;
-- 带and或or的多条件查询
select * from tb_course where credit>=3 and coursehour > 32;
-- 查询籍贯是北京或湖南的少数民族男生的姓名、籍贯和民族
select studentname,native,nation from tb_student
where (nation = ‘beijing’ or nation = ‘hunan’) and nation != ‘han’and sex = ‘male’;
3. 对查询结果排序
order by <列名> [asc|desc] ,默认升序
select * from student order by studentname;
select * from tb_score where score > 60 order by studentid,score desc;
– 多个不同字段会按照从左至右的次序依次进行排序
– 对空值进行排序时,会将空值作为最小值对待
4. 限制查询结果的数量
使用limit子句限制select语句返回的行数,
limit [位置偏移量,]行数
行数指定需要返回的记录数,位置偏移量指示从哪一行开始显示,第一条记录的位置偏移量是0,第二条记录的位置是1…。不指定位置偏移量将从第一条记录开始显示
select studentid,courseid,score
from tb_score
order by score desc
limit 2,3;
MySQL5.0开始,可是用另一种语法
limit 行数 offset 位置偏移量
【SQL语句展示】
-- 对emp表查询
select * from emp; -- * 代表所有数据
-- 显示部分列
select ename,empno,sal from emp;
-- 显示部分行:where子句
select * from emp where sal > 2000;
-- 显示部分列,部分行
select empno,ename,job,mgr from emp where sal > 2000;
-- 起别名
select empno 员工编号,ename 姓名,sal 工资 from emp;
-- as alias 别名
select empno as 员工编号,ename as 姓名,sal as 工资 from emp;
select empno as ‘员工编号’,ename as “姓名”,sal as 工资 from emp;
-- 在别命中有特殊符号时,’ ’或者 “”不可以省略!
-- 算术运算符
select empno,ename,sal,sal+1000 as ’涨薪后’,deptno from emp where sal < 2500;
select empno,ename,sal,comm,sal+comm from emp; -- null时如何实现加减??
-- 去重操作
select job from emp;
select distinct job from emp;
select job,deptno from emp;
select distinct job,deptno from emp; -- 对后面的所有列组合去重,而不是单独的某一列去重!!
-- 排序
select * from emp order by sal; -- 默认情况下按照升序排列
select * from emp order by sal asc; -- asc 升序,可不写
select * from emp order by sal desc; -- desc 降序
select * from emp order by sal asc, deptno desc; -- 在工资升序情况下,相同工资的deptno 降序
-- where子句
-- 将过滤条件放在where子句后,可筛选过滤出符合条件的数据
-- where子句 + 关系运算符
select * from emp where deptno = 10;
select * from emp where deptno > 10;
select * from emp where deptno < 10;
select * from emp where deptno <= 10;
select * from emp where deptno >= 10;
select * from emp where deptno != 10;
select * from emp where deptno <> 10;
select * from emp where job = ‘clerk’;
select * from emp where job = ‘CLERK’;-- 默认情况下不区分大小写!
select * from emp where binary job = ‘clerk’; -- 区分大小写!!!
select * from emp where hiredate < ’1999-12-30’;
-- where子句 + 逻辑运算符 and
select * from emp where sal > 1500 and sal < 3000;
select * from emp where sal > 1500 && sal < 3000;
select * from emp where sal > 1500 and sal < 3000 order by sal;
select * from emp where sal between 1500 and 3000; -- 两边都包含
-- where子句 + 逻辑运算符 or
select * from emp where deptno = 20 or deptno = 10;
select * from emp where deptno = 20 || deptno = 10;
select * from emp where deptno in (10,20);
select * from emp where job in (’manager’,’clerk’,’analyst’);
-- where子句 + 模糊查询
-- 查询名字中带a的员工
-- % 代表任意多个字符
select * from emp where ename like ‘%a%’;
-- _代表任意一个字符
select * from emp where ename like ‘_a%’; -- 任意一个字符
select * from emp where ename like ‘__a%’; -- 任意两个字符
-- 关于null的判断
select * from emp where comm is null;
select * from emp where comm is not null;
-- 小括号的使用
-- 因为不同运算符的优先级别不同,加括号为了可读性
-- 先 and ,再 or,以下两句等效
select * from emp where job = ‘salesman’ or job = ‘clerk’ and sal >=1500;
select * from emp where job = ‘salesman’ or (job = ‘clerk’ and sal >=1500);
--
select * from emp where (job = ‘salesman’ or job = ‘clerk’) and sal >=1500;
4.3 分组聚合查询
分组聚合查询是通过把聚合函数(如count(),sum()等)添加到一个带有group by 分组子句的select语句中实现的。
1. 使用聚合函数查询
count([distinct|all] *) 统计数据表中的记录数
count([distinct|all] <列名>) 统计数据表的一列中值的个数
max([distinct|all] <列名>) 求数据表的一列中值的最大值
min([distinct|all] <列名>) 求数据表的一列中值的最小值
sum([distinct|all] <列名>) 计算数据表的一列中值的总和
avg([distinct|all] <列名>) 计算数据表的一列中值的平均值
distinct表示在计算时要取消指定列中的重复值。
除函数count(*)外,其余聚合函数都会忽略空值!
-- 查询学生表中学生总人数
select count(*) from tb_student;
-- 查询几门选修课成绩表中学生人数,学生可选修多门课
select count(distinct studentid) from tb_score;
-- 计算选修课程编号2100的学生平均成绩
select avg(score) from tb_score where courseid = ’2100’;
2. 分组聚合查询
select语句中使用group by子句对数据进行分组运算。分组运算的目的是为了细化聚合函数的作用对象。如果不对查询结果分组,聚合函数作用于整个查询结果;分组后,聚合函数则分别作用于每个组,查询结果按组聚合输出。
group by 字段列表 [having <条件表达式>]
group by 对查询结果按字段列表进行分组,字段值相等的记录分为一组;指定用于分组的字段列表可以是一列,也可以是多个列,彼此间用逗号分隔;having短语对分组的结果进行过滤,仅输出满足条件的组。
注意:使用group by子句后,select子句的目标列表达式中只能包含group by子句中的字段列表和聚合函数
select courseid,count(studentid) from tb_score group by courseid;
– 若在select语句中使用表达式,则必须在group by中指定相同的表达式,不能使用别名
– 除聚合函数外,select子句中的每个列都必须在group by中给出
– 若用于分组的列中含有null值,则null将作为一个单独的分组返回;若该列中存在多个null值,将这些null值所在的行分为一组。
-- 查询平均分在80以上的每个同学的选课门数、平均分和最高分
select studentid,count(*) 选课门数,avg(score),max(score) from tb_score
group by studentid
having avg(score)>=80;
-- 查询有2门以上(含2门)课程成绩大于88分的学生学号及(88分以上的)课程数
select studentid,count(*) from tb_score
where score >= 88
group by studentid
having count(*)>=2;
-- where 作用于基本表或视图,having作用于分组后的每个组
-- where不可包含聚合函数,having可以包含聚合函数
-- where在分组前进行过滤,having在分组后进行过滤
-- 查询所有学生选课的平均成绩,输出平均成绩大于80的成绩
select avg(score) from tb_score having avg(score)>80;
函数的分类
MySQL中提供了大量函数来简化用户对数据库的操作,如字符串的处理、日期的运算、数值的运算等等。使用函数可以大大提高SELECT语句操作数据库的能力,同时也给数据的转换和处理提供了方便。(在sql中使用函数)
函数只是对查询结果中的数据进行处理,不会改变数据库中数据表的值。MySQL中函数主要分为单行函数和多行函数两大类。
单行函数
是指对每一条记录输入值进行计算,并得到相应的计算结果,然后返回给用户,就是说,每条记录作为一个输入参数,经过函数计算得到每条记录的计算结果。
常用的单行函数主要包括字符串函数、数值函数、日期与时间函数、流程函数以及其他函数。
多行函数
是指对一组数据进行运算,针对这一组数据(多行记录)只返回一个结果,也称为分组函数。
-- 函数举例
select empno,ename,lower(ename),upper(ename),sal from emp;
select max(sal),min(min),count(sal),sum(sal),avg(sal) from emp;
-- lower(ename),upper(ename) 改变每一条结果,每条数据对应每条结果
-- max(sal),min(min),count(sal),sum(sal),avg(sal) 多条数据,最终展现一个结果
PS:除了多行函数(max,min,count,sum,avg),都是单行函数
### 20.1 单行函数
-- 1. 字符串函数 (Sting StringBuilder)
select ename,length(ename),substring(ename,2,3) from emp;
-- substring 截取字符串从下标2开始的3个字符 (下标从1开始数)
-- 2. 数值函数(Math)
select abs(-5),ceil(5.3),floor(5.9),round(3.14) from dual; -- dual 实际上是一个伪表
select abs(-5) 绝对值,ceil(5.3) 向上取整,floor(5.9) 向下取整,round(3.14) 四舍五入; -- 若没有where条件,from dual可以省略不写
select ceil(sal) from emp;
select 10/3,10%3,mod(10,3);
-- 3. 日期与时间函数
select curdate(),curtime();
select now(),sysdate(),sleep(3),now(),sysdate() from dual;
insert into emp values(9999,’lily’,’salesman’,7698,now(),1000,null,30);
-- now()可以表示年月日时分秒,但是插入数据时还是要参照表的结构
-- 4. 流程函数 (IF SWITCH)
-- if 相关
select empno,ename,sal,if(sal>=2500,’高薪’,’低薪’) as ‘薪资等级’ from emp; -- if-else 双分支结构
select empno,ename.sal,comm,sal+ifnull(comm,0) from emp; -- 若comm是null,取值为0 -- 单分支
select nullif(1,1),nullif(1,2) from dual; -- 若value1等于value2,返回null,否则返回value1
-- case 相关
-- case等值判断
select empno,ename,job,
case job
when ‘clerk’ then ‘店员’
when ‘salesman’ then ‘销售’
when ‘manager’ then ‘经理’
else ‘其他’
end ‘岗位’,
sal from emp;
-- case区间判断
select empno,ename,sal,
case
when sal<=1000 then ‘A’
when sal<=2000 then ‘B’
when sal<=3000 then ‘C’
else ‘D’
end ‘工资等级’,
deptno from emp;
-- 5. JSON函数
-- 6. 其他函数
select database(),user(),version() from dual;
##### 2 多行函数
-- max(),min(),count()针对所有类型
-- sum(),avg()只针对数值类型有效
select max(ename),min(ename),count(ename),sum(ename),avg(ename) from emp;
-- count 计数
-- 统计表的记录数:方式一
select count(*) from emp;
select count(ename) from emp;
-- 统计表的记录数:方式二
select 1 from dual;
select 1 from emp;
select count(1) from emp;
###### 分组 group by
-- 统计各个部门的平均工资
select deptno,avg(sal) from emp; -- 字段和多行函数不可同时使用
select deptno,avg(sal) from emp group by deptno;
select deptno,avg(sal) from emp group by deptno order by deptno desc;
-- 统计各个岗位的平均工资
select job,avg(sal) from emp group by job;
###### having分组后筛选
-- 统计各个部门的平均工资,只显示平均工资2000以上的
-- 分组以后进行二次筛选 having
select deptno,avg(sal) from emp group by deptno having avg(sal) > 2000;
select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资 > 2000;
select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资 > 2000 order by deptno desc;
-- 统计各个岗位的平均工资,除了manager
-- 方法1:
select job,avg(sal) from emp where job != ‘manager’ group by job;
-- 方法2:
select job,avg(sal) from emp group by job having job != ‘manager’;
-- where是在分组前进行过滤,having在分组后进行过滤
#### 单表查询总结
1】 select 语句总结
select column,group_function(column)
from table
[where condition]
[group by group_by_expression]
[having group_condition]
[order by column];
注意:顺序固定,不可以改变
2】 select语句的执行顺序
from -- where -- group by -- select - having - order by
3】 单表查询总结练习
-- 列出工资最小值小于2000的职位
-- 列出平均工资大于1200的部门和工作搭配组合
-- 列出人数小于4的部门的平均工资
-- 列出各部门的最高工资,排除最高工资小于3000的部门
select job,min(sal) from emp group by job having min(sal)<2000; -- 每个职位都有工資最小值
select deptno,job,avg(sal)
from emp
group by deptno,job
having avg(sal)>1200
order by deptno;
select deptno,count(1),avg(sal)
from emp
group by deptno
having count(1)<4;
select deptno,max(sal)
from emp
group by deptno
having max(sal)>=3000;
4.4 连接查询
一个查询同时涉及两个或多个表,则称为连接查询。
包括交叉连接、内连接和外连接。当两个或多个表中存在相同意义的字段时,便可通过这些字段对相关的表进行连接查询。
1. 交叉连接
交叉连接(cross join)又称笛卡尔积,即把一张表的每一行与另一张表的每一行连接起来,返回两张表的每一行相连接后所有可能的搭配结果,其连接结果会产生一些没有意义的记录,所以实际很少使用。
2. 内连接
内连接(inner join)通过在查询中设置连接条件来移除交叉连接查询结果集中某些数据行。
内连接就是使用比较运算符进行表间某(些)字段值的比较操作,并将与连接条件相匹配的数据行组成新的记录,其目的是为了消除交叉连接中某些没有意义的数据行。就是说,在内连接查询中,只有满足条件的记录才能出现在结果集中。
内连接对应的SQL语句有两种表示形式:
- 使用inner join的显示语法结构为:
select 目标列表达式1,目标列表达式2,...,目标列表达式n
from table1 [inner] join table2
on 连接条件
[where 过滤条件];
- 使用where子句定义连接条件的隐式语法结构:
select 目标列表达式1,目标列表达式2,...,目标列表达式n
from table1,table2
where 连接条件 [and 过滤条件];
- 等值与非等值连接
连接查询中用来连接两个表的条件称为连接条件,一般格式为:
[<表名1>.]<字段名1> <比较运算符> [<表名2>.]<字段名2>
当比较运算符为“=”时表示等值连接,其他运算符为非等值连接。
连接条件中的字段名称为连接字段,连接条件中的各连接字段类型必须是可比的,但不一定要相同。
-- 查询每个学生选修课程的情况
select s.*,c.*
from tb_student s,tb_score c
where s.studentid = c.studentid;
或
select s.*,c.*
from tb_student s inner join tb_score c
on s.studentid = c.studentid;
使用where子句定义连接条件比较简单明了,inner join连接是ansi sql的标准规范,能够确保不会忘记连接条件。
-- 查询会计学院全体同学的学号、姓名、籍贯、班级编号和所在班级名称
select studentid,name,native,s.classid,classname
from tb_student s,tb_class c
where s.classid = c.classid and department = ‘会计学院’;
select studentid,name,native,s.classid,classname
from tb_student s join tb_class c
on s.classid = c.classid
where department = ‘会计学院’;
内连接是系统默认的表连接,可以省略inner,只用join。
涉及多个表的相同字段名,必须在相同的字段名前加上表名加以区分。
-- 查询选修了课程名称为“程序设计”的学生学号、姓名和成绩
select s.studentid,studentname,score
from tb_student s,tb_course c,tb_score sc
where s.courseid = c.courseid and s.studentid = sc.studentid
and coursename = ‘程序设计’;
select s.studentid,studentname,score
from tb_student s join tb_course c join tb_score sc
on s.courseid = c.courseid and s.studentid = sc.studentid
where coursename = ‘程序设计’;
注意,如果在from子句中指定了表别名,那么所在的select语句的其他子句都必须使用表别名来代替原来的表名。当同一个表在select语句中多次被使用时,必须使用表别名加以区分。
- 自连接
某个表与自身进行连接,称为自表链接或自身连接,简称自连接。使用自连接时,需要为表指定多个不同的别名,且对所有查询字段的引用均必须使用表别名限定,否则select操作会失败。
-- 查询与“数据库”这门课学分相同的课程信息
select c1.*
from tb_course c1,tb_course c2
where c1.credit = c2.credit and c2.coursename = ‘数据库’;
select c1.*
from tb_course c1 join tb_course c2
on c1.credit = c2.credit
where c2.coursename = ‘数据库’;
查询结果仍然包含“数据库”这门课,若要去掉这条记录,只需在where子句中增加一个条件 c1.coursename != ‘数据库’ 即可。
- 自然连接
自然连接(natural join)只有当连接字段在两张表中的字段名都相同时才可以使用,否则返回笛卡尔积的结果集。关键字使用natural join。
使用natural join进行自然连接时,不需要指定连接条件,系统自动根据两个表中相同的字段名来连接。
3. 外连接
连接查询是要查询多个表中相关联的行,内连接查询只返回查询结果集合中符合查询条件(即过滤条件)和连接条件的行。但有时候查询结果也需要显示不满足连接条件的记录,即返回的查询结果集中不仅包含符合连接条件的行,而且还包括两个连接表中不符合连接条件的行。
外连接首先将连接的两张表分为基表和参考表,然后再以基表为依据返回满足和不满足连接条件的记录,就好像是在参考表中增加了一条全部由空值组成的万能行,它可以和基表中所有不满足连接条件的记录进行连接。
外连接根据连接表的顺序,可分为左外连接和右外连接两种。
- 左外连接
也称左连接(left outer join或 left join),用于返回该关键字左边表(基表)的所有记录,并用这些记录与该关键字右边表(参考表)的记录进行匹配。若左表记录在右表没有匹配,就和右表万能行连接,即右表对应字段值设置为空值null。
-- 查询所有学生及其选修课程的情况,包括没有选修课程的学生,显示学号姓名性别班号选修的课程号和成绩
select s.studentid,studentname,sex,class,courseid,score
from tb_student s left join tb_score c
on s.studentid = c.studentid;
- 右外连接
right outr join 或 right join,同理。
-- 查询所有学生及其选修课程的情况,包括没有选修课程的学生,显示学号姓名性别班号选修的课程号和成绩
select s.studentid,studentname,sex,class,courseid,score
from tb_score c right join tb_student s
on s.studentid = c.studentid;
4.5 子查询
子查询也称嵌套查询,是将一个查询语句嵌套在另一个查询语句的where子句或having短语中。前者被称为内层查询或子查询,后者被称为外层查询或父查询。在整个select语句中,先计算子查询,然后将子查询结果作为父查询的过滤条件。
1. 带 in 关键字的子查询
最常用的一类子查询,用于判定一个给定值是否存在于子查询的结果集中。使用in关键字进行子查询时,内层查询语句仅仅返回一个数据列,其值将提供给外层查询进行比较操作。
-- 查询选修了课程的学生姓名
-- 在学生表tb_student中,将学号出现在成绩表tb_score中的姓名查询出来
select s.studentname from tb_student s
where s.studentid in
(select distinct tb_score.studentid from tb_score);
-- 可以用连接查询来改写
select distinct studentname
from tb_student s , tb_score c
where s.studentid = c.studentid;
-- 查询没有选修过课程的学生姓名
select studentname from tb_student
where tb_student.studentid not in
(select distinct tb_score.studentid from tb_score);
注意:表示否定的查询不能用连接查询来改写
2. 带比较运算符的子查询
带比较运算符的子查询是指父查询与子查询之间用比较运算符进行连接。当用户能确切知道内层查询返回的是单值时,可以用比较运算符构造子查询。
-- 查询班级计算机141班所有学生的学号姓名
select studentid,studentname from tb_student
where claassid =
(select classid from tb_class where classname = ‘计算机141班’);
这类查询都可以用连接查询来改写
-- 查询与黎明在同一个班学习的学生学号姓名班号
select studentid,studentname,classid
from tb_student s1
where classid =
(select classid from tb_student s2 where studentname = ‘limin’) and studentname != ‘limin’;
比较运算符还可以与all、some和any关键字一起构造子查询。all、some和any 用于指定比较运算的限制:all 用于指定表达式需要与子查询结果集中的每个值都进行比较,当表达式与每个值都满足比较关系时,会返回 True,否则 False;some 和 any 是同义词,表示表达式与子查询结果集中的某个值满足比较关系时,就返回 True。
-- 查询男生中比某个女生出生年份晚的学生姓名和出生年份
select studentname,year(birthday)
from tb_student
where sex = ‘male’ and year(birthday) > any(
select year(birthday) from tb_student where sex = ‘female’
);
-- 查询男生中比所有女生出生年份晚的学生姓名和出生年份
select studentname,year(birthday)
from tb_student
where sex = ‘male’ and year(birthday) > all(
select year(birthday) from tb_student where sex = ‘female’
);
用聚合函数实现子查询比直接用all或any效率要高!!!
select studentname,year(birthday)
from tb_student
where sex = ‘male’ and year(birthday) > (
select min(year(birthday)) from tb_student where sex = ‘female’
); -- 某个女生的
3. 带 exists 关键字的子查询
系统对子查询进行运算以判断它是否返回结果集。若子查询的结果集不为空,则返回结果为True,此时外层查询语句将进行查询;反之,返回False,外层语句不进行查询。
由于带 exists 关键字的子查询只返回True或False,内层查询的select子句给出字段名没有实际意义,所以目标表达式通常用星号 * 。
-- 查询选修了课程号为31002的学生姓名
select studentname from tb_student a
where exists
(select * from tb_score b
where a.studentid = b.studentid and courseid = ’31002’);
-- 等价于用in构造的子查询
select studentname from tb_student a
where studentid in
(select * from tb_score b
where a.studentid = b.studentid and courseid = ’31002’);
4.6 联合查询(UNION)
使用union关键字可把来自多个select语句的结果组合到一个结果集中,这种查询方式称为并运算或联合查询。合并时,多个select子句中对应的字段数和数据类型必须相同。
select - from - where
union [all]
select - from - where
[...union [all]
select - from - where]
不是用关键字all,执行的时候去掉重复的记录,所有返回的行都是唯一的;使用all是不去掉重复的记录,也不对结果进行自动排序。
-- 使用union查询选修了管理学或计算机基础的学生学号
select studentid
from tb_score s,tb_course c
where s.courseid = c.courseid and coursename = ‘管理学’
union
select studentid
from tb_score s,tb_course c
where s.studentid = c.studentid and coursename = ‘计算机基础’;
-- 等价于
select distinct studentid
from tb_student s,tb_course c
where s.studentid = c.studentid and (coursename = ‘管理学’ or coursename = ‘计算机基础’);
-- 使用union all查询选修了管理学或计算机基础的学生学号
select studentid
from tb_score s,tb_course c
where s.courseid = c.courseid and coursename = ‘管理学’
union all
select studentid
from tb_score s,tb_course c
where s.studentid = c.studentid and coursename = ‘计算机基础’;
-- 等价于
select studentid
from tb_student s,tb_course c
where s.studentid = c.studentid and (coursename = ‘管理学’ or coursename = ‘计算机基础’);
注意:
- union 语句每个select子句必须包含相同的列、表达式或聚合函数
- 每个select子句对应的目标列的数据类型必须兼容
- 第一个select子句的目标列会被作为union语句结果集的列名称
- 联合查询只能使用一条order by子句或limit子句,且它们必须置于最后一条select语句后
union联合查询相当于集合操作中的并运算。MySQL中交运算和差运算只能用子查询来实现。
-- 查询选修了计算机基础和管理学的学生学号
select studentid
from tb_score s,tb_course c
where s.courseid = c.courseid and coursename =’计算机基础’
and studentid in (select studentid
from tb_score s,tb_course c
where s.courseid = c.courseid and coursename=’管理学’);
-- 选修了计算机基础但没有选管理学的学生学号
select studentid
from tb_score s,tb_course c
where s.courseid = c.courseid and coursename =’计算机基础’
and studentid not in (select studentid
from tb_score s,tb_course c
where s.courseid = c.courseid and coursename=’管理学’);
多表查询99语法
交叉连接、自然连接、内连接
1】内连接引入
实际开发中往往需要针对两张甚至更多张数据表进行操作,而这多张表之间需要使用主键和外键关联在一起,然后使用连接查询来查询多张表中满足要求的数据记录。
一条SQL语句查询多个表,得到一个结果,包含多个表的数据。效率高。在SQL99中,连接查询需要使用join关键字实现。
提供了多种连接查询的类型:cross natural using on
交叉连接(CROSS JOIN)是对两个或多个表进行笛卡尔积操作。所谓笛卡尔积就是关系代数里的一个概念,表示两个表中的每一行数据任意组合的结果。如,有两个表,左表有m条数据记录,x个字段,右表有n条数据记录,y个字段,则执行交叉连接后将返回m*n条数据记录,x+y个字段。笛卡尔积示意图如图所示。
2】 SQL展示
-- 查询员工编号,姓名和部门编号
select empno,ename,deptno from emp;
-- 查询员工编号,姓名和部门编号,部门名称
select * from emp;
select * from dept;
-- 多表查询
-- 交叉查询:cross join
select *
from emp
cross join dept; -- 14*4=56 条数据 笛卡尔乘积:没有实际意义,有理论意义,有些数据实际上是无效的
select *
from emp
join dept; -- mysql 中cross 可省略不写,Oracle不可以
-- 自然连接:natural join
-- 优点:自动匹配所有的同名列,同名列只展示一次;简单
select *
from emp
natural join dept;
select empno,ename,sal,dname,loc
from emp
natural join dept;
-- 缺点:查询字段时,没有指定字段所属的数据库表,效率低
-- 解决:指定表名:
select emp.empno,emp.ename,dept.dname,dept.loc,dept.deptno
from emp
natural join dept;
-- 缺点:表名太长了
-- 解决:表起别名:
select e.empno,e.ename,d.dname,d.loc,e.deptno
from emp e
natural join dept d;
-- 自然连接 natural join
-- 缺点:自动匹配表中所有的同名列,但有时候只希望匹配部分同名列
-- 解决:内连接 - using 子句:
select *
from emp e
inner join dept d -- inner可不写
using(deptno); -- 这里不能写natural join,这里是内连接
-- using 缺点:关联的字段,必须是同名的
-- 解决:内连接 - on 子句:
select *
from emp e
inner join dept d
on (e.deptno = d.deptno);
-- 多表连接查询的类型:
-- 1.交叉查询 cross join 2.自然连接 natural join 3.内连接-using子句 4.内连接-on子句
-- 综合看,内连接-on子句 用得最多
select *
from emp e
inner join dept d
on (e.deptno = d.deptno)
where sal > 3500;
-- 条件:
-- 1.筛选条件: where having
-- 2.连接条件:on,using,natural join
-- SQL99语法:筛选条件和连接条件是分开的
### 24.2 外连接查询
-- inner join - on子句 :显示的是所有匹配的信息
select *
from emp e
inner join dept d
on (e.deptno = d.deptno);
select * from emp;
select * from dept;
-- 问题
-- 1.40号部门没有员工,没有显示在查询结果中
-- 2.员工若没有部门,无法显示在查询结果中
-- 外连接:除了显示匹配的数据之外,还可以显示不匹配的数据
-- 左外连接:left outer join :左边的表的信息,即使不匹配,也可全部显示
select *
from emp e
left outer join dept d
on e.deptno = d.deptno;
-- 右外连接:right outer join :右边的表的信息,即使不匹配,也可全部显示
select *
from emp e
right outer join dept d
on e.deptno = d.deptno;
-- 全外连接:full outer join :MySQL不支持,Oracle支持。两边表的信息,即使不匹配,也可全部显示
select *
from emp e
full outer join dept d
on e.deptno = d.deptno;
-- 解决MySQL中不支持全外连接的问题
select *
from emp e
left outer join dept d
on e.deptno = d.deptno
union -- 并集 去重 效率低
select *
from emp e
right outer join dept d
on e.deptno = d.deptno;
select *
from emp e
left outer join dept d
on e.deptno = d.deptno
union all-- 并集 不去重 效率高
select *
from emp e
right outer join dept d
on e.deptno = d.deptno;
-- MySQL中对集合操作支持较弱,只支持并集操作,差集、交集不支持。Oracle支持
-- outer可以省略不写
### 24.3 三表连接查询
-- 查询员工编号、姓名、薪水、部门编号、部门名称、薪水等级
select * from emp;
select * from dept;
select * from salgrade;
select * e.empno,e.ename,e.sal,d.deptnp,d.dname,s.*
from emp e
inner join deptno d
on e.deptno = d.deptno
inner join salgrade s
on e.sal between s.losal and s.hisal;
### 24.4 自连接查询
-- 查询员工编号、姓名、上级编号、上级姓名
-- 自关联,自己和自己的关联
select e1.empno,e1.ename 员工姓名,e1.mgr,e2.ename 员工领导姓名
from emp e1
inner join emp e2
on e1.mgr = e2.empno;
-- 还有一个领导没有上级没显示
-- 左外连接
select e1.empno,e1.ename 员工姓名,e1.mgr,e2.ename 员工领导姓名
from emp e1
left join emp e2
on e1.mgr = e2.empno;
多表查询92语法
-- 查询员工编号,姓名,薪水,部门编号,部门名称
select e.empno,e.ename,e.sal,e.deptno,d.dname
from emp e,dept d;
-- 相当于99语法中的cross join,出现笛卡尔积,没有意义
select e.empno,e.ename,e.sal,e.deptno,d.dname
from emp e,dept d
where e.deptno = d.deptno;
-- 相当于99语法中的natural join
-- 查询员工编号,姓名,薪水,部门编号,部门名称,工资大于2000的员工
select e.empno,e.ename,e.sal,e.deptno,d.dname
from emp e,dept d
where e.deptno = d.deptno and e.sal > 2000;
-- 查询员工姓名,岗位,上级编号,上级名称(自连接)
select e1.ename,e1.job,e1.mgr,e2.ename
from emp e1,emp e2
where e1.mgr = e2.empno;
-- 查询员工编号、姓名、薪水、部门编号、部门名称、薪水等级
select e.empno,e.ename,e.sal,e.depno,d.dname,s.grade
from emp e,dept d,salgrade s
where e.deptno = d.deptno and e.sal >=losal and e.sal <=hisal;
-- 总结:
-- 1.92语法麻烦
-- 2.92语法中,表的连接条件和筛选条件 是放在一起的,没有分开
-- 3.99语法中,提供了更多的查询连接类型:cross,natural,inner,outer
子查询 - 不相关子查询
1. 什么是子查询
一条SQL语句含有多个select
-- 引入子查询
-- 查询所有比’clark’工资高的员工的信息
-- 步骤1:查询clark工资
select sal from emp where ename = ‘clark’; -- 2450
-- 步骤2:查询所有比’clark’工资高的员工的信息
select * from emp where sal > 2450;
-- 两次命令解决问题 -》 效率低
-- 第二个命令依托于第一个命令,第一个命令的结果给第二个命令使用
-- 第一个命令的结果可能不确定要改,第二个命令也会导致修改
-- 将步骤1和步骤2合并 -》子查询
select * from emp where sal > (select sal from emp where ename = ‘clark’);
-- 一个命令解决问题 -》效率高
2. 执行顺序
先执行子查询,再执行外查询
3. 不相关子查询
子查询可以独立运行,称为不相关子查询
4. 不相关子查询分类
根据子查询的结果行数,可以分为单行子查询和多行子查询。
### 26.1 单行子查询
-- 单行子查询
-- 查询工资高于平均工资的雇员名字和工资
-- 查询和clark同一部门且比他工资低的雇员名字和工资
-- 查询职务和Scott相同,比Scott雇佣时间早的雇员信息
select ename,sal
from emp
where sal > (select avg(sal) from emp);
select ename,sal
from emp
where deptno = (select deptno from emp where ename = ‘clark’)
and
sal < (select sal from emp where ename = ‘clark’);
select *
from emp
where job = (select job from emp where ename = ‘scott’)
and hiredate < ( select hiredate from emp where ename = ‘scott’);
### 26.2 多行子查询
-- 多行子查询
-- 1】 查询部门20中职务同部门10的员工一样的员工信息
-- 查询员工信息
select * from emp;
-- 查询部门20中的员工信息
select * from emp where deptno = 20;
-- 查询部门10中的员工的职务
select job from emp where deptno = 10;
-- 查询部门20中职务同部门10的员工一样的员工信息
select * from emp
where deptno = 20
and job in (select job from emp where deptno = 10);
select * from emp
where deptno = 20
and job = any(select job from emp where deptno = 10);
-- 2】 查询工资比所有的salesman都高的员工编号,名字和工资
-- 查询员工编号,名字和工资
select empno,ename,sal from emp;
-- salesman 工资
select sal from emp where job = ‘salesman’;
-- 查询工资比所有的salesman都高的员工编号,名字和工资
-- 多行子查询
select empno,ename,sal from emp
where sal > all(select sal from emp where job = ‘salesman’);
-- 单行子查询
select empno,ename,sale from emp
where sal > (select max(sal) from emp where job = ‘salesman’);
-- 3】 查询工资低于任意一个clerk的工资的员工信息
-- 查询员工信息
select * from emp;
-- 查询工资低于任意一个clerk的工资的员工信息
-- 多行子查询
select * from emp
where sal < any(select sal from emp where job = ‘clerk’)
and job != ‘clerk’;
-- 单行子查询
-- 任意一个都要小,如,1000,1200,比1200小也是任意一个小
select * from emp
where sal < ( select max(sal) from emp where job = ‘clerk’)
and job != ‘clerk’;
## 27. 相关子查询
1】 不相关子查询 引入
不相关子查询:子查询可以独立运行,先运行子查询,再运行外查询。
相关子查询:子查询不可以独立运行,并且先运行外查询,再运行子查询
2】 不相关子查询 优缺点
优点:简单 功能强大(一些使用不相关子查询不能实现或者实现繁琐的子查询,可以使用相关子查询实现)
缺点:稍难理解
-- 查询最高工资的员工 (不相关子查询)
select * from emp where sal = (select max(sal) from emp);
-- 查询本部门最高工资的员工 (相关子查询)
-- 方法1:通过不相关子查询实现
select * from emp where deptno = 10 and sal = ( select max(sal) from emp where deptno = 10)
union
select * from emp where deptno = 20 and sal = ( select max(sal) from emp where deptno = 20)
union
select * from emp where deptno = 30 and sal = ( select max(sal) from emp where deptno = 30);
-- 缺点:语句比较多,具体有多少个部门未知
-- 方法2:相关子查询
select * from emp e where sal = (select max(sal) from emp where deptno = e.deptno) order by deptno;
-- 查询工资高于所在岗位平均工资的员工 (相关子查询)
select * from emp e
where sal >= (select max(sal) from emp where job = e.job) order by job;
-- 一些部门若只有一个员工的话,等于号可以将其显示出来
5. 数据更新
5.1 插入数据
MySQL使用insert或replace插入数据,方式有:插入完整数据记录、插入记录的一部分、插入多条记录、插入另一个查询的结果等。
插入数据之前应使用use将需要插入记录的表所在的数据库指定为当前数据库。
insert into tb_name [(column_list)] value(value_list1)[,(value_list2)...(value_listn)];
tb_name指定要插入数据的表名,column_list指定要插入数据的字段,value_list指定每个字段对应插入的数据。
DML_添加数据
Navicat中查询-新建查询,命名test。
-- 查看表记录
select * from student;
-- 在 student 表中插入数据
insert into student values (1,’zhang’,’男’,18,’2022-4-6’,’class 1’,’dsgs@mail.com’);
insert into student values (76541,’zhang’,’男’,18,’2022-4-6’,’class 1’,’dsgs@mail.com’);
insert into student values (44,’zhang’,’男’,18,’2022.4.6’,’class 2’,’dsgs@mail.com’);
insert into student values (76,”zhang”,’男’,18,’2022-4-6’,’class 1’,’dsgs@mail.com’);
insert into student values (765,’zhang’,’男’,18,now(),’class 2’,’dsgs@mail.com’);
insert into student (name,age,class) values (’zhang’,18,’class 1’);
注意事项:
1)int 宽度是显示宽度,若超过,可以自动增大宽度,int 底层都是4个字节。
2)时间的方式多样,’2021-12-25’ “2021/12/25” “2021.12.25”。
3)字符串不区分单引号和双引号。
4)如何写入当前的时间,now() sysdate() CURRENT_DATE()。
5)char varchar 是字符的个数,可以使用 binary、varbinary 表示定长和不定长的字节个数。
6)若不是全字段插入数据的话,需要加入字段的名字。
– 插入查询的结果
insert into tb_name1 (column list1)
select (column_list2) from tb_name2 where (condition);
select子句返回的是一个查询结果集,insert语句将这个结果集插入到指定表中,其中,结果集的每行数据的字段数、字段的数据类型必须与被操作的表完全一致。
insert into tb_studentcopy (studentid,name,sex,nation)
select studentid,name,sex,nation from tb_student;
– 使用 replace 语句插入表数据
若一个待插入的表中存在有primary key 或unique约束,而待插入的数据行中包含有与待插入表的已有数据行中相同的primary key 或unique列值,insert语句无法使用。使用replace可以在插入数据之前将表中与待插入的新记录相冲突的旧记录删除,从而保证新记录能够正常插入。
replace into tb_name (column_list) values (value_list);
replace into tb_student (studentid,name,sex) values (’2000101’,’Yoyo’,’M’);
-- 2000101相同id的记录被删除并替换成新记录
5.2 修改数据记录
update tb_name
set column1 = value1,column2 = value2,...,column1 = valuen
[where <conditions>];
set子句用于指定表中要修改的字段名及其值,column1,column2,…,column1 为指定修改的字段名称,value1, value2,…,valuen为相对应的指定字段修改后的值;每个指定的列值可以是表达式,也可以是该列所对应的默认值;如果指定的是默认值,则用关键字default表示列值。
-- 修改表中所有数据
update student set sex = ‘男’;
-- 修改表中指定数据
update student set sex = ‘w’ where number = 765;
UPDATE STUDENT SET SEX = ‘w’ WHERE NUMBER = 44;
update student set CLASS = ‘CLASS 1’ where number = 76; (修改成大写了)
update student set age = 30 where class = ‘CLASS 1’;(class 1 大小写都修改了)
-- 带子查询的修改
-- 将选修程序设计这门课程的学生成绩置零
update db_school.tb_score set score = 0
where courseno = (select courseno from tb_score where coursename = ‘程序设计’);
5.3 删除数据记录
delete from tb_name [where <condition>];
– 删除特定数据
delete from student where number = 1;
注意事项:
1)关键字、表名、字段名不区分大小写
2)默认情况下,内容不区分大小写
3)删除操作 from 关键字不可缺少
4)修改、删除操作要加限制条件
– 带子查询的删除
– 将程序设计这门课程的所有选课记录删除
delete from db.school.tb_score
where courseno = (select courseno from tb_score where coursename=’程序设计’);
– 删除所有记录
– delete from db_school.tb_score;
– delete语句删除的是表中的数据,而不会删除表中的定义
– truncate语句将直接删除原来的表并重新创建一个表,而不是逐行删除表中的记录,因此执行速度会比delete操作更快
– truncate语句会使表中auto_increment计数器被重新设置为该列的初始值
truncate [table] tb_name
--创建数据库表:
create table student (
number int(6) primary key auto_increment,
name varchar(10) not null,
sex char(1) default ‘M’ check(sex=’M’||sex=’F’),
age int(3) check(age>17 and age<51),
enterdate date,
class varchar(10),
email varchar(15) unique
);
-- 添加数据
insert into student values (1,’wang’,’F’,28,now(),’class 1’,’wang@126.com’);
insert into student values (2,’zhaol’,’M’,19,now(),’class 2’,’zhaol@126.com’);
insert into student values (3,’xusong’,’F’,32,now(),’class 1’,’xusong@126.com’);
-- 查看表
select * from student;
-- 添加一张表:快速添加:新表结构和数据跟原表一致:
create table student2
as
select * from student;
-- 快速添加:新表结构跟原表一致:
create table student3
as
select * from student where 1=2;
-- 快速添加:只要部分列,部分数据:
create table student2
as
select id,name,age from student where id = 2;
-- 删除数据操作:清空数据
delete from student;
truncate table student;
delete 和 truncate 的区别:
1) delete为数据操作语言DML;truncate为数据定义语言DDL。
2)delete是将表中所有记录一条一条删除直到删除完,truncate则是保留了表的结构,重新创建了这个表,所有的状态都相当于新表。因此,truncate的效率更高。
3) delete可以回滚,truncate会导致隐式提交,因此不能回滚。
4) delete执行成功后会返回已删除的行数(如 删除4行记录,会显示“Affect rows: 4”);截断操作truncate不会返回已删除的行量,结果通常是“Affect rows: 0”。delete删除表中记录后,再次向表中添加新记录时,对于设置有自增约束字段的值会从删除前表中该字段的最大值加1开始自增;truncate则会重新从1开始自增。
DQL_表的准备
准备四张表:dept(部门表),emp(员工表),salgrade(薪资等级表),bonus(奖金表)
create table DEPT(
deptno int(2) not null,
dname varchar(14),
loc varchar(13) -- location
);
alter table DEPT
add constraint pk_dept primary key (deptno);
create table EMP(
empno int(4) primary key,
ename varchar(10),
job varchar(9),
mgr int(4), -- manager
hiredate date,
sal double(7,2),
comm double(7,2), -- common 补助
deptno int(2)
);
alter table EMP
add constraint pk_deptno foreign key (deptno)
references DEPT (deptno);
create table SALGRADE(
grade int primary key,
losal double(7,2),
hisal double(7,2)
);
create table BONUS(
ename varchar(10),
job varchar(9),
sal double(7,2),
comm double(7,2)
);
insert into DEPT (deptno,dname,loc)
values (10,’accounting’,’new york’),
(20,’research’,’dallas’),
(30,’sales’,’chicago’),
(40,’operations’,’boston’);
insert into EMP values
(7369,’smith’,’clerk’,7902,’1999-12-01’,800,null,20),
(7499,’allen’,’salesman’,7698,’1999-12-28’,1600,300,30),
(7521,’ward’,’salesman’,7698,’1998-11-23’,1250,500,30),
(7566,’jones’,’manager’,7839,’2000-01-24’,2975,null,20),
(7654,’martin’,’salesman’,7698,’2000-01-10’,1250,1400,30),
(7698,’blake’,’manager’,7839,’2000-02-15’,2850,null,3),
(7782,’clark’,’manager’,7839,’2000-01-19’,2450,null,10),
(7788,’scott’,’analyst’,7566,’1997-12-02’,3000,null,20),
(7839,’king’,’president’,null,’1990-06-01’,5000,null,10),
(7844,’turner’,’salesman’,7698,’1999-07-15’,1500,0,30),
(7876,’adams’,’clerk’,7788,’1992-04-20’,1100,null,20),
(7900,’james’,’clerk’,7698,’1995-05-15’,950,null,30),
(7902,’ford’,’analyst’,7566,’1999-04-03’,3000,null,20),
(7934,’miller’,’clerk’,7782,’1993-08-23’,11300,null,10);
insert into SALGRADE values
(1,700,1200),(2,1201,1400),(3,1401,2000),
(4,2001,3000),(5,3001,9999);
select * from emp;
-- deptno 外键 参考 dept - deptno字段
-- mgr 外键 参考 自身表emp - empno 产生了自关联
select * from salgrade;
-- losal - lowsal
-- hisal - highsal
6. 索引
6.1 索引概述
对数据库中数据表进行查询操作时,系统对表中的数据主要有两种搜索扫描方式:一种是全表扫描、检索,另一种是利用数据表上建立的索引进行扫描。
全表扫描是将表中所有数据记录从头至尾逐行读取,与查询条件进行对比,返回满足条件的记录。
索引访问是通过搜索索引值,再根据索引值与记录的关系直接访问数据表中的记录行。例如,对学生表的姓名字段建立索引,即按照表中姓名字段的数据进行索引排序,并为其建立指向学生表中记录所在位置的“指针”。
根据用途,索引主要分为普通索引、唯一性索引、主键索引、聚簇索引和全文索引等。
1) 普通索引
普通索引(index)是最基本的索引类型。索引列值可以取空值或重复值。创建普通索引通常使用关键字 index 或 key 。
2) 唯一性索引
唯一性索引(unique)索引与普通索引基本相同,区别仅在于索引列值不能重复,即索引列值必须是唯一的,但可以是空值。创建唯一性索引所使用的关键字是unique。
3) 主键索引
在MySQL建立主键时,系统自动创建主键(primary key)索引。主键索引是一种唯一性索引。与唯一性索引的不同在于其索引值不能为空。
4) 聚簇索引
聚簇索引(clustered index)的索引顺序就是数据存储的物理存储顺序,这样能保证索引值相近的元组所存储的物理位置也相近。对于非聚簇索引,索引顺序与数据的物理排列顺序无关。一个表只能有一个聚簇索引。目前支持聚簇索引的引擎只有solidDB和InnoDB。
5) 全文索引
全文索引(fulltext)只能创建在数据类型为varchar或text的列上。全文索引只能在MyISAM存储引擎的表中创建。
实际使用中,索引可以建立在单一列上,称为单列索引。也可建立在多列上,称为组合索引。
1) 单列索引
一个索引只包含原表中的一个列。一个表上可以建立多个单列索引。
2) 组合索引
也称复合索引或多列索引。组合索引是指在表的多个列上创建一个索引。如,班级表中所属院系和年级两列上建立一个索引。此索引的含义是先按所属院系排序,若所在院系相同,则按年级排序。这就是最左前缀法则。
最左前缀法则,指先按照第一列(顺序排列位于最左侧的字段)进行排序,当第一列的值相同的情况下再对第二列排序,以此类推。
6.2 查看数据表上所建立的索引
使用 show index 可以查看数据表中是否建立了索引,以及所建立的索引类型及相关参数:
show {index|indexes|keys} {from|in} tb_name [{from|in} db_name]G;
索引信息:
- table:指明索引所在表的名称
- non_unique:该索引是否不是唯一性索引。若不是,则该列值为1;若是,为0。
- key_name:索引的名称。若是在创建索引的语句中使用primary key关键字,且没有明确给出索引名,系统会为其制定一个索引名称,primary。
- column_name:建立索引的列名称。
- collation:说明以何种顺序(升序或降序)索引。若是升序,则该列的值显示为A;若该列的值显示为null,则表示无分类。
– 屏幕显示项目较多,不易查看,可使用G参数
show index from db_school.tb_scoreG;
6.3 创建索引
三种创建索引的方法。一种是在创建表的同时创建索引,另外两种是已经存在的表上使用 create index语句创建索引,或使用alter table语句添加索引。
1. 使用create table 语句创建索引
create table tb_name [col_name data_type]
[constraint index_name] [unique] [index|key]
[index_name] (index_col_name [length]) [asc|desc]
- tb_name:指定需要建立索引的表名。
- index_name:指定所建立的索引名称。一个表上可以建立多个索引,而每个索引名称必须是唯一的。
- unique:可选项,指定所创建的是唯一性索引。
- index_col_name:指定要创建索引的列名。通常可考虑将查询语句中在where子句和join子句里出现的列作为索引列。
- length:指定使用列的前length个字符创建索引。使用列值的一部分创建索引有利于减小索引文件的大小,节省磁盘空间。blob或text类型的数据类型必须使用前缀索引。前缀最长为255个字节,对于MyISAM和InnoDB,前缀最长为1000个字节。
- asc:默认为asc。
-- 创建表的同时建立普通索引
create table tb_student(
studentno char(10) not null,
studentname varchar(20) not null,
sex char(1) not null,
birthday date,
classno char(6),
index(studentname)
);
-- 查看索引
show index;
-- 创建表的同时建立唯一性索引
create table tb_student2(
studentno char(10) not null unique,
studentname varchar(20) not null,
sex char(1) not null,
birthday date,
classno char(6),
);
-- 创建表的同时建立主键索引
create table tb_score2(
studentno char(10),
courseno char(5),
score float,
constraint pk_score primary key(studentno,courseno),
constraint fk_score1 foreign key(studentno) references as tb_student(studentno),
constraint fk_score2 foreign key (courseno) references as tb_course(courseno)
);
并非所有数据库管理系统都自动对主键、外键建立索引。
2. 使用 create index 语句创建索引
使用create index能够在一个已存在的表上创建索引
create [unique] index index_name
on tbl_name (col_name [(length)] [asc|desc],...)
– 创建普通索引
– 在数据库db_school的学生表tb_student建立一个普通索引,索引字段号是studentno
create index index_stu on db_school.tb_student (studentno);
– 查看索引
show index from db_school.tb_student;
– 创建基于字段值前缀字符的索引
– 在数据库db_school课程表tb_course建立一个索引,要求按课程名称coursename字段值前三个字符建立降序索引
create index index_course on db_school.tb_course(coursename(3) desc);
– 创建组合索引
– 在数据库db_school表tb_book建立图书类别(升序)和书名(降序)的组合索引,索引名称为index_book
create index index_book on db_school.tb_book (bclassno,bookname desc);
3. 使用 alter table 语句创建索引
alter table tbl_name add [unique|fulltext] [index|key] [index_name] (col_name [length] [asc|desc],...)
– 建立普通索引
– tb_student1表studentname列建立一个普通索引,名称
idx_studentname
alter table db_school.tb_student1 add index idx_studentname(studentname);
6.4 删除索引
1. 使用 drop index 语句创建索引
drop index index_name on tbl_name;
– 删除tb_student1表idx_studentname
drop index idx_studentname on db_school.tb_student1;
2. 使用 alter table 语句创建索引
alter table tb_name drop index index_name;
– 删除数据库db_school的表tb_student的索引index_stu
alter table db_school.tb_student drop index index_stu;
注意:
若删除表中某一列,而该列是索引项,则该列也会从索引中被删除。
若组成索引的所有列都被删除,则整个索引将被删除。
6.5 对索引的进一步说明
1.使用索引时的问题
1)降低更新表中数据的速度
2)增加存储空间
2.使用索引的建议
1)插入、修改、删除操作较多的数据表上避免过多地建立索引
2)数据量较小的表最好不要建立索引
3)使用组合索引时,严格遵循最左前缀法则,即先按照第一列(最左字段)进行排序,当第一列的值相同的情况下对第二列排序,依此类推。
4)在查询表达式中经常使用、有较多不同值的字段上建立索引
5)在where子句中尽量避免将索引列作为表达式的一部分。在使用like时,避免在开头使用通配符,如 like %aaa% 会使索引失效,而 like aaa% 子句可以使用索引
6)为提高索引效率,若char或varchar列的字符数很多,则可视具体情况选取字段值前n个字符值进行索引,即对索引列的前缀建立索引,可节约存储空间。
7. 视图
1】 视图的概念
视图(View)是一个从单张或多张基础数据表或其他视图中构建出来的虚拟表。同基础表一样,视图中也包含了一系列带有名称的列和行数据,但是数据库中只是存放视图的定义,也就是动态检索数据的查询语句,而不存放视图中的数据,这些数据依旧存放于构建视图的基础表中,只有当用户使用视图时才去数据库请求相对于的数据,即视图中的数据是在引用视图时动态生成的。因此视图中的数据依赖于构建视图的基础表,若基本表中的数据发生了变化,视图中相应的数据也会跟着改变。
2】 视图的优点
1.简化用户操作:视图可以使用户将注意力集中在所关心的数据上,而不需要关心数据表的结构、与其他表的关联条件以及查询条件等。
2.对机密数据提供安全保护:有了视图,可以在设计数据库应用系统时,对不同的用户定义不同的视图,避免机密数据(如,敏感字段“salary”)出现在不应该看到这些数据的用户视图上。这样视图就自动提供了对机密数据的安全保护功能。
7.2 创建视图
create [or replace]
view view_name [(column_list)]
as select_statement
[with [cascaded|local] check option]
- or replace:用于替换数据库中已有的同名视图,但需要在该视图上具有drop权限
- column_list:可以为视图中每个列指定明确的名称。列名的数目必须等于select语句检索出的结果数据集的列数,每个列名用逗号分隔。若无此项,则新建视图使用与基础表或源视图中相同的列名
- select_statement:用于指定创建视图的select语句。给出了视图的定义,可用于查询多个基础表或源视图。存在一些限制:
1)定义视图的用户除了要求被授予create view的权限外,还必须被授予可以操作视图所涉及的基础表或其他视图的相关权限
2)select语句不能包含from子句中的子查询
3)select语句不能引用系统变量或用户变量
4)select语句不能引用预处理语句参数
5)select语句引用的表或视图必须存在。但创建视图后,可以删除视图定义中所引用的表或视图。若想检查视图定义是否存在这类问题,可使用check table语句
6)select语句引用的非当前数据库的表或视图,需要在该表或视图前加上数据库的名称作为限定前缀
7)select语句允许使用order by子句。弱引用的视图使用了自己的order by语句,则视图定义的order by将被忽略
8)select语句的其他选项或子句,若所创建的视图中也包含了这些选项,则语句执行效果未定义 - with check option:用于指定在可更新视图上所进行的修改都需要符合select_statement中所指定的限制条件,这样可确保数据修改后仍可以通过视图看到修改后数据。 当视图是根据另一个视图定义时,with check option给出两个参数,决定检查测试的范围。cascaded 为选项默认值,会对所有视图进行检查,local 则只对定义的视图进行检查。
– 在数据库db_school创建视图v_student,要求包含客户信息表tb_student所有男生的信息,并且要求保证今后对该视图数据的修改都必须符合学生性别为男性
create or replace view db_school.v_student
as
select * from tb_student where sex =’m’
with check option;
– 在数据库db_school创建视图db_score.v_score_avgs,要求该视图包含表中所有学生的学号和平均成绩,并按学号studentno进行排序
create view db_score.v_score_avgs(studentno,score_avg)
as
select studentno,avg(score)
from tb_score
group by studentno;
7.3 删除视图
drop view [if exists]
view_name[,view_name1]...
drop view [if exists] db_school.v_student;
7.4 修改视图定义
alter view view_name [(column_list)]
as select_statement
[with [cascaded|local] check option]
alter view的使用,需要用户具有针对视图的create view 和 drop权限,以及由 select语句选择的每一列上的某些权限
– 使用alter view语句修改数据库db_school视图v_student定义,要求包含学生表中性别为男民族为汉的学生学号、姓名和所属班级,且要求保证今后对该视图数据的修改都必须符合学生性别为男、民族为汉这个条件
alter view db_school.v_student
as select studentno,studentname,classno from db_school.tb_student
where sex=’m’ and nation=’han’
with check option;
create or replace view db_school.v_student
as select studentno,studentname,classno from db_school.tb_student
where sex=’m’ and nation=’han’
with check option;
7.5 查看视图定义
show create view view_name
mysql中,使用G可以改变输出结果集的显示方式,按列显示;使用G后,SQL语句可以不加分隔符,加分隔符会报错。
– 查看数据库视图v_score的定义
– show create view db_school.v_score G
7.6 更新视图数据
视图是一个虚拟表,所以通过插入、修改和删除等操作来更新视图中的数据,实质上是在更新视图所引用的基础表中的数据。对于可更新的视图,需要该视图中的行和基础表中的行之间具有一对一的关系。
视图中以下任何一种SQL语句结构,都不可更新视图:
- 聚合函数
- distinct 关键字
- group by 子句
- order by 子句
- having 子句
- union 运算符
- 位于选择列表中的子查询
- from 子句中包含多个表
- select 语句中引用了不可更新视图
- where 子句中的子查询,引用from子句中的表
– 使用insert语句通过视图向基础表插入数据
insert into db_school.v_student values(’2342355’,’zhou’,’m’,’1999-08-13’);
– 使用update语句通过视图修改基础表数据
update db_school.v_student
set native=’henan’;
– 使用delete语句通过视图删除基础表数据
delete from db_school.v_student where studentname=’zhouming’;
7.7 查询视图数据
– 在视图v_student查找classno为’cs1401’学生学号和姓名
select studentno,studentname from db_school.v_student
where classno=’cs1401’;
7.8 对视图的进一步说明
-- 创建单表视图
create or replace view myview01
as
select empno,ename,job,deptno
from emp
where deptno = 20
with check option;
-- 查看视图
select * from myview01;
-- 插入数据
insert into myview01 (empno,ename,job,deptno) values (9999,’Nana’,’clerk’,20);
insert into myview01 (empno,ename,job,deptno) values (8888,’Nabby’,’clerk’,30);
-- 》 check option failed
-- 创建/替换多表视图
create or replace view myview02
as
select e.empno,e.ename,e.sal,e.deptno,d.dname
from emp e
join dept d
on e.deptno = d.deptno
where sal >2000;
select * from myview02;
-- 创建统计视图
create or replace view myview03
as
select e.deptno,d.dname,avg(sal),min(sal),count(1)
from emp e
join dept d
using(deptno)
group by e.deptno;
select * from myview03;
-- 创建基于视图的视图
create or replace view myview04
as
select * from myview03 where deptno = 20;
8. 触发器
8.1 触发器概述
触发器是一个被指定关联到一个表的数据库对象,当对一个表的特定事件出现时,它将会被激活。如:
每当增加一个客户到数据库的客户基本信息表时,都检查其电话号码的格式是否正确。
每当客户订购一个产品时,都从产品库存量中减去订购的数量。
每当删除客户基本信息表中一个客户的全部基本信息时,该客户所订购的未完成订单信息也应该被自动删除。
无论何时删除一行,都在数据库的存档表中保留一个副本。
触发器用于保护表中的数据。当有操作影响到触发器所保护的数据时,触发器就会自动执行,从而保障数据库中数据的完整性,以及多个表之间数据的一致性。
触发器就是MySQL响应 insert、update 和 delete 语句而自动执行的一种MySQL语句(或位于begin和end之间的一组MySQL语句)。其他MySQL语句不支持触发器。
8.2 创建触发器
create trigger trigger_name trigger_time trigger_event
on tb_name for each row trigger_body
- trigger_name:触发器名称。若要在某个特定数据库中创建,名称前面应该加上数据库的名称。
- trigger_time:触发器被触发的时刻,有两个选项,before 和 after。若希望验证新数据是否满足使用的限制,使用before;若希望在激活触发器的语句执行之后完成几个或更多的改变,通常使用after
- trigger_event:触发事件。
- tb_name:与触发器相关联的表名,必须引用永久性表,不能将触发器与临时表或视图关联起来。同一个表不能拥有两个具有相同触发时刻事件的触发器。
- for each row:用于指定对于受触发事件影响的每一行都要激活触发器的动作。
- trigger_body:触发器动作主体,包含触发器激活时将要执行的MySQL语句。若要执行多个语句,可使用 begin…end 复合语句结构。这里可使用存储过程中允许的相同语句。
注意,在触发器的创建中,每个表每个事件每次只允许一个触发器。因此,每个表最多支持6个触发器,即每条 insert、update、delete的之前和之后。单一触发器不能与多个事件或多个表关联。
查看数据库中已有的触发器,可以使用 show triggers [{from|in} db_name]
-- 数据库db_school的表tb_student创建一个触发器 tb_student_insert_trigger,用于每次向表插入一行数据时将学生变量 str的值设置为 one student added!
create trigger db_school.tb_student_insert_trigger after insert
on db_school.tb_student for each row set @str=’one student added!’;
-- 插入数据
insert into db_school.tb_student values (’11232’,’zhang’,’m’,’2000-02-23’,’shanxi’,’han’,’ac1301’);
-- 验证触发器
select @str;
8.3 删除触发器
drop trigger [if exists] [schema_name.]trigger_name
schema_name:指定触发器所在的数据库名称
drop trigger语句需要 super权限
– 删除数据库db_school触发器tb_student_insert_trigger
drop trigger if exists db_school.tb_student_insert_trigger;
8.4 使用触发器
1. insert 触发器
- 可引用一个名为 new(不区分大小写)的虚拟表来访问被插入的行。
- before insert触发器中,new中的值也可以被更新,即允许更改被插入的值(只要具有对应的操作权限)。
- 对于auto_increment列,new在insert执行之前包含的是0值,在insert执行之后将包含新的自动生成值。
-- 在数据库db_school表tb_student重新创建触发器tb_student_insert_trigger,用于每次向表插入一行数据时将学生变量str的值设置为新插入学生的学号
create trigger db_school.tb_student_insert_trigger
on db_school.tb_student for each row set @ str=new.studentno;
-- 插入数据
insert into db_school.tb_student values(’1323’,’..)
-- 验证
select @str;
2. delete 触发器
- 可以引用一个名为 old(不区分大小写)的虚拟表来访问以前(update语句执行前)的值,也可以引用一个名为 new(不区分大小写)的虚拟表来访问新更新的值
- 在before update触发器中,new中的值也可以被更新,即允许更改将要用于 update 语句的值(只要具有对应的操作权限)。
- old 中的值全部是只读的,不能被更新
- 当触发器涉及对表自身的更新操作时,只能使用 before update触发器,而after update触发器将不被允许
-- 在数据库db_school表tb_student重新创建触发器tb_student_update_trigger,用于每次更新表时将nation列的值设置为native列的值
create trigger db_school.tb_student_update_trigger
on db_school.tb_student for each row set new.nation=old.native;
-- 更新数据
update db_school.tb_student set nation = ‘zhuang’
where studentname=’zhang’;
-- 输入命令发现触发器更新
select nation from db_school.tb_student where studentname=’zhang’;
在触发器执行过程,MySQL会按照下面的方式来处理错误
- 若 before触发程序失败,将不执行相应行上的操作
- 仅当 before触发程序和行操作均已被成功执行,才会执行after触发程序(如果有的话)
- 若在before或after触发程序的执行过程出现错误,将导致调用触发程序的整个语句的失败
8.5 对触发器的进一步说明
创建触发器可能需要特殊的安全访问权限
应多使用触发器来保证数据的一致性、完整性和正确性
触发器可创建审计跟踪,把表的更改状态及之前和之后的状态记录到另外一张数据表中
9. 事件
9.1 事件
事件可以通过MySQL服务器中的功能模块–事件调度器(event scheduler)进行监视,并判断其是否需要被调用。事件调度器可以在指定的时刻执行某些特定的任务,并以此可取代原先只能由操作系统的计划任务来执行的工作。这种需要在指定的时刻才被执行的某些特定任务就是事件。可以精确到每秒钟执行一个任务。
事件和触发器相似,都是在某些事情发生的时候启动,因此事件也可称为临时触发器(temporal trigger)。其中,事件是基于特定时间周期触发来执行某些任务,触发器是基于某个表所产生的事件触发的。
使用事件调度器前必须确保 EVENT_SCHEDULER 已被开启。可通过如下语句来查看是否已开启
show variables like ‘event_scheduler’;
或者查看系统变量
select @ @event_scheduler;
若没有开启,则开启该功能
set global event_scheduler=1;
或可以在MySQL配置文件 my.ini中加上“event_scheduler=1”或”set global event_scheduler=on”来开启。
9.2 创建事件
create event [if not exists] event_name
on schedule schedule1 [enable|disable|disable on slave]
do event_body
其中 schedule1 的语法格式为:
at timestamp [+ interval interval1]…
| every interval
[starts timestamp [+ interval interval1] …]
[ends timestamp [+ interval interval1] …]
interval1 的语法格式为:
quantity {year | quarter | month | day | hour | minute |
week | second | year_month | day_hour | day_minute |
day_second | hour_minute | hour_second | minute_second}
- schedule:时间调度,用于指定事件何时发生或者每隔多久发生一次,分别对应下面两个子句:
1) at 子句:用于指定时间在某个时刻发生。timestamp 表示一个具体的时间点,后面可以加上一个时间间隔,表示在这个时间间隔后事件发生;interval 表示这个时间间隔,由一个数值和单位构成;quantity 是间隔时间的数值。
2) every 子句:表示时间在指定时间区间内每间隔多长时间发生一次。其中,starts 子句指定开始时间, ends 子句指定结束时间。- event_body:do 子句中的event_body部分用于指定事件启动时所要求执行的代码。若包含多条语句,可以使用begin…end 复合结构。
- enable|disable|disable on slave :表示事件的一种属性。enable 表示事件是活动的,活动意味着调度器检查事件动作是否必须调用;disable 表示事件是关闭的,关闭意味着事件的声明存储到目录中,但是调度器不会检查是否应该调用;disable on slave 表示事件在从机中是关闭的。若不指定这三个中的任一个,则一个事件创建之后,立即变为活动的。
– 数据库db_school创建一个事件,用于每个月向表插入一条数据,该事件开始于下个月并且在2016年12月31日结束
use db_school;
delimiter $$
create event if not exists event_insert
on schedule every 1 month
starts curdate()+interval 1 month
ends ’2016-12-31’
do
begin
if year(curdate()) < 2013 then
insert into tb_student
values(null,’zhang’,’m’,’1997-02-01’,’shanxi’,’han’,’ac1301’);
end if;
end $$
9.3 修改事件
alter event event_name
[on schedule schedule]
[rename to new_event_name]
[enable|disable|disable on slave]
[do event_body]
注意:一个时间最后一次被调用后,它是无法被修改的,因为此时它已不存在了。
– 临时关闭创建的事件
alter event event_insert disable;
– 再次开启临时关闭的事件
alter event event_insert enable;
– 将事件名字修改为 e_insert
alter event event_insert rename to e_insert;
9.4 删除事件
drop event if exists event_name;
10. 存储过程和存储函数
10.1 存储过程
存储过程是一组为了完成某个特定功能的SQL语句集,实质就是一段存放在数据库中的代码,可以由声明式的SQL语句(如,create、update、select等)和过程式语句(如 if-then-else 控制结构语句)组成。这组语句经过编译后会存储在数据库中,用户只需通过指定存储过程的名字并给定参数(若该存储过程带有参数),即可随时调用并执行它,而不必重新编译。这种通过定义一段程序存放在数据库中的方式,可加大数据库操作语句的执行效率。
一个存储过程是一个可编程的函数,同时可看作是在数据库编程中对面向对象方法的模拟,它允许控制数据的访问方式。当希望在不同应用程序上或平台上执行相同的特定功能时,存储过程尤为适合。优点:
- 可增强SQL语言的功能和灵活性
- 良好的封装性
- 高性能
- 可减少网络流量
- 存储过程可作为一种安全机制开确保数据库的安全性和数据的完整性
1. 创建存储过程
create procedure sp_name([proc_parameter[,...]])
[characteristic ...] routine_body
其中,proc_parameter 的格式为:
[in|out|inout] param_name type
type的格式为:
any valid mysql data type
characteristic 的格式为:
comment ‘string’|language sql
|[not] deterministic
|{contains sql|no sql|reads sql data|modifies sql data}
|sql security {definer|invoker}
routine_body的格式为:
valid sql routine_statement
- sq_name:存储过程的名称。在特定数据库中创建存储过程,则要在名称前面加上数据库的名称, db_school.sq_name。
- proc_parameter:存储过程的参数列表。param_name 为参数名, type 为参数的类型 (可以是任何有效的MySQL数据类型)。存储过程可以没有参数(此时存储过程的名称后仍需加上一对括号),也可以有1个或多个参数。MySQL 存储过程支持三种类型的参数,即输入参数 in、输出参数 out和输入输出参数 intout。in 是是数据可以传递给一个存储过程;out 用于存储过程需要返回一个操作结果的情形;inout既可以充当输入参数也可以充当输出参数。
- characteristic:存储过程的某些特征设定。
1)comment ‘string’:对存储过程的描述,string为描述内容,comment为关键字。这个描述信息可以用 show create procedure 语句来显示
2)language sql:指明编写这个存储过程的语言为SQL语言。这个选项可以不指定。MySQL扩展后可能支持php
3)deterministic:表示存储过程对同样的输入参数产生相同的结果;若设置为not deterministic,表示会产生不确定的结果。默认为 not
4)contains sql 表示存储过程包含读或写数据的语句;no sql 表示存储过程不包含SQL语句;reads sql data 示存储过程包含读数据的语句;modifies sql data 示存储过程包含写数据的语句。默认 contains sql。
5)sql security:指定存储过程使用创建该存储过程的用户(definer)。- routine_body:存储过程的主体部分,也称为存储过程体,包含了在过程调用的时候必须执行的SQL语句。这个部分以关键字 begin开始,end 结束。存储过程体只有一条语句可省略beginend。 存储体中begin-end复合语句可嵌套使用。
使用 delimiter 命令 将MySQL结束标志临时修改为其他符号,从而使得服务器可以完整地处理存储过程体中所有的SQL语句。
delimiter语法格式: delimiter $$
- $$ 是用户定义的结束符。通常这个符号可以使一些特殊的符号,如两个##或¥¥
- 当使用delimiter,应避免使用反斜杠,因为是MySQL转义字符
– 将结束符改为!!
delimiter !!;
– 执行后,任何命令语句或程序的结束标志就换为两个!!。若希望换回默认的;,只需输入
delimiter;
– 数据库db_school创建一个存储过程,用于实现给定表 tb_student中一个学生的学号即可修改表中学生的性别为一个指定的性别
use db_school;
delimiter $$
create procedure sp_update_sex(in sno char(20),in sex char(2))
begin
update tb_student set sex=ssex where studentno=sno;
end $$
2. 存储过程体
存储过程体中可以使用各种SQL语句与过程式语句的组合,来封装数据库应用中复杂的业务逻辑和处理规则,以实现数据库应用的灵活编程。
1.局部变量
存储存储过程体中的临时结果。用declare声明局部变量,并且同时还可以对该局部变量赋予一个初始值
declare var_name[,...] type [default value]
– 声明一个整型局部变量 sno
declare sno char(10);
使用说明:
- 局部变量只能在存储过程体的 begin…end语句块中声明
- 局部变量必须在存储过程体的开头处声明
- 局部变量的作用范围仅限于声明它的begin…end语句块,其他语句块中的语句不可以使用它。
- 局部变量不同于用户变量,两者区别:局部变量声明时,在其前面没有使用@符号,且它只能被声明它的begin…end语句块中的语句所使用;用户变量在声明时,会在其名称前面使用@符号,同时已声明的用户变量存在于整个会话中
- set 语句
为局部变量赋值
set var_name = expr[,var_name=expr]...
– 为局部变量sno赋予一个字符串’202201001’
set sno = ’202201001’;
- select…into 语句
把选定列的值直接存储到局部变量中
select col_name[,...] into var_name[,...] table_expr
- col_name:指定列名
- var_name:指定要赋值的变量名
- table_expr:表示select语句中from 子句及后面的语法部分
说明:存储过程体中的select…into语句返回的结果集只能有一行数据
4.流程控制语句
1) 条件判断语句
常用的条件判断语句有 if-then-else 语句和 case 语句。
if-then-else 语句不同于系统内置函数if()。
if search_condition then statement_list
[elseif search_condition then statement_list]...
[else statement_list]
end if
case 语句在存储过程中的使用具有两种语法格式。
case case_value
when when_value then statement_list
[when when_value then stateent_list]...
[else statement_list]
end case
或
case
when search_condition then statement_list
[when search_condition then statement_list]...
[else statement_list]
end case
- 第一种语法格式中 case_value 用于指定要被判断的值或表达式,随后紧跟的是一系列的when-then语句块。其中,每一个when-then语句块中的参数when_value用于指定要与case_value进行比较的值。倘若比较的结果为真,则执行对应的statement_list中的SQL语句。如若每一个when-then语句块中的参数when_value都不能与case_value相匹配,则会执行else子句中指定的语句。
- 第二种语法格式,能实现更为复杂的条件判断,使用起来更方便些
2)循环语句
常用循环语句 while 语句, repeat 语句和 loop 语句。
while 的语法格式:
[begin_label:] while search_condition do
statement_list
end while [end_label]
- begin_label和end_label是while语句的标注,且必须使用相同的名字,并成对出现。
repeat 语句的语法格式:
[begin_label:] while search_condition do
statement_list
end while [end_label]
- repeat也可以使用begin_label和end_label进行标注
loop 语句的语法格式:
[begin_label:] loop
statement_list
end loop [end_label]
- begin_label和end_label是loop语句的标注,且必须使用相同的名字,并成对出现。
- 循环体statement_list中语句会一直重复执行,直至循环使用 leave 语句退出。其中,leave语句的语法格式为: leave label,这里的label是loop语句中所标注的自定义名字。
另外,循环语句还可以用 iterate 语句,但它只能出现在循环语句 while、repeat、loop子句中,用于表示退出当前循环,且重新开始一个循环。语法格式: iterate label,label是loop语句中自定义的标注名字。
- 游标
一条select…into语句成功执行后,会返回带有值的一行数据,这行数据可以被读取到存储过程中进行处理。使用select语句进行数据检索时,返回一组称为结果集的数据行,该结果集可能拥有多行数据,这些数据无法直接被一行行进行处理,这时就需要使用游标。游标是一个被select语句检索出来的结果集,在存储了游标后,应用程序或用户就可以根据需要滚动或浏览器中的数据。
注意:
- 游标支持从mysql5.0开始
- 游标只能用于存储过程或存储函数中,不能单独在查询操作中使用
- 在存储过程或存储函数中可以定义多个游标,但在一个begin…end语句块中每一个游标的名字必须是唯一的
- 游标不是一条select语句,是被select语句检索出来的结果集
使用游标的具体步骤如下:
1)声明游标
使用游标前,必须先声明(定义)它。语法格式:
declare cursor_name cursor for select_statement
注意,select语句不能有into子句
2)打开游标
定义游标之后,必须打开该游标,才能使用。这个过程实际上是将游标连接到由 select语句返回的结果集中。
open cursor_name
实际应用中,一个游标可以被多次打开,由于其他用户或应用程序可能随时更新了数据表,因此每次打开的游标结果集可能会不同。
3)读取数据
fetch cursor_name into var_name[,var_name]...
- var_name:用于指定存放数据的变量名
fetch…into语句与select…into语句具有相同的意义,fetch语句是将游标指向的一行数据赋给一些变量,这些变量的数目必须等于声明游标时select子句中选择列的数目。游标相当于一个指针,它指向当前的一行数据。
4) 关闭游标
结束游标使用时,必须关闭游标。
close cursor_name
使用close语句将会释放游标所使用的全部资源。关闭后的游标没有重新被打开则不能使用。声明过的游标不需要再次声明。没有明确关闭游标,MySQL将会在到达end语句时自动关闭它。
– 创建存储过程sp_sumofrow,用于计算表tb_student数据行的行数。
delimiter $$
create procedure sp_sumofrow(out rows int)
begin
declare sno char;
declare found boolean default true;
declare cur cursor for
select studentno from tb_student;
declare continue handler for not found
set found=false;
set rows = 0;
open cur;
fetch cur into sno;
while found do
set rows = rows + 1;
fetch cur into sno;
end whiile;
close cur;
end $$
– 调用存储过程sp_sumofrow
call sp_sumofrow(@rows);
– 查看调用存储过程sp_sumofrow后的结果
select @rows;
- 定义了一个continue handler句柄,它是在条件出现时被执行的代码,用于控制循环语句,以实现游标的下移。
- declare语句的使用存在特定的次序。用declare语句定义的局部变量必须在定义任意游标或句柄之前定义,而句柄必须在游标之后定义,否则系统会出现错误信息。
- 调用存储过程
可以使用call语句在程序、触发器或其他存储过程中调用存储过程,语法格式为:
call sp_name([parameter[,...]])
call sp_name[()]
- 调用某个特定数据库的存储过程,则需要在前面加上该数据库的名称。
- parameter:调用存储过程所要使用的参数。调用语句中参数的个数必须等于存储过程的参数个数。
- 当调用没有参数的存储过程时,使用call sp_name()语句与使用call sp_name语句是相同的。
– 调用存储过程sp_update_sex将学号为’20130101’的学生性别修改为男
call sp_update_sex(’20130101’,’m’);
- 删除存储过程
drop procedure function [if exists] sp_name
drop procedure function if exists sp_update_sex;
10.2 存储函数
存储函数与存储过程一样,都是由SQL语句和过程式语句所组成的代码片段,且可以被应用程序和其他SQL语句调用。存储函数与存储过程的区别:
- 存储函数不能拥有输出参数。因为存储函数自身就是输出参数,而存储过程可以拥有输出参数。
- 可以直接对存储函数进行调用,且不需要使用call语句;而对存储过程的调用,需要使用call语句。
- 存储函数必须包含一条return语句,而这条特殊的SQL语句不允许包含于存储过程中。
- 创建存储函数
create function sp_name([func_parameter[,...]])
returns type
routine_body
其中,func_parameter格式为:
param_name type
type格式为:
any valid mysql data type
routine_body格式为:
valid sql routine statement
- 存储函数不能与存储过程具有相同的名字。
- func_parameter:指定存储函数的参数。这里的参数只有名称和类型,不能指定关键字 in、out和inout。
- returns子句:声明存储函数返回值的数据类型。其中,type用于指定返回值的数据类型。
- routine_body:存储函数的主体部分,也称存储函数体。所有在存储过程中使用的SQL语句在存储函数中同样也适用,包括前面介绍的局部变量,set语句,流程控制语句,游标等。但在存储函数体中还必须包含一个return value 语句,其中,value指定存储函数的返回值。
– 创建一个存储函数,要求该函数能根据给定的学号返回学生的性别,若数据库中没有给定的学号,则返回没有该学生
use db_school
delimiter $$
create function fn_search(sno char(10))
returns char(2)
deterministic
begin
declare ssex char(2);
select sex into ssex from tb_student
where studentno=sno;
if ssex is null then
return(select ‘没有该学生’);
else if ssex=’f’ then
return (select ‘f’);
else return(select ‘m’);
end if;
end if;
end $$
return value语句包含select语句时,select语句的返回结果只能是一行且只能有一列值。另外,若要查看数据库存在哪些存储函数,可以使用 show function status 语句;若要查看数据库中某个具体的存储函数,可以使用 show create function sp_name 语句。
- 调用存储函数
如同调用系统内置函数一样,使用关键字select对其进行调用
select sp_name([func_parameter[,...]])
– 调用数据库db_school的存储函数fn_search
select fn_search(’201300101’);
- 删除存储函数
drop function [if exists] sp_name
存储过程
1】 什么是存储过程(Stored Procedure)
SQL基本是一个命令实现一个处理,是所谓的非程序语言。在不能编写流程的情况下,所有的处理只能通过一个个命令来实现。当然,通过使用连接及子查询,即使使用SQL的单一命令也能实现一些高级的处理,但是,其局限性是显而易见的。如,在SQL中就很难实现针对不同条件进行不同的处理以及循环等功能。
这个时候就出现了存储过程这个概念,简单地说,存储过程就是数据库中保存(Stored)的一系列SQL命令(Procedure)的集合。也可将其看作相互之间有关系的SQL命令组织在一起形成的一个小程序。
2】 存储过程的优点
1)提高执行性能。存储过程执行效率之所以高,在于普通的SQL语句,每次都会对语法分析、编译、执行,而存储过程只是在第一次执行语法分析、编译、执行,以后都是对结果进行调用。
2)可减轻网络负担。使用存储过程,复杂的数据库操作也可以在数据库服务器中完成。只需要从客户端(或应用程序)传递给数据库必要的参数就行,比起需要多次传递SQL命令本身,这大大减轻了网络负担。
3)可将数据库的处理黑匣子化。应用程序中完全不用考虑存储过程的内部详细处理,只需要知道调用哪个存储过程就可以了。
3】 SQL展示
-- 定义 一个没有返回值 的存储过程
-- 实现:模糊查询操作
select * from emp where ename like ‘%A%’;
create procedure mypro01(name varchar(10))
begin
if name is null or name =”” then
select * from emp;
else
select * from emp where ename like concat(‘%’,name,’%’);
end if;
end
-- 删除存储过程
drop procedure mypro01;
-- 调用存储过程
call mypro01(null);
call mupro01(‘R’);
-- 定义 一个有返回值 的存储过程
-- 实现:模糊查询操作
-- 参数前面的in可以省略不写
-- found_rows() mysql中定义的一个函数,作用返回查询结果的条数
create procedure mypro02(in name varchar(10),out num int(3))
begin
if name is null or name =”” then
select * from emp;
else
select * from emp where ename like concat(‘%’,name,’%’);
end if;
select found_rows() into num;
end
-- 调用存储过程
call mypro02(null,@num);
select @num;
call mupro02(‘R’,@aaa);
select @aaa;
11. 访问控制与安全管理
11.1 用户帐号管理
MySQL的用户帐号和相关信息都存储在一个名为mysql的MySQL数据库中,这个数据库里有一个名为user的数据表,包含了所有用户帐号,且它用一个名为user的列存储用户的登录名。
– 查看数据库的使用者账号
select user from mysql.user;
root用户拥有对整个MySQL服务器完全控制的权限。
- 创建用户帐号
create user user_specification
[,user_specification]...
其中,user_specification的格式为:
user [
identified by [password] ‘password’
|identified with auth_plugin [as ‘auth_string’]]
- user:指定创建的用户账号,格式为 ’user_name’@’host name’。user_name是用户名,host_name是主机名,用户连接MySQL时所在主机的名字。若在创建的过程中,只给了账户中的用户名,而没指定主机名,则主机名会被默认为 % ,表示一组主机。
- identified by 子句:指定用户帐号对应的口令,若该用户账号无口令,则可省略。
- password:指定散列口令,即若使用明文设置口令时,需忽略password;若不想以明文设置口令,且知道 password()函数返回给密码的散列值,则可以在此口令设置语句中指定此散列值,但要加上password。
- identified with 子句:指定验证用户帐号的认证插件。
- auth_plugin:指定认证插件的名称。
– 在MySQL服务器中添加两个新用户,其用户名分别为zhangsan和lisi,主机名均为localhost,zhangsan的口令设置为明文’123’,用户lisi的口令设置为对明文’456’使用password()函数加密返回的散列值
– 首先在MySQL的命令行客户端输入下面的SQL语句,得到明文’456’所对应的password()函数返回的散列值:
select password(’456’);
返回散列值’*3434…’
– 创建新用户
create user ‘zhangsan’@’localhost’ identified by ’123’,
’lisi’@’localhost’ identified by password
’*3434...’;
- 使用create user语句,必须拥有MySQL中数据库的insert权限或全局create user权限。
- 创建一个用户帐号后,会在系统自身的mysql数据库的user表中添加一条新记录。若创建的用户存在,语句执行会出现错误。
- 若两个用户具有相同的用户名和不同的主机名,MySQL会将它们视为不同的用户,并允许为这两个用户分配不同的权限集合。
- 若没有为用户指定口令,则允许不使用口令登录系统,不推荐。
- 新创建的用户权限很少。
- 删除用户
drop user user[,user]...
- 必须拥有delete权限或全局create user权限。
- 若没有明确给出账户的主机名,默认为 % 。
- 用户的删除不会影响之前创建的表、索引或其他数据库对象,MySQL并没有记录谁创建了这些对象。
drop user lisi@localhost;
- 修改用户帐号
rename user old_user to new_user[,old_user to new_user]...
- 必须拥有 update权限或全局create user权限。
- 倘若旧账户不存在或新账户已存在,语句执行会出现错误。
- 修改用户口令
set password [for user] = {
password(‘new_password’)|’encrypted password’}
- password(‘new_password’):新口令必须传递到函数password()中进行加密。
- encrypted password:表示已被函数password()加密的口令值。
-- 将用户wangwu的口令修改成明文’hello’对应的散列值
-- 明文’hello’对应的散列值
select password(‘hello’);
-- 返回散列值’*9999...’
-- 修改口令
set password for wangwu@localhost = ’*9999...’;
- 若不加上for子句,表示修改当前用户的口令
11.2 账户权限管理
新创建的用户账号没有访问权限,只能登录MySQL服务器。
– 查看前面新创建的用户zhangsan权限表
show grants for zhangsan@localhost;
grant usage on *.* to changsan@localhost,表示用户对任何数据库和数据表都没有权限。
11.2.1. 权限的授予
grant
priv_type [(column_list)][,priv_type [(column_list)]]...
on [object_type] priv_level
to user_specification[,user_specification]...
[require {none|ssl_option [[and] ssl_option]...}]
[with with_option...]
其中,object_type的格式为:
table|function|procedure
priv_level的格式为:
* | *.* | db_name.* | db_name.tb_name | tb_name | db_name.routine_name
user_specification的格式为:
user [identified by [password] ‘password’
|identified with auth_plugin [as ‘auth_string’]]
with_option的格式为:
grant option
|max_queries_per_hour count
|max_update_per_hour count
|max_connections_per_hour count
|max_user_connections count
- priv_type:指定权限的名称,如select、update、delete等数据库操作。
- column_list:指定权限要授予给表中哪些具体的列。
- on 子句:指定权限授予的对象和级别,如可在on后面给出要授予权限的数据库名或表名等。
- object_type:指定权限授予的对象类型,包括表、函数和存储过程。
- priv_level:指定权限的级别。可授予的权限有如下几组:
1)列权限,其和表中的一个具体列相关。例如,可以使用update语句更新表tb_student中studentname列的值的权限。
2)表权限,其和一个具体表中的所有数据相关。例如,可使用select语句查询表tb_student的所有数据的权限。
3)数据库权限。如,可在已有的数据库db_school创建新表的权限。
4)用户权限,和MySQL所有数据库相关。可以删除已有的数据库或者创建一个新的数据库的权限。
对应地,在grant语句中可用于指定权限级别的值有这样几类格式:
1)* :表示当前数据库中的所有表。
2)*.*:表示所有数据库中的所有表。
3)db_name.* :表示某个数据库中的所有表。
4)db_name.tb_name :表示某个数据库中的某个表或视图。
5)tb_name :表示某个表或视图。
6)db_name.routine_name:表示某个数据库中的某个存储过程或函数。 - to 子句:用来设定用户的口令,以及指定被授予权限的用户user。若给存在的用户指定口令,则新密码会将原密码覆盖;若权限被授予给一个不存在的用户,MySQL会自动执行一条create user语句来创建这个用户,但同时必须为该用户指定口令。
- user_specification:to子句中的具体描述部分。
- with 子句:用于实现权限的转移或限制。
-- 授予用户zhangsan在数据库db_school的表tb_student拥有对列studentno和列studentname的select权限
grant select(studentno,studentname) on db_school.tb_student to zhangsan@localhost;
-- 创建liming和huang用户,设置对应的系统登录口令,同时授予他们在数据库 db_school 的表 tb_student 上拥有select 和 update 权限
grant select,update on db_school.tb_student
to liming@localhost identified by ’123’,
huang@localhost identified by ’345’;
-- 授予用户wangwu拥有创建用户的权限
grant create user on *.*
to wangwu@localhost;
grant语句中 priv_type的说明:
1)授予表权限时,priv_type可以指定为以下值:
select
insert
delete
update
references
create
alter
index
drop
all
2) 授予列权限时,只能指定为 select、insert、update,同时权限后面需要加上列名列表
3)授予数据库权限时,可以定为以下值:
select
insert
delete
update
references
create
alter
index
drop
create temporary tables
create view
show view
create routine:授予用户可以为特定数据库创建存储过程和存储函数等权限。
alter routine:授予用户可以更新和删除数据库已有的存储过程和存储函数等权限。
execute routine:授予用户调用特定数据库创建存储过程和存储函数的权限。
lock tables
all
4)最有效率的权限是用户权限。授予用户权限时,除了可以指定为授予数据库权限时的所有值外,还可以是下面这些值:
create user:授予用户可以创建和删除新用户的权限。
show databases:授予用户可以使用show databases查看所有已有的数据库的定义的权限。
11.2.2. 权限的转移与限制
1. 转移权限
若将with子句指定为with grant option,则表示to子句中所指定的所有用户都具有把自己所拥有的权限授予其他用户的权利,而无论那些其他用户是否拥有该权限。
– 授予当前系统中一个不存在的用户zhou在数据库db_school表tb_student有select和update权限,并允许其可以将自身的这个权限授予其他用户
grant select,update on db_school.tb_student
to zhou@localhost identified by ’123’
with grant option;
2. 限制权限
若with子句中with后为 |max_queries_per_hour count,限制每小时可以查询数据库的次数;
|max_update_per_hour count,限制每小时可以修改数据库的次数;
|max_connections_per_hour count,限制每小时可以连接数据库的次数;
|max_user_connections count,限制同时连接MySQL的最大用户数。
这里,count 用于设置一个数值,对于前三个指定,count为0则表示不起限制作用。
– 授予系统中用户huang在数据库db_school表tb_student上每小时只能处理一条delete语句的权限
grant delete on db_school.tb_student to huang@localhost
with max_queries_per_hour 1;
??:哪些操作属于查询,哪些属于修改
11.2.3. 权限的撤销
当要撤销一个用户的权限,而不希望删除用户,使用revoke语句。
revoke priv_type [(column_list)][,priv_type [(column_list)]]...
on [object_type] priv_level
from user[,user]...
revoke all privileges,grant option
from user[,user]...
- 第一种用于回收某些特定的权限。
- 第二种用于回收特定用户的所有权限。
- 必须拥有mysql数据库的全局 create user权限或 update权限。
– 回收zhou在数据库db_school表tb_student的select权限
revoke select on db_school.tb_student from zhou@localhost;
12. 备份与恢复
12.1 数据库备份与恢复的概念
不可预估因素,使数据库中的数据部分或全部丢失:
- 计算机硬件故障
- 计算机软件故障
- 病毒
- 人为误操作
- 自然灾害
- 盗窃
数据库备份是指通过导出数据或者复制表文件的方式来制作数据库的副本。数据库恢复则是当数据库出现故障或遭到破坏时,将备份的数据库加载到系统,从而使数据库从错误状态恢复到备份时的正确状态。
另外,通过备份和恢复数据库,也可实现将数据库从一个服务器移动或复制到另一个服务器的目的。
12.2 MySQL数据库备份与恢复的方法
四种常用的备份与恢复方法。
12.2.1. 使用SQL语句备份与恢复表数据
MySQL5.5中,可以使用 select into…outfile 语句把表数据导出到一个文本文件中进行备份,并可使用 load data…infile 语句来恢复先前备份的数据。这种方法有一点不足,就是只能导出或导入数据的内容,而不包括表的结构,若表的结构文件损坏,则必须先设法恢复原表结构。
- select into … outfile 语句
select * into outfile ‘file_name’ [character set charset_name] export_options
|into dumpfile ‘file_name’
其中,export_options 的格式为:
[fields [terminated by ‘string’]
[[optionally] enclosed by ‘char’]
[escaped by ‘char’]]
[lines terminated by ‘string’]
-
file_name 指定数据备份文件名称。文件默认在服务器主机上创建,且文件名不能是已经存在的,否则可能将原文件覆盖。若要将文件写入到一个特定位置,则要在文件名前加上具体的路径。文件中,导出的数据行会以一定的形式存放,其中空值是用 N 表示。
-
export_options 中可以加入两个自选的子句,它们的作用是决定数据行在备份文件中存放的格式:
1)fields 子句:至少指定一个亚子句。terminated by 指定字段值之间的符号,如,terminated by ’,’ 指定逗号作为两个字段值之间的标志;enclosed by 指定包裹文件中字符值的符号,如,enclosed by ‘”’表示文件中字符值放在双引号之间,若加上 optionally 表示所有的值都放在双引号之间;escaped by 用来指定转义字符,如, escaped by ‘’ 将定义为转义字符,取代 ,如空格将表示为 *N。
2)lines 子句:terminated by 指定一个数据行结束的标志,如 lines terminated by ’?’ 表示一个数据行以?作为结束标志。
若fields 和 lines 子句都不指定,则默认声明是下面的子句:
fields terminated by ‘t’ encloased by ” escaped by ‘’
lines terminated by ‘n’ -
导出语句中使用的是 dumpfile 而非 outfile 时,导出的备份文件里面所有的数据行都会彼此紧挨着放置,即值和行之间没有任何标记。
- load data … infile 语句
load data [low_priority | concurrent] [local] infile ‘file_name.txt’
[replace | ignore]
into table tb_name
[fields [terminated by ‘string’]
[[optionally] enclosed by ‘char’]
[escaped by ‘char’]]
[lines [starting by ‘string’]
[terminated by ‘string’] ]
[ignore number lines]
[(col_name_or_user_var,...)]
[set col_name=expr,...]]
- low_priority | concurrent:若指定 low_priority 则延迟该语句的执行;若指定 concurrent,则当 load data 正在执行的时候其他线程可以同时使用该表的数据。
- local:指定了local,文件会被客户主机上的客户端读取,并被发送到服务器。文件会被给予一个完整的路径名称,以指定确切的位置。若没有指定local,则文件必须位于服务器主机上,且被服务器直接读取。使用local速度会略慢些。这是由于文件的内容必须通过客户端发送到服务器上。
- file_name:待导入的数据库备份文件名。输入文件可以手动创建,也可使用其他的程序创建。导入文件可以指定文件的绝对路径,若不不指定路径,则服务器在默认数据库的数据库目录中读取。出于安全考虑,当读取位于服务器中的文本文件时,文件必须位于数据库目录中,或者是全体可读的。
- replace | ignore:指定replace,则当导入文件中出现与数据库中原有行相同的唯一关键字值时,输入行会替换原有行;指定ignore,则把原有行有相同的唯一关键字值的输入行跳过。
- tb_name:指定需要导入数据的表名,该表在数据库中必须存在,表结构必须与导入文件的数据行一致。
- fields 子句:用于判断字段之间和数据行之间的符号。
- lines 子句:terminated by 亚子句用来指定一行结束的标志;starting by 亚子句则指定一个前缀,导入数据行时,忽略数据行中的该前缀和前缀之前的内容。若某行不包括该前缀,则整个数据行被跳过。
- ignore number lines:这个选项可以用于忽略文件的前几行。
- col_name_or_user_var:若需要载入一个表的部分列,或者文件中字段值顺序与原表中列的顺序不同时,就必须指定一个列清单,其中可以包含列名或用户变量,如:
load data infile ‘backupfile.txt’
into table backupfile (cust_id,cust_name,cust_address);
– 备份数据库db_school中表tb_student全部数据到C盘BACKUP目录下一个名为backupfile.txt文件中,要求字段值若是字符则用双引号标注,字段值之间用逗号隔开,每行以问号为结束标志。然后,将备份后的数据导入到一个和tb_student表结构相同的空表tb_student_copy中
-- 导出数据
select * from db_school.tb_student
into outfile ‘D:backupbackupfile.txt’
fields terminated by ’,’
optionally enclosed by ‘”’
lines terminated by ’?’;
-- 导入数据
load data infile ‘D:backbackupfile.txt’
into table db_school.tb_student_copy
fields terminated by ’,’
optionally enclosed by ‘”’
lines terminated by ’?’;
导入数据时,必须根据数据备份文件中数据行的格式来指定判断的符号!
另外,需要注意,多个用户同时使用MySQL数据库的情况下,为了得到一个一致的备份,需要在指定的表上使用 lock tables table_name read 语句做一个读锁定,以防止在备份过程中表被其他用户更新;而当恢复数据时,则需要使用 lock tables table_name write 语句做一个写锁定,以避免发生数据冲突。在数据库备份或恢复完毕之后需要使用 unlock tables 语句对该表进行解锁。
12.2.2. 使用MySQL客户端实用程序备份和恢复数据
MySQL提供许多免费的客户端实用程序,存放于MySQL安装目录下的bin子目录中。
mysqldump 程序和 mysqlimport 程序就分别是两个常用的用于实现MySQL数据库备份和恢复的实用工具。
- 使用实用程序的方法
打开dos终端,进入MySQL的bin子目录, cd c:program filesmysqlmysql server 5.5bin
之后可输入命令 - 使用mysqldump程序备份数据
除了可以导出备份的表数据文件之外,还可在到处的文件中包含数据库中表结构的SQL语句。
– 查看mysqldump的三种命令
mysqldump --help
usage: mysqldump [options] database [tables]
or mysqldump [options] --databases [options] db1 [db2 db3…]
or mysqldump [options] --all-databases [options]
for more options,use mysqldump --help
- 备份表
mysqldump [options] database [tables] > filename
- database:指定数据库的名称,其后面可加上需要备份的表名。
- 与其他MySQL客户端实用程序一样,使用mysqldump备份数据时,需要使用一个用户帐号连接到MySQL服务器,可以通过用户手工提供参数或在选项文件中修改有关值的方式来实现。使用参数的格式是:-h[hostname] -u[username] -p[password]。 其中,-h 是主机名,若是本地服务器,则可忽略。
– 使用mysqldump备份数据db_school表tb_student
mysqldump -h localhost -uroot -p123456 db_school tb_student > c:backupfile.sql
文件中存储了创建表的一系列SQL语句及表中所有数据。
- 备份数据库
mysqldump [options] --databases [options] db1 [db2 db3…] > filename
– 备份数据库db_school到C盘backup目录下
mysqldump -uroot -p123456 --databases db_school > c:backupdata.sql
3) 备份整个数据库系统
mysqldump [options] --all-databases [options] > filename
– 备份MySQL服务器上所有数据库
mysqldump -uroot -p123456 --all-databases > c:backupalldata.sql
注意:
尽管使用mysqldump程序可以有效的导出表的结构,但在恢复数据的时候,倘若所需恢复的数据量很大,备份文件中,众多的SQL语句会使恢复的效率降低。可在mysqldump命令中使用 --tab= 选项来分开数据和创建表的SQL语句。–tab= 选项会在 = 后面指定目录里分别创建存储数据内容的 .txt 文件和包含创建表结构的SQL语句的 .sql 文件。另外,该选项不能与 --databases 或 --all-databases 同时使用,且mysqldump必须运行在服务器主机上。
– 将数据库db_school所有表的表结构和数据分别备份到C盘的backup目录下
mysqldump -uroot -p123456 --tab= c:backupdb_school
- 使用mysql命令恢复数据
可以通过使用mysql命令将mysqldump程序备份的文件中全部的SQL语句还原到MySQL服务器中,从而恢复一个损坏的数据库。
– 假设数据库db_school遭到损坏,使用数据库备份文件db_school.sql将其恢复
mysql -uroot -p123456 db_school < db_school.sql
若是数据库表结构损坏,也可使用mysql命令对其单独做恢复处理,但是表中原有的数据会全部清空。
– 假设db_school表tb_student表结构被损坏,试将存储表tb_student结构的备份文件tb_student.sql恢复到服务器中,该备份文件存放在C盘的backup目录中
mysql -uroot -p123456 tb_student < c:backuptb_student.sql
- 使用 mysqlimport 程序恢复数据
只是为了恢复数据表中的数据,可以使用 mysqlimport 客户端实用程序来完成。程序提供了 load data…infile 语句中的一个命令行接口,它发送一个 load data infile 命令到服务器来运作,大多数选项直接对应load data … infile 语句。
mysqlimport [options] database textfile…
- options:mysqlimport命令支持的选项,可以通过执行mysqlimport --help 命令查看这些选项的内容和作用。常用的选项有:
1) -d、 --delete:在导入文本文件之前清空表中所有的数据行。
2) -l、 --lock-tables:在处理任何文本文件之前锁定所有的表,以保证所有的表在服务器上同步,但对于InnoDB类型的表则不必进行锁定。
3) --low-priority、 --local、 --replace、 --ignore:分别对应load data…infile语句中的关键字。- database:欲恢复的数据库名称。
- textfile:存储备份数据的文本文件名。mysqlimport会剥去这个文件名的扩展名,并使用它来决定向数据库中哪个表导入文件的内容。如,file.txt、file.sql、file 都会被导入名为file的表中,因此备份的文件名应根据需要恢复表命名。若未指定备份文件具体路径,则会选取默认位置 MySQL安装目录的data目录下。
- 使用mysqlimport恢复数据时,也需提供 -h、-u、-p选项来连接MySQL服务器。
– 使用存放在C盘backup目录下的备份数据文件tb_student.txt恢复数据库db_school表tb_student的数据
mysqlimport -uroot -p123456 --low-priority --replace db_school c:backuptb_student.txt
12.2.3. 使用MySQL图形界面工具备份和恢复数据
以phpMyAdmin为例。
- 备份数据库
以web方式登录phpMyAdmin,菜单栏点击导出 选项,指定备份数据库的操作功能,同时还有一个格式选择下拉框,用于选择备份文件的文件格式。界面左边,对于备份的数据库和表进行选择。最后,单击执行即可。 - 恢复数据库
单击管理界面中 import 选项,输入欲导入的备份文件名,单击执行即可。
12.2.4 直接复制
1)复制前确保数据表当前状态下没有被使用,最好是暂时关闭MySQL服务器。
2)复制待备份数据库所对应的文件目录下所有的表文件。其中,若表使用的是MyISAM格式,则复制 table_name.frm (表的描述文件)、table_name.MYD(表的数据文件)和 table_name.MYI (表的索引文件)三类文件;若表使用的是ISAM格式,则复制 table_name.frm (表的描述文件)、table_name.ISD(表的数据文件)和 table_name.ISM (表的索引文件)三类文件.
3)重启服务器。
文件复制好后,就可将该文件复制到另外一个MySQL服务器的数据库目录下,此时该服务器就可正常使用这个直接复制过来的数据库了。另外,还可以在数据库遭遇损坏时,将该文件直接覆盖到当前服务器的数据库目录下,实现数据库的恢复。
直接从一个MySQL服务器复制文件到另一个服务器的方法,注意:
- 两个服务器必须使用相同或兼容的MySQL版本
- 两个服务器的硬件结构相同或相似,除非要复制的表使用MyISAM存储格式,这是因为这种表为在不同的硬件体系中共享数据提供了保证。
12.4 二进制日志文件的使用
当数据遭遇丢失或被损坏时,只能恢复已经备份的文件,在这之后更新的数据就无法恢复了。这时,可以考虑使用更新日志,因为更新日志可以实时记录数据库中修改、插入和删除的SQL语句。MySQL5.5中更新日志被二进制日志取代。
12.3.1. 开启日志文件
MySQL默认不开启二进制日志功能(因为系统性能会有所降低,浪费一定的存储空间)。需要手工启用
1)打开MySQL安装目录下的 my.ini 文件(Linux系统打开my.cnf)
2)找到 [mysqld] 这个标签,标签下面,添加以下格式的一行语句:
log-bin[ =filename]
其中,log-bin 说明要开启二进制日志文件,可选项filename 是二进制日志文件的名字。加入后,服务器启动时就会加载该选项,从而启用二进制日志。若 filename包含扩展名,则扩展名被忽略。MySQL服务器会为每个二进制日志文件名后面自动添加一个数字编号扩展名,每次启动服务器或刷新日志时,都会重新生成一个二进制日志文件,数字编号依次递增。若filename未给,默认主机名。
3)保存修改,重启MySQL服务器。此时MySQL安装目录下 data文件夹下可看到两个格式文件:filename.数字编号、filename.index。filename.数字编号 大小达到最大时,MySQL会自动创建一个新的文件。 filename.index 是服务器自动创建的二进制日志索引文件,包含所有使用的二进制日志文件的文件名。
– filename取名 bin_log。若不指定目录,在安装目录data文件夹下会自动创建二进制日志文件。使用实用工具 mysqlbinlog 处理二进制日志,而该工具位于bin目录下,请在 my.ini文件的[mysqld]标签下添加一行指定二进制日志路径的语句,用于开启二进制日志功能
log-bin= c:program filesmysqlmysql server 5.5binbin_log
12.3.2. 使用 mysqlbinlog 实用工具处理日志
- 查看二进制日志文件
mysqlbinlog [options] log_files…
– 查看二进制日志文件bin_log.000001
mysqlbinlog bin_log.0000001
– 由于二进制日志数据可能会非常庞大,可采用重定向的方法将二进制日志数据保存在一个文本文件中以便查看
– mysqlbinlog bin_log.000001 > d:backupbin_log000001.txt
- 使用二进制日志恢复数据
mysqlbinlog [options] log_files… | mysql [options]
– 假设系统管理员在本周一下午五点公司下班前,使用mysqldump进行数据库db_school的一个完全备份,备份文件为 alldata.sql。之后,本周一下午五点开始启用日志,bin_log.000001 文件保存了本周一下午五点到本周三上午九点所有的更改信息,在本周三上午九点运行一条日志刷新语句 flush logs,此时系统自动创建了一个新的二进制日志文件 bin_log.000002,直至本周五上午十点公司数据库服务器系统崩溃。要求将数据库恢复到崩溃前状态
– 恢复过程可分三个步骤
– 将数据恢复到本周一下午五点前状态
mysqldump -uroot -p123456 db_school < alldata.sql
– 将数据恢复到本周三上午九点
mysqlbinlog bin_log.000001 | mysql -uroot -p123456
– 将数据恢复到本周五上午十点
mysqlbinlog bin_log.000002 | mysql -uroot -p123456
由于二进制日志文件会占用很大硬盘资源,需要及时清除没用的二进制日志文件。
删除所有的日志文件:
reset master;
倘若需要删除部分日志文件,可使用 purge master logs 语句实现:
purge {master | binary} logs to ‘log_name’
或
purge {master | binary} logs before‘date’
第一条用于删除指定的日志文件,第二条用于删除时间date之前的所有日志文件。
13. MySQL 数据库的应用编程
广泛应用于互联网中各种中小型网站或信息管理系统的开发,其所搭建的应用环境主要有LAMP和WAMP两种,均可使用PHP作为与MySQL数据库进行交互的服务器端脚本语言。
13.1 PHP概述
PHP是 Hypertext Preprocessor(超文本预处理器)的递归缩写,目前使用相当广泛,它是一种在服务器端执行的嵌入HTML文档的脚本语言,风格类似C语言,独特的语法混合了C、Java、Perl以及PHP自创的新语法。PHP作为一种服务器端的脚本/编程语言,是当前世界上最流行的构建B/S模式Web应用程序的编程语言之一。
PHP具有强大的功能,其能实现所有的CGI的功能,并可提供比一般CGI更快的执行速度,它的多平台特性使其能无缝地运行在UNIX和windows平台。
PHP5作为MySQL开发语言,将Appserv(这个开源工具包含了Apache、MySQL和PHP的安装及自动配置,并通过phpMyAdmin来管理MySQL)作为应用平台环境。
13.2 PHP编程基础
PHP网页文件会被当作一般的HTML文件来处理,并且在编辑时可以使用编辑HTML的常规方法来编写PHP程序。
– 编写一个可以通过浏览器网页显示hello world的PHP5程序代码
– 文本编辑器(如记事本)输入如下PHP程序,命名为hello.php
<html>
<head>
<title>hello world</title>
</head>
<body>
<h1>
<? php
$string=”hello”;
echo $string;
?>
</h1>
</body>
</html>
然后,将程序hello.php部署在已开启的Appserv平台环境中,并在浏览器地址栏输入http://localhost/hello.php或http://127.0.0.1/hello.php即可查看程序执行结果。
示例程序中,PHP代码生成的页面输出将取代<?php...?>标记中的内容。通过浏览器查看运行结果页面的源文件,可看到如下:
<html>
<head>
<title>hello world</title>
</head>
<body>
<h1>hello</h1>
</body>
</html>
PHP编写过程中,可以混合编写PHP5代码和html代码。
13.3 使用php进行MySQL数据库应用编程
PHP内置了许多函数。为了在PHP5中实现对数据库各种操作,可以使用其中mysql函数库。在使用mysql函数库访问数据库之前,需要在PHP配置文件 php.ini 中将 ;extension =php_mysql.dll 修改为 extension =php_mysql.dll,即删除注释符号; 。然后再重新启动web服务器(如Apache)。
使用内置函数库mysql所构建的基于B/S模式的web应用程序的工作流程可描述如下:
1)用户计算机的浏览器中通过在地址栏中输入相应URI信息,向网页服务器提出交互请求。
2)网页服务器收到用户浏览器交互请求。
3)网页服务器根据请求寻找服务器上的网页。
4)web应用服务器(如Apache)执行页面内含的PHP代码脚本程序。
5)PHP代码脚本程序通过内置的API函数访问后台MySQL数据库服务器。
6)PHP代码脚本程序取回后台数据库服务器的查询结果。
7)网页服务器将查询处理结果以html文档的格式返回给用户浏览器端。
13.3.1. 编程步骤
1)建立与MySQL数据库服务器的连接。
2)选择要对其进行操作的数据库。
3)执行相应的数据库操作,包括对数据的添加、删除、修改和查询等。
4)关闭与MySQL数据库服务器的连接
以上步骤,均是通过PHP5内置函数库mysql中相应的函数来实现的。
13.3.2. 建立与MySQL数据库服务器的连接
使用函数mysql_connect()建立非持久连接,mysql_pconnect()建立持久连接。
- mysql_connect()建立非持久连接
mysql_connect([servername[,username[,password]]])
- servername:字符串型,指定要连接的数据库服务器。localhost:3306.
- username:字符串型,指定登录数据库服务器所用用户名。默认值是拥有服务器进程的用户的名称,如,超级用户root。
- password:字符串型,指定登录数据库服务器所用的密码。默认为空串。
- 函数mysql_connect()返回值为资源句柄型(resource)。若成功执行,返回一个连接标识号;否则返回逻辑值FALSE。
PHP程序中,通常是将mysql_connect()函数返回的连接标识号保存在某个变量中,以备PHP程序使用。实际上,在后续其他有关操作MySQL数据库的函数中,一般都需要指定相应的连接标识号作为该函数的实参。
– 编写一个数据库服务器的连接示例程序connect.php,要求以超级用户 root 及其密码123456连接本地主机中MySQL数据库服务器,并使用变量 $con 保存连接结果
– 首先在文本编辑器(如记事本)输入如下PHP程序,命名为connect.php:(注意,PHP程序是被包含在标记符 <? php 与 ?> 之间的代码段,同时PHP程序中的变量名是以 $ 开头的
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”);
if (!$con){
echo “connect failed <br>”;
echo “wrong number:”.mysql_errno().”<br>”;
echo “wrong information:”.mysql_error().”<br>”;
die(); //终止程序运行 }
echo “connect success <br>”;
?>
然后,将程序connect.php部署在已开启的Appserv平台环境中,并在浏览器地址栏中输入 http://localhost/connect.php ,按回车查看程序执行结果。
建立连接是执行其他MySQL数据库操作的前提条件,因此执行mysql_connect()之后,应立即进行相应的判断,以确定数据库连接是否已被成功建立。 PHP中,一切非0值会被认为是逻辑值TRUE,数值0是FALSE。因此,若要判断是否已成功建立与MySQL数据库服务器的连接,只需判断函数mysql_connect()返回值即可。
若连接失败,则可进一步调用PHP中函数 mysql_errno() 和 mysql_error(),获取相应的错误编号和错误提示信息。。执行成功时,分别返回数值0和空字符串。
- 使用函数 mysql_pconnect() 建立持久连接
mysql_pconnect([servername[,username[,password]]])
- mysql_connect()建立的连接,在数据库操作结束之后将自动关闭; mysql_pconnect()建立的连接会一直存在,是一种稳固持久的连接。
- 对于mysql_pconnect(),每次连接前都会检查是否使用了同样的 servername、username、password进行连接,若有,则直接使用上次的连接,而不会重复打开。
- mysql_connect()建立的连接,可以使用mysql_close()关闭; mysql_pconnect() 则不能关闭。
– 编写一个数据库服务器的持久连接示例程序pconnect.php,要求使用函数mysql_pconnect(),并以超级用户 root及密码123456 连接本地主机中的MySQL数据库服务器
– 文本编辑器输入如下PHP程序,并命名为pconnect.php
<? php
/* 定义三个变量,分别存储服务器名,用户名和密码,以备后续程序引用*/
$server = “localhost:3306”;
$user=”root”;
$pwd=”123456”;
$con=mysql_pconnect($server,$user,$pwd)’
if (!$con) {
die(“connect failed”.mysql_error()); //终止程序运行,并返回错误信息 }
echo “使用函数mysql_pconnect()永久连接数据库 <br>”;
?>
13.3.3. 选择数据库
执行具体MySQL数据库操作之前,应当选定相应的数据库作为当前工作数据库。使用函数 mysql_select_db()。
mysql_select_db(database[,connection])
- database:字符串型。
- connection:资源句柄型,指定相应的与MySQL数据库服务器相连的连接标识号。若未指定,则使用上一个打开的连接。若没有打开的连接,则会使用不带参数的函数 mysql_connect()来尝试打开一个连接并使用。
- mysql_connect()返回值为布尔型。成功执行则返回TRUE。
– 编写一个选择数据库的PHP示例程序selectdb.php,要求选定数据库 mysql_test作为当前工作数据库
– 首先文本编辑器编写,命名selectdb.php
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”);
if (mysql_errno()){
echo “数据库服务器连接失败 <br>”;
die(); //终止程序运行 }
mysql_select_db(“mysql_test”,$con);
if (mysql_errno()){
echo “数据库选择失败 <br>”;
die(); //终止程序运行 }
echo “数据库选择成功 <br>”;
?>
13.3.4. 执行数据库操作
对数据库的各种操作,都是通过提交并执行相应的SQL语句来实现的。
使用函数 mysql_query() 提交并执行SQL语句。
mysql_query(query[,connection])
- query:字符串型,指定要提交的SQL语句。注意,SQL语句以字符串的形式提交,且不以分号作为结束符。
- connection:资源句柄型,指定相应的与MySQL数据库服务器项链的连接标识号。若未指定,则使用上一个打开的连接。若没有打开的连接,则会使用不带参数的函数 mysql_connect()来尝试打开一个连接并使用。
- mysql_query():返回值是资源句柄型。对于 select、show、explain或describe语句,若执行成功,则返回相应的结果标识符,否则返回False;对于 insert、delete、update、replace、create table、drop table或其他非检索语句,执行成功则返回 TRUE。
- 数据的添加
– 编写一个添加数据的PHP示例程序insert.php,要求可向数据库db_school表tb_student添加一个名为zhangx的学生的全部信息
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”)
or die(“数据库服务器连接失败 <br>”);
mysql_select_db(“db_school”,$con) or die(“数据库选择失败 <br>”);
mysql_query(“select names ‘gbk’”); //设置中文字符集
$sql=”insert into tb_student(studentno,studentname,sex,native,nation,classno)”;
$sql=$sql.”values(’20000232’,’zhangx’,’m’,’shanxi’,’han’,’as123’)”;
if (mysql_query($sql,$con))
echo “学生添加很成功 <br>”;
else
echo “学生添加失败 <br>”;
?>
- 数据的修改
– 编写一个修改数据的PHP程序update.php,要求将数据库db_school表tb_student一个名为‘zhang’的籍贯修改为’guangzhou’
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”)
or die(“failed connected <br>”);
mysql_select_db(“db_school”,$con) or die(“failed <br>”);
mysql_query(“set names ‘gbk’”); //设置中文字符集
$sql=”update tb_student set native=’guangzhou’”;
$sql=$sql.”where studentname=’zhang’”;
if (mysql_query($sql,$con))
echo “update success <br>”;
else
echo “update failed <br>”;
?>
- 数据的删除
– 编写一个删除程序delete.php,要求将数据库db_school表tb_student的一个学生”zhang“删除
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”)
or die(“failed <br>”);
mysql_select_db(“db_school”,$con) or die(“failed <br>”);
mysql_query(“set names ‘gbk’”);
$sql=”delete from tb_student”;
$sql=$sql.”where studentname=’zhang’”;
if (mysql_query($sql,$con)
echo “delete success <br>”;
else
echo “delete fail <br>”;
?>
- 数据的查询
用于数据检索的select语句,当mysql_query()成功执行返回值是一个资源句柄型的结果标识符。结果标识符也称结果集,代表相应查询语句的查询结果。每个结果集都有一个记录指针,所指向的记录即为当前记录。初始状态下,结果集的当前记录就是第一条记录。为了灵活的处理结果集中的相关记录,PHP提供了一系列的处理函数,包括结果集中记录的读数、指针的定位以及记录集的释放等。
1)读取结果集中的记录
可以使用 mysql_fetch_array()、mysql_fetch_row() 或 mysql_fetch_assoc() 读取结果集中的记录。
mysql_fetch_array(array[,array_type])
mysql_fetch_row(data)
mysql_fetch_assoc(data)
- data:资源句柄型,指定要使用的时间指针。该数据指针可指向函数mysql_query()产生的结果集,即结果标识符。
- array_type:为整型(int),指定函数返回值的形式,其有效取值为 PHP 常量 MySQL_NUM(表示数字数组)、MySQL_ASSOC(表示关联数组)或 MySQL_BOTH(表示同时产生关联数组和数字数组)。其默认值为MySQL_BOTH。
- 三个函数成功执行后,返回值均为数组类型(array)。若成功,即读取到当前记录,则返回一个由结果集当前记录所生成的数据,其中每个字段的值会保存到相应的索引元素中,并自动将记录指针指向下一个记录。若失败,则返回false。
使用mysql_fetch_array()时,若以常量mysql_num作为第二个参数,其功能与函数 mysql_fetch_row() 的功能一样,所返回的数据为数字索引方式的数组,只能以相应的序号(从0开始)作为元素的下表进行访问; 若以常量 mysql_assoc 作为第二个参数,则其功能与 mysql_fetch_assoc() 是一样的,返回的数组为关联索引方式的数组,只能以相应的字段名(若指定了别名,则为相应的别名)作为元素的下标进行访问;若未指定第二个参数,或以 mysql_both 作为第二个参数,则返回的数组位数字索引方式与关联索引方式的数组,既能以序号为元素的下表进行访问,也能以字段名为元素的下标进行访问。实际编程中,mysql_fetch_array() 最为常用。
– 编写一个检索数据的程序select.php,要求在数据库db_school表tb_student中查询学号为’231222’的学生姓名
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”)
or die(“failed <br>”);
mysql_select_db(“db_school”,$con) or die(“failed <br>”);
mysql_query(“set names ‘gbk’”);
$sql=”select studentname from tb_student”;
$sql=$sql.”where studentno=231222”;
$result=mysql_query($sql,$con);
if ($result) {
echo “querry success <br>”;
$array=mysql_fetch_array($result,MYSQL_NUM);
if ($array) {
echo “querry success <br>”;
echo “the student name is :”.$array[0];}
}
else
echo “failed <br>”;
?>
2) 读取结果集中记录数
使用函数 mysql_num_rows() 读取结果集中的记录数,即数据集的行数。
mysql_num_rows(data)
– 编写一个读取查询结果集中行数的程序num.php,要求在数据库db_school表tb_student中查询女学生的人数
<? php
$con=mysql_connect(“locaolhost:3306”,”root”,”123456”)
or die(“fail <br>”);
mysql_select_db(“db_school”,$con) or die(“fail <br>”);
mysql_query(“set names ‘gbk’”);
$sql=”select * from tb_student”;
$sql=$sql.”where sex=’f’”;
$result=mysql_query($sql,$con);
if ($result){
echo “query success <br>”;
$num=mysql_num_rows($result);
echo “女学生人数是”.$num”名”;}
else
echo “fail <br>”;
?>
3) 读取指定记录号的记录
使用 mysql_data_seek() 在结果集中随意移动记录的指针,就是将记录指针直接指向某个记录。
mysql_data_seek(data,row)
- data:资源句柄型,指定要使用的数据指针。数据指针指向函数 mysql_query()产生的结果集,即结果标识符。
- row:整型int,指定记录指针所要指向的记录的序号,其中0指示结果集中第一条记录。
- mysql_data_seek()返回值为布尔型bool。成功执行返回TRUE。
– 编写一个读取指定结果集中记录号的记录seek.php,要求在数据库db_school表tb_student查询第三位女学生的姓名
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”)
or die(“fail <br>”);
mysql_select_db(“db_school”,$con);
mysql_query(“set names ‘gbk’”);
$sql=”select * from tb_student”;
$sql=$sql.”where sex=’f’”;
$result=mysql_query($sql,$con);
if ($result){
echo “success <br>”;
if (mysql_data_seek($result,2){
$array=mysql_fetch_array($result,MYSQL_NUM);
echo “数据库第3位女学生是”.$array[1];}
else echo “记录定位失败 <br>”;
}
else echo “query fail <br>”;
?>
13.3.5. 关闭与数据库服务器的连接
使用 mysql_close()关闭由函数mysql_connect()所建立的非持久连接。
mysql_close([connection])
- connection:资源句柄型,指定相应的的与MySQL数据库服务器相连的连接标识号。若未指定,默认使用最后被mysql_connect()打开的连接。若没有打开的,则会使用不带参数的mysql_connect()尝试打开一个连接并使用。若发生意外,没有找到或无法建立连接,系统发出 E_WARNING级别的警告信息。
- 返回值为布尔型,若成功执行,返回True。
– 编写一个关闭程序 close.php
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”)
or die(“fail <br>”);
echo “connect success <br>”;
mysql_select_db(“db_school”,$con) or die(“fail <br>”);
echo “select success <br>”;
mysql_close($con) or die(“close fail <br>”);
echo “close success <br>”;
?>
已打开的非持久连接会在PHP程序脚本执行完毕后自动关闭,因而在PHP程序中通常无需使用函数mysql_close().
14. 开发实例
学生成绩管理系统
14.1. 需求描述
主要负责管理和维护本系统内部所有学生的个人基本信息及每个学生的成绩信息。
14.2. 系统分析与设计
简单的学生成绩管理系统可设计为 学生管理、班级管理、课程管理、成绩管理四个主要功能模块。
各个功能模块描述如下:
1)学生管理模块…
14.3. 数据库设计与实现
1.数据库表结构的设计
四个表的结构如下:
2.数据库表结构的实现
create database db_school;
1) 学生表的实现
create table tb_student(
studentno char(10) not null,
studentname varchar(20) not null,
sex char(2) not null,
birthday date,
nation varchar(10) default ‘han’,
classno char(6),
constraint pk_stu primary key (studentno),
constraint fk_stu foreign key(classno) references tb_class(classno)
)engine=innodb;
2) 班级表的实现
use db_school;
create table tb_class(
classno char(6) not null primary key,
classname varchar(20) not null,
department varchar(30) not null,
grade smallint,
classnum tinyint,
constraint uq_class unique(classname)
)engine=innodb;
3) 课程表的实现
create table tb_course(
courseno char(6) not null,
coursename varchar(20) not null,
credit int not null,
coursehour int not null,
term char(2),
priorcourse char(6),
constraint pk_co primary key(classno),
constraint fk_co foreign key(priorcourse) references tb_course(courseno)
)engine=innodb;
4) 成绩表的实现
create table tb_score(
studentno char(10) not null,
courseno char(6) not null,
score float check(score >=0 and score <=100),
constraint pk_sc primary key(studentno,courseno),
constraint fk_sc1 foreign key(studentno) references tb_student(studentno),
constraint fk_sc2 foreign key(courseno) references tb_coursea(courseno)
)engine=innodb;
14.4. 应用程序的编程与实现
本实例系统的最终运行与应用是基于B/S结构,因此本实例系统的开发与实现将采用三层软件体系架构。
三层软件体系架构由表示层、应用层和数据层构成。表示层是本实例系统的用户接口(User Interface,UI),具体表现为Web页面,主要使用html标签语言来实现(为便于简洁的描述所有构成表示层的web页面的实现代码,本小节给出的各个页面实现代码均未添加CSS、JavaScript等脚本);应用层是本实例系统的功能层,表现为应用服务器,位于表示层与数据层之间,主要负责具体的业务逻辑处理,以及与表示层、数据层的信息交互,其所处理的各种业务逻辑主要由PHP语言编写的动态脚本来实现;数据层位于本实例系统的最底层,具体表现为MySQL数据库服务器,主要通过SQL数据库操作语言,负责对MySQL数据库中的数据进行读写管理,以及更新与检索,并与应用层实现数据交互。
- 实例系统的主页面设计与实现
<html>
<head>
<title>一个学生成绩管理系统实例</title>
</head>
<body>
<h2>学生成绩管理系统</h2>
<h3>学生管理</h3>
<a href=”add_user.php”>添加学生</a><br />
<a href=”show_user.php”>查看学生</a>
<h3>班级管理</h3>
<a href=”add_dept.php”>添加班级</a><br />
<a href=”show_dept.php”>查看班级</a>
<h3>课程管理</h3>
<a href=”add_usergroup.php”>添加课程</a><br />
<a href=”show_course.php”>查看课程</a>
<h3>成绩管理</h3>
<a href=”add_fun.php”>添加成绩</a><br />
<a href=”show_fun.php”>查看成绩</a>
</body>
</html>
- 公共代码模块的设计与实现
学生管理模块中存在一些应用层的业务逻辑处理代码,经常需要使用相同的代码来实现与数据层MySQL数据库的连接,因此可将对数据库的连接操作编写成一个单独的公共代码文件common.php,以供那些应用层的业务逻辑处理代码在需要连接数据库时可直接通过PHP语言的 require_once函数进行加载,而不必针对所有需要处理数据库连接的业务逻辑代码都重复编写相同的数据库连接代码。
公共代码模块 common.php 的实现代码描述如下:
<? php
$con=mysql_connect(“localhost:3306”,”root”,”123456”)
or die(“数据库服务器连接失败 <br>”);
mysql_select_db(“db_school”,$con) or die(”数据库选择失败 <br>”);
mysql_query(“set names ‘gbk’”);
?>
- 添加学生的页面设计与实现
为学生管理模块中添加学生的web页面效果。
<html>
<head><title>添加学生</title>
</head>
<? php require_once”common.php”:?>
<body>
<h3>添加学生</h3>
<form id=”add_student” name=”add_student” method=”post” action=”insert_student.php”>
学生学号:<input type=”text” name=”studentno” /><br />
学生姓名:<input type=”text” name=”studentname” /><br />
学生性别:<input type=”text” name=”sex” /><br />
学生年龄:<input type=”text” name=”birthday” /><br />
学生籍贯:<input type=”text” name=”native” /><br />
学生民族:<input type=”text” name=”nation” /><br />
所属班级:<select name=”classno”>
<? php
$sql=”select * from tb_class”;
$result=mysql_query($sql,$con);
while ($rows=mysql_fetch_row($result)){
echo “<option value=”.$rows[0].”>”.$rows[1].”</option>”;}
?>
</select><br />
<input type=”submit” value=”添加“/>
</form>
</body>
</html>
当在添加学生的web页面输入完并点击添加,即可调用应用层中用于执行添加学生操作的业务逻辑处理代码 insert_student.php:
<? php
require_once “common.php”;
$studentno=$_post[‘studentno’];
$studentname=$_post[‘studentname’];
$sex=$_post[‘sex’];
$birthday=$_post[‘birthday’];
$native=$_post[‘native’];
$nation=$_post[‘nation’];
$classno=$_post[‘classno’];
$sql=”insert into tb_student(studentno,studentname,sex,birthday,native,nation,classno)”;
$sql=$sql.”values(‘”.$studentno.”’,’”$studentname”’,’”ex”’,’”birthday”’,
‘”.$native.”’,’”.$nation.”’,’”.$classno.”’)”;
if (mysql_query($sql,$con)
echo “add success <br>”;
else echo “add fail <br>”;
?>
- 查看学生的页面设计与实现
事务及其特征
事务(Transaction)是用来维护数据库完整性的,它能够保证一系列的MySQL操作要么全部执行,要么全不执行。
例1:转账操作:A账户转账给B账户,A账户上减少的钱数和B账户上增加的钱数必须一致,即A的转出和B的转入操作要么全部执行,要么全不执行;若其中一个操作出现异常而没有执行的话,就会导致A和B的转入转出金额不一致的情况,这种情况是不允许发生的,为防止这种情况的发生,需要使用事务处理。
例2:淘宝购物下订单,商家库存要减少,订单增加记录,付款账号少100元,操作要么全部执行,要么全不执行。
1】 事务的概念
事务(Transaction)指的是一个操作序列,该操作序列中的多个操作要么都做,要么都不做,是一个不可分割的工作单位,是数据库环境中的逻辑工作单位,由DBMS(数据库管理系统)中的事务管理子系统负责事务的处理。
目前常用的存储引擎有InnoDB(MySQL5.5后默认的存储引擎)和MyISAM(MySQL5.5之前默认的存储引擎)。其中InnoDB支持事务处理机制,MyISAM不支持。
2】 事务的特性
事务处理可以确保除非事务性序列内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要求全部失败的序列,可以简化错误恢复并使应用程序更加可靠。
但并不是所有的操作序列都可以称为事务,这是因为一个操作序列要成为事务,必须满足事务的原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。这四个特性简称为ACID特性。
- 原子性
原子是自然界最小的颗粒,具有不可再分的特性。事务中的所有操作可以看作一个原子。事务是应用中不可再分的最小的逻辑执行体。使用食物对数据及西宁修改的操作序列,要么全不执行,要么全部执行。通常,某个事物中的操作都具有共同的目标,并且是相互依赖的。若数据库系统只执行这些操作中的一部分,则可能会破坏事务的总体目标,而原子性消除了系统只处理部分操作的可能性。
2)一致性
一致性是指事务执行的结果必须使数据库从一个一致性状态,变成另一个一致性状态。当数据库中只包含事务成功提交的结果时,数据库处于一致性状态。一致性是通过原子性来保证的。
3)隔离性
隔离性是指各个事务的执行互不干扰,任意一个事务的内部操作对其他并发的事务,都是隔离的。即是说,并发执行的事务之间既不能看到对方的中间状态,也不能相互影响。
4)持久性
持久性指事务一旦提交,对数据所做的任何改变,都要记录到永久存储器中,通常是保存进物理数据库,即使数据库出现故障,提交的数据也应该能恢复。但如果是由于外部原因导致的数据库故障,如硬盘被损坏,那么之前提交的数据则有可能会丢失。
3】 SQL展示:使用事务保证转账的安全
– 创建帐户表
create table account(
id int primary key auto_increment,
uname varchar(10) not null,
balance double
);
– 插入数据
insert into account values(null,’Jane’,2000),(null,’Ben’,2000);
– J转给B 200
update account set balance = balance - 200 where id =1;
update account set balance = balance + 200 where id =2;
– 默认一个DML语句是一个事务,所以上面的操作执行了2个事务
– 必须让上面的两个操作控制在一个事务中
– 手动开启事务
start transaction;
update account set balance = balance - 200 where id =1;
update account set balance = balance + 200 where id =2;
– 手动回滚:刚才执行的操作全部取消
rollback;
– 手动提交
commit;
– 在回滚和提交之前,数据库中的数据都是操作的缓存中的数据,并不是真实数据
事务并发问题
脏读(Dirty read)
当一个事务正在访问数据并对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据还没有提交,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据所做的操作可能是不正确的。
不可重复读(Unrepeatable read)
在一个事务内多次读同一个数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
幻读(Phantom read)
与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉,所以称为幻读。
不可重复读和幻读的区别:
不可重复读的重点是修改,幻读的重点在于新增或删除。
解决不可重复读的问题只需锁住满足条件的行,
解决幻读需要锁表
事务隔离级别
事务的隔离级别用于决定如何控制并发用户读写数据的操作。是开始允许多用户并发访问的,若多个用户同时开启事务并对同一数据进行读写操作的话,有可能会出现脏读、不可重复读和幻读问题,所以MySQL提供了四种隔离级别来解决上述问题。
事务的隔离级别从低到高依次为READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 以及 SERIALIZABLE,隔离级别越低,越能支持高并发的数据库操作。
repeatable read 比较经常用
-- 查看默认的事务隔离级别 MySQL默认的是 repeatable read
select @@transaction_isolation;
-- 设置事务的隔离级别 (设置当前会话的隔离级别)
set session transaction isolation level read uncommitted;
set session transaction isolation level read committed;
set session transaction isolation level repeatale read;
set session transaction isolation level serializable;
-- 事务A
start transaction;
select * from account where id = 1;
-- 同时开启另一个事务B
start transaction
update account set balance = balance -200 where id =1;
-- 事务A
select * from account where id =1; -- 数据变化
-- 事务B
rollback;
-- dirty read
-- 解决
-- 事务A
select @@transaction _isolation;
set session transaction isolation level read committed;
start transaction;
select * from account where id = 1;
-- 此时事务B修改数据
update account set balance = balance - 200 where id =1;
-- 事务A查到的数据不会发生变化
select * from account where id = 1;
二、 MySQL高级篇
1. 导入表的数据
准备四张表:dept(部门表),emp(员工表),salgrade(薪资等级表)
set names utf8mb4;
set foreign_key_checks = 0;
drop table if exists ‘dept’;
create table DEPT(
deptno int(2) not null,
dname varchar(14) character set utf8 collate utf8_general_ci null default null,
loc varchar(13) character set utf8 collate utf8_general_ci null default null,
primary key(deptno) using btree
)engine = innodb character set = utf8 collate = utf8_general_ci row_format = compact;
/*
alter table DEPT
add constraint pk_dept primary key (deptno);
*/
drop table if exists ‘emp’;
create table EMP(
empno int(4) primary key ,
ename varchar(10) character set utf8 collate utf8_general_ci null default null,
job varchar(9) character set utf8 collate utf8_general_ci null default null,
mgr int(4) null default null,
hiredate date null default null,
sal double(7,2) null default null,
comm double(7,2) null default null,
deptno int(2) null default null
)engine = innodb character set = utf8 collate = utf8_general_ci row_format = compact;
alter table EMP
add constraint pk_deptno foreign key (deptno)
references DEPT (deptno);
create table SALGRADE(
grade int primary key,
losal double(7,2) null default null,
hisal double(7,2) null default null
)engine = innodb character set = utf8 collate = utf8_general_ci row_format = compact;
insert into DEPT (deptno,dname,loc)
values (10,’accounting’,’new york’),
(20,’research’,’dallas’),
(30,’sales’,’chicago’),
(40,’operations’,’boston’);
insert into EMP values
(7369,’smith’,’clerk’,7902,’1999-12-01’,800,null,20),
(7499,’allen’,’salesman’,7698,’1999-12-28’,1600,300,30),
(7521,’ward’,’salesman’,7698,’1998-11-23’,1250,500,30),
(7566,’jones’,’manager’,7839,’2000-01-24’,2975,null,20),
(7654,’martin’,’salesman’,7698,’2000-01-10’,1250,1400,30),
(7698,’blake’,’manager’,7839,’2000-02-15’,2850,null,3),
(7782,’clark’,’manager’,7839,’2000-01-19’,2450,null,10),
(7788,’scott’,’analyst’,7566,’1997-12-02’,3000,null,20),
(7839,’king’,’president’,null,’1990-06-01’,5000,null,10),
(7844,’turner’,’salesman’,7698,’1999-07-15’,1500,0,30),
(7876,’adams’,’clerk’,7788,’1992-04-20’,1100,null,20),
(7900,’james’,’clerk’,7698,’1995-05-15’,950,null,30),
(7902,’ford’,’analyst’,7566,’1999-04-03’,3000,null,20),
(7934,’miller’,’clerk’,7782,’1993-08-23’,11300,null,10);
insert into SALGRADE values
(1,700,1200),(2,1201,1400),(3,1401,2000),
(4,2001,3000),(5,3001,9999);
set foreign_key_checks = 1;
2. 语句
select
-- 查询员工名字和年薪
select ename,sal * 12 annual_sal from emp;
select ename,sal * 12 `annual sal` from emp; -- 键盘上1左边的那个倒引号
-- 计算总收入(薪水*12+津贴)(处理NULL值)
-- null是空值,不是0
select ename,sal*12 + comm from emp;
select ename,sal*12 + (case when comm is null then 0 else comm end) as annual_sal from emp;
-- 去重distinct
select deptno from emp;
select distinct deptno from emp; -- 给字段去重
select distinct deptno,job from emp; -- 给组合去重
### where
-- 查询薪水在1000和2000之间的记录
select * from emp where sal between 1000 and 2000;
select * from emp where sal >= 1000 and sal <= 2000;
-- 查询comm值为空值的数据
select * from emp where comm is null;
-- 不为空
select * from emp where comm is not null;
-- 薪水是800 或者 1000
select * from emp where sal = 800 or sal = 1000;
select * from emp where sal in (800,1000);
-- 名字是smith或king
select * from emp where ename = ‘smith’ or name = ‘king’;
select * from emp where ename in (‘smith’,’king’);
-- 名字不是smith或king
select * from emp where ename not in (‘smith’,’king’);
-- 简单日期处理
select * from emp where hiredate > ’1990-01-01’;
-- 模糊查询
select * from emp where ename like ‘%A%’;
-- % 代表0个或多个字符
-- % 代表%本身
### 排序 order by
select * from emp order by sal desc; -- 降序
select * from emp order by sal asc; -- 升序
select ename,deptno,sal from emp order by deptno asc, ename desc;
### 常用函数
http:dev.mysql.com/doc/refman/5.7/en/func-op-summary-ref.html
select lower(‘AA’);
select upper(ename) from emp;
select concat(‘mashi’,’bing’,’.com’) as url; -- 字符串连接到一起
select char_length(‘aaaa’); -- 字符串长度
select substring(‘gogodaddy’,0,5); -- 从第0个位置,到第5个位置截取字符串
select ltrim/rtrim/trim(’ aaa bbb ‘); -- 去掉左边的空串、去掉右边的空串、去掉两边的空串
select abs(),cell(),floor(); -- 取绝对值、向上取整、向下取整
select round(3.14159,3); -- 3.14159四舍五入保留3位小数 3.142
select truncate(3.14159,3); -- 截断,3.14159截断保留3位小数 3.141
select curdate()/curtime()/now(); -- 当前日期:年月日、当前时间:时分秒、当前日期+时间:年月日时分秒
select month(hiredate) from emp; -- 取日期中的月份
select monthname(d)/week(d)/year(d)/hour(time)/minute(time);
select weekday(curdate())/dayname(d);
### 组函数
select max(sal) from emp;
min(sal)
avg(sal)
sum(sal)
count(*)
count(comm) -- 有空值不计数
### group by
select max(sal) from emp group by deptno;
select deptno,job,max(sal) from emp group by deptno,job; -- 按照deptno,job两个字段进行分组
-- 查询最高工资的那个人
select ename,max(sal) from emp; -- 无法查到
-- 分组函数是多行输入,但只有一行输出,这里ename也有多人,无法进行匹配
select ename from emp where sal = ( select max(sal) from emp); -- 使用子查询,解决了无法匹配的问题
-- 查询每个部门最高薪资
select deptno,max(sal) from emp group by deptno;
-- 查询每个部门薪水最高的人名字
select deptno,max(sal) max_sal from emp group by deptno; -- 查询的结果作为一个新表 t1
select ename,sal,e.deptno from emp e join
(select deptno,max(sal) max_sal from emp group by deptno) t
where e.deptno = t.deptno and e.sal = t.max_sal
### having子句与select总结
select avg(sal),deptno from emp group by deptno having avg(sal) > 2000;
总结:
select XX from 表名
where XX XXXX 对数据进行过滤
group by 分组
having 对分组进行限制
order by 排序
取数据,过滤,分组,分组限制,排序
-- 要求薪水大于1200的雇员按照部门编号进行分组,分组后的平均薪水大于1500,查询分组内的平均工资,按照工资的倒序进行排列
select t.deptno,avg(t.sal) avg-sal from (select * from emp where sal > 1200) t group by t.deptno having avg-sal > 1500 order by avg-sal desc;
select avg(sal) from emp where sal > 1200
group by deptno
having avg(sal) > 1500
order by avg(sal) desc;
子查询与自连接
子查询即一个select语句嵌套另一个select语句(可以看作临时表)
1】 求那些人的工资比平均工资高
select * from emp where sal > ( select avg(sal) from emp);
2】 按照部门进行分组之后,每个部门工资最高的人(可能有多个),要求显示他的名字,部门编号
select ename,deptno from emp where sal in (select max(sal) from emp group by deptno);
1) 为什么用 in 而不是 = ?
= 是单行查询,而子查询中的语句的功能是多行查询,使用 = 会报错
2) 这条语句查询的结果可能会出现一个错误,若1部门中有2部门的最高工资,那么1部门中的这个人也会显示出来,所以,这条SQL语句并不完全正确,显示正确只是因为数据量少
3) 这条SQL语句正确
select ename,sal from emp
join (select max(sal) max_sal,deptno from emp group by deptno) t
on (emp.sal = t.max_sal and emp.deptno = t.deptno);
表连接练习与面试题
每个部门平均薪水的等级
部门的平均薪水的等级
哪些人是经理
不用组函数求最高薪水
求平均薪水最高的部门编号
比普通员工最高薪水还高的经理名字
多对多关系面试题
分页
DDL语句
DML语句
索引
MySQL入门小结
两天挑战架构师级海量数据设计与实现
三、MySQL面试篇
最后
以上就是从容钢铁侠最近收集整理的关于MySQL数据库 学习笔记 零基础入门 面试 整理一、MySQL基础篇二、 MySQL高级篇三、MySQL面试篇的全部内容,更多相关MySQL数据库内容请搜索靠谱客的其他文章。








发表评论 取消回复