Unsupervised Learning for Intrinsic Image Decomposition from a Single Image

[paper] [github]
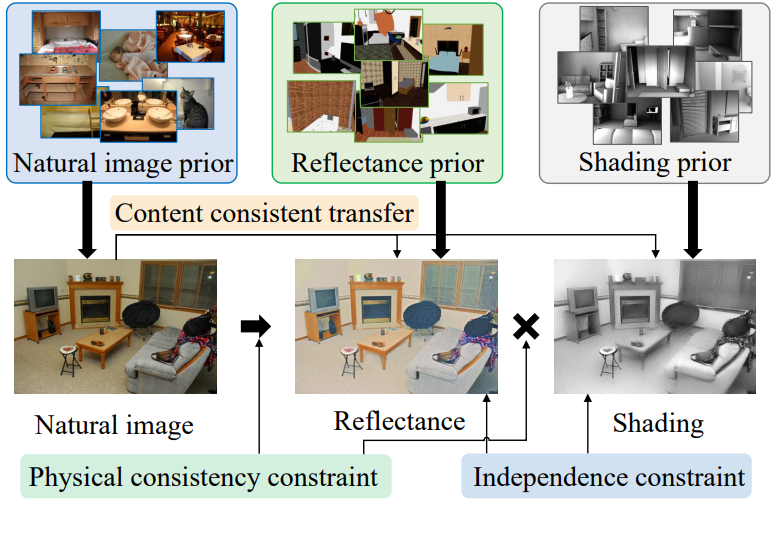
Figure 1. Our method learns intrinsic image decomposition in an unsupervised fashion where the ground truth reflectance and shading is not available in the training data. We learn the distribution priors from unlabeled and uncorrelated collections of natural image, reflectance and shading. Then we perform intrinsic image decomposition through content preserving image translation with independence constraint and physical consistency constraint.
本文的方法无监督的方式学习本征图像分解,真实的反射率和照度是无标签的训练数据。我们从未标记和不相关的自然图像、反射率和照度集合中学习分布先验。然后,在独立约束和物理一致性约束下,通过保留内容的图像平移来实现图像的本征分解。
Abstract
Intrinsic image decomposition, which is an essential task in computer vision, aims to infer the reflectance and shading of the scene. It is challenging since it needs to separate one image into two components. To tackle this, conventional methods introduce various priors to constrain the solution, yet with limited performance. Meanwhile, the problem is typically solved by supervised learning methods, which is actually not an ideal solution since obtaining ground truth reflectance and shading for massive general natural scenes is challenging and even impossible.
In this paper, we propose a novel unsupervised intrinsic image decomposition framework, which relies on neither labelled training data nor hand-crafted priors. Instead, it directly learns the latent feature of reflectance and shading from unsupervised and uncorrelated data. To enable this, we explore the independence between reflectance and shading, the domain invariant content constraint and the physical constraint.
Extensive experiments on both synthetic and real image datasets demonstrate consistently superior performance of the proposed method.
第一段,四句话分别说了:介绍了本征图分解是干嘛的;难点在哪里;传统非深度学习(效果一般);和监督学习(很难获得真实的反射率图像和照度图像)方法的不足。
第二段,三句话分别说了:本文非监督图像本征分解最大的特点:既没有标记训练数据,也没有手工制作的先验;训练数据集:从无监督和不相关的数据中学习反射和照度的潜在特征;方法的核心思想:探索反射率和照度之间的独立性,域不变内容约束和物理约束。
第三段,实验结论。
Introduction
The appearance of a natural image depends on various factors, such as illumination, shape and material. Intrinsic image decomposition aims to decompose such a natural image into an illumination-invariant component and an illumination-variant component. Therefore, it can benefit a variety of high-level computer vision tasks such as texture editing [3], face appearance editing [5] and many others. In this paper, we follow the common practice [8, 18, 28] that assumes the ideal Lambertian surface. Then, a natural image I can be decomposed as the pixel-wise product of the illumination invariance, the reflectance R(I); and the illumination variance, the shading S(I), i.e.,
Eq. (1) is ill-posed because there are twice the unknowns than the knowns. Conventional methods [3, 18] therefore explore physical priors as extra constraints, while recent researches tend to use deep neutral networks to directly learn such priors [8, 28, 33, 38].
本征分解算法原理简介:
自然图像的外观取决于各种因素,如光照、形状和材料。本征图像分解的目的是将这样的自然图像分解为照度不变分量和照度变化分量。因此,它可以有利于各种高级计算机视觉任务,如纹理编辑 [3],人脸外观编辑 [5] 等许多其他。本文遵循理想朗伯面的假设 [8,18,28]。然后,将自然图像 I 分解为照度不变性的反射图 R(I) 和照度变化的照度图 S(I) 的逐像素积。
式(1)是不适定的,因为未知量是已知量的两倍。因此,传统的方法[3,18]将物理先验视为额外的约束,而最近的研究倾向于使用深度神经网络直接学习这些先验。
Unlike high-level vision tasks, intrinsic image decomposition is obviously physics-based, and therefore designing a supervised learning method will heavily rely on high quality physical realistic ground truth. However, existing datasets are either created from a small set of manually painted objects [9], synthetic objects or scenes [4, 6, 19] or manual annotations [15, 31]. These datasets are either too small or far from natural images and therefore limit the performance of supervised learning.
监督学习方法最大问题:
与高阶视觉任务不同,内在图像分解显然是基于物理的,因此设计一种监督学习方法将严重依赖于高质量的物理逼真的真实图像。然而,现有的数据集要么是从一小组手动绘制的对象[9]、合成对象或场景[4,6,19]创建的,要么是手工标注[15,31]。这些数据集要么太小,要么离自然图像太远,因此限制了监督学习的性能。
A few semi-supervised and unsupervised learning methods have been exploited very recently. Janner et al. [14] proposed self-supervised intrinsic image decomposition which relies on few labelled training data and then transfers to other unlabelled data. However, many other supervised information such as shape of the object need be involved. Li et al. [20] and Ma et al. [26] work on unlabelled image sequences where the scene requires to be fixed within the sequence and only the lighting and shading allow to change. Such settings are still very limited.
现有的半监督和非监督学习方法问题:
一些半监督和非监督学习方法最近已经被开发出来。Janner等人[14]提出了自我监督的本征图像分解,它依赖于少量带标记的训练数据,然后转移到其他未标记的数据。然而,许多其他的监督信息,如物体的形状需要涉及。Li等人的[20]和Ma等人的[26]工作在未标记的图像序列上,其中场景需要在序列内进行固定,并且只有光照和照度允许改变。这样的设置仍然非常有限。
In this paper, we aim to explore single image unsupervised intrinsic image decomposition.
The key idea is that the natural image, the reflectance and the shading all share the same content, which reflects the nature of the target object in the scene. Therefore, we consider estimating reflectance and shading from a natural image as transferring image style but remaining the image content. Based on such an idea, we can actually use unsupervised learning method to learn the style of natural image, reflectance and shading by collecting three unlabelled and un-correlated samples for each set.
Then we apply auto-encoder and generative-adversarial network to transfer the natural image to the desired style while preserve the underlying content. Unlike naı”ve unsupervised style transfer methods which are from one domain to another, our method transfers from one domain to another two domains with explicit physical meanings. We therefore explicitly adopt three physical constraints into our proposed method which are 1) the physical consistent constraint as in Eq. (1), 2) domain invariant content constraint that natural image and its decomposition layers share the same object, layout, and geometry, 3) the physical independent constraint that reflectance is illumination-invariant and shading is illumination-variant.
本文算法概述:
讲了两点:
1. 核心思想:将反射率图和照度图看成是自然图像的图像迁移产物。
因此,构建的数据集只要是反射率图域的、照度图域的样本即可,不需要一一对应(unlabelled ,un-correlated)。
2. 迁移方法:
迁移方法可不像传统那样,用一个简单的图像迁移网络实现就可以了(CVPR的文章呀,核心思想的点子已经很新颖了,方法技术上还需要大的突破,大概两三个新技术吧)。
本文引入了三个约束:
1)物理一致性约束:即迁移后的反射率图像和照度图像,应该满足公式(1);
2)域内容不变约束:自然图像及其分解层共享相同的对象、布局和几何图形;
3)物理独立性约束:反射率是照度不变的,照度是照度变化的。
Rigorous experiments show that our method can produce superior performance against state-of-the-art unsupervised methods on four benchmarks, namely ShapeNet, MPI Sintel benchmark, MIT intrinsic dataset and IIW. Our method also demonstrates comparable performance with state-ofthe-art fully supervised methods [8, 33], and even outperforms some of them appeared in the recent years [28, 38].
本文的一些实验方法和结果:
实验表明,与最先进的无监督方法相比,本文的方法可以在四个基准上产生更好的性能,即 ShapeNet,MPI sinter 基准,MIT 内在数据集和 IIW。该方法也表现出与最先进的监督方法相当的性能[8,33],甚至超过了近年来出现的一些方法[28,38]。
Method
Problem formulation and assumptions
- Single input intrinsic image decomposition.
To begin with, we formulate the task with precise denotations. As illustrated in Fig. 1 and Eq. (1), the goal of single image intrinsic decomposition is to decompose a natural image, denoted as I, into two layers, illumination-invariance, namely the reflectance R(I); and illumination-variance, namely the shading S(I). Eq. (1) has more ‘unknowns’ than ‘knowns’ and therefore is not directly solvable. Providing sufficient amount of data-samples with ground truths, i.e., the triplet samples
, supervised learning based methods have also been explored[8, 19, 28, 33]. In previous sections, we have discussed the difficulty in obtaining the ground truth. We now focus on unsupervised learning.
简单介绍单输入本征图像分解任务是干嘛的。
- Unsupervised Intrinsic Image Decomposition.
In this section, we define the Unsupervised Single Image Intrinsic Image Decomposition (USI3D) problem. Assuming we collect unlabelled and unrelated samples, we learn the appearance style of each collection. Say, we can learn the style of reflectance, the marginal distribution p(Rj ), by providing a set of unlabelled reflectance images: {Rj ∈ R}; we learn the shading style, the marginal distribution p(Sk), by providing a set of unlabelled shading images: {Sk ∈ S}; and we learn the natural image style, marginal distribution p(Ii), by providing a set of unlabelled natural images: {Ii ∈ I}. Then, we aim to infer R(Ii), S(Ii) of Ii from the marginal distributions. To make the task tractable, we make the following three assumptions.
介绍无监督单图像固有图像分解问题:
假设我们收集未标记的和不相关的样本,我们学习每个集合的风格。例如,可以通过提供一组未标记的反射率图像来学习反射率的样式,即边缘分布 p(Rj): {Rj∈R};我们通过提供一组无标记的照度图像来学习照度样式,边缘分布p(Sk): {Sk∈S};我们通过提供一组未标记的自然图像 p(Ii): {Ii∈I} 来学习自然图像的样式,边缘分布 p(Ii)。然后,我们从边缘分布推断出 Ii 的 R(Ii), S(Ii)。为了使任务易于处理,我们做了以下三个假设。
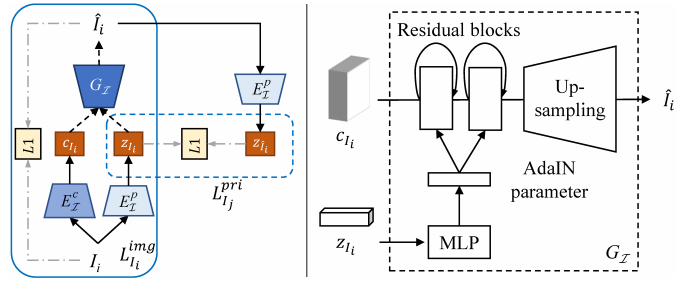
Assumption-1. Domain invariant content. Physically, the natural appearance, the reflectance and the shading are all the appearance of a given object. As illustrated in Fig. 2, we assume such object property can be latent coded and shared amount domains. Following a style transfer terminology, we call such shared property as content, denoted as c ∈ C. Also, we assume the content can be encoded from all three domains.
Assumption-2. Reflectance-shading independence. Physically, reflectance is the invariance against lighting and orientation while shading is the variance. And therefore, to decompose these two components, we assume their conditional priors are independent and can be learned separately. As illustrated in Fig. 2, we denote the latent prior for reflectance as zR ∈ ZR which can be encoded from both the reflectance domain and the natural image domains. Similarly, we define the latent prior for shading, zS ∈ ZS .
Assumption-3. The latent code encoders are reversible. This assumption is widely used in image-to-image translation [12, 17]. In detail, it assumes an image can be encoded into the latent code, which can be decoded to image at the same time. This allows us to transfer style and contents among domains. Particularly, this allow us to transfer natural image to reflectance and shading.
假设1:域的内容不变。物理上,自然的外观,反射率和照度都是给定物体的外观。如图2所示,我们假设这样的对象属性可以是潜在编码和共享的数量域。根据样式转换术语,我们将这样的共享属性称为内容,表示为c∈c。此外,我们假定内容可以从所有三个域编码。
假设2:反射率和照度独立。物理上,反射率是对照度和方向的不变性,而照度是方差。因此,为了分解这两个成分,我们假设它们的条件先验是独立的,可以分别学习。如图2所示,我们将反射率的潜在先验表示为zR∈zR,可以从反射率域和自然像域进行编码。类似地,我们为照度定义了潜伏先验,zS∈zS。
假设3:潜在代码编码器是可逆的。这种假设被广泛应用于图像到图像的转换中[12,17]。具体来说,该算法假设一幅图像可以被编码成潜码,潜码可以同时解码成图像。这允许我们在域之间传递样式和内容。特别是,这让我们可以把自然图像转换成反射率和照度。
Figure 2. Content preserving translation among domains. I is the domain of natural image. S is the domain of shading and R is the domain of reflectance. For our unsupervised learning method, we learn a set of encoders which encode the appearance from each domain to domain-invariance latent space C. We also learn the encoders to encode the appearance to domain-depended prior space for reflectance (ZR) and shading (ZS ) correspondingly. Later the image style can be transferred from encoders (solid arrows) to generators (dash arrows).
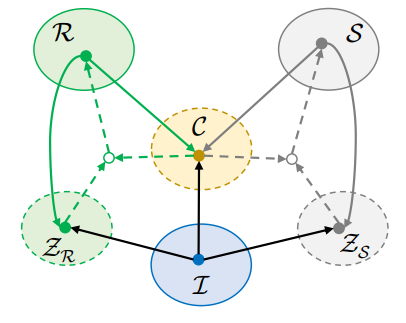
图2:内容保持的域迁移。I 是自然图像的领域。S 为照度域,R 为反射率域。对于无监督学习方法,学习一组编码器,将外观从每个域编码到域不变性潜在空间 c,还学习编码器将外观编码到依赖域的先验空间反射 (ZR) 和照度(ZS)。稍后,图像样式可以从编码器 (实心箭头) 转移到生成器 (虚线箭头)。
Implementation
- The Content-sharing architecture.
As with Assumption1, we design our content-sharing architecture. We use encoder
to extract the content code c of the input image
, then c is used to generate the decomposition layers
and
through generators
and
, respectively. Next, we extract the content code
of
of
, respectively. Finally, we apply content consistent loss to make content encoders
work correctly. In detail, we use the content consistency
to constrain the content code among input image
where
is L1 distance.
- 内容共享网络结构:内容编码的网络结构和约束
1. 编码器 ![]() :从自然图像得到内容编码 c;
:从自然图像得到内容编码 c;
2. 生成器 ![]() and
and ![]() :从 c 生成反射率图像
:从 c 生成反射率图像 ![]() 和照度图像
和照度图像 ![]() ;
;
3. 编码器 ![]() :从反射率图像
:从反射率图像 ![]() 和照度图像
和照度图像 ![]() 分别得到内容编码
分别得到内容编码 ![]() 和
和 ![]() ;
;
4. 内容一致损失![]() :内容编码 c,
:内容编码 c, ![]() 和
和 ![]() 应该是是一致的,如公式(2),这个损失函数用于训练编码器
应该是是一致的,如公式(2),这个损失函数用于训练编码器 ![]() 。
。
Figure 3. The proposed architecture of USI3D. Our method decompose intrinsic images with unsupervised learning manner, which translate images from natural image domain I to reflectance domain R and shading domain S.
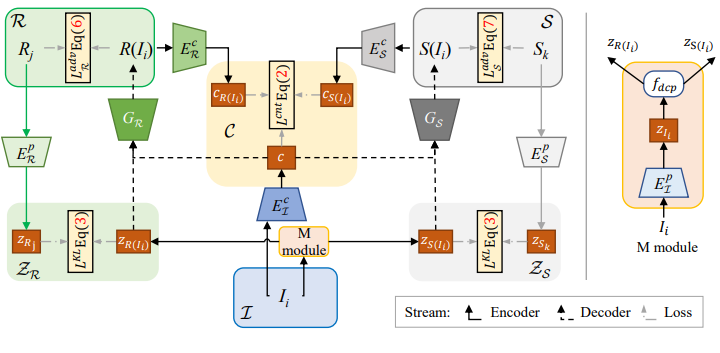
- Mapping module (M module).
Following the Assumption-2, the prior codes of reflectance and shading are domain-variant and independent to each other. Because we need to infer the prior code
from
, then we designed a decomposition mapping
to infer the prior code . To constrain the
in the reflectance prior domain
, we use Kllback-Leibler Divergence (KLD) and other real prior
which is sampled from
is generated and constrained in the similar way. The definition KLD loss is
where the prior code
is extracted from M module and its real prior code z is extracted from its real image. Here are two prior domains
, so the total KLD loss is
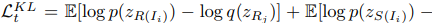
.
- 匹配模块:先验编码的网络解构和约束,这里的先验编码即通常说的特征编码。
根据假设-2,反射率和照度的先验编码是领域变化的,彼此独立。本文的做法是,
1. M 模块 (M module):得到自然图像的先验编码 ![]() ;
;
2. 分解映射 ![]() :通过对
:通过对 ![]() 进行分解映射,得到反射率和照度的先验编码
进行分解映射,得到反射率和照度的先验编码 ![]() ;
;
3. KLD 损失函数对 ![]() 进行约束:
进行约束:![]() 来自真实的、非配对的反射率数据集;同理
来自真实的、非配对的反射率数据集;同理 ![]() 来自真实的、非配对的照度数据集;KLD 约束就是说,
来自真实的、非配对的照度数据集;KLD 约束就是说,![]() 和
和 ![]() 的概率分布应该是近似的,
的概率分布应该是近似的,![]() 和
和 ![]() 的概率分布是近似的。
的概率分布是近似的。
- Auto-encoders
Per Assumption-3, we implement three auto-encoders. Left of Fig. 4 shows the detail of implementing the auto-encoder for natural image stream. The auto-encoder for reflectance and shading are implemented in a similar way where the detail are provided in the supplementary material. We follow the recent image-to-image translation methods [12, 17] and use bidirectional reconstruction constraints which enables reconstruction in both image → latent code → image and latent code → image → latent code directions.
Figure 4. Left: Auto-encoder for natural image stream, the reflectance and shading streams are designed similarly. Right: Architecture of the generator.
- 自动编码器:详细介绍内容编码和先验编码的 生成网络 结构
根据假设-3,本文实现了三个自动编码器。图4左侧显示了实现自然图像流自动编码器的细节。反射和照度的自动编码器以类似的方式实现,细节在补充材料中提供。我们遵循最近的图像-图像转换方法[12,17],采用双向重构约束,使重构分别在图像→隐码→图像和隐码→图像→隐码两个方向进行。
图 4 已经可以看出解耦网络的结构了。下面详细介绍自动编码器的训练约束:
1. Image reconstruction loss
Given an image sampled from the data distribution, we can reconstruct it after encoding and decoding.
图像重构约束:
意思是说,图像(包括自然图像、反射率图像和照度图像)分解为内容编码和先验编码后,再将二者合并生成的图像应该与原图像相同。
文章用 L1 损失实现该约束。
2. Prior code reconstruction loss.
Given a prior code sampled from the latent distribution at decomposition time, we should be able to reconstruct it after decoding and encoding. Different from Eq.(3), which is suitable to constrain the distributions of two samples, the constraint of the prior codes of the image and the reconstructed image should be identical.
To make the decomposed intrinsic image be indistinguishable from real image in the target domain, we use GANs to match the distribution of generated images to the target data distribution. The adversarial losses are defined as follow:
We notice that Eq. (1) means that image Ii is equal to the pixel-product of its analogous R(Ii) and S(Ii), thus this physical loss can be employed to regularize our method.
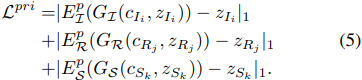
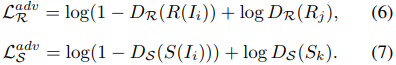
先验编码重构约束:
意思是说,从原图像(包括自然图像、反射率图像和照度图像)分解的先验编码,应该与从重构图像(包括重构的自然图像、反射率图像和照度图像)分解的先验编码是相同的。
文章用三个方法实现这个约束:
1. L1 损失:容易理解,不解释了;
2. 对抗损失:为了使分解后的本征图像在目标域内与真实图像无法区分,又使用 GANs 将生成的图像分布与目标数据分布进行匹配。
GAN 网络确实是用来使特征编码(先验编码)分布概率相同的方法。
3. 物理约束:也好理解。当然,也是对先验编码的约束。
Implementation details
Encoders
The distribution prior encoder Ep is constructed by several strided convolutional layers to downsample the input image, then followed by a global average pooling layer and a dense layer
Our content encoder Ec includes several strided convolutional layers and several residual blocks [10] to downsample the input.
All convolutional layers are followed by Instance Normalization.
We implement the distribution prior mapping function
via multi-layer perceptron (MLP). More specifically, the
.
Generator
The generator reconstructs the image from its content feature and distribution prior. As illustrated in the right of Fig. 4, it processes the content feature by several unsampling and convolutional layers. Inspired by recent unsupervised image-to-image translation works that use affine transformation parameters in normalization layers to represent image styles [11, 12], hence we use image style to represent intrinsic image distribution priors. To this end, we equip the Adaptive Instance Normalization (AdaIN) [11] after each of convolutional layers in residual blocks. The parameters of AdaIN are dynamically generated by a MLP from the distribution prior.
Discriminator
We use multi-scale discriminators [35] to guide the generators to generate high quality images in different scales including correct global structure and realistic details. We employ the LSGAN [27] as the objective.
先验编码: 若干带有步进的卷积层(分辨率下采样),最后跟一个全局平均池化(压缩成一组编码向量)和一个密集层;
内容编码:若干带有步进的卷积层+若干残差网络模块(分辨率下采样);
所有的归一化均采用:Instance Normalization
先验映射函数 ![]() :多层感知器 (MLP)。输入是自然图像的先验编码
:多层感知器 (MLP)。输入是自然图像的先验编码 ![]() ,输出是反射率和照度图像的先验编码
,输出是反射率和照度图像的先验编码 ![]() 。
。
图像重构生成器:根据图像的内容特征和先验的分布来重建图像。如图 4 右侧所示,通过几个反采样和卷积层对内容特征进行处理。受最近的无监督图像到图像翻译方法的启发,在归一化层中使用仿射变换参数来表示图像风格[11,12],因此本文使用图像风格来表示本征图像先验分布。为此,在残差网络模块的每个卷积层之后都配置了自适应实例归一化 (AdaIN)[11]。AdaIN 的参数由 MLP 根据先验分布动态生成。
判别器:采用多尺度鉴别器[35]来指导生成不同尺度的高质量图像,包括正确的全局结构和真实的细节。用 LSGAN[27] 中的判别器结构。
Dataset
- ShapeNet
https://shapenet.org
[paper]
We use 8979 input images, 8978 reflectance images and 8978 shadings to train USI3D , each set is shuffled before training. We use the other 2245 images for evaluation.
用 8979 输入图像、8978 反射图像和 8978 照度图像对 USI3D 进行训练,训练前对每组图像进行洗牌。我们使用其他 2245 张图像进行评估。洗牌的目的就是为了不配对,做到无监督。
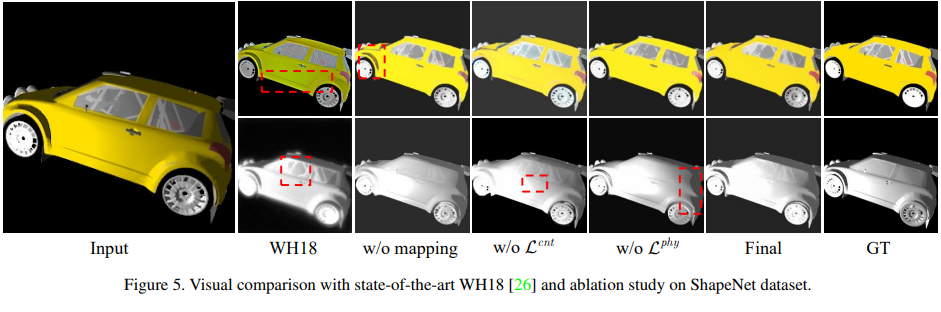
图 5 是本文的一个消融实验对比,并且和 WH18 这个方法做了对比。
- MPI-Sintel benchmark
http://sintel.is.tue.mpg.de
[paper]
MPI-Sintel benchmark [4] is a synthesized dataset, which includes 890 images from 18 scenes with 50 frames each (except for one that contains 40 images). We follow FY18[8] and make data argumentation(单词写错了吧,应该是 augmentation), after that, 8900 patches of images are generated. Then, we adopt two-fold cross validation to obtain all 890 test results. In the training set, we randomly select half of the input image as input samples, the reflectance and shading with remain file names as our reflectance samples and shading samples, respectively
MPI-Sintel 基准[4]是一个合成数据集,包括来自18个场景的 890 幅图像,每幅 50 帧(除了一个包含40幅图像)。我们遵循 FY18[8] 进行数据扩增,生成 8900 个图像 patch。然后,采用双交叉验证得到所有的 890 个检验结果。在训练集中,我们随机选取一半的输入图像作为输入样本,保留文件名的反射率和照度图像分别作为我们的反射率样本和照度样本.

- MIT intrinsic dataset
http://www.cs.toronto.edu/~rgrosse/intrinsic/
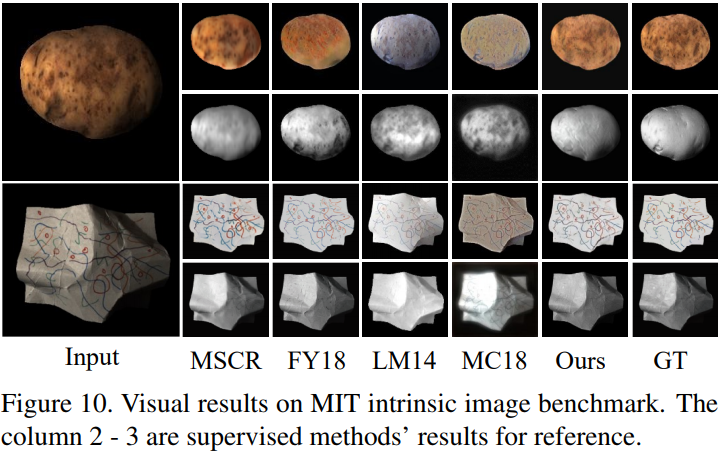
To test performance on real images, we use the 220 images in the MIT intrinsic dataset [32] as in [28]. This data contains only 20 different objects, each of which has 11 images. To compare with previous methods, we finetune our model using 10 objects via the split from [8], and evaluate the results using the remaining objects.
为了测试在真实图像上的性能,使用了 MIT 本征数据集[32]中的 220 幅图像。这个数据只包含 20 个不同的对象,每个对象有 11 张图像。为了与以前的方法进行比较,我们通过[8]的分割使用 10 个对象来微调我们的模型,并使用剩下的对象来评估结果。
- IIW benchmark + CGIntrinsics Dataset
IIW benchmark : http://opensurfaces.cs.cornell.edu/publications/intrinsic/
CGIntrinsics Dataset: http://www.cs.cornell.edu/projects/cgintrinsics/
The Intrinsic Images in the Wild (IIW) benchmark [31] contains 5,230 real images of mostly indoor scenes, combined with a total of 872,161 human judgments regarding the relative reflectance between pairs of points sparsely selected throughout the images. We split the input images of IIW into a training set (4184) and test set in the same way as [8, 19]. Because the IIW dataset contains no reflectance and shading images, we employ unpaired reflectance and shading from the rendered dataset CGIntrinsics [19]. To make a fair training, we choose the first 4000 consecutive reflectance sorted by the image ID and the last 4000 shading images for training. Samples of the training set are illustrated in Fig. 7.
IIW 基准[31]包含 5230 幅主要为室内场景的真实图像,并结合人类对图像中稀疏选择的点对之间的相对反射率的判断共 872,161 幅。我们将 IIW 的输入图像分割为训练集 (4184) 和测试集,方法与[8,19]相同。因为 IIW 数据集不包含反射率和照度图像,所以我们使用了渲染数据集 CGIntrinsics[19] 中未配对的反射率和照度。为了进行公平的训练,我们选择了按照图像 ID 排序的前 4000 张连续反射率和后 4000 张照度图像进行训练。训练集的样本如图7所示。

最后
以上就是傻傻玉米最近收集整理的关于MyDLNote-Unsupervised: 2020CVPR 无监督学习的本征图像分解Unsupervised Learning for Intrinsic Image Decomposition from a Single Image的全部内容,更多相关MyDLNote-Unsupervised:内容请搜索靠谱客的其他文章。








发表评论 取消回复