目录
一、矩阵乘法测试
二、测试结果
一、矩阵乘法测试
通过一个简单的矩阵乘法,和L2距离计算来测试NPU计算性能与启动NPU的一般方法。具体代码如下:
/**
* Example: Calculate (x-y)^2 using Matmul API
*/
/*-------------------------------------------
Includes
-------------------------------------------*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <time.h>
#include <sys/time.h>
#include <math.h>
#include "rknn_matmul_api.h"
/*-------------------------------------------
Macros and Variables
-------------------------------------------*/
double __get_us(struct timeval t) { return (t.tv_sec * 1000000 + t.tv_usec); }
static int gen_random_data(int8_t *x,int len,int min_value,int max_value)
{
srand((unsigned int)time(NULL));
int range = max_value-min_value+1;
for (int i = 0;i<len;++i)
{
x[i] = (int)rand()%range+min_value;
}
return 0;
}
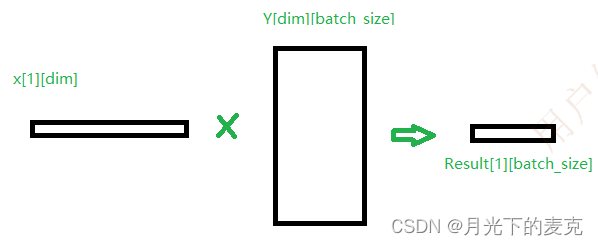
//sum([K,1]*[K,N]) =[1,N]
//dim_len=K,batch_size=N
static int multiply_sum_cpu(int8_t *x,int8_t *y,int dim_len,int batch_size,float *res)
{
for (int i = 0;i<batch_size;++i)
{
float sum = 0.0;
for(int j = 0;j<dim_len;++j)
{
int offset = j*batch_size+i;
float mul = ((int32_t)x[j])*((int32_t)y[offset]);
sum+=mul;
}
res[i] = sum;
}
return 0;
}
static int l2_distance_cpu(int8_t *x,int8_t *y,int dim_len,int batch_size,float *res)
{
for (int i = 0;i<batch_size;++i)
{
float sum = 0.0;
for(int j = 0;j<dim_len;++j)
{
int offset = j*batch_size+i;
float mul = ((int)x[j])-((int)y[offset]);
sum+=mul*mul;
}
res[i] = sum;
}
return 0;
}
//calculate y^2
static int pre_process_y(int8_t * y,int dim_len, int batch_size, int *square_y)
{
for (int i = 0;i<batch_size;++i)
{
int sum = 0;
for(int j = 0;j<dim_len;++j)
{
int offset = j*batch_size+i;
int mul = ((int)y[offset])*((int)y[offset]);
sum+=mul;
}
square_y[i] = sum;
}
return 0;
}
static int get_sum(int8_t * x, int *square_y,int dim_len, int batch_size,float *xy) {
int x_sum = 0;
for(int j = 0;j<dim_len;++j) {
x_sum += ((int)x[j])*((int)x[j]);
}
for (int i = 0;i<batch_size;++i) {
xy[i] = x_sum-2*xy[i]+square_y[i];
}
return 0;
}
static float cal_relative_err(float *rknn_out,float *cpu_out,int len) {
float sum = 0.0;
for(int i = 0;i<len;++i) {
float err = (fabs(rknn_out[i] - cpu_out[i]))/(cpu_out[i]+0.000000001);
sum+=err;
}
return sum/(float)len;
}
/*-------------------------------------------
Main Functions
-------------------------------------------*/
int main
(
int argc,
char **argv
)
{
if(argc != 3)
{
printf("Info: Get L2 distance for matrix A: Kx1, matrix B: KxNn");
printf("Usage: %s <K> <N>n",argv[0]);
return -1;
}
int DIM = atoi(argv[1]);
int BATCH_SIZE = atoi(argv[2]);
rknn_tensor_type dtype = RKNN_TENSOR_INT8;
int8_t *x = (int8_t *)malloc(DIM*sizeof(int8_t));
int8_t *y = (int8_t *)malloc(DIM*BATCH_SIZE*sizeof(int8_t));
float out_fp32_buf[BATCH_SIZE];
float res_cpu[BATCH_SIZE];
int x_size = DIM;
int y_size = DIM*BATCH_SIZE;
int test_count = 100;
float err;
struct timeval start_time, stop_time;
int *square_y = (int *)malloc(BATCH_SIZE*sizeof(int));
//generate random test data
gen_random_data(x,x_size,-128,127);
gen_random_data(y,y_size,-128,127);
pre_process_y(y,DIM,BATCH_SIZE,square_y);
rknn_matmul_handle_t handle= rknn_matmul_load(x,y, 1, DIM, BATCH_SIZE, dtype);
if (handle == NULL)
{
fprintf(stderr, "rknn_matmul_load failed.n");
return -1;
}
//loop for matmul
gettimeofday(&start_time, NULL);
for(int i = 0;i<test_count;++i) {
// can set x/y values before run
// ...
rknn_matmul_run(handle,out_fp32_buf);
}
gettimeofday(&stop_time, NULL);
printf("run Matmul %d times, average time:%f msn", test_count ,(__get_us(stop_time) - __get_us(start_time)) / (1000.0*test_count));
//get matmul err
int element_num = BATCH_SIZE;
multiply_sum_cpu(x,y,DIM,BATCH_SIZE,res_cpu);
//show 10 data
printf("compare first 10 results (npu vs cpu)n");
for(int i = 0;i<(10<BATCH_SIZE?10:BATCH_SIZE); ++i)
{
printf("[%d] % -12.2f vs % -8.2fn",i,out_fp32_buf[i],res_cpu[i]);
}
err = cal_relative_err(out_fp32_buf,res_cpu,element_num);
printf("[Matmul INT8] average relative err = %fn",err);
//get (x-y)^2 err
get_sum(x,square_y,DIM,BATCH_SIZE,out_fp32_buf);
l2_distance_cpu(x,y,DIM,BATCH_SIZE,res_cpu);
err = cal_relative_err(out_fp32_buf,res_cpu,element_num);
printf("[L2 distance INT8] average relative err = %fn",err);
rknn_matmul_unload(handle);
if(square_y) {
free(square_y);
}
if(x)
{
free(x);
}
if(y)
{
free(y);
}
return 0;
}
二、测试结果
[root@RV1126_RV1109:/]# ./userdata/rknn_matmul_sample/bin/rknn_matmul_sample 100 100
run Matmul 100 times, average time:0.322500 ms
compare first 10 results (npu vs cpu)
[0]
68448.00
vs
68462.00
[1] -48960.00
vs -48972.00
[2]
36576.00
vs
36591.00
[3]
40192.00
vs
40192.00
[4]
29440.00
vs
29445.00
[5] -85280.00
vs -85279.00
[6]
116640.00
vs
116635.00
[7]
104352.00
vs
104349.00
[8]
111360.00
vs
111371.00
[9]
69280.00
vs
69298.00
[Matmul INT8] average relative err = 0.000171
[L2 distance INT8] average relative err = 0.000015
最后
以上就是飘逸飞机最近收集整理的关于RK1109 NPU算法测试demo一、矩阵乘法测试二、测试结果的全部内容,更多相关RK1109内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复