一.DataFrame和DataSet的API
从Spark 2.0开始,DataFrame和Dataset可以表示静态的有界数据以及流式无界数据。与静态数据集/数据框类似,可以使用公共入口点SparkSession (Scala / Java / Python / R docs)从流源创建流式数据框/数据集,并对它们应用与静态数据框/数据集相同的操作。
二.创建DataFrame和DataSet
可以通过由返回的DataStreamReader接口(Scala / Java / Python文档)的SparkSession.readStream()创建流式DataFrame 。在R中,使用read.stream()方法。与用于创建静态DataFrame的读取接口类似,可以指定源的详细信息:数据格式,架构,选项等。
1.输入源【内置】
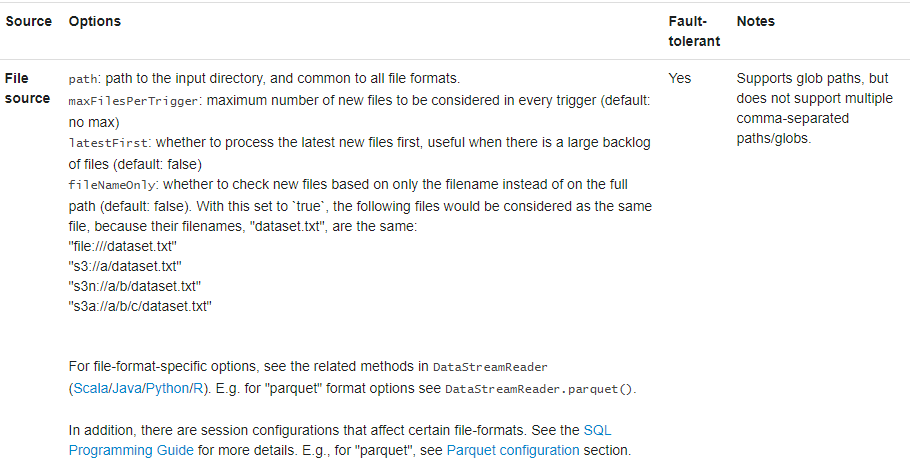
- File Source文件源:读取写入目录的文件作为数据流。支持的文件格式为text,csv,json,orc,parquet。请注意,文件必须原子地放置在给定目录中,在大多数文件系统中,这可以通过文件移动操作来实现。
- Kafka:从Kafka读取数据。它与0.10.0或更高版本的Kafka代理兼容。
- Socket【用于测试】:从套接字连接读取UTF8文本数据。监听服务器套接字位于驱动程序处。请注意,这仅应用于测试,因为这不能提供端到端的容错保证。
- Rate source【用于测试】:以每秒指定的行数生成数据,每个输出行包含timestamp和value。where timestamp是Timestamp包含消息分发时间的类型,并且value是Long包含消息计数的类型,从0开始作为第一行。此源旨在进行测试和基准测试。
某些源不是容错的,因为它们不能保证故障后可以使用检查点偏移来重放数据。

2.例子
val spark: SparkSession = ...
// Read text from socket
val socketDF = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
socketDF.isStreaming // Returns True for DataFrames that have streaming sources
socketDF.printSchema
// Read all the csv files written atomically in a directory
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark
.readStream
.option("sep", ";")
.schema(userSchema) // Specify schema of the csv files
.csv("/path/to/directory") // Equivalent to format("csv").load("/path/to/directory")
这些示例生成未类型化的流式DataFrame,这意味着在编译时不检查DataFrame的架构,仅在提交查询时在运行时检查它。有些操作(如map,flatMap等)需要在编译时知道类型。为此,可以使用与静态DataFrame相同的方法将这些未类型化的流数据框架转换为已类型化的流数据集。
三.streaming DataFrame/DataSet的模式推断和分区
默认情况下,从基于文件的源进行结构化流传输需要指定架构,而不是依靠Spark自动推断。此限制确保即使在发生故障的情况下,也将一致的架构用于流查询。对于临时用例,可以通过将设置spark.sql.streaming.schemaInference为true来重新启用模式推断。
当存在命名的子目录时,分区发现确实会发生,/key=value/并且列表将自动递归到这些目录中。如果这些列出现在用户提供的架构中,Spark将根据读取文件的路径来填充它们。启动查询时,必须存在组成分区方案的目录,并且这些目录必须保持静态。
四.基本操作-选择,投影,汇总
流上支持DataFrame / Dataset上的大多数常见操作。稍后将讨论不支持的一些操作。
case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
val df: DataFrame = ... // streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string }
val ds: Dataset[DeviceData] = df.as[DeviceData] // streaming Dataset with IOT device data
// Select the devices which have signal more than 10
df.select("device").where("signal > 10") // using untyped APIs
ds.filter(_.signal > 10).map(_.device) // using typed APIs
// Running count of the number of updates for each device type
df.groupBy("deviceType").count() // using untyped API
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed API
还可以将流式DataFrame / Dataset注册为临时视图,然后在其上应用SQL命令。
df.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") // returns another streaming DF
注意,可以使用df.isStreaming来确定DataFrame / Dataset是否具有流数据。
最后
以上就是直率母鸡最近收集整理的关于Spark结构化流编程【Dataset、DataFrame】的全部内容,更多相关Spark结构化流编程【Dataset、DataFrame】内容请搜索靠谱客的其他文章。








发表评论 取消回复