(1)FPA: Feature Pyramid Attention
作者认为像SENet和EncNet这样对通道加attention是不够的,我们需要对pixel加attention,同时采纳了PSPnet的global pooling的思想,将pooling的结果与加了attention的卷积的结果相加。由于作者的方法会造成计算量的大量增加,为了减少计算量,作者再使用FPA之前减少通道数(PSPnet或者Deeplab则是之后再减少通道数)。
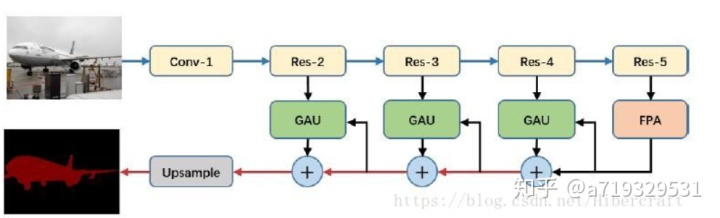
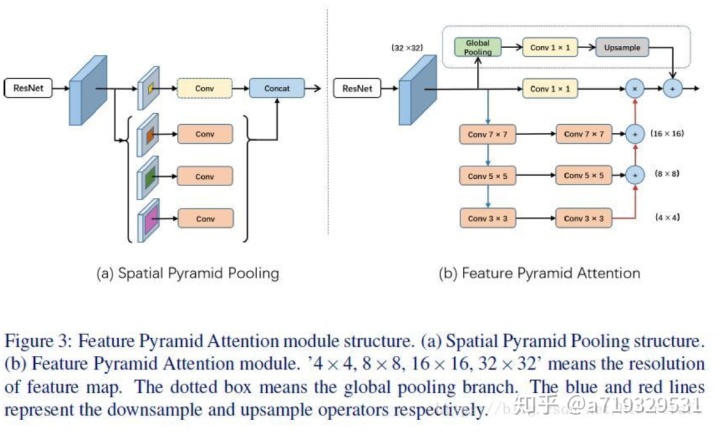
作者提出了分割中常见的两个问题:(1)同个物体可能存在不同的size导致了分类的困难(对于存在多种物体,轮廓是正确的但是分类错误,即把猫圈出来但是认为是狗),而PSPnet和Deeplab系列都是使用ASPP的结构来试图解决这个问题,而认为DeepLab系列使用空洞卷积会导致grid artifacts【28】的问题,而pspnet使用global average pooling则可能失去像素级别的位置信息。因此,作者提出根据高层的特征来得到pixel-level的attention来帮助低层的特征,从而增加感觉野以及更好地分类小物体。(2)高层的特征对于分类很有作用,但是却不利于像素级别的分类,即判断某个像素点属于某个类。所以作者采用对高层的特征进行pool得到一个vector(vector的长度对应通道数),相当于对低层信息的通道进行加权。提出Feature Pyramid Attention module(FPA)和Global Attention Upsample module(GAU),引入注意力机制用于语义分割。现有分割ASPP模型会导致grid artifact;以及pyramid pooling module会很大程度丢失像素位置信息。提出用两个分支,一个分支用pyramid结构预测attention mask,另外再加一个global pooling branch.
FPA(最高层):引入注意力机制用于语义分割。现有分割ASPP模型会导致grid artifact以及pyramid pooling module会很大程度丢失像素位置信息。提出用两个分支,一个分支用pyramid结构预测attention mask,另外再加一个global pooling branch。
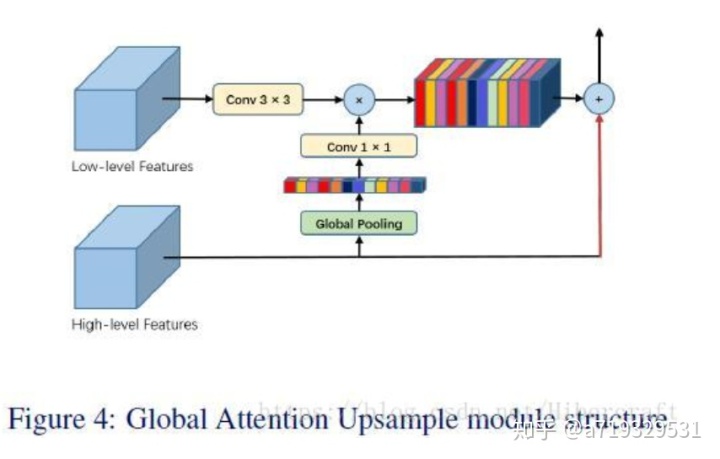
GAU(Global Attention Upsample)是用在decode时候的单元,同样引入注意力机制,基本思路也就是high resolution feature map预测一个channel mask然后乘在low resolution shortcut上,高层的特征带有充足的分类信息可以作为attention去指导低层的信息。
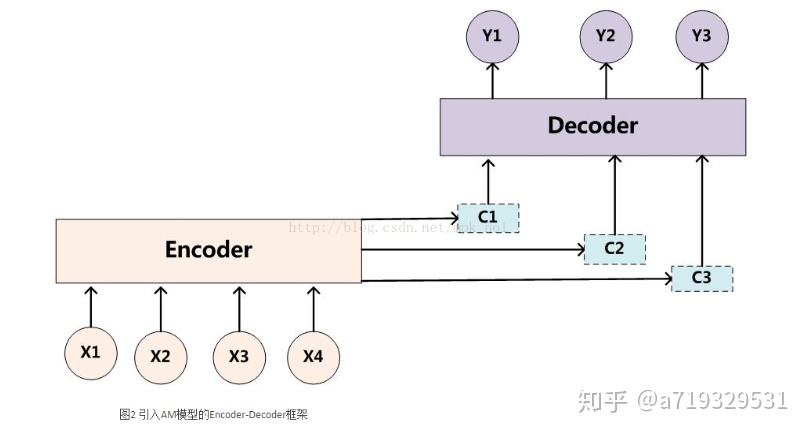
如下图所示,机器翻译主要使用的是Encoder-Decoder模型,在Encoder-Decoder模型的基础上引入了AM,取得了不错的效果:
最后
以上就是可爱芒果最近收集整理的关于通道注意力机制_注意力机制用于语义分割的全部内容,更多相关通道注意力机制_注意力机制用于语义分割内容请搜索靠谱客的其他文章。








发表评论 取消回复