文章目录
相关参考连接:
https://blog.csdn.net/hpulfc/article/details/80448570
https://blog.csdn.net/weixin_42398658/article/details/90804173
https://blog.csdn.net/jesseyule/article/details/101633159
论文讲解:
https://www.jianshu.com/p/25fc600de9fb
https://www.cnblogs.com/robert-dlut/p/8638283.html
https://www.icode9.com/content-4-619546.html
目录
文章目录
一、注意力机制的原理
1.1.背景——人类视觉注意力
1. 2. encoder——decoder框架
1.3.注意力机制
1.3.1 基于encoder-decoder的注意力机制
1.3.2 注意力机制的原理-基于encodr-decoder的软注意力
二、多头注意力
2.1 自注意力机制(self-attention模型)
2.1.1 概念简介
2.2.2 优点
2.2.3 计算过程
2.2 多头注意力(Multi-Head attention)
三、机器翻译(transformer)模型架构
3.1位置编码(positional encoding)
3.2 Add&Norm(Residual connection和layer-normalization)
3.2.1 残差连接(Residual connection)
3.2.2 层归一化(layer-normalization)
3.3 位置前馈方向网络( position-wise feed forward)
3.4 encoder-decoder attention
3.5 Masked Multi-Head Attention
总结
一、注意力机制的原理
1.1.背景——人类视觉注意力

图1
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
1. 2. encoder——decoder框架
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。图2是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。encoder常用RNN。

图2 抽象的文本处理领域的Encoder-Decoder框架
也可以理解为翻译模型:输入源语句source,生成目标语句target(和源语句可以是同一种语言也可以是不同种语言),生成过程如下:
输入和输出:

(1)经过encoder编码生成中间语义表示C:
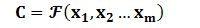
(2)decoder通过C和之前已经生成的历史信息...
生成


1.3.注意力机制
1.3.1 基于encoder-decoder的注意力机制
上文翻译语句中,生成每一个翻译单词时,对输入的每个单词依赖程度相同,短的句子还好,对于比较长的句子,所有单词的语义完全通过固定的中间向量C来表示,会丢失很多细节。
注意力模型采用变化的来分配生成单词对源句子中每个单词的依赖程度。
假设encoder和decoder都用RNN模型来实现,如下图3,则有:

图3 RNN作为具体模型的Encoder-Decoder框架
(1) 生成每个单词的隐藏状态:
(2)中间语义表示,含有目标单词对每个源单词的依赖程度,用概率
表示,
通常为源单词隐藏状态*依赖程度之和(加权平均和)
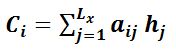
附:每个中
的生成,以“Tom chase Jerry”->“汤姆追逐杰瑞”为例。
对于采用RNN的Decoder来说,在时刻i,如果要生成yi单词,我们是可以知道Target在生成Yi之前的时刻i-1时,隐层节点i-1时刻的输出值的,而我们的目的是要计算生成Yi时输入句子中的单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态
去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,
)来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。


(3)生成decoder阶段的 :
(4)生成target单词:
1.3.2 注意力机制的原理-基于encodr-decoder的软注意力
attention总体计算过程
将3.1中的encoder-decoder框架剥离,做进一步抽象:
抽象:source 看做一组键值对<key,value>: 一般情况下,key=value=输入语句中每个单词对应的语义编码,本文采用k=v
target中的每一个要生成的单词看做一个query(查询):RNN中为前一个的隐藏状态
求target中的每个单词。
按照encoder-decoder算法,且均采用RNN,步骤为:
(1)根据RNN计算source每个key的
(2)计算target中query/对应的中间语义表示
,也可称作Attention(Qeury,Source),
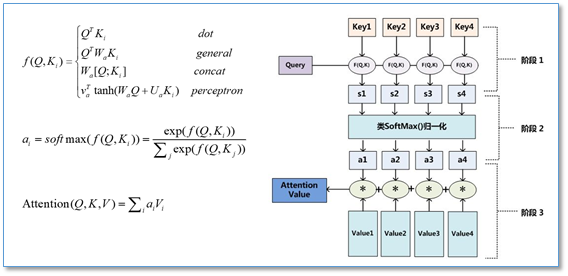
第一阶段:计算
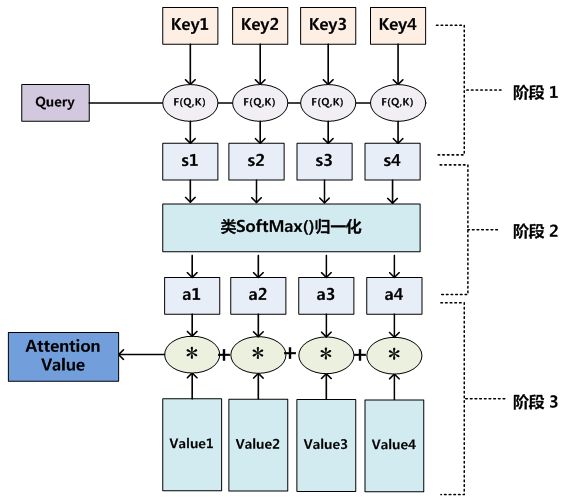
按照encoder-decoder注意力算法,根据和source中的每个
作计算得出每个单词的依赖概率:
计算: 根据函数F(Q,K)/F(
,
)/similarity(Q,K)(简称simi函数)计算两者的相似性。其中,计算两者的相似性,可以引入不同的函数和计算机制,根据Query和某个Key_i,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

计算: 通过softmax函数进行归一化处理,形成依赖概率
。
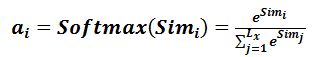
第二阶段:计算
为和
的加权平均和:

(3)计算query的值:RNN中
二、多头注意力
2.1 自注意力机制(self-attention模型)
2.1.1 概念简介
对于基于encoder-decoder框架的注意力机制,其attention是通过target中的query和source中的所有value求得的,学习的是target中的每个元素和source中的所有元素的相关度,而self-attention机制是学习source本身的每个单词和其他单词的相似度, Self Attention可以捕获同一个句子中单词之间的一些句法特征(比如图(a)展示的有一定距离的短语结构make...more difficult)或者语义特征(比如图(b)展示的its的指代对象Law)。
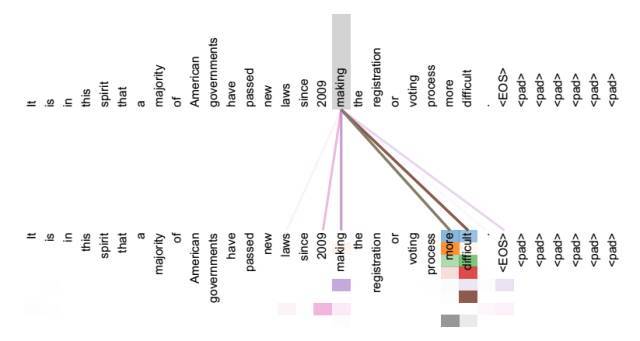
(a) self-attention可视化实例

(b) self-attention可视化实例
2.2.2 优点
相比于RNNRNN或者LSTM:
引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征。因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。
2.2.3 计算过程
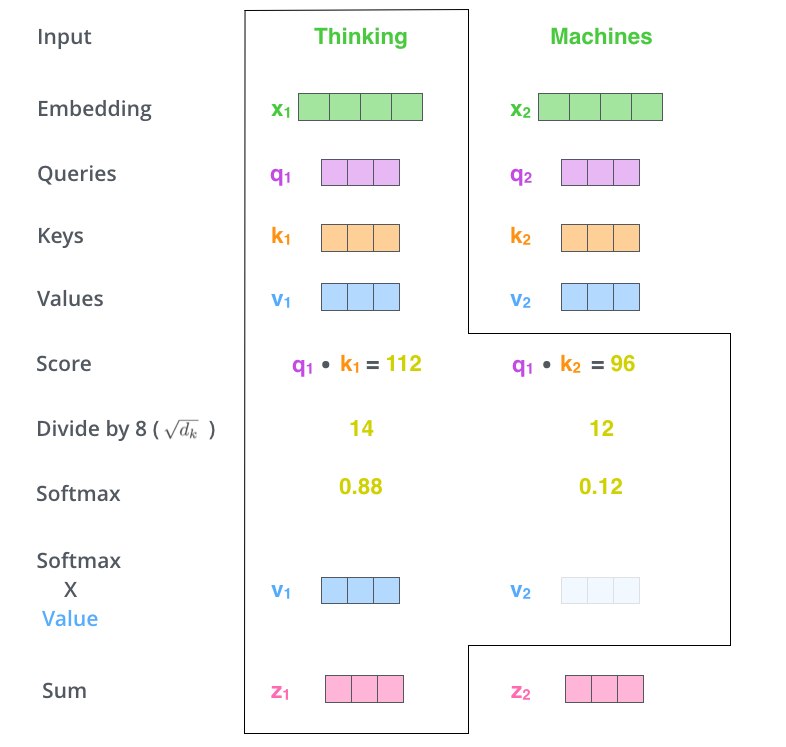
以计算含有thinking和machine两个单词的句子中,thinking的attention为例:
(1)生成词向量(embeddng):thinking->;machine->
.....
(2)计算...
的Q,K,V:
其中,Q,K,V都为维。
(3) 利用缩放点积attention(scaled dot-product attention)方式计算attention:
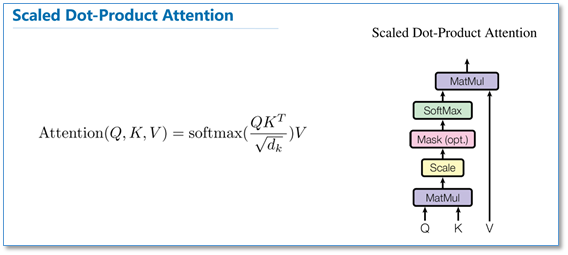
其实scaled dot-Product attention就是我们常用的使用点积进行相似度计算的attention,只是多除了一个(为的维度)起到调节作用,使得内积不至于太大。先进行softmax计算出thinking和其他单词的相似度并进行归一化处理形成概率,然后用概率乘以每个单词的V,加和得到thinking的attention。
2.2 多头注意力(Multi-Head attention)
上面例子计算了句子中一个单词thinking的自注意力,多头注意力就是计算句子中所有单词的注意力,然后将所有值连起来,同时,通过降低维度减少损耗。
eg:
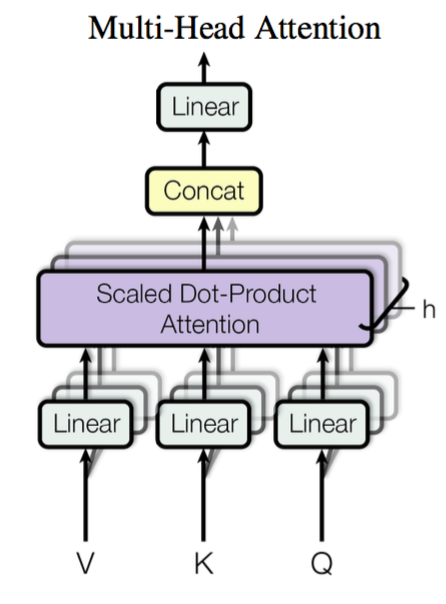
三、机器翻译(transformer)模型架构

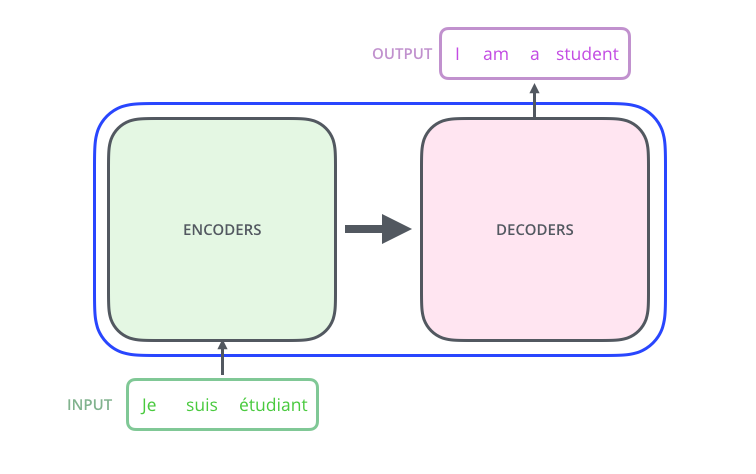
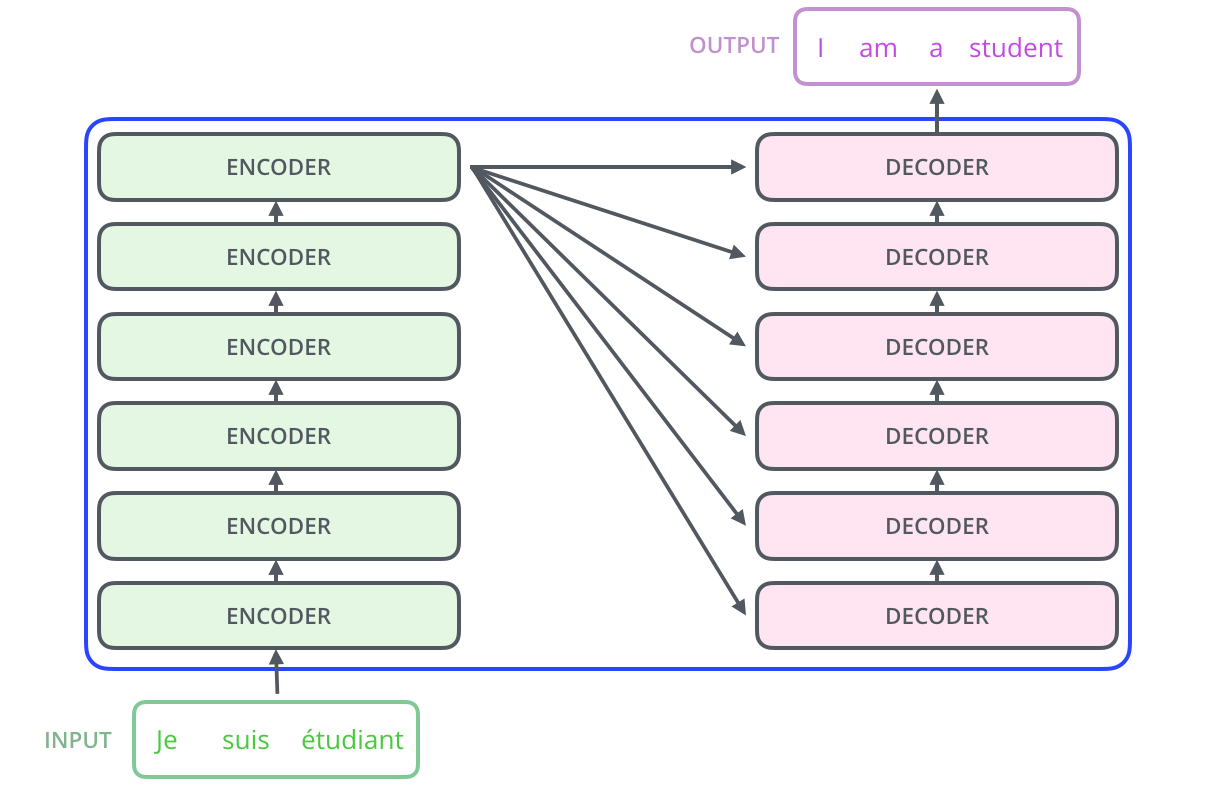
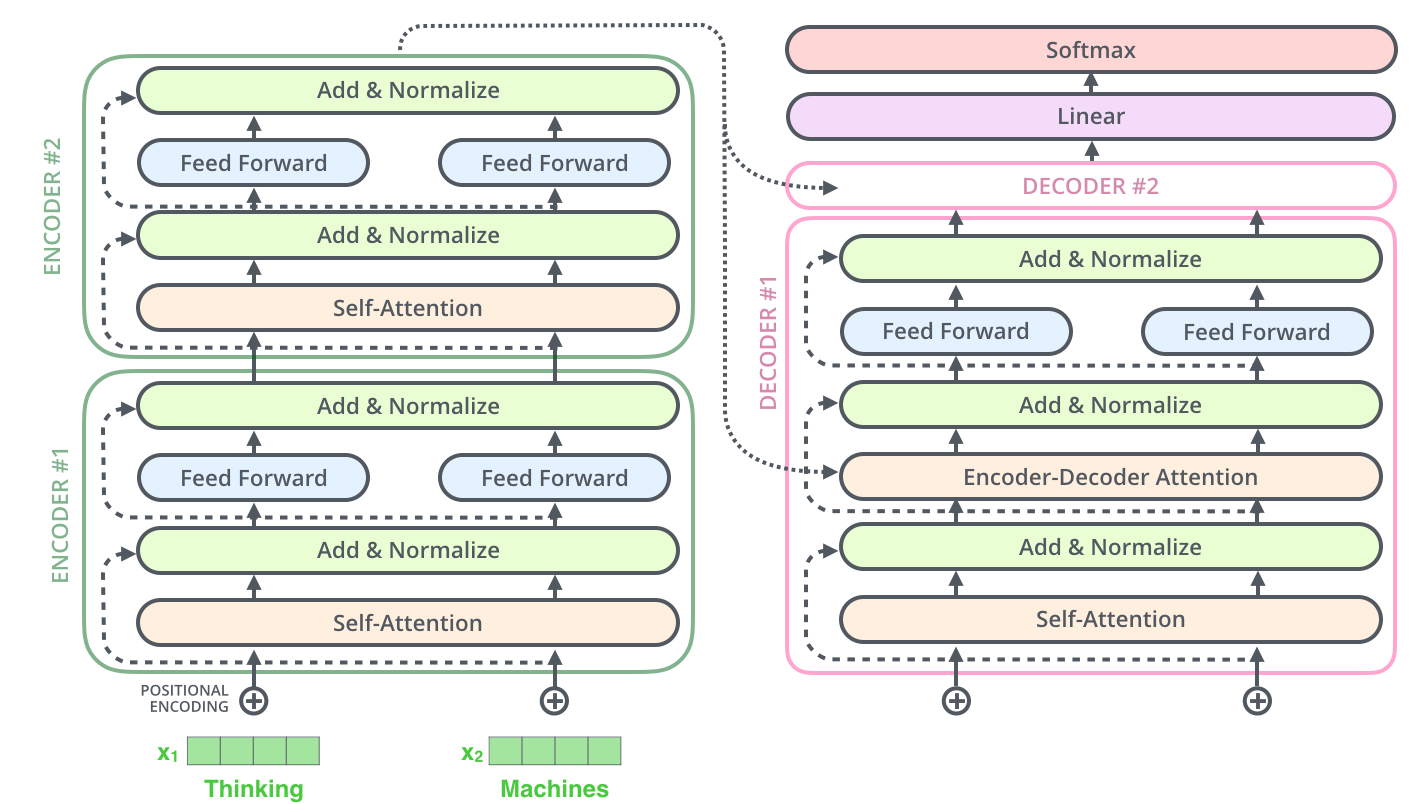
Transformer的Encoder其实有6层,Decoder也有6层,从Encoder的角度,每层encoder提取到的信息不一样,低层的Encoder是表层的词法信息,逐步向上进行抽象之后,在上层将表示抽象语义信息。Encoder部分还在最上层连了几条线到每个Decoder的部分,这是为了在Decoder中进行Attention操作,Decoder的网络中和Encoder也有信息传递和交互的。最后一个特点是Decoder和Encoder画的大小是一样的,因为它们层的维度大小是一样的。
多层的神经网络结构能够对句子层级化信息进行建模,如果我们更精细的去看每一层的结构,就会发现这样的情况:每个Encode分两个子网络部分,第一个是Self-Attention/multi-head attention,第二个部分是Feed Forward。
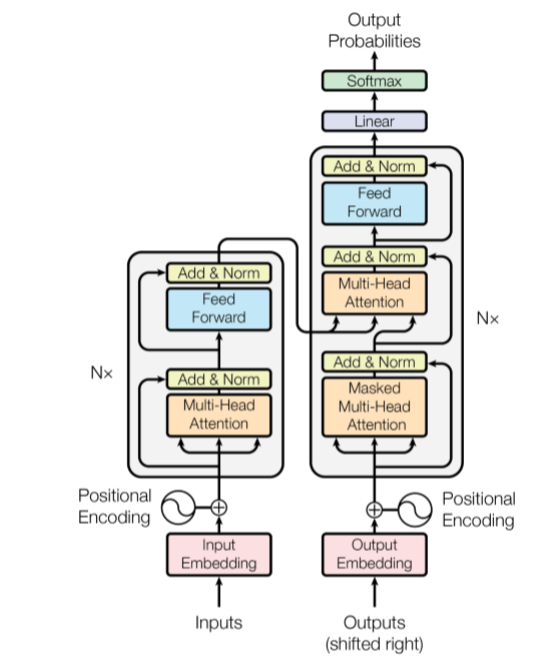
The Transformer-model architecture
3.1位置编码(positional encoding)
这样的模型并不能捕捉序列的顺序!换句话说,如果将K,V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。这就表明了,到目前为止,Attention模型顶多是一个非常精妙的“词袋模型”而已。
Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
在以往的Position Embedding中,基本都是根据任务训练出来的向量。而Google直接给出了一个构造Position Embedding的公式:
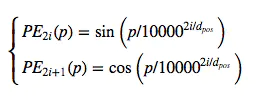
这里的意思是将id为p的位置映射为一个dpos维的位置向量,这个向量的第i个元素的数值就是PEi(p)。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有sin(α+β) = sinαcosβ+cosαsinβ 以及 cos(α+β)=cosαcosβ−sinαsinβ,这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
需要注意的一点,结合位置向量和词向量其实有好几个可选方案,可以把它们拼接起来作为一个新向量,也可以把位置向量定义为跟词向量一样大小,然后两者加起来。Google论文中用的都是后者。
3.2 Add&Norm(Residual connection和layer-normalization)
3.2.1 残差连接(Residual connection)
Residual connection是对于较为深层的神经网络有比较好的作用,比如网络层很深时,数值的传播随着weight不断的减弱,Residual connection是从输入的部分,就是图中虚线的部分,实际连到它输出层的部分,把输入的信息原封不动copy到输出的部分,减少信息的损失。
残差连接公式:y=f(x,w)+x
3.2.2 层归一化(layer-normalization)
layer-normalization这种归一化层是为了防止在某些层中由于某些位置过大或者过小导致数值过大或过小,对神经网络梯度回传时有训练的问题,保证训练的稳定性,这是神经网络设计比较常用的case。
基本在每个子网络后面都要加上layer-normalization、加上Residual connection,加上这两个部分能够使深层神经网络训练更加顺利。
3.3 位置前馈方向网络( position-wise feed forward)
Transformer中所有全连接网络都是一样的,由两个线性转换和中间一个RELU函数组成 。
虽然线性变换在不同位置上是相同的,但它们在层与层之间使用不同的参数。 另一种描述这种情况的方法是两个内核大小为1的卷积。
3.4 encoder-decoder attention
每层decoder都含有一个encoder-decoder attention层,就是平常使用的attention,这里接收从最后一层encoder的输出信息,用于计算attention。
3.5 Masked Multi-Head Attention
目标端的Attention注意力机制是一个masked注意力机制,为什么?比如在机器翻译当中,在源端能够看到所有的词,但如果你目标端生成翻译时是自左上右,生成翻译时能够看到前面已经生成词的信息,看不到后面层的,这是目标端Attention和源端Attention比较大的区别,所以在目标端所有的Attention都是加Masked的,这个Masked相当于把后面不该看到的信息屏蔽掉
总结
所谓的机器翻译模型就是分为将输入编码和输出解码,经过不同的层对信息进行编码/特征提取,比如第一层编码过后是词法信息,最后一层经过编码过后是语法信息,然后将语法信息输出译码器部分,进行相关的计算。译码部分也分为几层,对另一种语言的单词进行翻译、排列等,最终形成完整的句子。
每一层encoder都是由一个multi-head attention、add&norm层和一个position-wise feed forward构成,具体流程如下:
- 第一个encoder的输入:将底层的词的输入转化为embedding的输入,X1、X2,加上“Positional Encoding”的输入
- 在第一个Encoder当中,经过self-Attention层,直连的“Residual connection”和归一化层,得到的输出;将其输入到前馈神经网络中,前馈神经网络出来之后再经过直连层和归一化层,这样就完成了第一个Encoder部分,并作为第二个encoder输入
- 在第二个Encoder当中,它会把第二个Encoder的输出(以两层encoder为例,所以第二个Encoder就是最后Encoder)作为第一个Decoder的输入,也是依次进行上面的过程
- 最后就是通过一个liner层之后由softmax层转化概率进行最终的输出
最后
以上就是粗犷煎蛋最近收集整理的关于Transformer、多头注意力机制学习笔记:Attention is All You Need.文章目录一、注意力机制的原理二、多头注意力三、机器翻译(transformer)模型架构 总结的全部内容,更多相关Transformer、多头注意力机制学习笔记:Attention内容请搜索靠谱客的其他文章。








发表评论 取消回复