由于pytorch和tensorflow不支持int8 int16的gemm,因此只能测试fp32 fp16 bf16等精度的tflops,如果要测试int8 int16精度下的数值,需要编写cublas脚本,目前不会CUDA编程,可参考大佬的脚本:
cuBLAS矩阵乘法性能分析(附代码示例)_算法码上来的博客-CSDN博客
lightseq/gemm_test.cpp at master · bytedance/lightseq · GitHub
lightseq/tests/gemm_test at 430e4e4018a049186db02ddbf015cbce39c14679 · bytedance/lightseq · GitHub
这里我用torch测试了3090的fp32 fp16 bf16,先给出3090实测结果,mnk大小一样,这里用n表示了:
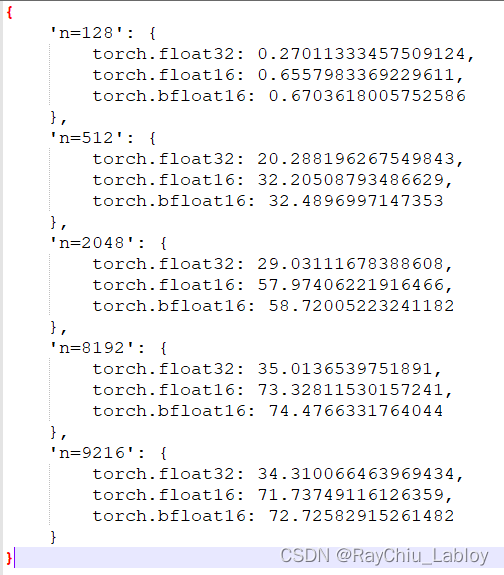
依赖torch的测试脚本(李沐沐神提供):
import torch
print('Pytorch versiont:', torch.__version__)
print('CUDA versiont:', torch.version.cuda)
print('GPUtt:',torch.cuda.get_device_name())
import inspect
from collections import defaultdict
import pandas as pd
from torch.utils import benchmark
pd.options.display.precision = 3
def var_dict(*args):
callers_local_vars = inspect.currentframe().f_back.f_locals.items()
return dict([(name, val) for name, val in callers_local_vars if val is arg][0]
for arg in args)
def walltime(stmt, arg_dict, duration=3):
return benchmark.Timer(stmt=stmt, globals=arg_dict).blocked_autorange(
min_run_time=duration).median
matmul_tflops = defaultdict(lambda: {})
for n in [128, 512, 2048, 8192, 9216]:
for dtype in (torch.float32, torch.float16, torch.bfloat16):
a = torch.randn(n, n, dtype=dtype).cuda()
b = torch.randn(n, n, dtype=dtype).cuda()
t = walltime('a @ b', var_dict(a, b))
matmul_tflops[f'n={n}'][dtype] = 2*n**3 / t / 1e12
del a, b
# pd.DataFrame(matmul_tflops)
print(matmul_tflops)最后
以上就是温柔草莓最近收集整理的关于矩阵乘测试显卡算力的全部内容,更多相关矩阵乘测试显卡算力内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复