在概率论和信息论中,两个随机变量的互信息(Mutual Information,简称MI)或转移信息(transinformation)是变量间相互依赖性的量度。不同于相关系数,互信息并不局限于实值随机变量,它更加一般且决定着联合分布
p
(
X
,
Y
)
p(X,Y)
p(X,Y)和分解的边缘分布的乘积
p
(
X
)
p
(
Y
)
p(X)p(Y)
p(X)p(Y)的相似程度。互信息(Mutual Information)是度量两个事件集合之间的相关性(mutual dependence)。互信息最常用的单位是bit。
1 互信息定义
1.1 原始定义
两个离散随机变量
X
X
X和
Y
Y
Y,其联合概率分布函数为
p
(
x
,
y
)
p(x, y)
p(x,y),而边缘概率分布函数分别为
p
(
x
)
p(x)
p(x)和
p
(
y
)
p(y)
p(y),其互信息可以定义为:
I
(
X
;
Y
)
=
∑
x
∈
X
∑
y
∈
Y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
p
(
x
)
p
(
y
)
(1)
I(X;Y)=sum_{xinmathcal{X}}^{}sum_{yinmathcal{Y}}^{}{p(x,y)log frac{p(x,y)}{p(x)p(y)}}tag{1}
I(X;Y)=x∈X∑y∈Y∑p(x,y)logp(x)p(y)p(x,y)(1)
在连续随机变量的情形下,
p
(
x
,
y
)
p(x,y)
p(x,y)是
X
X
X和
Y
Y
Y的联合概率密度函数,而
p
(
x
)
p(x)
p(x)和
p
(
y
)
p(y)
p(y)分别是
X
X
X和
Y
Y
Y的边缘概率密度函数,求和被替换成了二重积分:
I
(
X
;
Y
)
=
∫
X
∫
Y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
p
(
x
)
p
(
y
)
d
x
d
y
(2)
I(X;Y)=int_Xint_Y{p(x,y)log frac{p(x,y)}{p(x)p(y)}}dxdytag{2}
I(X;Y)=∫X∫Yp(x,y)logp(x)p(y)p(x,y)dxdy(2)
互信息量
I
(
x
i
;
y
j
)
I(x_i; y_j)
I(xi;yj)在联合概率空间
P
(
X
Y
)
P(XY)
P(XY)中的统计平均值。 平均互信息
I
(
X
;
Y
)
I(X; Y)
I(X;Y)克服了互信息量
I
(
x
i
;
y
j
)
I(x_i; y_j)
I(xi;yj)的随机性,成为一个确定的量。如果对数以 2 为基底,互信息的单位是bit。
直观上,互信息度量 X X X和 Y Y Y共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X X X和 Y Y Y相互独立,则知道 X X X不对 Y Y Y提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X X X是 Y Y Y的一个确定性函数,且 Y Y Y也是 X X X的一个确定性函数,那么传递的所有信息被 X X X和 Y Y Y共享:知道 X X X决定 Y Y Y的值,反之亦然。因此,在此情形下,互信息 Y Y Y(或 X X X)单独包含的不确定度相同,称作 Y Y Y(或 X X X)的熵。而且,这个互信息与 X X X的熵和 Y Y Y的熵相同。(这种情形的一个非常特殊的情况是当 X X X和 Y Y Y为相同随机变量时。)
互信息是
X
X
X和
Y
Y
Y联合分布相对于假定
X
X
X和
Y
Y
Y独立情况下的联合分布之间的内在依赖性。于是互信息以下面方式度量依赖性:
I
(
X
;
Y
)
=
0
I(X; Y) = 0
I(X;Y)=0,当且仅当
X
X
X和
Y
Y
Y为独立随机变量。从一个方向很容易看出:当
X
X
X和
Y
Y
Y独立时,
p
(
x
,
y
)
=
p
(
x
)
p
(
y
)
p(x, y) = p(x) p(y)
p(x,y)=p(x)p(y),因此:
l
o
g
p
(
x
,
y
)
p
(
x
)
p
(
y
)
=
l
o
g
1
=
0
(3)
logfrac{p(x, y)}{p(x)p(y)}=log1=0tag{3}
logp(x)p(y)p(x,y)=log1=0(3)
1.2 用熵表示互信息
熵的定义:熵是一个随机变量不确定性的度量,对于一个离散型随机变量
X
∼
p
(
x
)
Xsim p(x)
X∼p(x),其离散熵可以定义为:
H
(
X
)
=
−
∑
x
∈
χ
p
(
x
)
l
o
g
p
(
x
)
(4)
H(X)=-sum_{xinchi}^{}{p(x)}log p(x)tag{4}
H(X)=−x∈χ∑p(x)logp(x)(4)
其中: 花体
χ
chi
χ表示为包含所有小
x
x
x元素的集合,
l
o
g
log
log以2为底。
一个随机变量的熵越大,意味着不确定性越大,换言之,该随机变量包含的信息量越大。必然是事件是确定无疑的,并不含有不确定性,所以必然事件的熵应该是0,也就是说,必然事件不含有信息量。
接下来推导如何用熵表示互信息:
1. 离散型
I
(
X
;
Y
)
=
∑
x
∈
X
∑
y
∈
Y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
p
(
x
)
p
(
y
)
=
∑
x
∈
X
∑
y
∈
Y
p
(
x
,
y
)
l
o
g
p
(
y
)
p
(
x
∣
y
)
p
(
x
)
p
(
y
)
=
∑
x
∈
X
∑
y
∈
Y
p
(
x
,
y
)
l
o
g
p
(
x
∣
y
)
p
(
x
)
=
∑
x
∈
X
∑
y
∈
Y
p
(
x
,
y
)
l
o
g
p
(
x
∣
y
)
−
∑
x
∈
X
∑
y
∈
Y
p
(
x
,
y
)
l
o
g
p
(
x
)
=
−
∑
x
∈
X
p
(
x
)
l
o
g
p
(
x
)
−
[
−
∑
x
∈
X
∑
y
∈
Y
p
(
x
,
y
)
l
o
g
p
(
x
∣
y
)
]
=
H
(
X
)
−
H
(
X
∣
Y
)
(5)
begin{aligned}I(X;Y)&=sum_{xinmathcal{X}}^{}sum_{yinmathcal{Y}}^{}{p(x,y)log frac{p(x,y)}{p(x)p(y)}}=sum_{xinmathcal{X}}^{}sum_{yinmathcal{Y}}^{}{p(x,y)log frac{p(y)p(x|y)}{p(x)p(y)}}\&=sum_{xinmathcal{X}}^{}sum_{yinmathcal{Y}}^{}{p(x,y)log frac{p(x|y)}{p(x)}}=sum_{xinmathcal{X}}^{}sum_{yinmathcal{Y}}^{}{p(x,y)log p(x|y)}-sum_{xinmathcal{X}}^{}sum_{yinmathcal{Y}}^{}{p(x,y)log p(x)} \&=-sum_{xinmathcal{X}}^{}{p(x)log p(x)}-left[ -sum_{xinmathcal{X}}^{}sum_{yinmathcal{Y}}^{}{p(x,y)log p(x|y)} right]=H(X)-H(X|Y)end{aligned}tag{5}
I(X;Y)=x∈X∑y∈Y∑p(x,y)logp(x)p(y)p(x,y)=x∈X∑y∈Y∑p(x,y)logp(x)p(y)p(y)p(x∣y)=x∈X∑y∈Y∑p(x,y)logp(x)p(x∣y)=x∈X∑y∈Y∑p(x,y)logp(x∣y)−x∈X∑y∈Y∑p(x,y)logp(x)=−x∈X∑p(x)logp(x)−⎣
⎡−x∈X∑y∈Y∑p(x,y)logp(x∣y)⎦
⎤=H(X)−H(X∣Y)(5)
2. 连续型
I
(
X
;
Y
)
=
∫
X
∫
Y
P
(
X
,
Y
)
log
P
(
X
,
Y
)
P
(
X
)
P
(
Y
)
=
∫
X
∫
Y
P
(
X
,
Y
)
log
P
(
X
,
Y
)
P
(
X
)
−
∫
X
∫
Y
P
(
X
,
Y
)
log
P
(
Y
)
=
∫
X
∫
Y
P
(
X
)
P
(
Y
∣
X
)
log
P
(
Y
∣
X
)
−
∫
Y
log
P
(
Y
)
∫
X
P
(
X
,
Y
)
=
∫
X
P
(
X
)
∫
Y
P
(
Y
∣
X
)
log
P
(
Y
∣
X
)
−
∫
Y
log
P
(
Y
)
P
(
Y
)
=
−
∫
X
P
(
X
)
H
(
Y
∣
X
=
x
)
+
H
(
Y
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
(6)
begin{aligned} I(X;Y)&=int_X int_Y P(X,Y)logfrac{P(X,Y)}{P(X)P(Y)}\ &=int_X int_Y P(X,Y)logfrac{P(X,Y)}{P(X)}-int_X int_Y P(X,Y)log{P(Y)}\ &=int_X int_Y P(X)P(Y|X)log P(Y|X) -int_Y log{P(Y)}int_X P(X,Y)\ &=int_X P(X)int_Y P(Y|X)log P(Y|X)-int_Y log{P(Y)}P(Y)\ &=-int_X P(X)H(Y|X=x)+H(Y)\ &=H(Y)-H(Y|X)\ end{aligned}tag{6}
I(X;Y)=∫X∫YP(X,Y)logP(X)P(Y)P(X,Y)=∫X∫YP(X,Y)logP(X)P(X,Y)−∫X∫YP(X,Y)logP(Y)=∫X∫YP(X)P(Y∣X)logP(Y∣X)−∫YlogP(Y)∫XP(X,Y)=∫XP(X)∫YP(Y∣X)logP(Y∣X)−∫YlogP(Y)P(Y)=−∫XP(X)H(Y∣X=x)+H(Y)=H(Y)−H(Y∣X)(6)
经过推导后,我们可以直观地看到
H
(
X
)
H(X)
H(X)表示为原随机变量
X
X
X的信息量,
H
(
X
∣
Y
)
H(X|Y)
H(X∣Y)为知道事实
Y
Y
Y后
X
X
X的信息量,互信息
I
(
X
;
Y
)
I(X; Y)
I(X;Y)则表示为知道事实
Y
Y
Y后,原来信息量减少了多少。用Venn图表示:
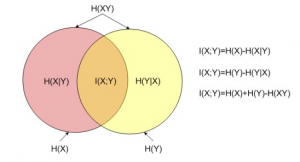
直观地说,如果把熵 H ( Y ) H(Y) H(Y)看作一个随机变量不确定度的量度,那么 H ( Y ∣ X ) H(Y|X) H(Y∣X)就是 X X X没有涉及到的 Y Y Y的部分的不确定度的量度。这就是“在 X X X已知之后 Y Y Y的剩余不确定度的量”,于是第一个等式的右边就可以读作“ Y Y Y的不确定度,减去在 X X X已知之后 Y Y Y的剩余不确定度的量”,此式等价于“移除知道 X X X后 Y Y Y的不确定度的量”。这证实了互信息的直观意义为知道其中一个变量提供的另一个的信息量(即不确定度的减少量)。
注意到离散情形 H ( X ∣ X ) = 0 H(X|X) = 0 H(X∣X)=0,于是 H ( X ) = I ( X ; X ) H(X) = I(X;X) H(X)=I(X;X)。因此 I ( X ; X ) ≥ I ( X ; Y ) I(X; X) geq I(X; Y) I(X;X)≥I(X;Y),我们可以制定”一个变量至少包含其他任何变量可以提供的与它有关的信息“的基本原理。
2 性质与应用
2.1 常用性质
1. 非负性
由图1可知:
H
(
X
)
≥
H
(
X
∣
Y
)
H(X)geq H(X|Y)
H(X)≥H(X∣Y),则
I
(
X
;
Y
)
≥
0
(7)
I(X; Y)geq0tag{7}
I(X;Y)≥0(7)
2. 对称性
I
(
X
;
Y
)
=
I
(
Y
;
X
)
(8)
I(X; Y) = I(Y; X)tag{8}
I(X;Y)=I(Y;X)(8)
3. 与条件熵和联合熵的关系
I
(
X
;
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
=
H
(
X
)
+
H
(
Y
)
−
H
(
X
,
Y
)
=
H
(
X
,
Y
)
−
H
(
X
∣
Y
)
−
H
(
Y
∣
X
)
(9)
begin{aligned} operatorname{I}(X;Y)& = H(X) - H(X|Y) \ &=H(Y) - H(Y|X) \ &= H(X) + H(Y) - H(X, Y) \ &= H(X, Y) - H(X|Y) - H(Y|X) end{aligned}tag{9}
I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)=H(X)+H(Y)−H(X,Y)=H(X,Y)−H(X∣Y)−H(Y∣X)(9)
4. 与K-L散度的关系
I
(
X
;
Y
)
=
∑
y
p
(
y
)
∑
x
p
(
x
∣
y
)
log
2
p
(
x
∣
y
)
p
(
x
)
=
∑
y
p
(
y
)
D
KL
(
p
(
x
∣
y
)
∥
p
(
x
)
)
=
E
Y
[
D
KL
(
p
(
x
∣
y
)
∥
p
(
x
)
)
]
.
(10)
begin{aligned} operatorname{I}(X;Y) &= sum_y p(y) sum_x p(x|y) log_2 frac{p(x|y)}{p(x)} \ &= sum_y p(y) ; D_text{KL}!left(p(x|y) parallel p(x)right) \ &= mathbb{E}_Yleft[D_text{KL}!left(p(x|y) parallel p(x)right)right]. end{aligned}tag{10}
I(X;Y)=y∑p(y)x∑p(x∣y)log2p(x)p(x∣y)=y∑p(y)DKL(p(x∣y)∥p(x))=EY[DKL(p(x∣y)∥p(x))].(10)
2.2 应用领域
- 通信中,信道容量是最大互信息
k-means,互信息被用作优化目标- 隐马尔可夫模型训练,可以采用最大互信息(MMI)标准。
RNA结构,可以从多序列比对预测RNA二级结构。- 互信息已被用作机器学习中的特征选择和特征变换的标准。它可用于表征变量的相关性和冗余性,例如最小冗余特征选择。
- 互信息用于确定数据集的两个不同聚类的相似性。
- 单词的互信息通常用作语料库语言学中搭配计算的重要函数。
- 医学成像中,互信息可以用于进行图像配准。
- 时间序列分析中,可以用于相位同步的检测。
- 互信息用于学习贝叶斯网络/动态贝叶斯网络的结构,这被认为可以解释随机变量之间的因果关系。
- 决策树学习中,是一种
loss function。
2.3 其他形式
1. 条件互信息
I
(
X
;
Y
∣
Z
)
=
E
Z
(
I
(
X
;
Y
)
∣
Z
)
=
∑
z
∈
Z
∑
y
∈
Y
∑
x
∈
X
p
Z
(
z
)
p
X
,
Y
∣
Z
(
x
,
y
∣
z
)
log
[
p
X
,
Y
∣
Z
(
x
,
y
∣
z
)
p
X
∣
Z
(
x
∣
z
)
p
Y
∣
Z
(
y
∣
z
)
]
,
(11)
begin{aligned} & {} operatorname{I}(X;Y|Z) = mathbb {E}_Z big(operatorname{I}(X;Y)|Zbig) = \ & {} sum_{zin Z} sum_{yin Y} sum_{xin X} {p_Z(z), p_{X,Y|Z}(x,y|z) logleft[frac{p_{X,Y|Z}(x,y|z)}{p_{X|Z},(x|z)p_{Y|Z}(y|z)}right]}, end{aligned}tag{11}
I(X;Y∣Z)=EZ(I(X;Y)∣Z)=z∈Z∑y∈Y∑x∈X∑pZ(z)pX,Y∣Z(x,y∣z)log[pX∣Z(x∣z)pY∣Z(y∣z)pX,Y∣Z(x,y∣z)],(11)
可以简写为:
I
(
X
;
Y
∣
Z
)
=
∑
z
∈
Z
∑
y
∈
Y
∑
x
∈
X
p
X
,
Y
,
Z
(
x
,
y
,
z
)
log
p
X
,
Y
,
Z
(
x
,
y
,
z
)
p
Z
(
z
)
p
X
,
Z
(
x
,
z
)
p
Y
,
Z
(
y
,
z
)
.
(12)
begin{aligned} & {} I(X;Y|Z) = \ & {} sum_{zin Z} sum_{yin Y} sum_{xin X} p_{X,Y,Z}(x,y,z) log frac{p_{X,Y,Z}(x,y,z)p_{Z}(z)}{p_{X,Z}(x,z)p_{Y,Z}(y,z)}. end{aligned}tag{12}
I(X;Y∣Z)=z∈Z∑y∈Y∑x∈X∑pX,Y,Z(x,y,z)logpX,Z(x,z)pY,Z(y,z)pX,Y,Z(x,y,z)pZ(z).(12)
2. 方向信息(Directed Information)
假设两个随机过程
X
n
,
Y
n
X^n,Y^n
Xn,Yn,方向互信息:
I
(
X
n
→
Y
n
)
=
∑
i
=
1
n
I
(
X
i
;
Y
i
∣
Y
i
−
1
)
(13)
operatorname{I}left(X^n to Y^nright) = sum_{i=1}^n operatorname{I}left(X^i; Y_i|Y^{i-1}right)tag{13}
I(Xn→Yn)=i=1∑nI(Xi;Yi∣Yi−1)(13)
3. 与相关系数的关系
互信息其中包含所有独立性(线性和非线性),不像correlation coefficients measures一样只包含线性。对于互信息与相关系数的关系,可以参考这篇博客:https://stats.stackexchange.com/questions/81659/mutual-information-versus-correlation
当随机变量
X
,
Y
X,Y
X,Y 的联合概率分布服从二元正态分布时,有以下性质:
ρ
rho
ρ是相关系数
I
=
−
1
2
log
(
1
−
ρ
2
)
(14)
operatorname{I} = -frac{1}{2} logleft(1 - rho^2right)tag{14}
I=−21log(1−ρ2)(14)
证明如下:
(
X
1
X
2
)
∼
N
(
(
μ
1
μ
2
)
,
Σ
)
,
Σ
=
(
σ
1
2
ρ
σ
1
σ
2
ρ
σ
1
σ
2
σ
2
2
)
H
(
X
i
)
=
1
2
log
(
2
π
e
σ
i
2
)
=
1
2
+
1
2
log
(
2
π
)
+
log
(
σ
i
)
,
i
∈
{
1
,
2
}
H
(
X
1
,
X
2
)
=
1
2
log
[
(
2
π
e
)
2
∣
Σ
∣
]
=
1
+
log
(
2
π
)
+
log
(
σ
1
σ
2
)
+
1
2
log
(
1
−
ρ
2
)
(15)
begin{aligned} begin{pmatrix} X_1 \ X_2 end{pmatrix} &sim mathcal{N} left( begin{pmatrix} mu_1 \ mu_2 end{pmatrix}, Sigma right),qquad Sigma = begin{pmatrix} sigma^2_1 & rhosigma_1sigma_2 \ rhosigma_1sigma_2 & sigma^2_2 end{pmatrix} \ H(X_i) &= frac{1}{2}logleft(2pi e sigma_i^2right) = frac{1}{2} + frac{1}{2}log(2pi) + logleft(sigma_iright), quad iin{1, 2} \ H(X_1, X_2) &= frac{1}{2}logleft[(2pi e)^2|Sigma|right] = 1 + log(2pi) + logleft(sigma_1 sigma_2right) + frac{1}{2}logleft(1 - rho^2right) \ end{aligned}tag{15}
(X1X2)H(Xi)H(X1,X2)∼N((μ1μ2),Σ),Σ=(σ12ρσ1σ2ρσ1σ2σ22)=21log(2πeσi2)=21+21log(2π)+log(σi),i∈{1,2}=21log[(2πe)2∣Σ∣]=1+log(2π)+log(σ1σ2)+21log(1−ρ2)(15)
所以,
I
(
X
1
;
X
2
)
=
H
(
X
1
)
+
H
(
X
2
)
−
H
(
X
1
,
X
2
)
=
−
1
2
log
(
1
−
ρ
2
)
(16)
operatorname{I}left(X_1; X_2right) = Hleft(X_1right) + Hleft(X_2right) - Hleft(X_1, X_2right) = -frac{1}{2}logleft(1 - rho^2right)tag{16}
I(X1;X2)=H(X1)+H(X2)−H(X1,X2)=−21log(1−ρ2)(16)
3 代码实现
实现一:基于直方图
% function: main.m
clc
u1 = rand(4,1);
u2 = [2;32;6666;5];
wind_size = size(u1,1);
mi = calmi(u1, u2, wind_size);
% function: calmi.m
% u1:输入计算的向量1
% u2:输入计算的向量2
% wind_size:向量的长度
function mi = calmi(u1, u2, wind_size)
x = [u1, u2];
n = wind_size;
[xrow, xcol] = size(x);
bin = zeros(xrow,xcol);
pmf = zeros(n, 2);
for i = 1:2
minx = min(x(:,i));
maxx = max(x(:,i));
binwidth = (maxx - minx) / n;
edges = minx + binwidth*(0:n);
histcEdges = [-Inf edges(2:end-1) Inf];
[occur,bin(:,i)] = histc(x(:,i),histcEdges,1); %通过直方图方式计算单个向量的直方图分布
pmf(:,i) = occur(1:n)./xrow;
end
%计算u1和u2的联合概率密度
jointOccur = accumarray(bin,1,[n,n]);
%(xi,yi)两个数据同时落入n*n等分方格中的数量即为联合概率密度
jointPmf = jointOccur./xrow;
Hx = -(pmf(:,1))'*log2(pmf(:,1)+eps);
Hy = -(pmf(:,2))'*log2(pmf(:,2)+eps);
Hxy = -(jointPmf(:))'*log2(jointPmf(:)+eps);
MI = Hx+Hy-Hxy;
mi = MI/sqrt(Hx*Hy); % 标准化互信息,两种形式 NMI=2*MI/(Hx+Hy) 和 NMI=MI/sqrt(Hx*Hy)
histc函数制定数值边界为分界条件
histc以 a=[1 2 3 4 5 6 7 8 9 0 ], edges=1:2:7 为例。
[n,bin]=histc(x,edges) 返回n=[2 2 2 1], bin=[ 1 1 2 2 3 3 4 0 0 0]。
edges=1:2:7即总共有三个数值分界,分别为1<=x<3, 3<=x<5, 5<=x<7,
n(1)=2表示a中落在第一个范围的数总共有两个,1和2;
n(2)=2表示a中落在第二个范围的数总共有两个,3和4;
n(3)=2表示a中落在第三个范围的数总共有两个,5和6;
n(4)=1表示a中的值等于edges最后一个值7的个数为1。
bin的值为a中的值分别在edges的哪个范围中(1就是在edges的第一个空中),若不在edges范围中,则返回0。
- 上述代码C++实现:标准化互信息NMI计算步骤和C++代码(Normalized Mutual Information)
- Python代码实现:NMI(标准化互信息) python实现
- stanford的讲解:https://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-clustering-1.html
- 互信息和标准化互信息:https://www.cnblogs.com/ziqiao/archive/2011/12/13/2286273.html
实现二:基于正态核的多变量核密度估计
原理介绍:请阅读:Estimation of mutual information using kernel density estimators和Jackknife approach to the estimation of mutual information
function [Ixy,lambda]=MutualInfo(X,Y)
%%
% Estimating Mutual Information with Moon et al. 1995
% between X and Y
% Input parameter
% X and Y : data column vectors (nL*1, nL is the record length)
%
% Output
% Ixy : Mutual Information
% lambda: scaled mutual information similar comparabble to cross-correlation coefficient
%
%
Programmed by
%
Taesam Lee, Ph.D., Research Associate
%
INRS-ETE, Quebecc
%
Hydrologist
%
Oct. 2010
%
%
X=X';
Y=Y';
d=2;
nx=length(X);
hx=(4/(d+2))^(1/(d+4))*nx^(-1/(d+4));
Xall=[X;Y];
sum1=0;
for is=1:nx
pxy=p_mkde([X(is),Y(is)]',Xall,hx);
px=p_mkde([X(is)],X,hx);
py=p_mkde([Y(is)],Y,hx);
sum1=sum1+log(pxy/(px*py));
end
Ixy=sum1/nx;
lambda=sqrt(1-exp(-2*Ixy));
%% Multivariate kernel density estimate using a normal kernel
% with the same h
% input data X : dim * number of records
%
x : the data point in order to estimate mkde (d*1) vector
%
h : smoothing parameter
function [pxy]=p_mkde(x,X,h);
s1=size(X);
d=s1(1);
N=s1(2);
Sxy=cov(X');
sum=0;
% p1=1/sqrt((2*pi)^d*det(Sxy))*1/(N*h^d);
% invS=inv(Sxy);
detS=det(Sxy);
for ix=1:N
p2=(x-X(:,ix))'*(Sxy^(-1))*(x-X(:,ix));
sum=sum+1/sqrt((2*pi)^d*detS)*exp(-p2/(2*h^2));
end
pxy=1/(N*h^d)*sum;
参考
- 互信息公式及概述:https://www.omegaxyz.com/2018/08/02/mi/
- 列向量互信息计算通用MATLAB代码:https://cloud.tencent.com/developer/article/1827416
- 计算两个向量的互信息(Mutual Information) matlab程序:https://blog.csdn.net/asfdsdg/article/details/104977788
- 互信息的介绍:https://www.zhihu.com/question/304499706/answer/544609335
- 信息论(1)——熵、互信息、相对熵:https://zhuanlan.zhihu.com/p/36192699
- 基于互信息的特征选择算法MATLAB实现:https://www.omegaxyz.com/2018/08/03/mifs/
最后
以上就是单纯果汁最近收集整理的关于高数篇(四)-- 互信息概述与matlab实现的全部内容,更多相关高数篇(四)--内容请搜索靠谱客的其他文章。






![[通信技术]Iub接口协议——专用传输信道(DCH)的用户平面协议](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)

发表评论 取消回复