verilog写积分
- 0.总体代码
- 1. 原理
- 1.如何进行量化,达到精度。
- 2.如何尽可能的提高吞吐量,尽可能做到完全流水线化。
- 仿真结果;
最近听别人说了道题,打算做一下
目标:x=1,x=2, y=0,f(x)=4x 3+2x+3围成图形的面积,要求精度小于0.0005;
原理:积分原理;
0.总体代码
module func_x#(
parameter DATA_WITEH = 10, //数据量化位宽
parameter ACCUTE_WITHE = 8, //量化小数点位宽
parameter RESULT_WITHE = 32 //结果数据位宽
)(
/*
模块功能:函数;f(x)=4x^3+2x+3
流水线话:3拍
*/
input clk,
input rst_n,
input s_din_tvalid,
input [DATA_WITEH-1:0] x,
output s_dout_tvalid,
output [RESULT_WITHE-1:0] result
);
// 打拍
reg s_dout_tvalid_r [2:0];
integer i;
always @ (posedge clk)
begin
for (i=0;i<2;i=i+1)
begin
s_dout_tvalid_r[i+1] <= s_dout_tvalid_r[i];
s_dout_tvalid_r [0] <= s_din_tvalid;
end
end
reg [RESULT_WITHE-1:0] dout_r0_xx; //ufix32_16
reg [RESULT_WITHE-1:0] dout_r0_4x; //ufix32_8
reg [RESULT_WITHE-1:0] dout_r0_2x3; //ufix32_8
reg [RESULT_WITHE-1:0] dout_r1_2x3; //ufix32_8
reg [RESULT_WITHE-1:0] dout_r1_4xxx; //ufix32_24
reg [RESULT_WITHE-1:0] result_r;
always @ (posedge clk)
begin
dout_r0_xx <= (x*x); //第一拍
dout_r0_4x <= (x<<2);
dout_r0_2x3 <= (x<<1) + (3<<ACCUTE_WITHE);
dout_r1_4xxx <= (dout_r0_4x*dout_r0_xx); //第二拍
dout_r1_2x3 <=dout_r0_2x3 ;
result_r <= dout_r1_4xxx + (dout_r1_2x3<<(ACCUTE_WITHE*2)); // 第三拍
end
assign s_dout_tvalid = s_dout_tvalid_r[2];
assign result = result_r;
endmodule
module polynomial#(
parameter DATA_WITEH = 10, //数据量化位宽
parameter POINT_WITHE = 8, //小数点位数
parameter RESULT_WITHE = 32 //结果位宽
)
(
/*
模块功能:x=1,x=2, y=0,f(x)=4x^3+2x+3围成图形的面积,要求精度小于0.0005;
原理:积分原理;
备注条件:
1.右端点到0 为量化总长度, 左端点以此为尺度进行量化
2.POINT_WITHE 输入数据量化后的小数点位数,计算步进的长度为 1/POINT_WITHE
3.din_en,X0,X1,在一个周期同时输入,dout_en,result同时输出
4.idle为空状态,本例中没有写,如果你需要的话,自己添加状态机处控制,需要简单修改下。
5.工作在非流水线,计算时间周期为 (X1-X0) + 4 个周期
6. 1 = 10'd256 ; 2=10'd512;
7.只能用于左右端点都是整数的情况,且计算过程数值均为正的情况下,充分条件为:函数单调增,F(0)>=0;
使用流程;
1.确定精度,即POINT_WITHE的宽度
2.确定报右端点在量化后再数据位宽的允许范围内,进而选择DATA_WITEH
3.根据具体公式推算结果数据范围,确定RESULT_WITHE
*/
input clk, //system_clk
input rst_n, //system_rst_n 已经经过同步化
input din_en, //数据使能
input [DATA_WITEH-1:0] X0, //左端点 unfixDATA_WITEH_POINT_WITHE
input [DATA_WITEH-1:0] X1, //右端点 unfixDATA_WITEH_POINT_WITHE
output dout_en,
output [POINT_WITHE+RESULT_WITHE-1:0] result, //本列中ufixRESULT_WITHE_POINT_WITHE*.
output idle
);
//数据分块,单位宽度 8'd1,送入功能函数
reg [DATA_WITEH-1:0] x_r;
reg [DATA_WITEH-1:0] X1_r;
reg s_din_tvalid_r;
always @ (posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
x_r <= 0;
X1_r <= 0;
s_din_tvalid_r <= 0;
end
else
begin
if(din_en)
begin
x_r <= X0;
s_din_tvalid_r <= 1'b1;
X1_r <= X1;
end
else
begin
if(x_r < X1_r - 1)
begin
x_r <= x_r + 1'b1;
end
else
begin
x_r <= 0;
s_din_tvalid_r <= 1'b0;
end
end
end
end
wire s_dout_tvalid;
reg s_dout_tvalid_r;
always @ (posedge clk)
begin
s_dout_tvalid_r <= s_dout_tvalid;
end
wire [RESULT_WITHE-1:0] result_r;
func_x #(
.DATA_WITEH(DATA_WITEH), //数据量化位宽
.ACCUTE_WITHE(POINT_WITHE), //精度位宽 ,步进为1
.RESULT_WITHE(RESULT_WITHE)
)
f1 (
.clk(clk),
.rst_n(rst_n),
.s_din_tvalid(s_din_tvalid_r),
.x(x_r),
.s_dout_tvalid(s_dout_tvalid),
.result(result_r) //ufix32_24
);
//累加
reg [POINT_WITHE+RESULT_WITHE-1:0] sum_r,sum; //ufixRESULT_WITHE_24
reg dout_en_r;
always @ (posedge clk or negedge rst_n)
begin
if(~rst_n)
begin
sum <= 0;
sum_r <= 0;
s_dout_tvalid_r <= 0;
dout_en_r <= 0;
end
else
begin
if(s_dout_tvalid)
begin
sum_r <= sum_r + result_r;
end
else
begin
sum_r <= 0;
end
if(s_dout_tvalid_r && ~s_dout_tvalid)
begin
sum <= sum_r;
dout_en_r <= 1'b1;
end
else
begin
sum <= 0;
dout_en_r <= 1'b0;
end
end
end
assign dout_en = dout_en_r;
assign result = sum>>POINT_WITHE;
endmodule
1. 原理
原理就是通过积分计算,通区间等分,近似一个一个小矩形然后相加。
公式:
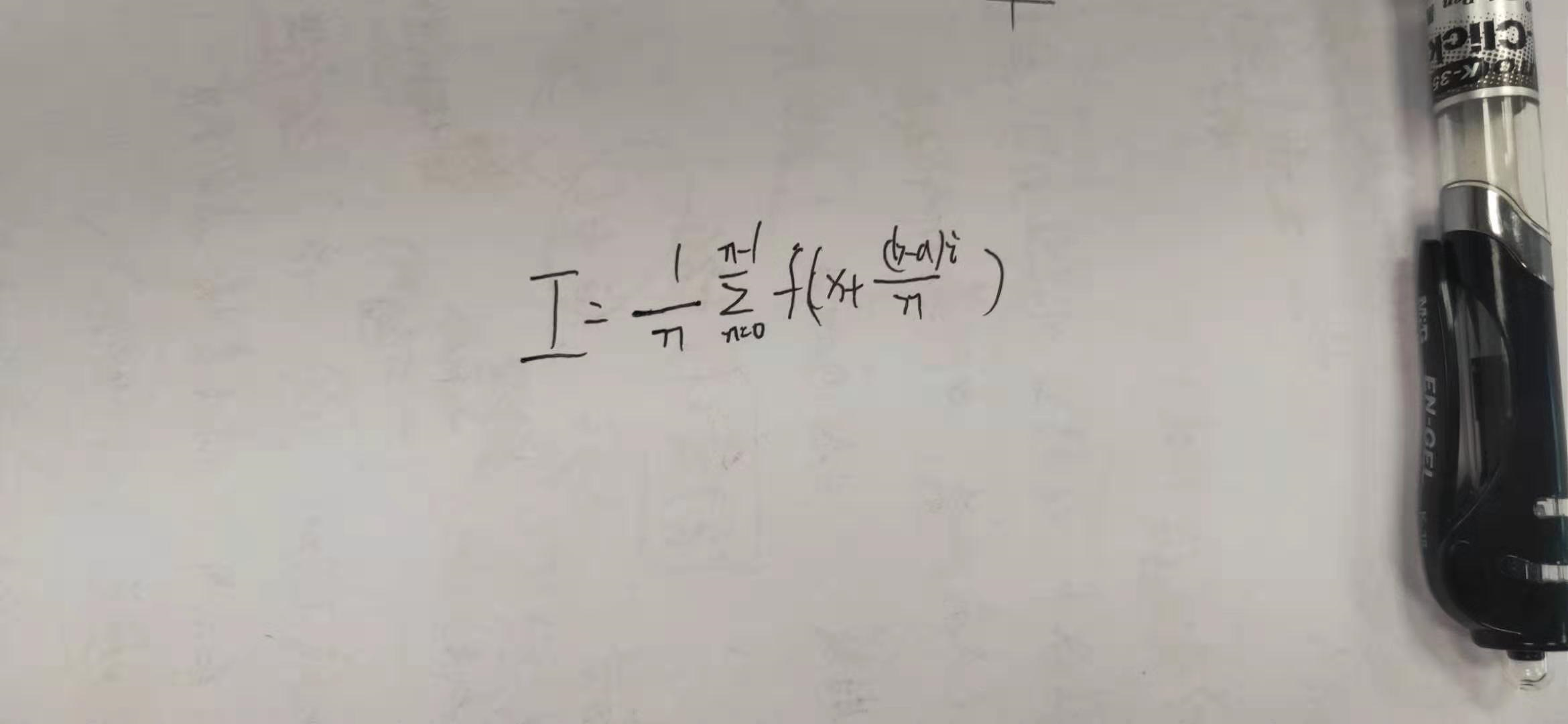
这道题的思路简单,但有两个难点
1.如何进行量化,达到精度。
我已经在代码中备注了,去进行量化,他的数据量化与输入的右端点的值有关,也与最后的计算精度有关,这个需要综合区考虑。简单来说,就是小数点的位数越多,精度越久越高
还要注意通用性,定点数计算比浮点计算差的就是在这里,具体问题具体分析,尽量做到参数传递绝对的通用,给出的代码的要求就是只能用于左右端点都是整数的情况,且计算过程数值均为正的情况下,充分条件为:函数单调增,F(0)>=0;如果还需要更通用的可能不太容易了。
2.如何尽可能的提高吞吐量,尽可能做到完全流水线化。
代码中的函数模块,做到流水线并进行了优化逻辑结构的优化,延迟为三个周期
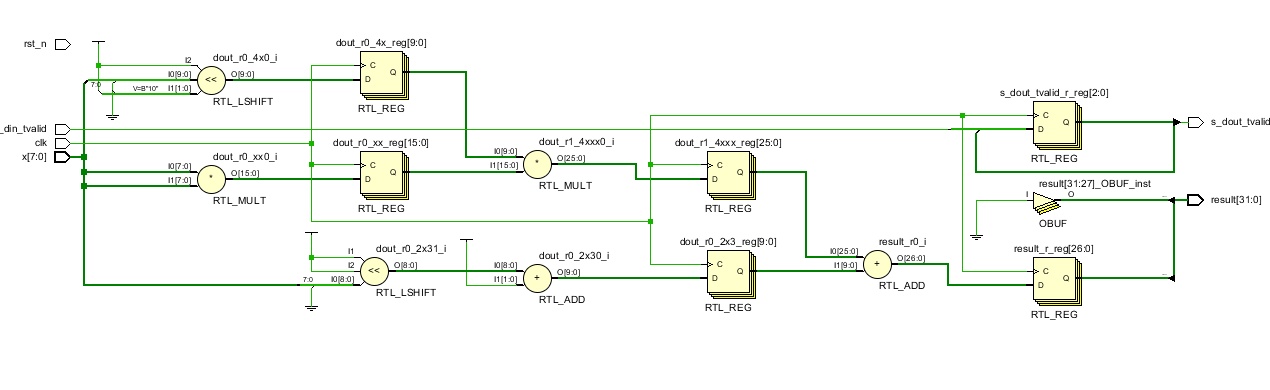
1.在设计过程中尽可能有使用括号的习惯,和结构优化的习惯,减少逻辑路径长度电路运行速度,做到流水线话。
2.注意每一拍中数据定义的变化,定点计算中必须时刻记住:
- 乘法:结果小数点为乘数被乘数小数位数之和,不需要考虑乘数与被乘数的小数点位置。
- 加法: 加数与被加数必须第一的小数点宽度相同,结果位置不变。
而顶层模块无法做到流水线化,这是因为需要步进无法完成,如果需要只能通过设计软件尝试流水线化。所以只能做半流水半穿行。计算时间为(X1-X0) + 4 个周期,这个时间是固定的不会变化。
仿真结果;
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2019/10/18 14:28:31
// Design Name:
// Module Name: poly
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module poly(
);
reg clk;
reg rst_n;
parameter clk_period=100;
parameter clk_half_period=clk_period/2;
reg din_en;
reg [9:0] X0,X1;
initial
begin
clk = 0;
rst_n = 0;
din_en =0;
X0 = 0;
X1 = 0;
#1000 rst_n = 1;
#1150
din_en = 1;
X0 = 10'd256;
X1 = 10'd512;
@(negedge clk)
din_en = 0;
X0 = 10'd0;
X1 = 10'd0;
end
always
#clk_half_period clk = ~clk;
polynomial #(
.DATA_WITEH (10), //数据量化位宽
.POINT_WITHE(8) , //分割数据位宽
.RESULT_WITHE(32)
)
p1(
.clk(clk), //system_clk
.rst_n(rst_n), //system_rst_n 已经经过同步化
.din_en(din_en), //数据使能
.X0(X0), //左端点
.X1(X1), //右端点
.dout_en(),
.result()
);
endmodule
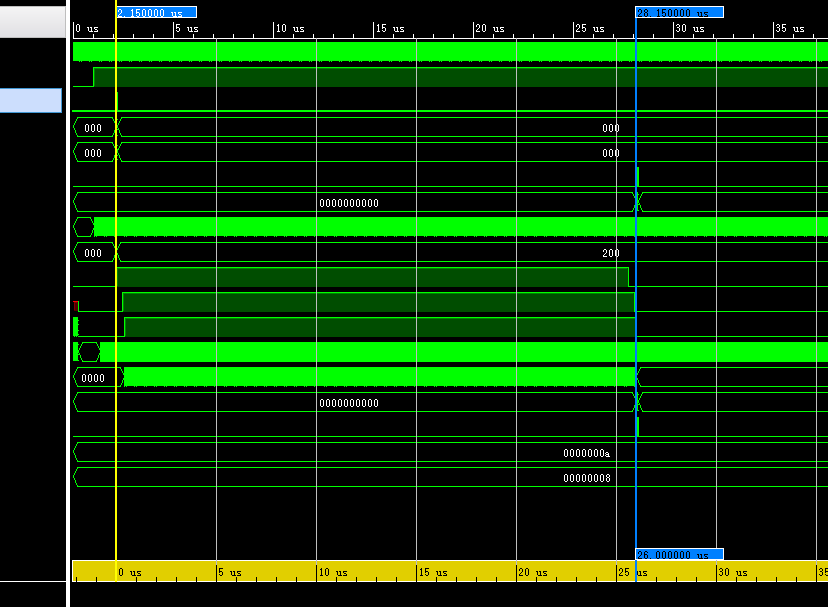

正确结果为21 ,误差为0.5,精度通过调整位宽是是可以控制的,
修改仿真文件
#1150
din_en = 1;
X0 = 11'd512;
X1 = 12'd1024;
polynomial #(
.DATA_WITEH (11), //数据量化位宽
.POINT_WITHE(9), //分割数据位宽
.RESULT_WITHE(40)
)
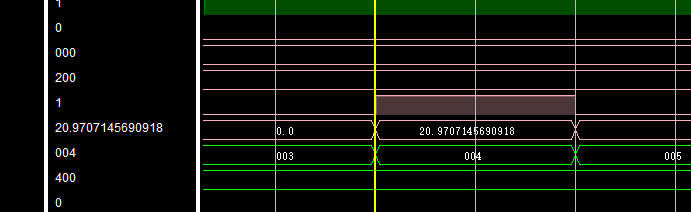
精度在提高点,达标了
#1150
din_en = 1;
X0 = {2'b01,18'd0};
X1 = {2'b10,18'd0};
polynomial #(
.DATA_WITEH (20), //数据量化位宽
.POINT_WITHE(18), //分割数据位宽
.RESULT_WITHE(60)
)
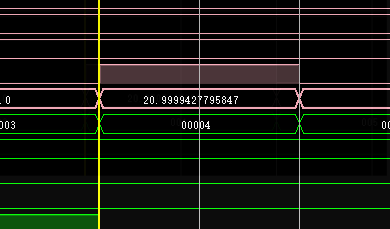
最后
以上就是粗犷镜子最近收集整理的关于(fpga)用verilog写积分函数的全部内容,更多相关(fpga)用verilog写积分函数内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复