文章目录
- 一、YOLOv5简介
- 二、网络结构
- 1、Input
- 2、Backbone
- 3、Neck
- 4、Head
- 三、改进方法
- 1、自适应锚框计算
- 2、自适应灰度填充
- 四、性能表现
- 五、YOLOv5入门实战
一、YOLOv5简介
YOLOv5是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
YOLOv5是YOLO系列的一个延申,您也可以看作是基于YOLOv3、YOLOv4的改进作品。YOLOv5没有相应的论文说明,但是作者在Github上积极地开放源代码,通过对源码分析,我们也能很快地了解YOLOv5的网络架构和工作原理。
Github源码地址:https://github.com/ultralytics/yolov5
二、网络结构
YOLOv5官方代码中,一共给出了5个版本,分别是 YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLO5x 五个模型。这些不同的变体使得YOLOv5能很好的在精度和速度中权衡,方便用户选择。
本文中,我们以较为常用的YOLOv5s进行介绍,下面是YOLOv5s的整体网络结构示意图: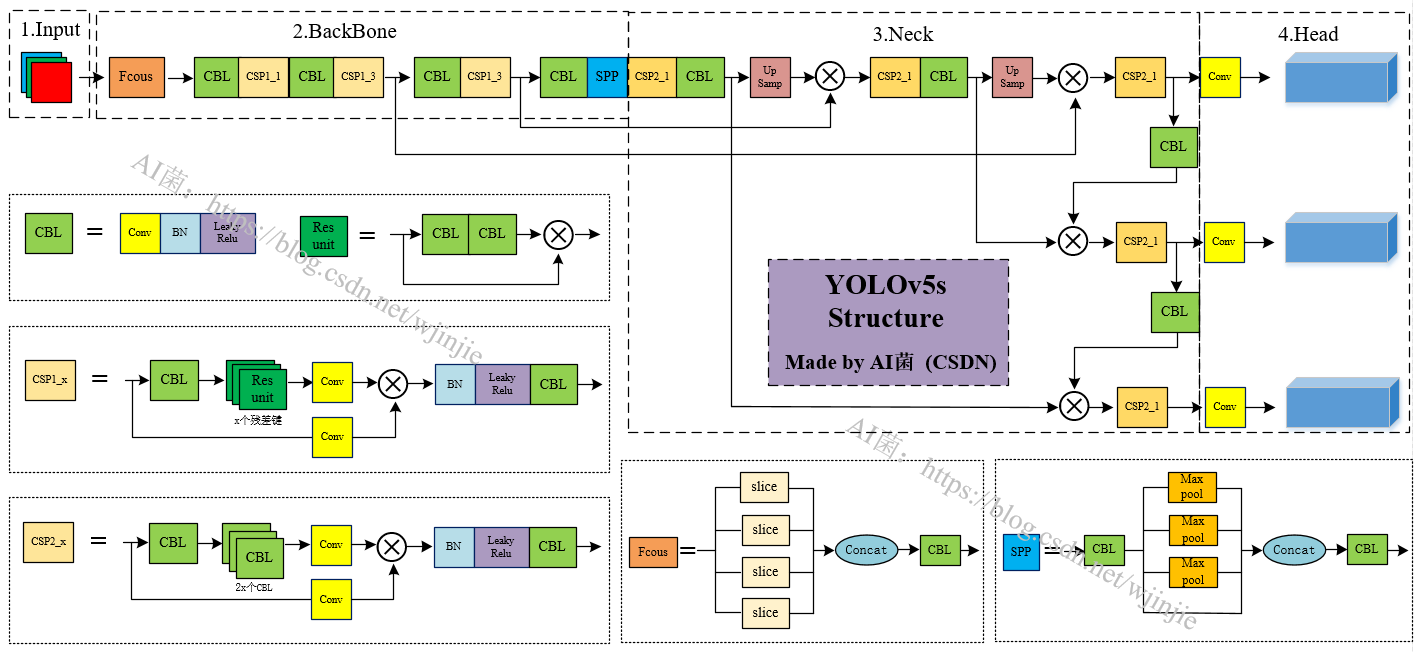
注:无水印原图,上我公众号【AI 修炼之路】,回复【YOLOv5】获取!
1、Input
和YOLOv4一样,对输入的图像进行Mosaic数据增强。Mosaic数据增强的作者也是来自Yolov5团队的成员,通过随机缩放、随机裁剪、随机排布的方式对不同图像进行拼接,如下如所示:
采用Mosaic数据增强方法,不仅使图片能丰富检测目标的背景,而且能够提高小目标的检测效果。并且在BN计算的时候一次性会处理四张图片!
2、Backbone
骨干网路部分主要采用的是:Focus结构、CSP结构。其中 Focus 结构在YOLOv1-YOLOv4中没有引入,作者将 Focus 结构引入了YOLOv5,用于直接处理输入的图片。Focus重要的是切片操作,如下图所示,4x4x3的图像切片后变成2x2x12的特征图。
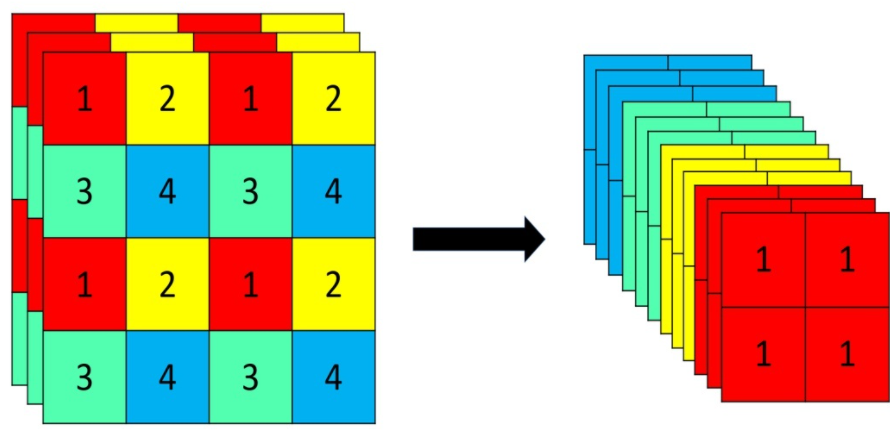
以YOLOv5s的结构为例,原始608x608x3的图像输入Focus结构,采用切片操作,先变成304x304x12的特征图,再经过一次32个卷积核的卷积操作,最终变成304x304x32的特征图。
3、Neck
在网络的颈部,采用的是:FPN+PAN结构,进行丰富的特征融合,这一部分和YOLOv4的结构相同。详细内容可参考:
- 目标检测算法 YOLOv4 解析
- YOLO系列算法精讲:从yolov1至yolov4的进阶之路
4、Head
对于网络的输出,遵循YOLO系列的一贯做法,采用的是耦合的Head。并且和YOLOv3、YOLOv4类似,采用了三个不同的输出Head,进行多尺度预测。详细内容可参考:
- 目标检测算法 YOLOv4 解析
- YOLO系列算法精讲:从yolov1至yolov4的进阶之路
三、改进方法
1、自适应锚框计算
在YOLOv3、YOLOv4中,是通过K-Means方法来获取数据集的最佳anchors,这部分操作需要在网络训练之前单独进行。为了省去这部分"额外"的操作,Yolov5的作者将此功能嵌入到整体代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
2、自适应灰度填充
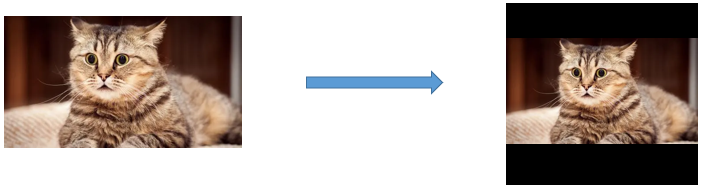
为了应对输入图片尺寸 不一的问题,通常做法是将原图直接resize成统一大小,但是这样会造成目标变形,如下图所示:

为了避免这种情况的发生,YOLOv5采用了灰度填充的方式统一输入尺寸,避免了目标变形的问题。灰度填充的核心思想就是将原图的长宽等比缩放对应统一尺寸,然后对于空白部分用灰色填充。如下图所示:
四、性能表现
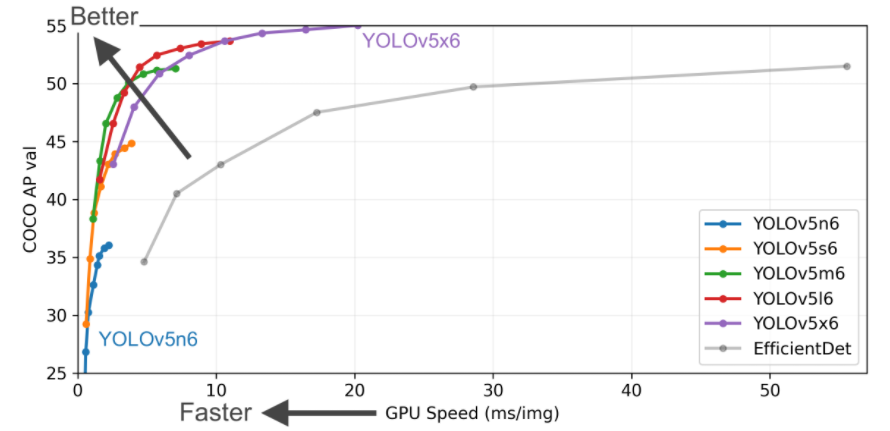
在COCO数据集上,当输入原图的尺寸是:640x640时,YOLOv5的5个不同版本的模型的检测数据如下:
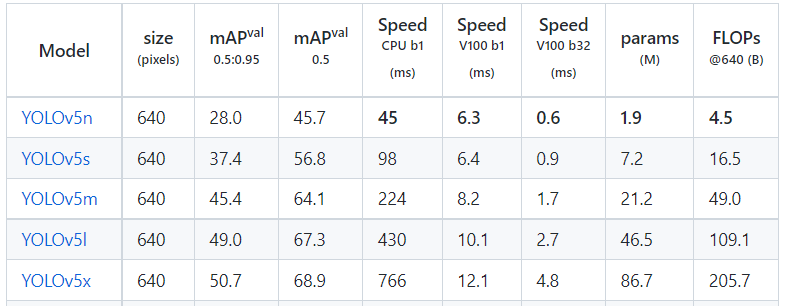
在COCO数据集上,当输入原图的尺寸是:640x640时,YOLOv5的5个不同版本的模型的检测数据如下:
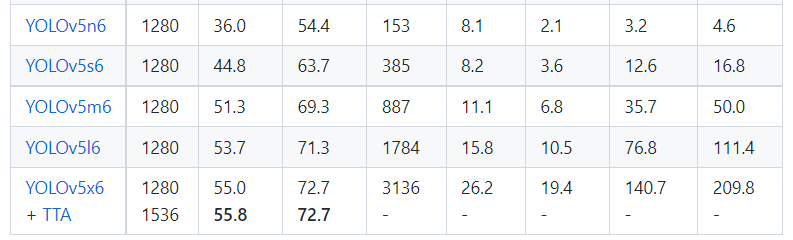
从上表可得知,从YOLOv5n到YOLOv5x,这五个YOLOv5模型的检测精度逐渐上升,检测速度逐渐下降。根据项目要求,用户可以选择合适的模型,来实现精度与速度的最佳权衡!
五、YOLOv5入门实战
1、下载YOLOv5,并安装相关依赖库。
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
2、检测。此过程会自动下载权重到root/runs/detect目录下,如果下载失败,可自行下载。
python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
3、训练。
python train.py --data coco.yaml --cfg yolov5n.yaml --weights '' --batch-size 128
yolov5s 64
yolov5m 40
yolov5l 24
yolov5x 16
参考文献:
- https://github.com/ultralytics/yolov5
- https://www.zhihu.com/search?q=YOLOv5&utm_content=search_history&type=content
最后
以上就是俊秀灯泡最近收集整理的关于【快速入门】YOLOv5目标检测算法的全部内容,更多相关【快速入门】YOLOv5目标检测算法内容请搜索靠谱客的其他文章。








发表评论 取消回复