迭代器
- 前言
- 一、可迭代对象(Iterable)
- (一)遍历对比
- (二)可迭代对象(Iterable)
- 1.确定可迭代对象
- 2.确定共同属性
- 3.错误
- 二、迭代器(Iterator)
- (一)调用 iter() 函数
- (二)迭代器的共同属性
- (三)抛出异常
- (四)构建迭代器
- 三、意义与实例
- (一)意义
- 1.浅层的意义
- 2.深层的意义
- (二)实例
- 实例1
- 实例2
- 结语
前言
笔者其实一开始并不想知道这么多关于迭代器和生成器的知识,只是想知道怎么使用这两个工具而已。但是,笔者越是抱着这样的想法去学习,越不能理解所写的代码,这让笔者感到非常的痛苦,而且笔者也发现这两件事情并不简单。
在真正了解了相关知识之后,笔者才知道:迭代器和生成器并不是并列的关系,应该是递进的关系,我们可以通过迭代器推出生成器,再从生成器推到协程(多线程知识的一部分)的相关知识。
一、可迭代对象(Iterable)
(一)遍历对比
笔者虽然是冲着迭代器去的,但最开始接触到的其实是遍历,请读者自行阅读下方的两段代码。
// C语言--数组
for (int i = 0; i < sizeof(arrTest)/sizeof(int); i++)
{
printf("%dn",arrTest[i]);
}
// C语言--链表 (笔者自己还没学过数据结构,这一段是搬运过来的)
PNODE p = pHead -> pNext;
while(p)
{
printf("%d ",p -> data);
p = p -> pNext;
}
# Python--列表
# 初始代码(下方还要提及)
object_1 = [1,2,3,4,5,6]
for a in object_1:
print(a)
# Python--字典
object_2 = {1:'a' ,2:'b'}
for b in object_2:
print(b)
相信大家在看完上面两段代码之后,都明显能感受到:关于遍历Python比C语言用起来舒服得多。这主要体现在以下两个方面:
(1)代码简短易读
(2)书写格式统一
然而,关于Python的遍历,我们其实已经用到了可迭代对象的知识了。这两个可迭代对象就是object_1 object_2。
(二)可迭代对象(Iterable)
1.确定可迭代对象
在介绍何为 可迭代对象 之前,各位读者必定有一个疑惑——笔者是怎么知道object_1 object_2就是可迭代对象的呢?其实笔者是利用 isinstance()函数来进行验证的,所以以下插入该函数的相关介绍。
isinstance() 函数
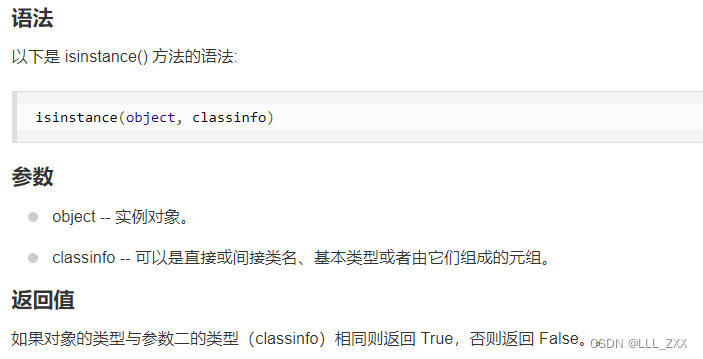
这里我们需要注意,在利用 isinstance()函数之前,我们需要用from...import...引入一个包。之后,我们才能通过 isinstance()函数确认数据是否是 可迭代对象。
笔者已在交互界面验证过上方的两个数据,结果如下图所示。
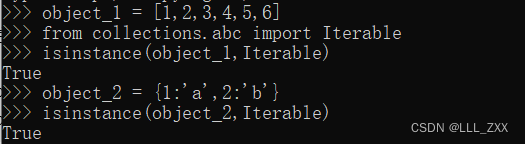
利用上面的方法,我们除了知道列表、字典是可迭代对象之外,还知道了字符串、元组、集合也是可迭代对象。
2.确定共同属性
至此,我们已经检验过部分数据,确认它们是可迭代对象。但是,我们的目的还没达成,我们仍然不知道何为可迭代对象。接下来笔者倒推,看看以上可迭代对象有什么共同属性,通过确定对象的共同属性,来给出对象下定义。接下来,笔者再介绍一个Python的内置函数 dir() 函数,其作用是:确定数据的属性。
dir() 函数
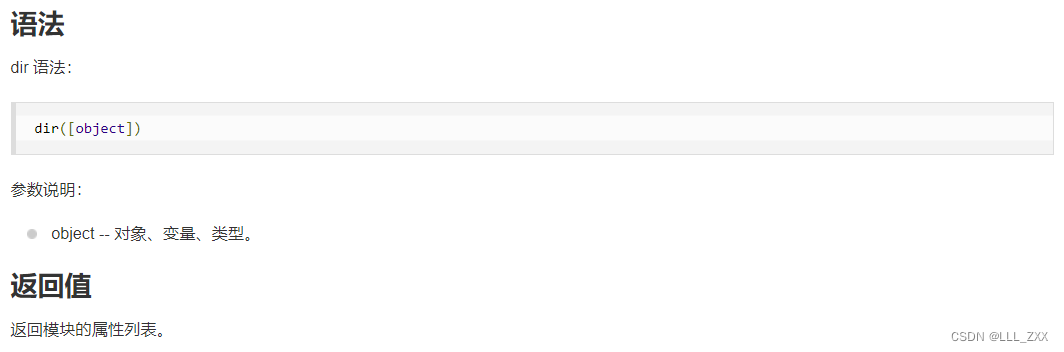
借用 dir() 函数,我们可以设计出下面这段代码(不是笔者写的)。
# 片段1
def common_attrs(*objs):
assert len(objs) > 0 # 设置断言,预警报错
attrs = set(dir(objs[0]))
for obj in objs[1:]:
attrs &= set(dir(obj)) # 取交集
attrs -= set(dir(object)) # 剔除基础对象的属性
return attrs
iterables = [
"123" , # 字符串
[1,2,3], # 列表
(1,2,3), # 元组
{1:'a',2:'b'}, # 字典
{1,2,3} # 集合
]
# 计算可迭代对象的共同属性
iterable_common_attrs = common_attrs(*iterables)
print(iterable_common_attrs)
#-------------------------------------------------------
# 结果为 {'__iter__', '__len__', '__contains__'}
这段代码的设计思路非常清晰,整体意思理解起不是很困难。但是关于 为什么要在def 函数处设计一个指针 笔者自己并不理解,这里希望有大神可以在评论区指点。
这段代码给出的结果其实并不是 可迭代对象 真正的共同属性。比较引起笔者注意的是后面的两个方法 '__len__', '__contains__' ,这两个方法会出现,可能意味着我们所选用的可迭代对象属于某一种特定类型,笔者称之为:容器类型。事实是:除了以上的类型,我们其实还有迭代器类型的数据,比如:文件、StringIO。
为了将迭代器类型的数据添加上去,我们会用到open()函数,下面是关于open()函数的相关知识。
open() 函数
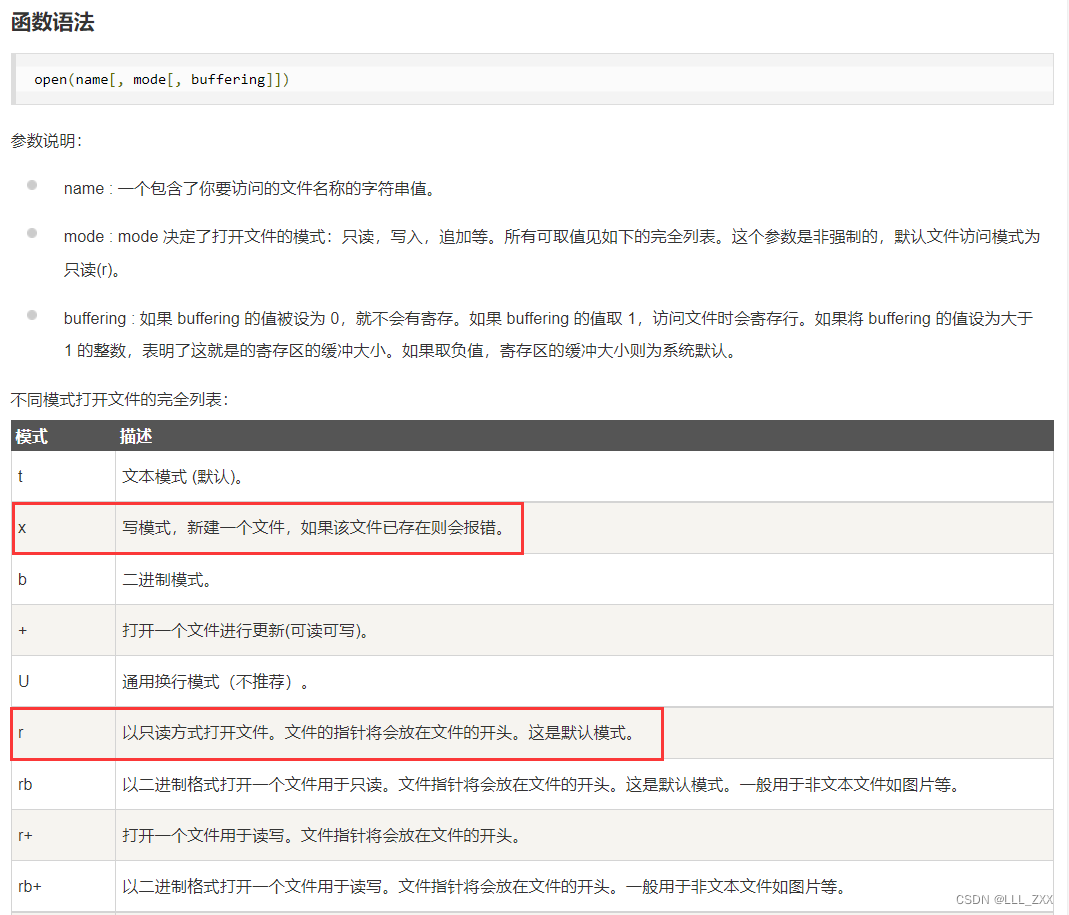
模式那里其实还有很多,想要继续了解的读者可以点击结语的第二个链接。这里要关注的就是红色框中的两种模式。
借用 open() 函数,我们可以接着 片段1 增添下面这段代码(不是笔者写的)。
# 片段2
# 文件对象也是可迭代对象
f = open('001 迭代器.ipynb','x')
iterables.append(f)
# 继续求一次交集
iterable_common_attrs &= set(dir(f))
print(iterable_common_attrs)
#-------------------------------------------------------
# 结果为 {'__iter__'}
读者在敲上面这段代码的时候,应该没有创建过跟笔者一模一样的文件名,所以第一次创建的时候,应该选 x 模式,在运行一次之后,将之改成 r 模式。
现在,我们终于知道可迭代对象的共同属性是__iter__了,其对应的调用方法就是 内置函数 iter() 。由此,我们定义 可迭代对象就是:有__iter__方法的对象。
3.错误
看到此处,部分读者心中可能就会有这样一个想法:在object_1 object_2的位置,我偏偏不放可迭代对象,这时候会怎么样呢?那么读者可以尝试下面这段代码。
a = 1234
for i in a:
print(i)
 我们可以看到运行之后的结果,编译器报错说:'Int’类型数据不是可迭代对象。
我们可以看到运行之后的结果,编译器报错说:'Int’类型数据不是可迭代对象。

因为,数字a 无法调用 iter() 函数,不符合我们上面得到的结论,不符合可迭代对象的定义。
二、迭代器(Iterator)
让我们回到最开始的那段初始代码。
# 初始代码
object_1 = [1,2,3,4,5,6]
for a in object_1:
print(a)
当我们得到上面的这个定义时,其实意味着:在 a 获得 object_1 里的数据时,会先悄悄地调用 __iter__方法。那么 object_1 在调用 __iter__方法之后呢?会是 1-6 吗?还是说,另有一个函数来实现返回的功能呢?
(一)调用 iter() 函数
于是,我们就可以写出下面这段代码。
# 片段3
# 调用这个函数,进入唯一的接口
for iterable in iterables:
print(iter(iterable))
#-------------------------------------------------------
# <str_iterator object at 0x0000018CD678F408>
# <list_iterator object at 0x0000018CD678F408>
# <tuple_iterator object at 0x0000018CD678F408>
# <dict_keyiterator object at 0x0000018CD6796688>
# <set_iterator object at 0x0000018CD6796688>
# <_io.TextIOWrapper name='001 迭代器.ipynb' mode='r' encoding='cp936'>
我们发现其实并没有像我们想象那样给出 1-6 的结果,返回的是 iterator ,也就是迭代器对象(实例化后的迭代器)。这说明:
1.调用 __iter__方法可以为我们构建迭代器
(调用后的结果返回给迭代器。)
2.迭代器仍然有调用某个函数
(二)迭代器的共同属性
在迭代器调用这个函数之后,我们才可能得到我们想要的结果。那我们就故技重施,看看迭代器的共同属性是什么。
# 片段4
# 迭代器的共同属性
iterators = [iter(iterable) for iterable in iterables]
iterator_common_attrs = common_attrs(*iterators)
print(iterator_common_attrs)
#-------------------------------------------------------
# {'__iter__', '__next__'}
于是,我们得到__iter__, __next__这两个方法。__iter__上文已经提到了,调用 iter() 函数可以为我们构建迭代器。所以,我们容易猜测__next__是用于:达成业务 和 返回数据 。
至此,我们终于可以给迭代器下定义了。迭代器就是:有__iter__和__next__方法的对象。
同时我们也知道了迭代的三个关键步骤:
1.调用 iter(iterable) 来构建迭代器
2.(多次)调用 next(iterator) 来获取值
3.最后捕获 StopIteration 异常来判断迭代结束
(三)抛出异常
我们现在利用__iter__, __next__这两个方法,根据上面的步骤,其实已经可以实现迭代了。代码演示如图。
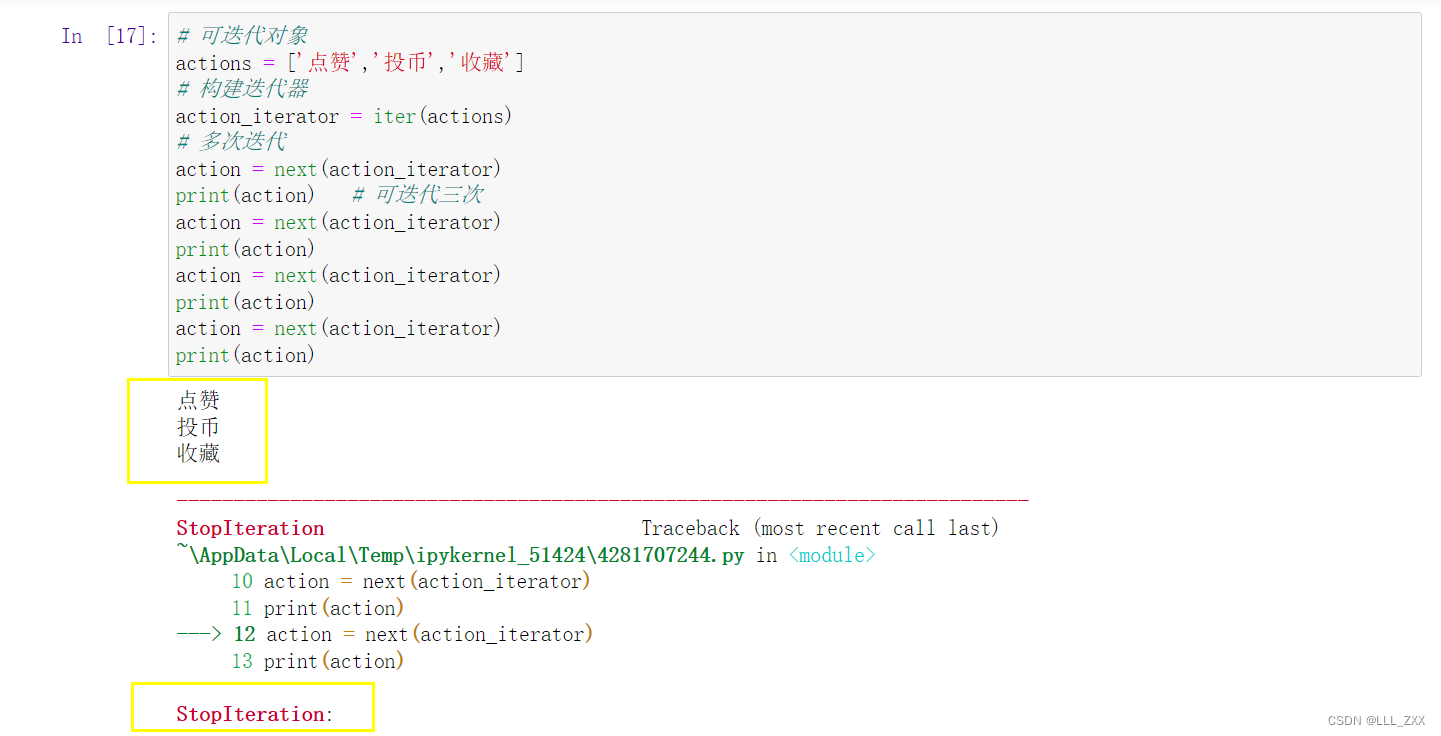
这张图值得注意的是第二个黄框的部分,编译器抛出异常。正常来说,可迭代对象有多少个元素,我们就能迭代多少次,但是我们在执行完三次迭代之后,仍然强行执行第4次的迭代,结果编译器就抛出异常。也就是说:超出可迭代次数,就会抛出异常。
(四)构建迭代器
在得到上文的两个武器之后,我们已经可以用 while 循环模拟 for 循环迭代。代码如下所示。
actions = ['点赞','投币','收藏']
iterator = iter(actions) # 对应 可迭代对象的 __iter__ 方法
while True:
try:
# 通过迭代器获取下一个对象
print(next(iterator)) # 对应迭代器的 __next__ 方法
except StopIteration: # 捕获异常来判断结束
break
上面这段代码貌似没什么实战价值,下面这段属于构建迭代器,可能更有实战价值一些,给大家参考。
# 我们可以自行设计迭代器
# 1.初始化时要传入可迭代对象,这样才能知道去哪取数据
# 2.要初始化迭代进度
# 3.每次迭代是,即每次调用 __next__() 方法时:
# 3_1 如果仍有元素可供迭代,则返回本轮迭代的元素,同时更新当前迭代进度
# 3_2 如果已无元素可供返回,则迭代结束,抛出 StopIteration 异常
BLACK_LIST = ['白嫖','取关']
class Suzhi_Iterator:
def __init__(self,action):
self.actions = actions
# 初始化索引下标
self.index = 0
def __next__(self):
while self.index < len(self.actions):
action = self.actions[self.index]
self.index += 1 # 更新索引下标
if action in BLACK_LIST:
continue
elif '币' in action:
return action * 2
else:
return action
raise StopIteration
#--------------------------------------------
def __iter__(self):
return self
#--------------------------------------------
actions = ['点赞','投币','取关']
sz_iterator = Suzhi_Iterator(actions)
for x in sz_iterator:
print(x)
在没有被短横线包围的__iter__方法时,for 循环 其实实现不了迭代的,运行后编译器就会报错:TypeError: 'Suzhi_Iterator' object is not iterable。

**因为Suzhi_Iterator(actions)根本就不是可迭代对象。**但是,这件事情又有点反直觉,一个迭代器竟然不是可迭代对象???
如果我们要用 for 循环 写出迭代,我们就必须调用iter()函数,但实际上我们根本没有用到 __iter__方法。所以,我们只需要在 class处添加上这个方法即可。值得注意的是,最后的返回值是迭代器自己,因为上文说过调用后的结果返回给迭代器,但是它就在迭代器里面呀,所以返回 self 就足够了。
三、意义与实例
(一)意义
1.浅层的意义
(1)统一通过next()方法获取数据,可以屏蔽底层不同的数据读取方式,简化编程。
(2)容器类的数据结构只关心数据的静态存储,每一次迭代都需要额外的迭代器对象专门负责记录迭代过程中的状态信息,而这可以交给迭代器去完成。
这会让我们认为:迭代器就是为了让数据结构能够快捷地遍历而定义的辅助对象。当然,这样想其实也没有什么问题,但是把迭代器看得太浅了。因为,利用下面这段代码,我们同样可以实现遍历。
actions = ['点赞','投币','收藏']
iterator = iter(actions) # 对应 可迭代对象的 __iter__ 方法
while True:
try:
# 通过迭代器获取下一个对象
print(next(iterator)) # 对应迭代器的 __next__ 方法
except StopIteration: # 捕获异常来判断结束
break
2.深层的意义
在讲深层的意义之前,请读者自行观看下方的图片。

当我们在构建迭代器的时候用到 __iter__方法时,就意味着:
(1)一个可迭代对象可以构建出任意多个不同的迭代器
(2)一种迭代器可以应用于任意多个可迭代对象(包括其它迭代器)
同时也意味着:
(1)很多个迭代器串联起来,形成一个处理数据的管道,或者称为数据流
(2)在这个管道中,每一次只通过一份数据,避免了一次性加载所有数据
(3)迭代器也不仅仅只是按顺序返回数据那么简单了,它开始承担处理数据的责任。例如,SuzhiIterator实际实现了部分过滤器和放大器的功能
(4)当通过迭代器获取数据的时候,远离了数据存储,渐渐地开始不关心数据到底是怎么存储的。(生成器)
(二)实例
实例1
Python是没有链表的,所以我们可以用迭代器写出一个链表的数据结构出来。
class NodeIter: # 相当于是一个 iterator ,实现 __next__ 这个函数
# 1.还能有 可迭代对象 时,走到下一个并返回去
# 2.在没有 可迭代对象 时,抛出错误 StopIteration
def __init__(self, node): # 魔法方法 __init__ ,作用是初始化
self.curr_node = node
def __next__(self):
if self.curr_node is None:
# 2.在没有 可迭代对象 时,抛出错误 StopIteration
raise StopIteration
# 1.还能有 可迭代对象 时,走到下一个并返回去
node, self.curr_node = self.curr_node, self.curr_node.next
return node
def __iter__(self):
return self
class Node: # 相当于是一个 iterable ,实现 __iter__ 这个函数
def __init__(self,name):
self.name = name
self.next = None
def __iter__(self):
# 需要返回 NodeIter 的对象
return NodeIter(self)
node1 = Node("node1")
node2 = Node("node2")
node3 = Node("node3")
node1.next = node2
node2.next = node3
for node in node1:
print(node.name)
实例2
生成器
from random import random
class Random:
def __iter__(self):
return self
def __next__(self):
return random()
结语
这一块的知识蛮复杂的,也挺难理解的,可以多读几遍或者评论区留言。
特别标注:此文部分知识是笔者自己的思考,大部分是 参考资料链接1 的知识整理。
参考资料链接1: 迭代器
参考资料链接2: 菜鸟教程
最后
以上就是怕孤单爆米花最近收集整理的关于迭代器详解前言一、可迭代对象(Iterable)二、迭代器(Iterator)三、意义与实例结语的全部内容,更多相关迭代器详解前言一、可迭代对象(Iterable)二、迭代器(Iterator)三、意义与实例结语内容请搜索靠谱客的其他文章。








发表评论 取消回复