背景
公司需要搭建一套大数据集群环境用于测试,本文记录其详细过程,方便后面参考
环境信息
一主两从,均为ubuntu18.04
主:192.168.10.203(mufengcn)
从:192.168.10.202(mufengcn),192.168.10.200(tsroot)
注:假定括号内为ssh用户名,均为非root用户名(真实服务器,文中涉及到的用户名图文是不对应的,我只是把文案中涉及到的用户名批量替换了下~)
准备
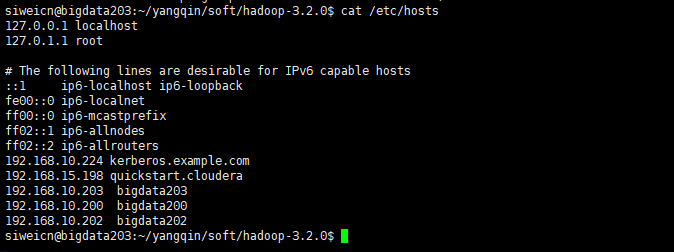
设置主机名及配置hosts
依次设置主机名,如:
sudo hostname bigdata203
sudo vi /etc/hostname

三台机器分别配置hosts
vi /etc/hosts
192.168.10.203 bigdata203
192.168.10.200 bigdata200
192.168.10.202 bigdata202
时间同步
设置相同时区:ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
同步时间:
参考连接:https://blog.csdn.net/vic_qxz/article/details/80344855
大概意思是,将一台服务器作为时间同步服务器,另外两台作为客户端直接同步。
-
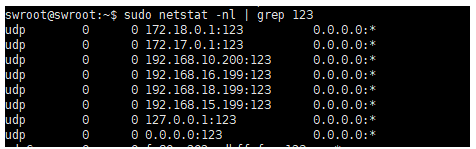
将192.168.10.200作为时间同步服务器
安装ntp: sudo apt-get install ntp 启动ntp: /etc/init.d/ntp start验证启动成功:
-
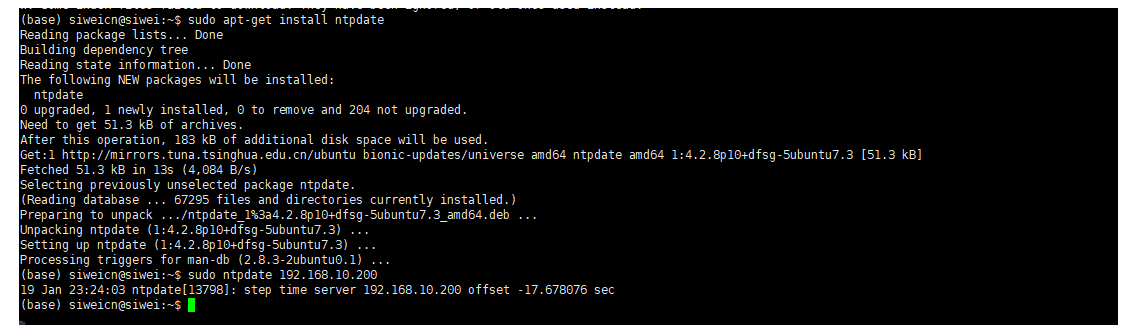
在192.168.10.203和192.168.10.202上安装客户端ntpdate
sudo apt-get install ntpdate手动同步时间测试:
sudo ntpdate 192.168.10.200
-
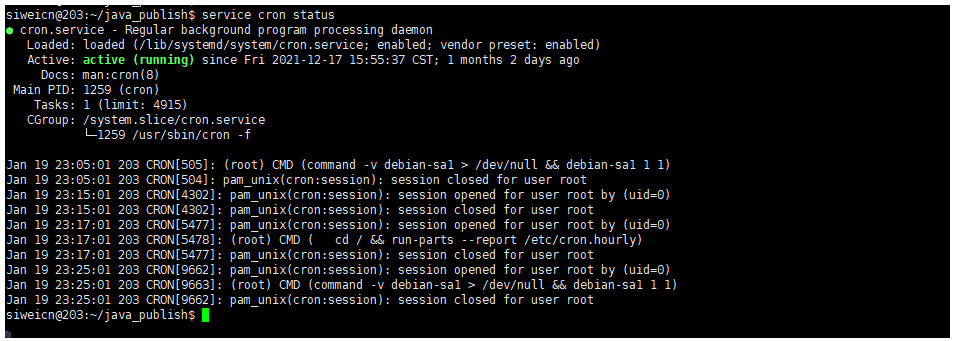
配置cron任务
确定cron服务正常启动: service cron status
在客户端(192.168.10.203,192.168.10.202)配置定时任务:crontab -e
下面表达式代表:每分钟同步一次时间,并将正确或错误消息输入到/home/mufengcn/ntpdate.log中
* * * * * sudo -n /usr/sbin/ntpdate 192.168.10.200 >>/home/mufengcn/ntpdate.log 2>&1查看当前用户的定时任务:crontab -l
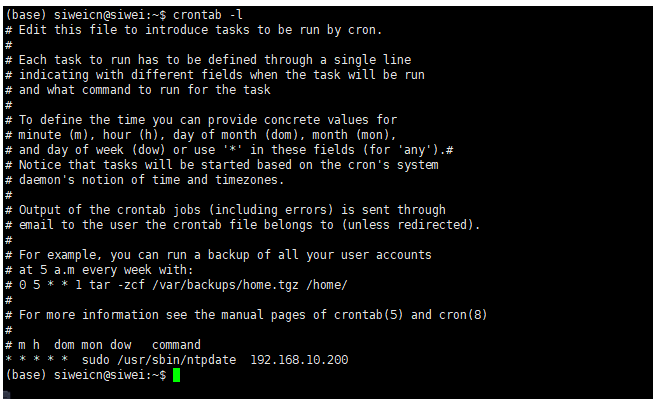
定时任务中需要sudo命令,应该设置免密:
sudo visudo -f /etc/sudoers
Defaults visiblepw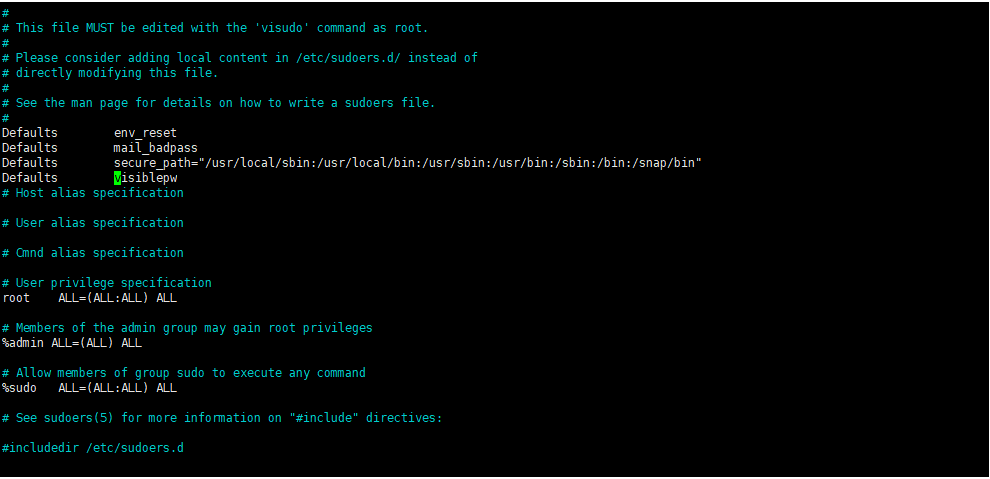
sudo visudo -f /etc/sudoers.d/ntpdate
mufengcn ALL=NOPASSWD: /usr/sbin/ntpdate
mufengcn 为当前所使用的用户名
-
查看定时任务执行情况
开启日志打印:sudo vi /etc/rsyslog.d/50-default.conf
取消注释:
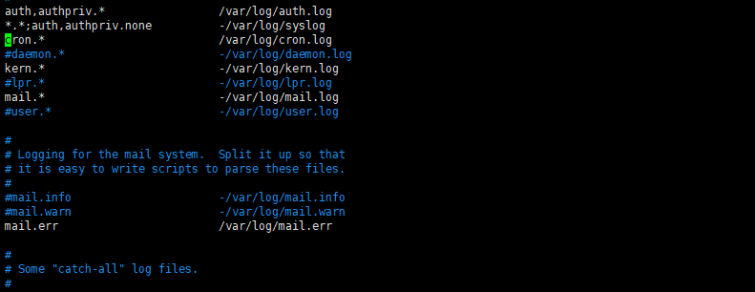
重启:sudo service rsyslog restart
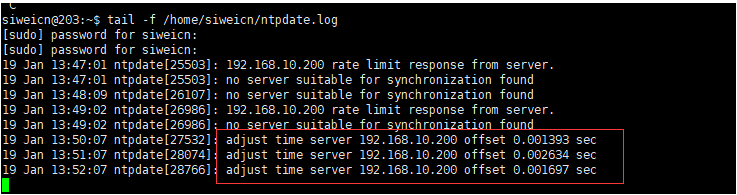
查看定时任务执行情况:tail -f /var/log/cron.log

查看ntpdate结果:tail -f /home/mufengcn/ntpdate.log
常见问题
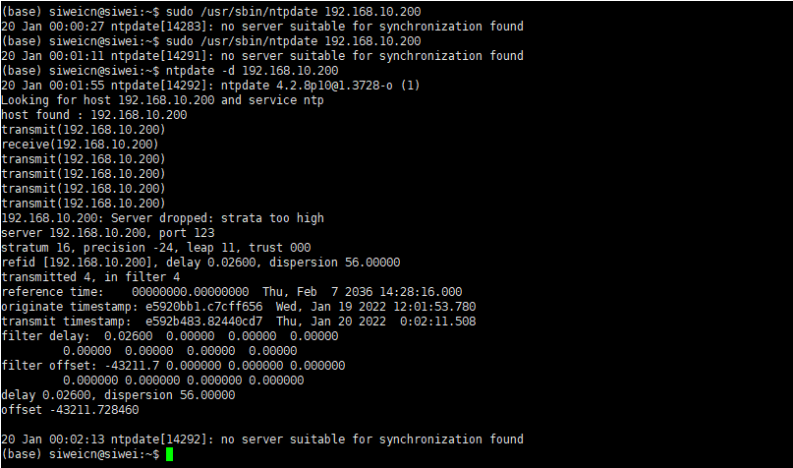
- 时间同步失败,no server suitable for synchronization found.参考以下连接调试
https://blog.csdn.net/weidan1121/article/details/3953021
- /etc/sudoers一定要用visudo 去修改,因为该工具修改错误时有语法提示。如果不小心用vi将/etc/sudoers修改错了,会导致系统不能使用sudo命令。此时的解决方案参考:
https://baijiahao.baidu.com/s?id=1623745008749543253&wfr=spider&for=pc&isFailFlag=1
关闭防火墙
sudo systemctl stop ufw.service
sudo systemctl disable ufw.service
免密登录
需要主节点向从节点复制东西免密,即将主节点的id_rsa.pub追加到从节点的authorized_keys
在主节点执行:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
把主节点的~/.ssh/authorized_keys拷贝到从节点的 ~/.ssh/authorized_keys即可
常见问题
- 假设bigdata203连不上bigdata200,可以先在bigdata200上调试(即自己连自己):
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh -vvvT bigdata200
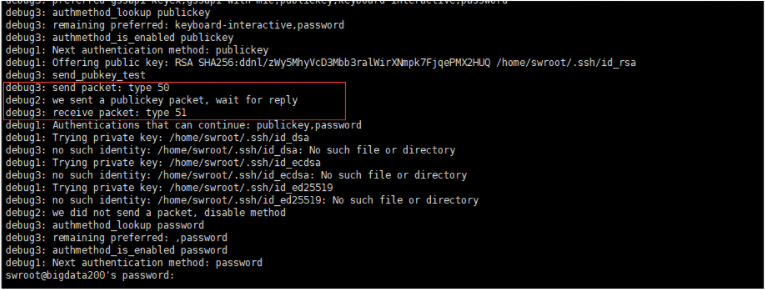
如上图所示,使用publickey认证时,正确的结果是:receive packet: type 60
解决方案:在bigdata200机器上执行
sudo chmod o-rwx /home/tsroot/ -R
- 假设bigdata200自身连接没问题,但是bigdata203上连不上bigdata200,那么继续查看调试信息,会发现是因为两台机器用户名不一样。在bigdata203上使用ssh连接bigdata200。默认是使用的当前登录用户名(mufengcn)连接的,而bigdata200没有mufengcn这个用户,所以失败
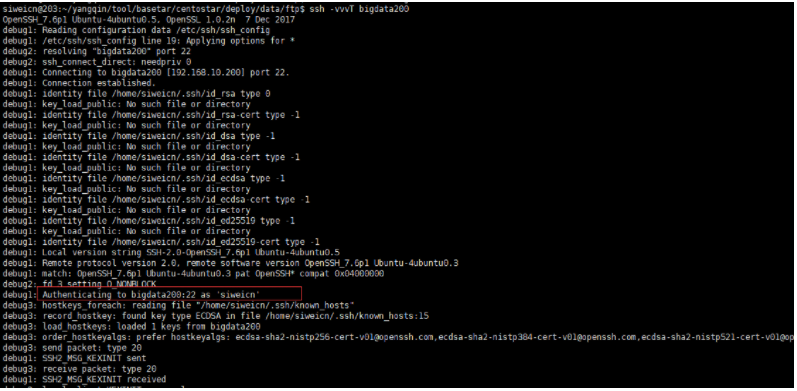
解决方案:
在bigdata203添加文件~/.ssh/config,配置用户名

hadoop集群安装
地址:http://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/
需提前安装好java,jdk 1.8即可。
架构示意如下:
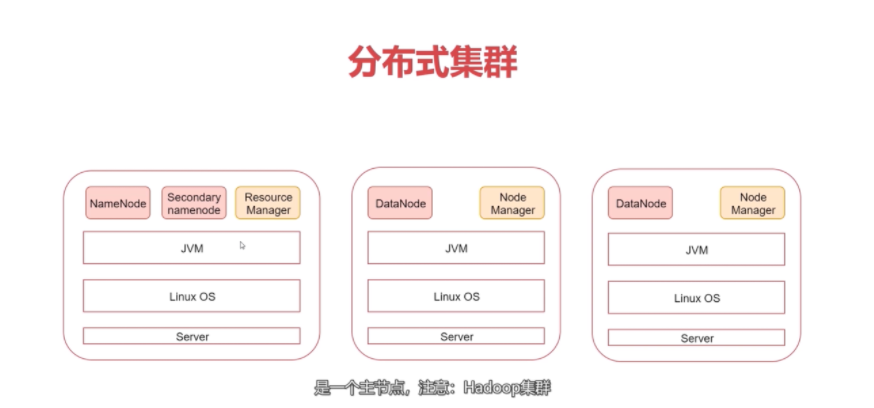
配置
主节点
hadoop-env.sh
export JAVA_HOME=/home/mufengcn/yangqin/jdk1.8.0_181
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata203:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata203:50090</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata203</value>
</property>
</configuration>
works
指定从节点信息:
bigdata200
bigdata202
后面两个配置文件修改,应该追加到最前面,方便脚本引用
sbin/start-dfs.sh sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
sbin/start-yarn.sh sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
从节点
将主节点整个配置拷贝到从节点即可
启动
在三台机机器,配置hadoop环境变量:vi /etc/profile
HADOOP_HOME=/home/mufengcn/yangqin/soft/hadoop-3.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
使环境变量生效: source /etc/profile
主节点运行:
格式化HDFS: hdfs namenode -format
启动: start-all.sh
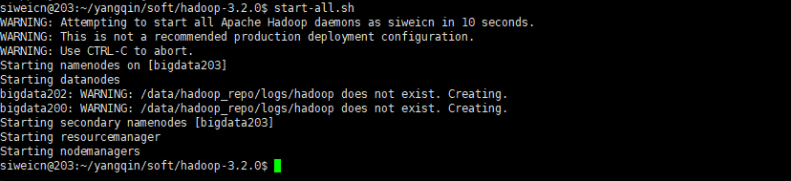
初次启动失败,可能是目录权限的原因:手工到从节点创建/data/hadoop_repo目录即可,并修改所属组为当前登录用户,如:
sudo mkdir -p /data/hadoop_repo
sudo chown tsroot:tsroot -R /data/hadoop_repo/
验证
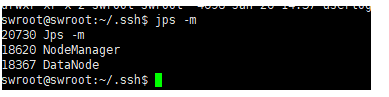
主节点查看
jps -m: 可以看到主节点启动了NameNode,SecondaryNameNode,ResourceManager

从节点查看
jps -m: 可以看到从节点只启动了DataNode,NodeManager
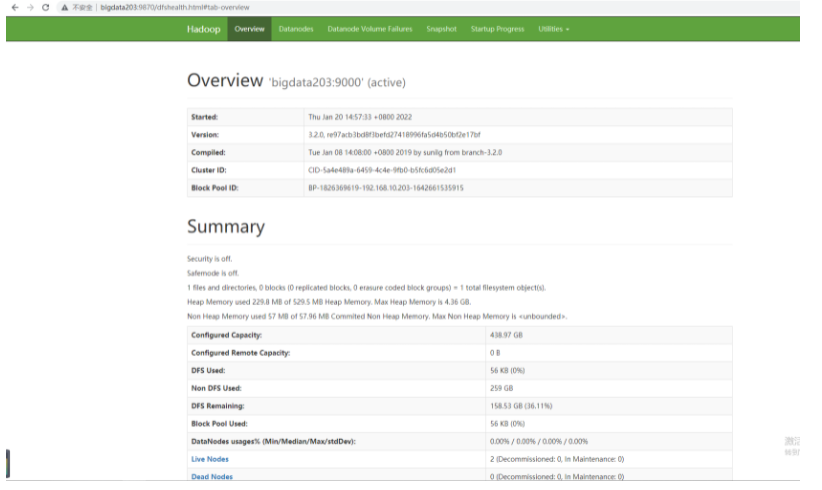
前台访问
hdfs: http://bigdata203:9870/
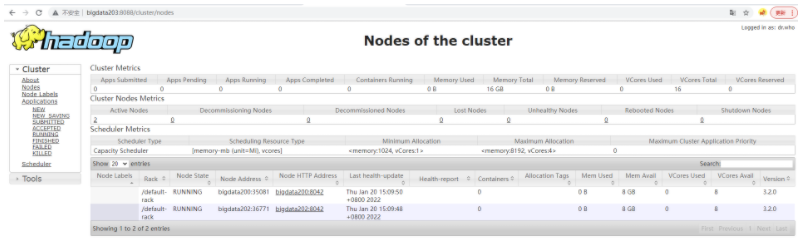
yarn: http://bigdata203:8088/
hive安装
地址: http://archive.apache.org/dist/hive/hive-3.1.2/
Hive相当于Hadoop的客户端工具,安装时不一定非要放在集群的节点中,可以放在任意一个集群客户端节点上都可以,先解压放入到/home/mufengcn/yangqin/soft/apache-hive-3.1.2-bin
配置
cd apache-hive-3.1.2-bin/conf/
mv hive-env.sh.template hive-env.sh
mv hive-default.xml.template hive-site.xml
hive-env.sh
export JAVA_HOME=/home/mufengcn/yangqin/jdk1.8.0_181
export HIVE_HOME=/home/mufengcn/yangqin/soft/apache-hive-3.1.2-bin
export HADOOP_HOME=/home/mufengcn/yangqin/soft/hadoop-3.2.0
hive-site.xml(找到并修改即可)
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://mysqlIp:3306/hive?serverTimezone=Asia/Shanghai</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPastsord</name>
<value>admin</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/data/hive_repo/querylog</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/data/hive_repo/scratchdir</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/data/hive_repo/resources</value>
</property>
在Hadoop的core-site.xml文件中增加下面配置
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
元数据库初始化
将mysql驱动程序放入hive的lib中
bin/schematool -dbType mysql -initSchema
插入数据:
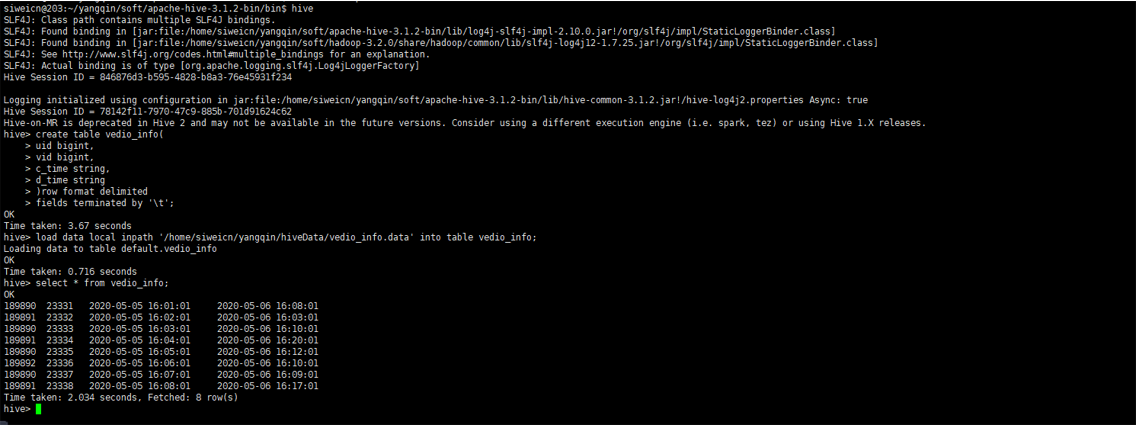
zookeeper集群安装
http://archive.apache.org/dist/zookeeper/zookeeper-3.5.8/
解压放入/home/mufengcn/yangqin/soft/apache-zookeeper-3.5.8
配置
cd apache-zookeeper-3.5.8-bin/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
dataDir=/home/mufengcn/yangqin/soft/apache-zookeeper-3.5.8-bin/data
server.0=bigdata203:2888:3888
server.1=bigdata202:2888:3888
server.2=bigdata200:2888:3888
分别在bigdata200,bigdata202,bigdata203执行:
echo 2 > data/myid
echo 1 > data/myid
echo 0 > data/myid
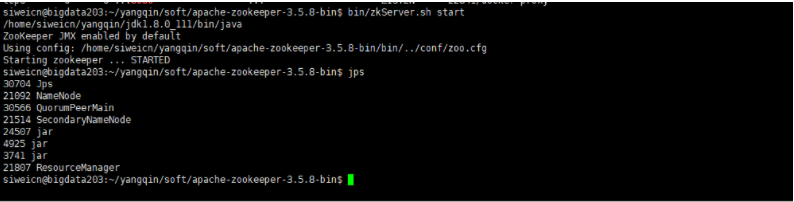
启动
主从节点分别启动
bin/zkServer.sh start
验证
如果能看到QuorumPeerMain进程就说明zookeeper启动成功
jps
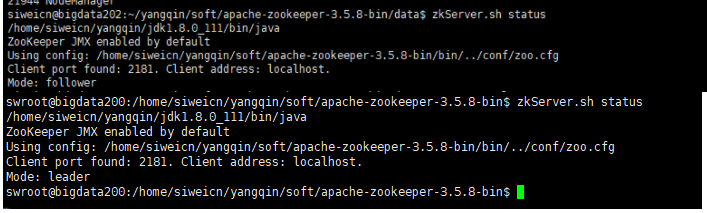
通过zkServer.sh status查看主从节点(leader和follower)
常用命令
进入shell: bin/zkCli.sh
创建test节点,存储hello数据:create /test hello
查看test节点内容: get /test
删除节点: deleteall
kafka安装
http://archive.apache.org/dist/kafka/2.4.1/
注意:由于Kafka需要依赖于Zookeeper,所以在这我们需要先把Zookeeper安装部署起来
解压:
配置
vi server.properties
broker.id=0
log.dirs=/home/mufengcn/yangqin/soft/kafka_2.12-2.4.1/kafka-logs
zookeeper.connect=bigdata203:2181,bigdata202:2181,bigdata200:2181
broker.id的值默认是从0开始的,集群中所有节点的broker.id从0开始递增即可
启动
三台机器依次启动
bin/kafka-server-start.sh -daemon config/server.properties
常用命令
启动:bin/kafka-server-start.sh -daemon config/server.properties
查看topic:bin/kafka-topics.sh --list --zookeeper localhost:2181
生产者:bin/kafka-console-producer.sh --broker-list 192.168.10.203:9092 --topic YQ_Topic
消费者:bin/kafka-console-consumer.sh --bootstrap-server 192.168.10.203:9092 --topic YQ_Topic --from-beginning
配置认证
默认情况无认证,常见的有acl和kerberos两种认证方式
acl认证
配置
server
config/server.properties
listeners=SASL_PLAINTEXT://:9092
allow.everyone.if.no.acl.found=true
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
super.users=User:admin
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.enabled.mechanisms=PLAIN
listeners=SASL_PLAINTEXT://:9092,这里虽然没有写IP地址,但是它会监听所有IP
bin/kafka-server-start.sh追加KAFKA_HEAP_OPTS
export KAFKA_HEAP_OPTS="$KAFKA_HEAP_OPTS -Djava.security.auth.login.config=/home/siweicn/yangqin/soft/kafka_2.12-2.4.1/jaas/kafka-server-jaas.conf"
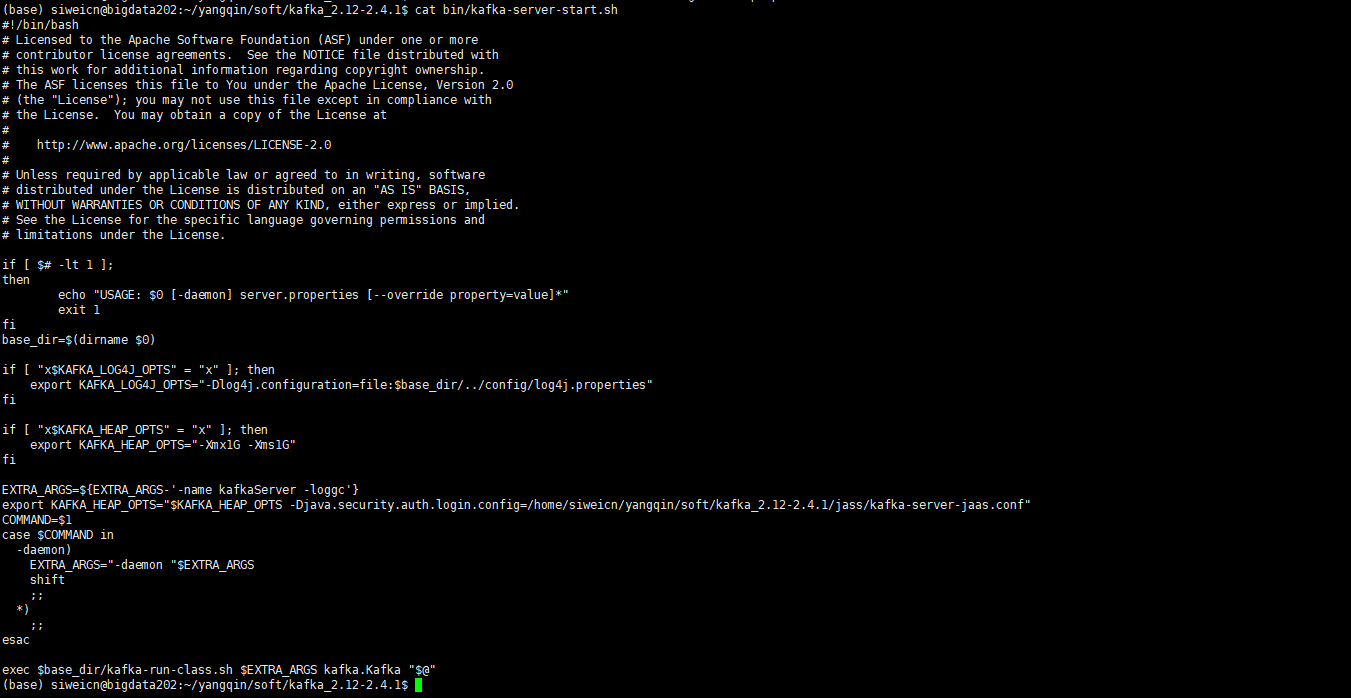
创建jass/kafka-server-jaas.conf
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin"
user_admin="admin"
user_writer="writer"
user_reader="reader";
};
生产者
bin/kafka-console-producer.sh追加KAFKA_HEAP_OPTS
KAFKA_HEAP_OPTS="$KAFKA_HEAP_OPTS -Djava.security.auth.login.config=/home/siweicn/yangqin/soft/kafka_2.12-2.4.1/jaas/kafka-writer-jaas.conf"
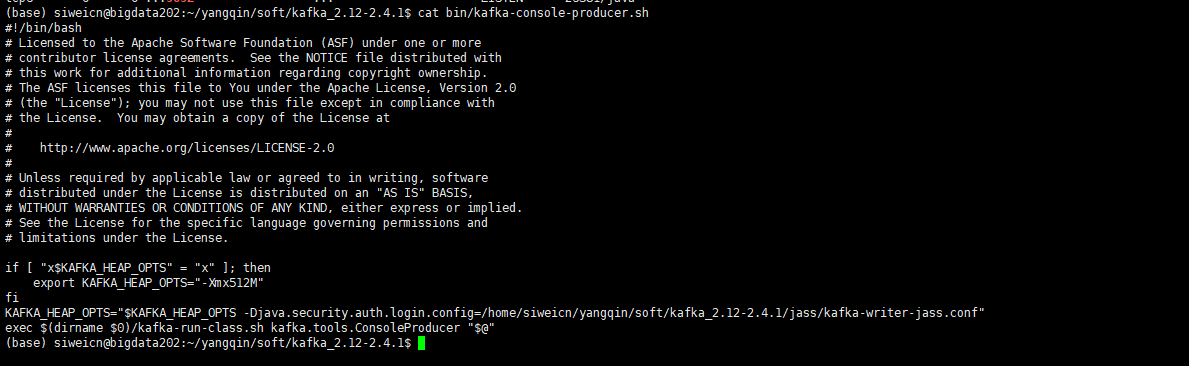
创建jaas/kafka-writer-jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="writer"
password="writer";
};
消费者
bin/kafka-console-consumer.sh追加KAFKA_HEAP_OPTS
KAFKA_HEAP_OPTS="$KAFKA_HEAP_OPTS -Djava.security.auth.login.config=/home/siweicn/yangqin/soft/kafka_2.12-2.4.1/jaas/kafka-reader-jaas.conf"
创建jaas/kafka-reader-jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="reader"
password="reader";
};
授权
授权,可以指定某个用户在某个topic下有什么权限。所以首先创建topic
bin/kafka-topics.sh --create --zookeeper bigdata203:2181 --topic yangqin_acl --partitions 1 --replication-factor 1
生产者-写权限
bin/kafka-acls.sh --authorizer kafka.security.auth.SimpleAclAuthorizer --authorizer-properties zookeeper.connect=bigdata203:2181,bigdata202:2181,bigdata200:2181 --add --allow-principal User:writer --operation Write --topic yangqin_acl
消费者-读权限
bin/kafka-acls.sh --authorizer kafka.security.auth.SimpleAclAuthorizer --authorizer-properties zookeeper.connect=bigdata203:2181,bigdata202:2181,bigdata200:2181 --add --allow-principal User:reader --operation Read --topic yangqin_acl
查看当前topic的授权情况
bin/kafka-acls.sh --list --authorizer-properties zookeeper.connect=bigdata203:2181,bigdata202:2181,bigdata200:2181

验证
启动kafkaserver
bin/kafka-server-start.sh -daemon config/server.properties
因为在server.properties中指定了认证方式为SASL_PLAINTEXT,所以在启动生产者、消费者时也需要指定认证方式,否则启动时会报连接不上:bin/kafka-console-producer.sh --broker-list bigdata203:9092 --topic yangqin_acl

可以通过配置文件指定认证方式
vi jaas/producer.conf
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
vi jaas/consumer.conf
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
两者内容是一样的,其实可以写到同一个文件即可
启动生产者
bin/kafka-console-producer.sh --broker-list bigdata203:9092 --topic yangqin_acl --producer.config jaas/producer.conf

启动消费者
bin/kafka-console-consumer.sh --bootstrap-server bigdata203:9092 --topic yangqin_acl --from-beginning --consumer.config jaas/consumer.conf

备注
除了config/server.properties中的broker.id不同,集群中所有节点配置是一样的
kerberos认证
之前写过单机环境下kafka配置kerberos的文章:https://blog.csdn.net/qq_31076523/article/details/117026263
集群环境下的配置也差不多。
安装配置kdc
sudo apt install krb5-{admin-server,kdc}
安装过程选项如下:
- Default Kerberos version 5 realm? EXAMPLE.COM
- Kerberos servers for your realm: bigdata203
- Administrative server for your Kerberos realm: bigdata203
我是在某个节点下安装kdc的,所以kdc的主机名直接写某个节点即可。
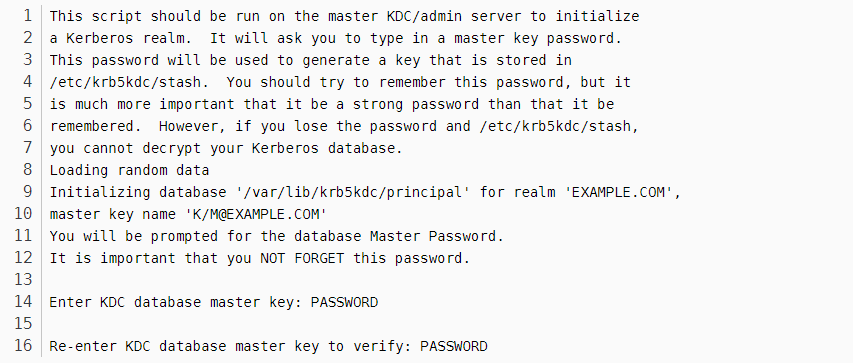
安装完成后会自动启动失败,这是因为还未初始化。初始化如下:
sudo krb5_newrealm
设置密码即可
修改配置文件:vi /etc/krb5.conf
[realms]
EXAMPLE.COM = {
kdc = bigdata203
admin_server = bigdata203
}
[logging]
kdc = FILE:/var/log/kerberos/krb5kdc.log
admin_server = FILE:/var/log/kerberos/kadmin.log
default = FILE:/var/log/kerberos/krb5lib.log
重启kdc:
sudo systemctl restart krb5-admin-server
sudo systemctl restart krb5-kdc
设置kdc开机自动启动:
sudo systemctl enable krb5-admin-server
sudo systemctl enable krb5-kdc
添加用户并生成keytab,可以所有用户共用一个keytab:
kadmin.local
add_principal kafka/bigdata203@EXAMPLE.COM
add_principal kafka/bigdata200@EXAMPLE.COM
add_principal kafka/bigdata202@EXAMPLE.COM
xst -k kafka_krb5.keytab kafka/bigdata203@EXAMPLE.COM
xst -k kafka_krb5.keytab kafka/bigdata200@EXAMPLE.COM
xst -k kafka_krb5.keytab kafka/bigdata202@EXAMPLE.COM
q
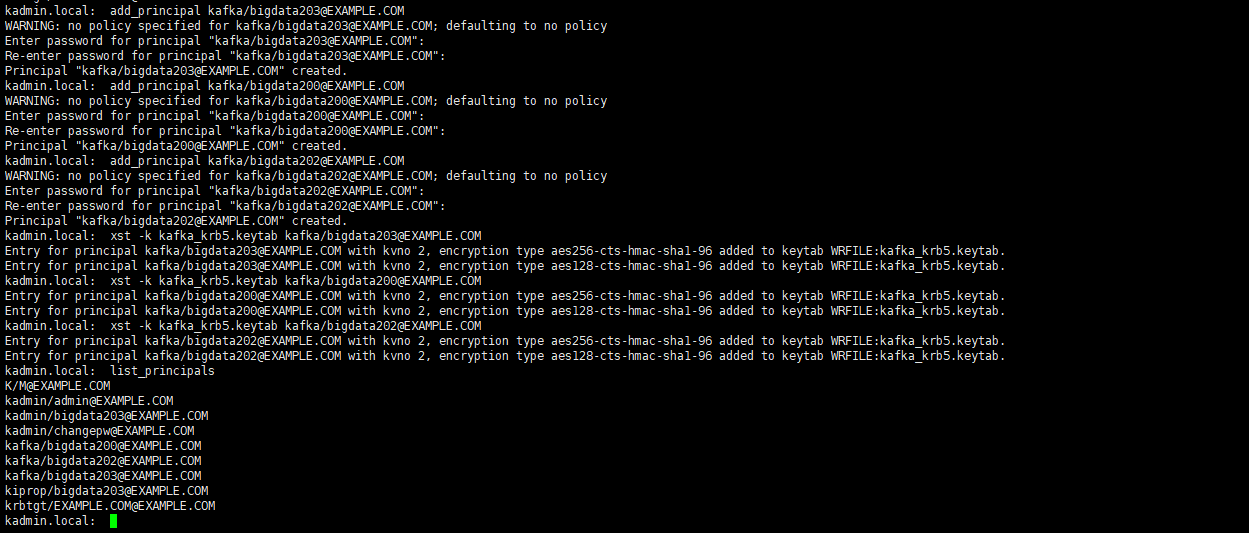
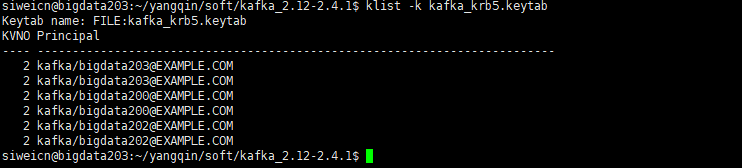
查看keytab
klist -k kafka_krb5.keytab
准备
配置
为了不影响之前的acl认证,从bin下的原始相关文件复制出来以便做kerberos认证配置(如果之前按照本文修改了acl相关配置,则需先在新脚本文件中重置相关修改,即移出KAFKA_HEAP_OPTS)
主节点配置
cp bin/kafka-server-start.sh bin/kafka-server-start-kerberos.sh
cp bin/kafka-console-consumer.sh bin/kafka-console-consumer-kerberos.sh
cp bin/kafka-console-producer.sh bin/kafka-console-producer-kerberos.sh
cp bin/kafka-run-class.sh bin/kafka-run-class-kerberos.sh
kafka-server-start-kerberos.sh
exec $base_dir/kafka-run-class-kerberos.sh $EXTRA_ARGS kafka.Kafka "$@"
kafka-console-consumer-kerberos.sh
exec $(dirname $0)/kafka-run-class-kerberos.sh kafka.tools.ConsoleConsumer "$@"
kafka-console-producer-kerberos.sh
exec $(dirname $0)/kafka-run-class-kerberos.sh kafka.tools.ConsoleProducer "$@"
kafka-run-class-kerberos.sh
KAFKA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/home/siweicn/yangqin/soft/kafka_2.12-2.4.1/jaas/kafka-server-jaas-kerberos.conf"
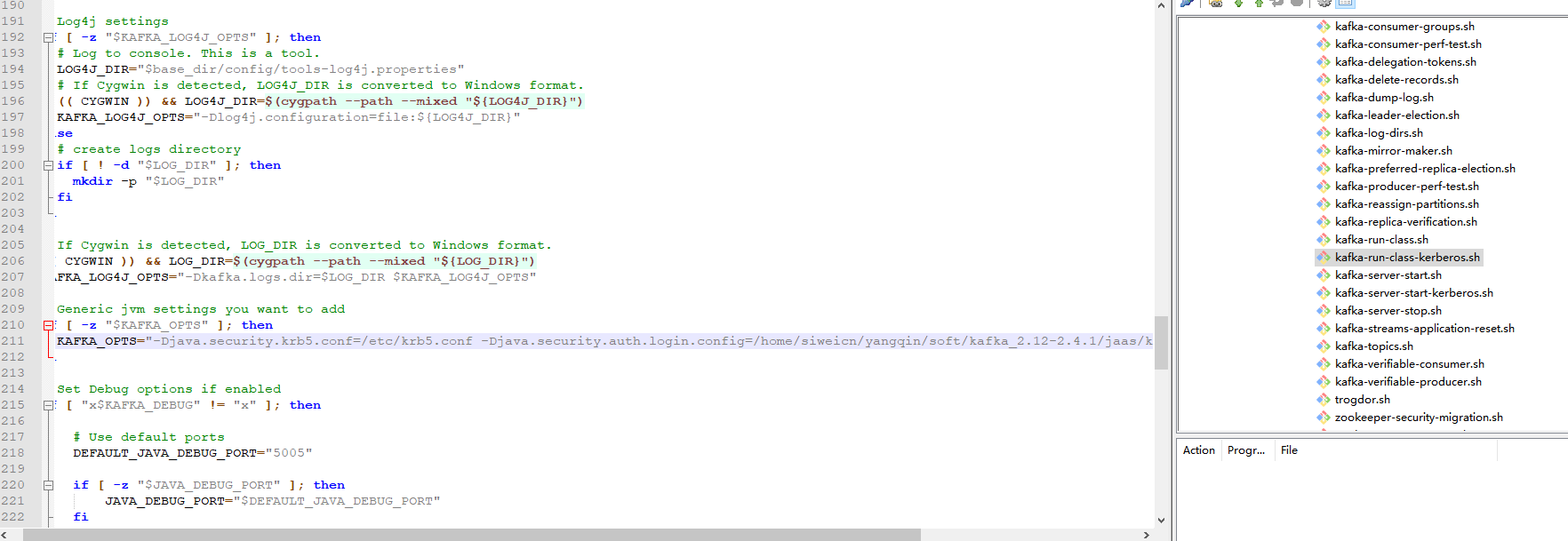
上述修改将启动kafka,生产者,消费者的脚本都引用kafka-run-class-kerberos.sh,所以最后的修改都在kafka-run-class-kerberos.sh脚本中,实际就是配置了一个krb5.conf和kafka-server-jaas-kerberos.conf文件,krb5.conf前面已编辑后,接下来编写jaas/kafka-server-jaas-kerberos.conf
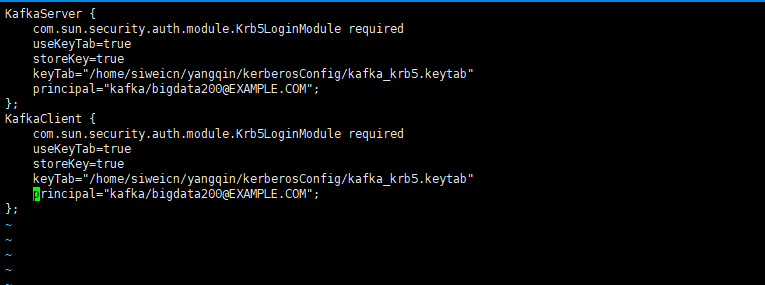
KafkaServer {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/home/siweicn/yangqin/kerberosConfig/kafka_krb5.keytab"
principal="kafka/bigdata203@EXAMPLE.COM";
};
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/home/siweicn/yangqin/kerberosConfig/kafka_krb5.keytab"
principal="kafka/bigdata203@EXAMPLE.COM";
};
该文件指定了之前创建的principal和keytab文件,路径根据实际填写即可
配置的最后一步:替换JCE
注意和jdk版本对应,我安装的是jdk8.
下载地址:https://www.oracle.com/java/technologies/javase-jce8-downloads.html
将local_policy.jar、US_export_policy.jar替换到java安装目录下的 jre/lib/security/
这步非常重要,如果不替换总是会提示验证失败:
Connection to node failed authentication due to: Authentication failed due to invalid credentials with SASL mechanism……
其他节点配置
内容几乎完全一样,将相关内容先复制过去:包括krb5.conf,keytab,jce相关jar包,kafka整个文件夹
scp -rq /etc/krb5.conf bigdata202:/etc/
scp -rq /home/siweicn/yangqin/kerberosConfig/kafka_krb5.keytab bigdata202:/home/siweicn/yangqin/kerberosConfig
scp -rq /home/siweicn/yangqin/jdk1.8.0_111/jre/lib/security/* bigdata202:/home/siweicn/yangqin/jdk1.8.0_111/jre/lib/security/
scp -rq /home/siweicn/yangqin/soft/kafka_2.12-2.4.1/ bigdata202:/home/siweicn/yangqin/soft/
scp -rq /etc/krb5.conf bigdata200:/etc/
scp -rq /home/siweicn/yangqin/kerberosConfig/kafka_krb5.keytab bigdata200:/home/siweicn/yangqin/kerberosConfig
scp -rq /home/siweicn/yangqin/jdk1.8.0_111/jre/lib/security/* bigdata200:/home/siweicn/yangqin/jdk1.8.0_111/jre/lib/security/
scp -rq /home/siweicn/yangqin/soft/kafka_2.12-2.4.1/ bigdata200:/home/siweicn/yangqin/soft/
在bigdata200上修改:
设置以下两个文件中的broker.id=1
vi config/server.properties
vi config/server-kerberos.properties
将kafka-server-jaas-kerberos.conf的principal中的203换为200
vi jaas/kafka-server-jaas-kerberos.conf
删除多余的日志文件和数据文件(不同broker上的数据是不同的)
rm -rf logs/ kafka-logs/
在bigdata202上修改:
和bigdata200一致:
- 将server.properties、server-kerberos.properties中broker.id写成2,
- 将kafka-server-jaas-kerberos.conf中的principal使用kafka/bigdata202@EXAMPLE.COM
- 删除多余的日志文件和数据文件
验证
启动kafka
bin/kafka-server-start-kerberos.sh -daemon config/server-kerberos.properties
启动生产者
bin/kafka-console-producer-kerberos.sh --broker-list bigdata203:9092 --topic topicTest --producer.config config/producer-kerberos.properties
启动消费者
bin/kafka-console-consumer-kerberos.sh --bootstrap-server bigdata203:9092 --topic topicTest --from-beginning --consumer.config config/consumer-kerberos.properties
启动生产者和消费者时的bootstrap-server可以为bigdata203,bigdata202,bigdata200中的任意一个


备注:经测试,当开启一个生产者时(如bigdata203),在分别在bigdata203,bigdata202,bigdata200开启一个消费者,启动命令中指定的bootstrap-server分别为bigdata203,bigdata202,bigdata200。当产生一条消息时,始终只有一个shell中的消费者够收到,如果把这个消费者关掉,再产生新的消息时,剩余两个中的某个消费者才能收到。即三个消费者不能同时收到生成者产生的消息。但是同样条件下,acl认证时可以同时收到,暂未搞清楚原由
hbase集群安装
地址:http://archive.apache.org/dist/hbase/2.2.7/
配置
hbase-env.sh
export JAVA_HOME=/home/mufengcn/yangqin/jdk1.8.0_111
export HADOOP_HOME=/home/mufengcn/yangqin/soft/hadoop-3.2.0
export HBASE_MANAGES_ZK=false
export HBASE_LOG_DIR=/home/mufengcn/yangqin/soft/hbase-2.2.7/logs
hbase-site.xml
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/mufengcn/yangqin/soft/hbase-2.2.7/tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!--设置HBase表数据,也就是HBase数据在hdfs上的存储根目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://bigdata203:9000/hbase</value>
</property>
<!--zookeeper集群的URL配置,多个host中间用逗号隔开-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata203,bigdata202,bigdata200</value>
</property>
<!--HBase在zookeeper上数据的根目录znode节点-->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<!--设置zookeeper通信端口,不配置也可以,zookeeper默认就是2181-->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
因为bigdata200的用户为tsroot,bigdata203的用户为mufengcn,所以有可能导致bigdata200没有权限向hadoop目录写入数据而启动失败

解决方案:关闭hadoop权限验证即可
hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata203:50090</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
修改hadoop配置文件后需要重启生效
regionservers
bigdata202
bigdata200
启动
bin/start-hbase.sh
验证
后台查看:hbase shell
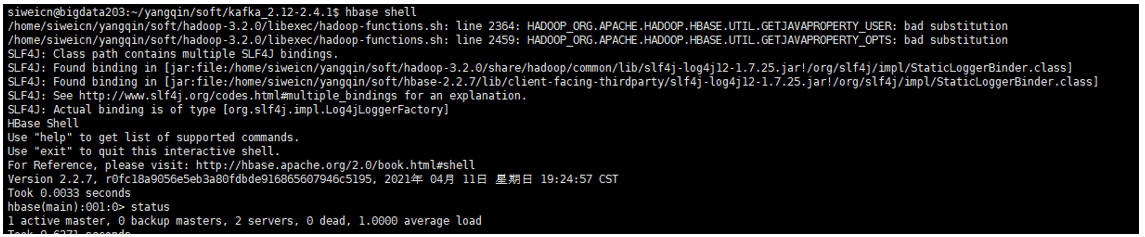
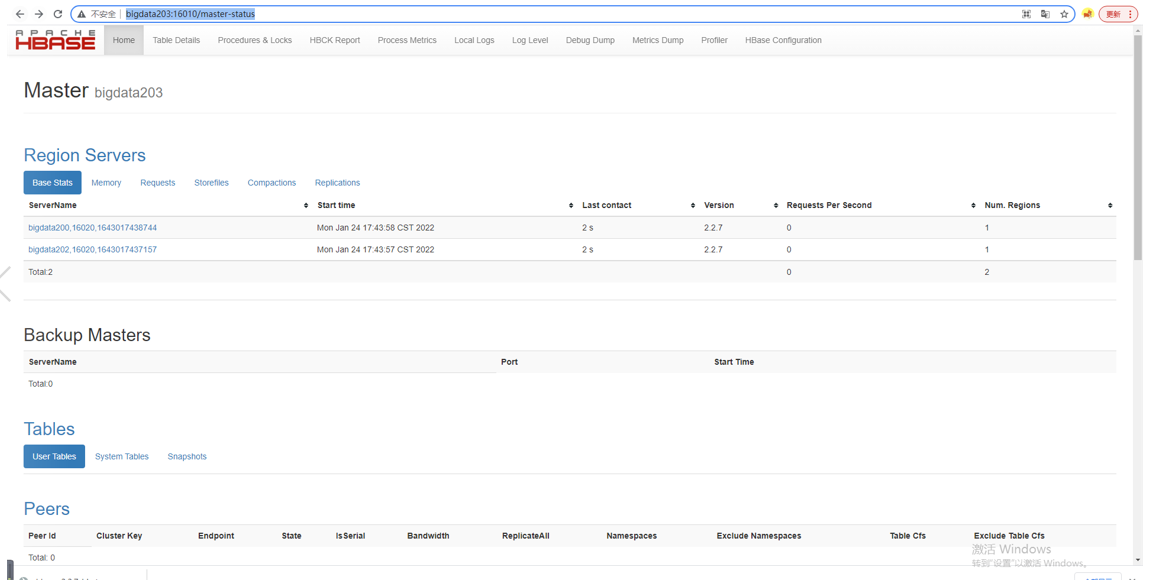
前台访问:http://bigdata203:16010/master-status
最后
以上就是无奈狗最近收集整理的关于大数据集群环境搭建详细步骤,涉及zookeeper,hadoop,hive,hbase,kafka背景环境信息准备hadoop集群安装hive安装zookeeper集群安装kafka安装hbase集群安装的全部内容,更多相关大数据集群环境搭建详细步骤内容请搜索靠谱客的其他文章。








发表评论 取消回复