目录
一.一维数组
二.二维数组
三.数组越界
四. 数组作为函数参数
五.数组的应用实例
一.一维数组
1.数组的创建
数组是一组相同类型元素的集合。 数组的创建方式:
type_t arr_name [const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小
注意:const_n是一个常量表达式
我们来看几个数组创建的实例:
//代码1
int arr1[10];
//代码2
int n = 10;
int arr2[n];//数组时候可以正常创建?
//代码3
char arr3[10];
float arr4[1];
double arr5[20];我们发现,数组二并不能成功创建
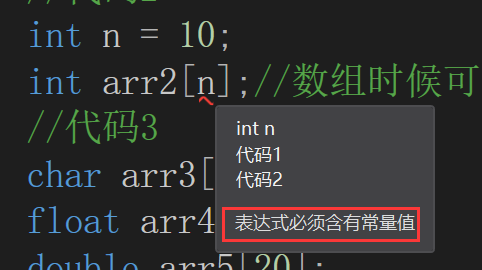
C99标准之前是不支持使用变量的,只能是常量
C99中增加了变常数组的概念,允许数组的大小是变量
而且要求编译器支持C99标准
而VS对C99的支持就不够好
2.一维数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };//完全初始化
int arr[10] = { 1,2,3 };//不完全初始化,剩余元素默认初始化为0
int arr[10] = { 0 };//所有元素初始化为0
int arr[] = { 1,2,3 };// []会根据你初始化的内容来确定有多少个元素,所以里面可以不放数字
char arr[] = { 'a',98,'c' };//98是字母b的ASCII码值
return 0;
}这是一些数组的初始化
下面讲一下两个数组初始化的区别
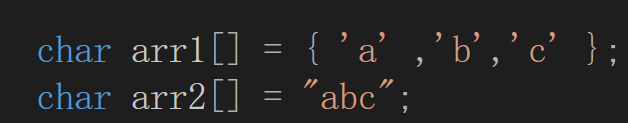
上面的数组有三个元素,数组的大小是3个字节
下面的数组有4个元素,数组的大小是4个字节
字符串初始化数组在最后多了个“�”
这里我们可以用操作符sizeof来计算一下他们所占空间的大小
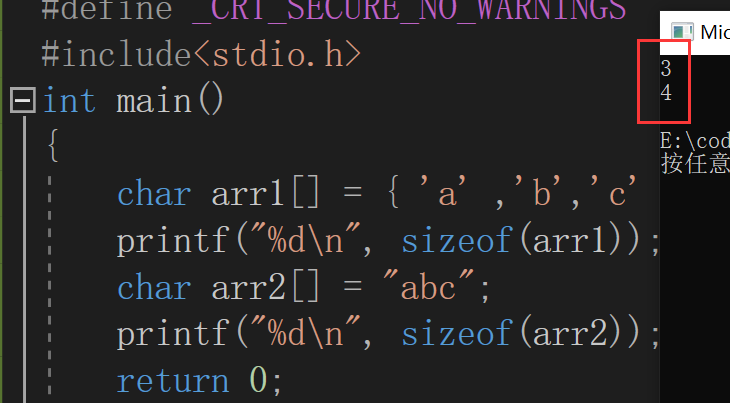
可见,上面的结论正确
并且我们可以知道操作符sizeof是不在乎内存中是否有�的,只关注空间多少
如果我们想求字符串长度

由于数组arr1里没有�,strlen不知道什么时候能遇到�,所以打印一个随机值
可知,strlen是关注字符中是否含有�的,计算的是�之前的字符个数
在这里,我们不妨把strlen 和 sizeof做一个对比,防止混淆
strlen是一个库函数
- 计算的是字符串的长度,并且只能针对字符串,
- 关注的是字符中是否含有�,计算的是�之前的字符个数
sizeof是一个操作符(运算操作符)
- sizeof是用来计算变量所占内存空间大小的,任何类型都可以使用
- 只关注空间大小 ,不关注内存中是否存在�
3.一维数组的使用
对于数组的使用我们之前介绍了一个操作符: [] ,下标引用操作符。它其实就数组访问的操作符。
下标是用来访问数组里的元素的
如果我们要打印数组里的所有十个元素
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
//0—9
int i = 0;
//计算数组元素的个数
int sz = sizeof(arr) / sizeof(arr[0]);
//40 / 4 =10
for (i = 0;i < sz; i++)
{
printf("%dn", arr[i]);
}
return 0;
}
需要注意的是这里我们计算数组元素个数的方式是这样的

如果想输入数组呢?
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
//0—9
int i = 0;
//计算数组元素的个数
int sz = sizeof(arr) / sizeof(arr[0]);
//40 / 4 =10
for (i = 0;i < sz; i++)
{
scanf("%d", &arr[i]);
}
for (i = 0;i < sz; i++)
{
printf("%d", arr[i]);
}
return 0;
} 
我们只需要添加这么一个循环
4.一维数组在内存中的存储
我们打印一下每个元素的地址
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//打印每个元素的地址
int i = 0;
for (i = 0;i < 10;i++)
{
printf("&arr[%d]=%pn", i, &arr[i]);
}
return 0;
}
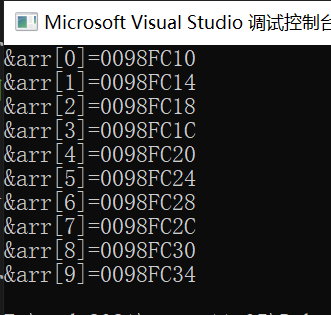
仔细观察输出的结果,我们知道,随着数组下标的增长,元素的地址,也在有规律的递增。我们发现数组中的相邻的两个元素的地址都相差4,而一个整型元素的大小是4个字节, 由此可以得出结论:数组在内存中是连续存放的。

我们发现:
- 一维数组在内存中是连续存放的
- 数组随着下标的增长,地址是由低到高变化的
当然,这里如果想打印数组元素的地址,我们也可以用指针
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//打印每个元素的地址
int i = 0;
int *p = &arr[i];
for (i = 0;i < 10;i++)
{
printf("%pn", p + i);
}
return 0;
}于是,我们也可以用指针来访问数组,这样就可以不用下标访问数组,也可以打印数组元素

同样达到了效果
二.二维数组
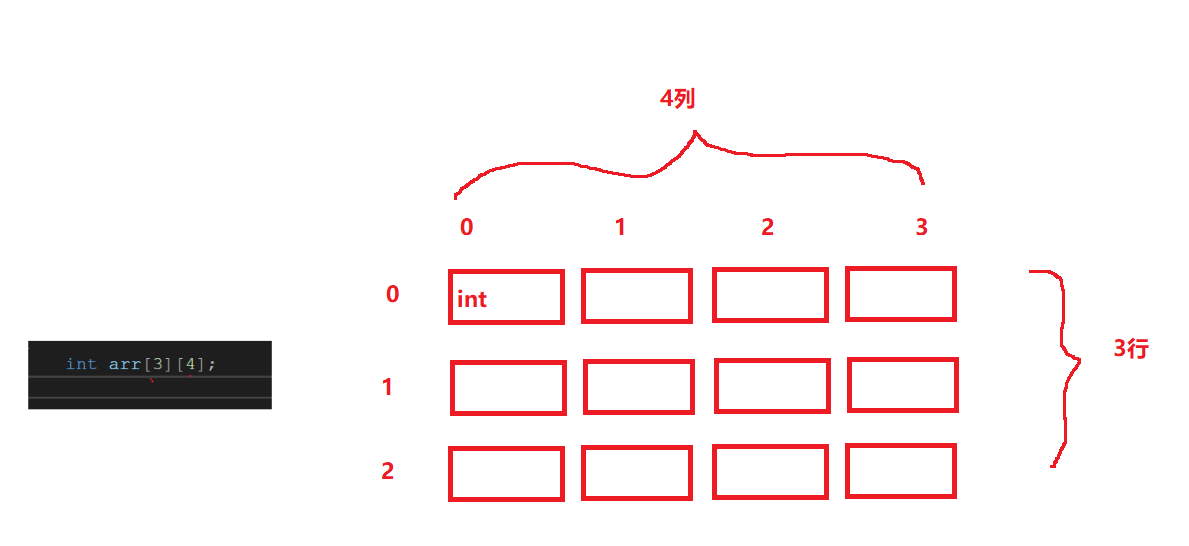
1.二维数组的创建
//数组创建
int arr[3][4];
char arr[3][5];
double arr[2][4];
2.二维数组的初始化
//数组初始化
int arr[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12};//这样初始化是先放满一行再往下一行放
int arr[3][4] = {{1,2},{4,5}}; //这样初始化是1,2放在第一行 。 4,5放在第二行
int arr[ ][4] = {{2,3},{4,5}}; //这样初始化是默认为两行
注意:
对于二维数组int array[M][N], 说明如下:
1. M和N都必须为常数,
2. M代表数组有M行,N代表每行中有N个元素
3. 其中M可以省略,省略后必须给出初始化表达式,编译器从初始化结果中推断数组有多少行
4. N一定不能省略,因为N省略了就不能确定一行有多少个元素,也不能确定数组有多少行
3.二维数组的使用
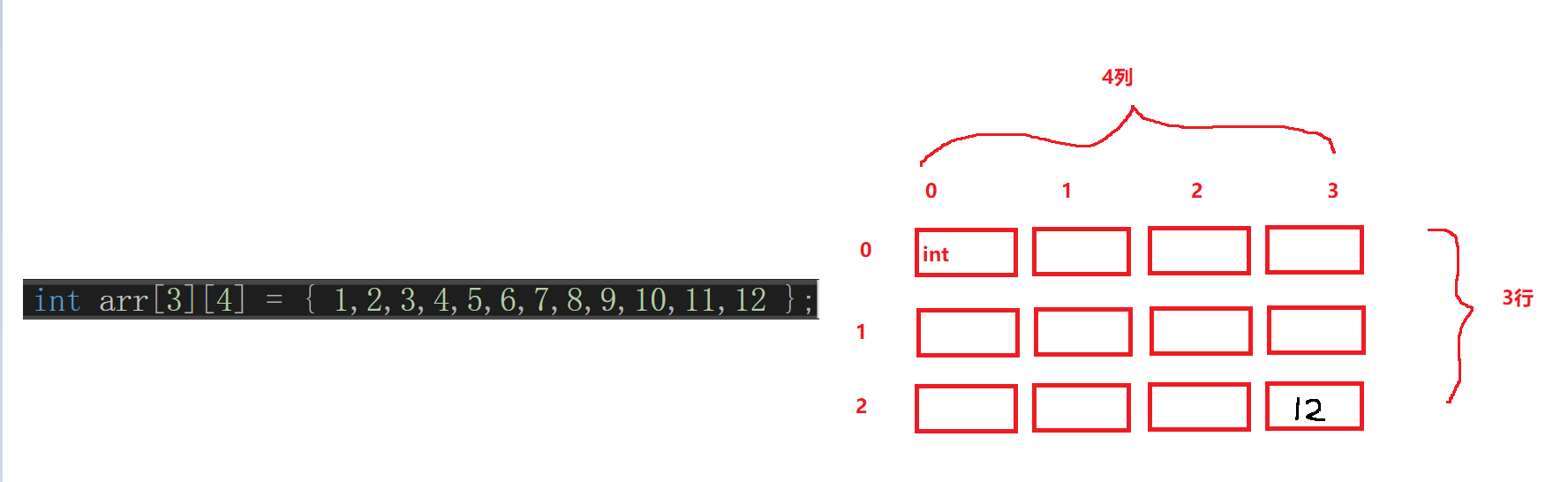
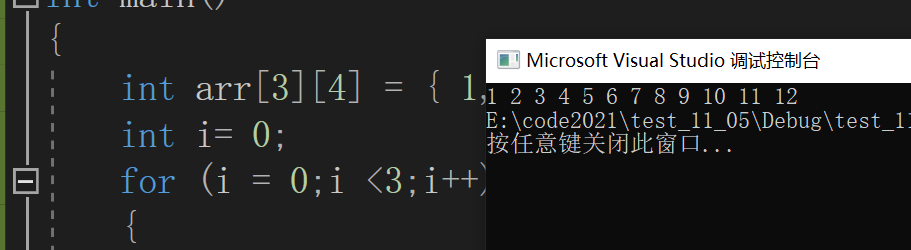
如图 arr[2][3]指的就是第三行第四列的元素12
如果要打印每一个元素,要用到两层循环
int main()
{
int arr[3][4] = { 1,2,3,4,5,6,7,8,9,10,11,12 };
int i= 0;
for (i = 0;i <3;i++)
{
int j = 0;
for (j = 0;j < 4;j++)
{
printf("%d ", arr[i][j]);
}
}
return 0;
}
4.二维数组在内存中的存储
我们还是先打印一下数组每个元素的地址
int main()
{
int arr[3][4] = { 1,2,3,4,5,6,7,8,9,10,11,12 };
int i= 0;
for (i = 0;i <3;i++)
{
int j = 0;
for (j = 0;j < 4;j++)
{
printf("&arr[%d][%d]=%pn", i, j,&arr[i][j]);
}
}
return 0;
}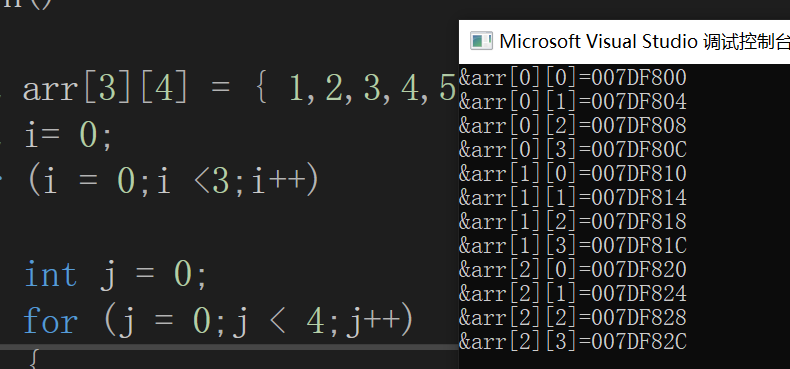
可以清楚的看到,每两个相邻的元素的地址还是都相差4,第一行的最后一个和第二行的第一个也是如此,由此我们得到结论 :二维数组在内存中也是连续存储的。
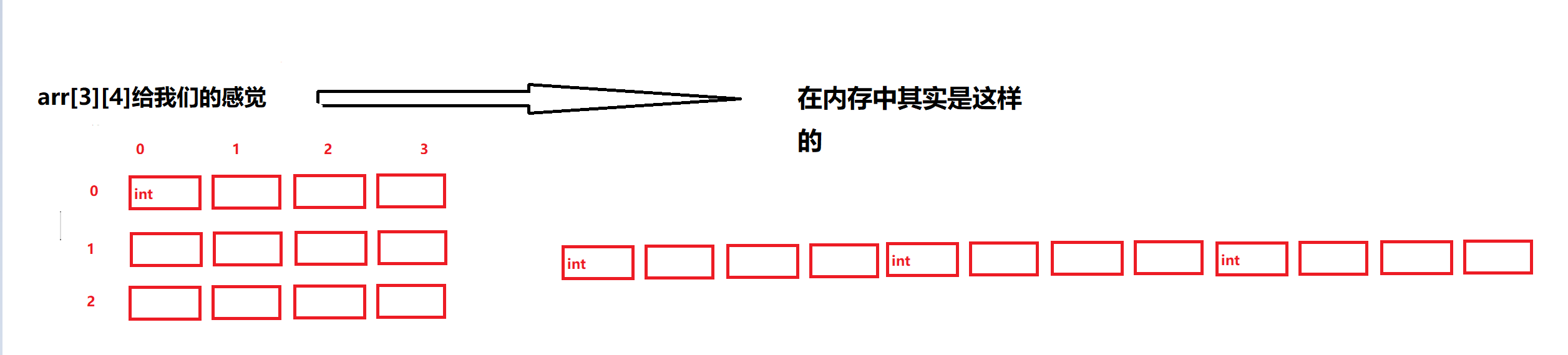
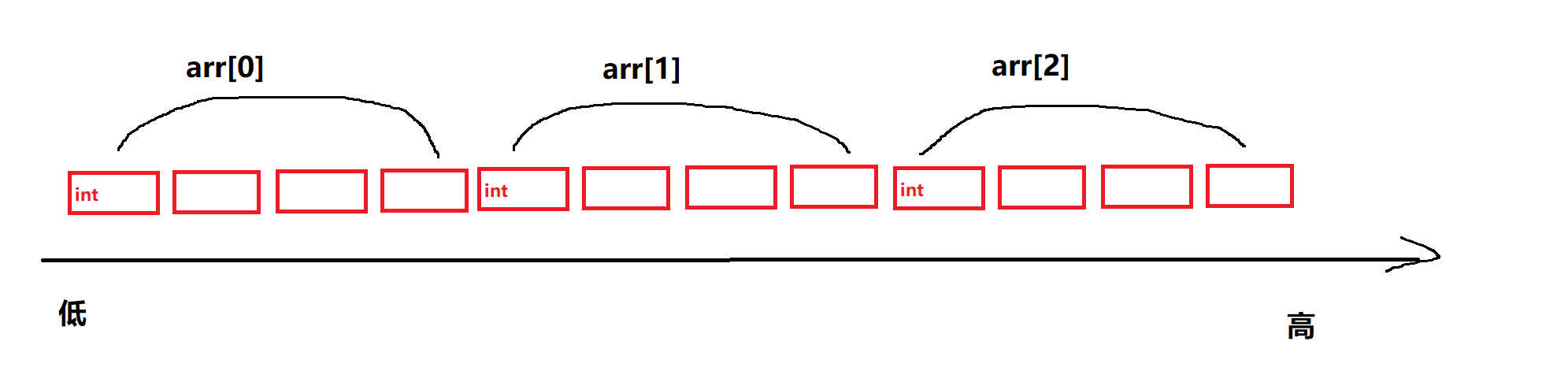
我们可以把二维数组理解为 一维数组 的数组
如图
三.数组越界
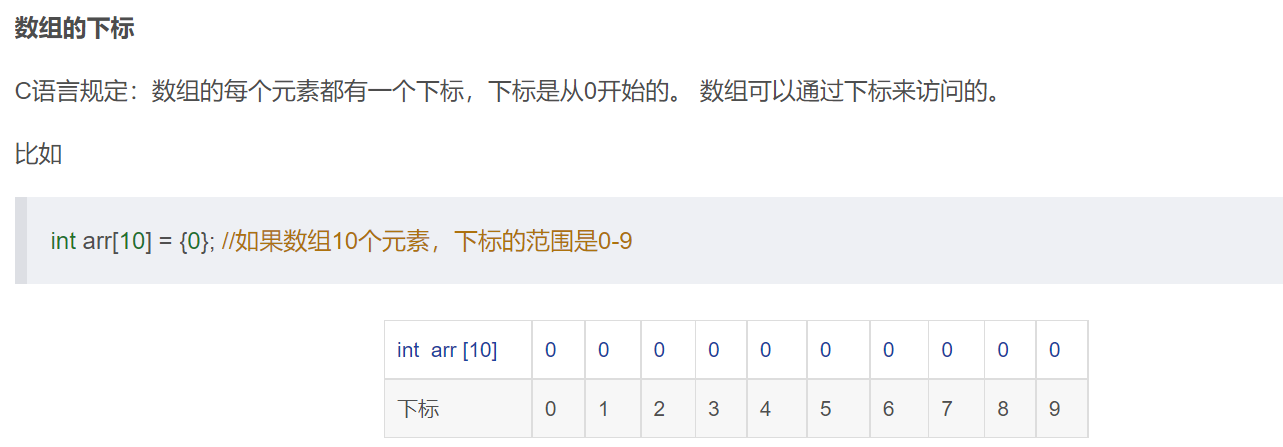
- 数组的下标是有范围限制的。
- 数组的下规定是从0开始的,如果输入有n个元素,最后一个元素的下标就是n-1。
- 所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
- C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的,所以程序员写代码时,最好自己做越界的检查。
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
//下标应是0~9
int i = 0;
for (i = 0;i <= 10;i++)
{
printf("%d ", arr[i]);
}
return 0;
} 我们来看一下这段代码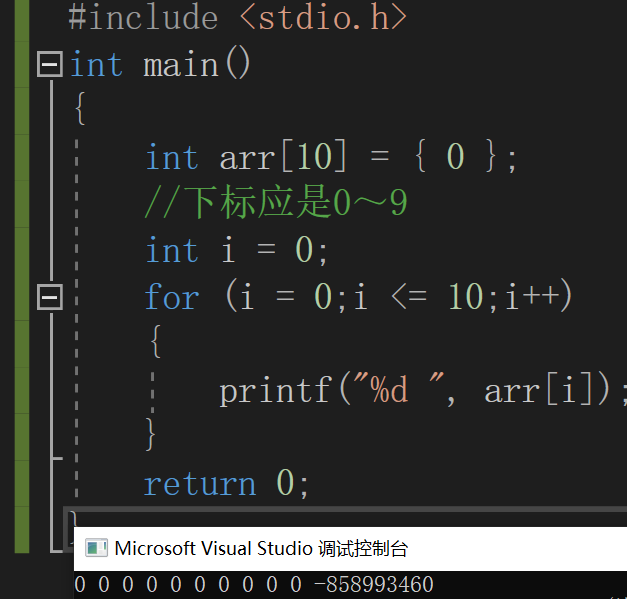
这就是典型的越界访问了,数组arr的下标的范围是0~9,但是我这里写的是i<=10,
当i=10时就越界了
但是系统并没有报错,并且运行成功了,但是这并不意味着程序正确,实际上是错误的
下面我们用一张图来帮助我们了解数组越界
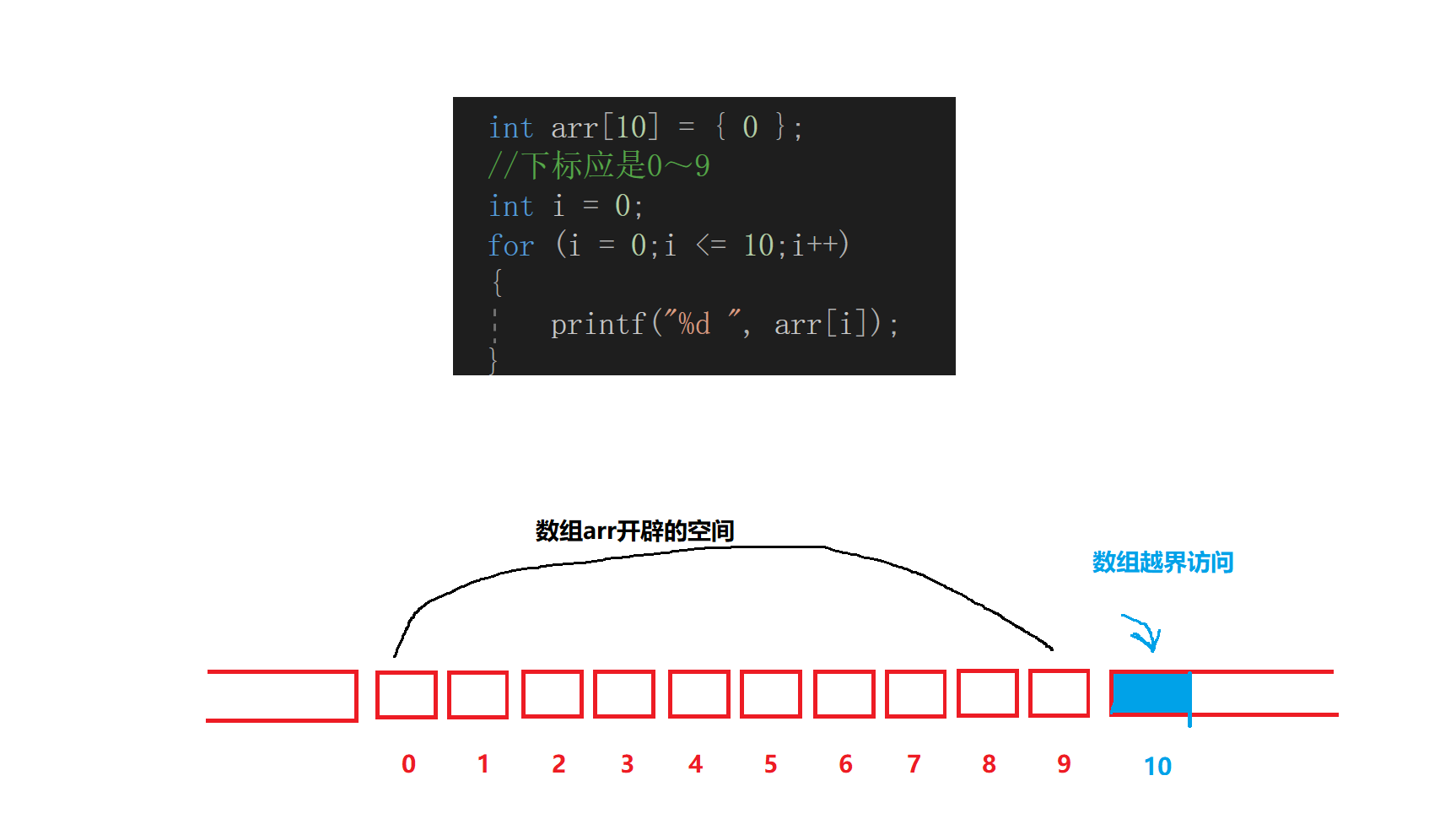
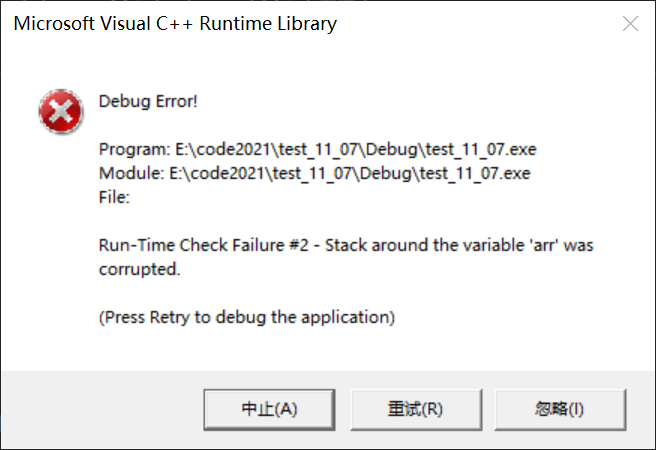
在我们编写代码的过程中
以后只要看到这样类似的提示,
那么大概率就是数组越界了
四. 数组作为函数参数
1.冒泡排序的示例
往往我们在写代码的时候,会将数组作为参数传个函数,
比如:我要实现一个冒泡排序:函数将一个整形数组排序。 那我们将会这样使用该函数:
(关于冒泡排序的详细解析,我会在另一篇文章中解析)
我们先来看一下冒泡排序的代码
int main()
{
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
int i = 0;
for (i = 0;i < 9;i++)
{
int j = 0;
for (j = 0;j < 9 - i;j++)
{
int tmp = 0;
if(arr[j]>arr[j+1])
{
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
for (i = 0;i < 10;i++)
{
printf("%d ", arr[i]);
}
return 0;
}但是这里我们为了说明数组作为函数参数时的一些特点,我们采用函数的形式,完成冒泡排序
void bubble_sort(int arr[])
{
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0;i < sz - 1;i++)
{
int j = 0;
for (j = 0;j < sz - 1 - i;j++)
{
int tmp = 0;
if (arr[j] > arr[j + 1])
{
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
bubble_sort(arr);
int i = 0;
for (i = 0;i < 10;i++)
{
printf("%d ", arr[i]);
}
return 0;
} 我们按照我们的思路完成了上面的代码,那么它能做到给这十个数按升序排序吗?
我们发现,并没有排序,这是为什么呢?
出现问题我们不要急,我们要试着去对代码进行调试,找出错误在哪里
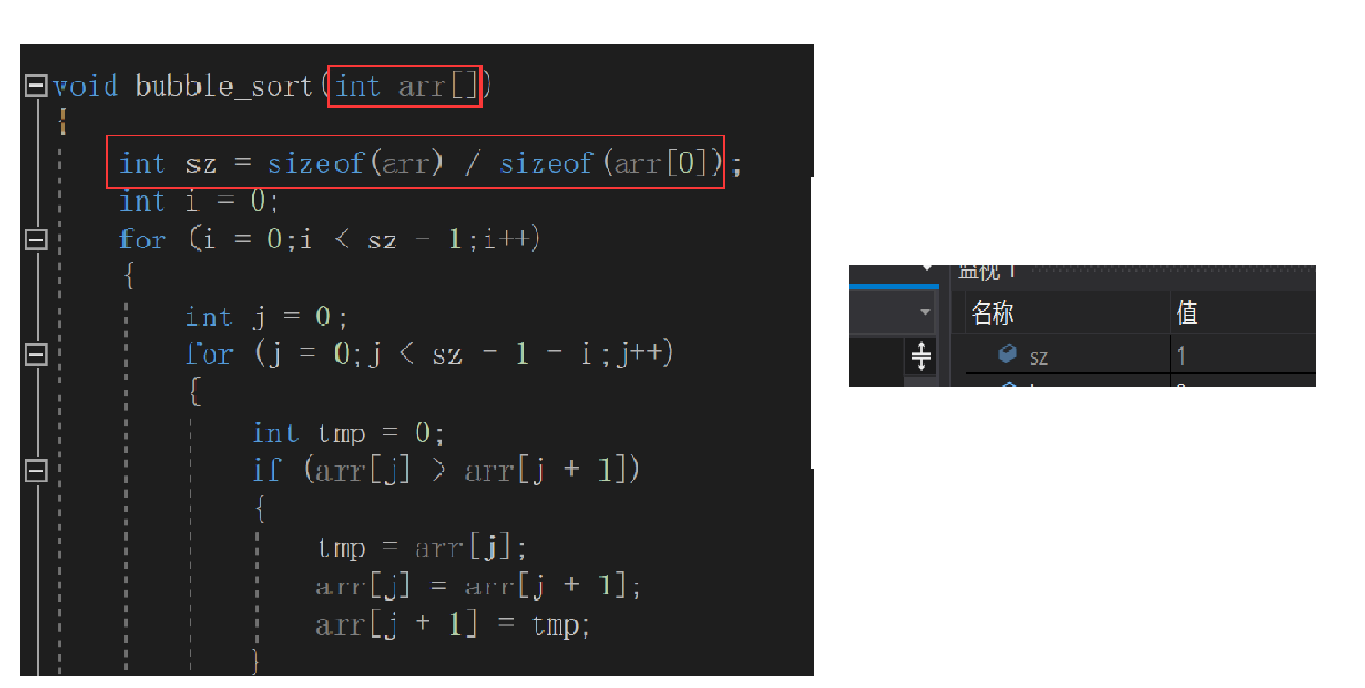
我们发现,这里貌似是sz出问题了,在我们的设想中:
sz应该是等于sizeof(arr) / sizeof(arr[0])= 40/ 4=10的,而这里等于1,这是为什么呢?
我们再进一步调试
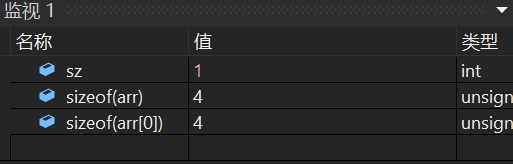
我们终于找到了问题的源头:sizeof(arr)
我们知道一个整型所占空间是4个字节,而10个整型就是4*10=40个字节,所以这里的sizeof(arr)应该是10啊,为什么会是1呢,接下来我们对这个问题展开思考:
一个整型所占空间是4个字节,10个整型就是4*10=40个字节,这里的sizeof(arr)变成了1字节,是不是因为它从10个元素变成了1个元素呢?
其实这个问题我们在用函数实现二分查找算法的时候也遇到过
经过学习,我们得知:实际上数组传参,传递的不是整个数组,是数组首元素的地址
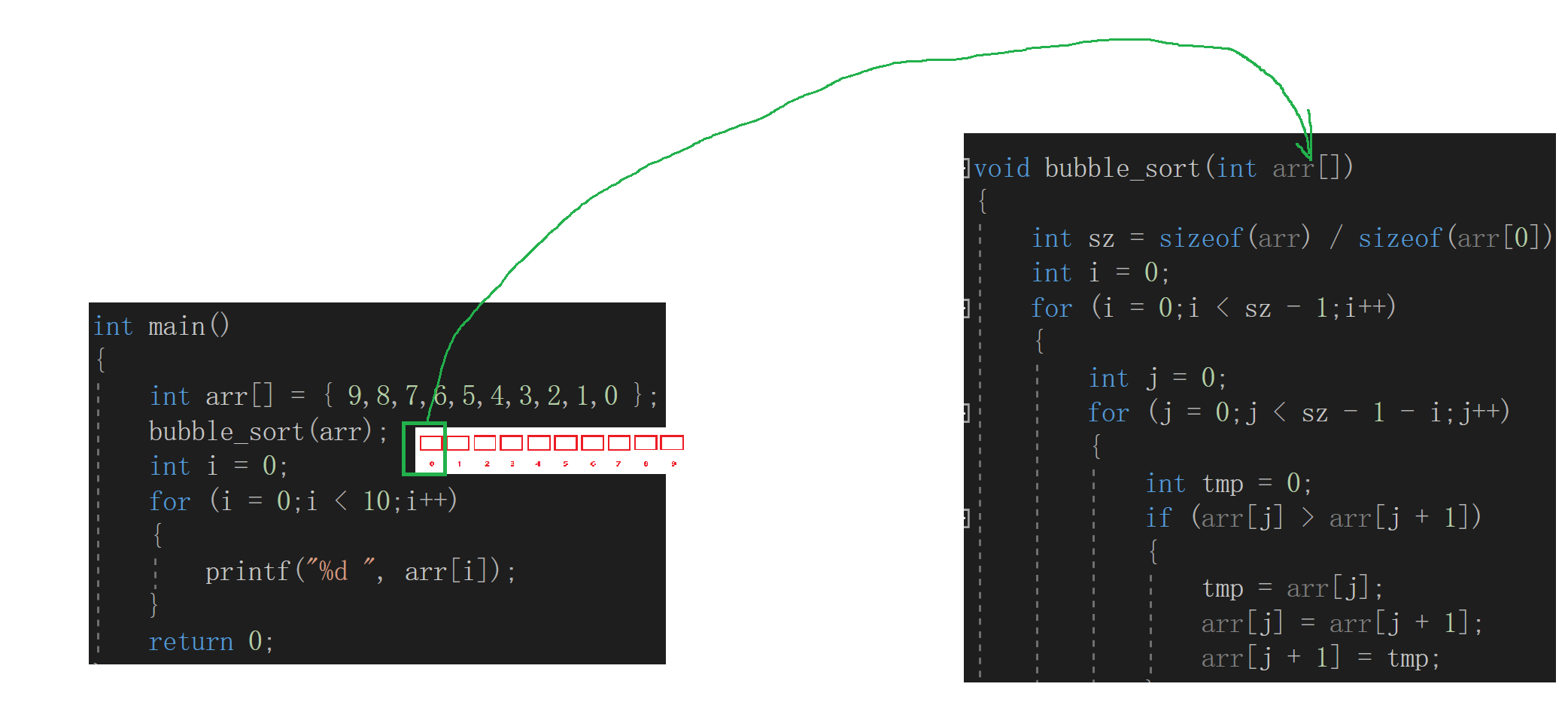
所以这里的 sizeof(arr)算的是指针的大小
而这里的指针大小是4个字节,这样就说得通了
现在我们再来看一下函数的形参我们当初的表示方法

C语言中,为了让一些基础较薄弱的用户理解代码更加方便,所以这里写成int arr[]
是完全没有问题的,是正确的,但是这里的形参本质上应该是一个指针,所以本质上是这样:

但这里我们为了方便理解,还是写成 int arr[]
学到这里,我们可以得到这样一个结论:
实际上作为函数的参数,传递参数,传递的不是整个数组,是数组首元素的地址
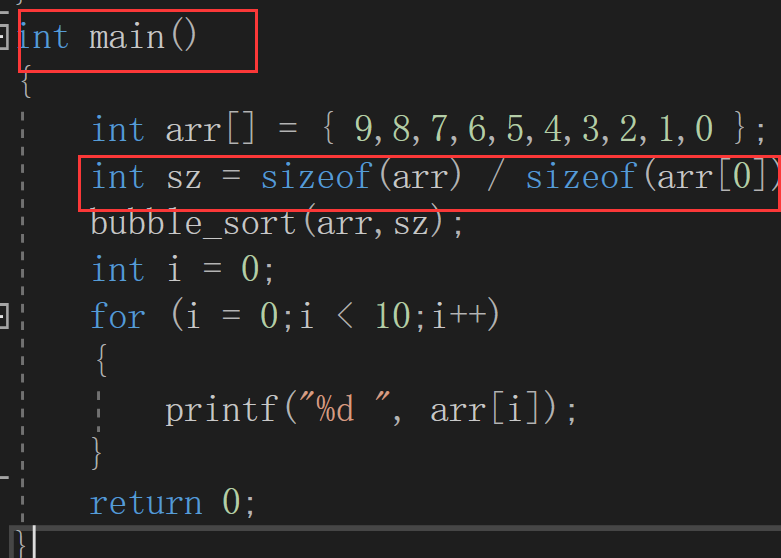
所以如果我们想实现排序的功能应该对代码做一下修改,将sz的计算放在main函数中
void bubble_sort(int *arr, int sz)
{
int i = 0;
for (i = 0;i < sz - 1;i++)
{
int j = 0;
for (j = 0;j < sz - 1 - i;j++)
{
int tmp = 0;
if (arr[j] > arr[j + 1])
{
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
int i = 0;
for (i = 0;i < 10;i++)
{
printf("%d ", arr[i]);
}
return 0;
} 
2.数组名是什么
数组名,就是首元素地址
我们来比较一下
int main()
{
int arr[] = { 1,2,3,4,5 };
printf("%pn", arr);
printf("%pn", &arr[0]);
return 0;
}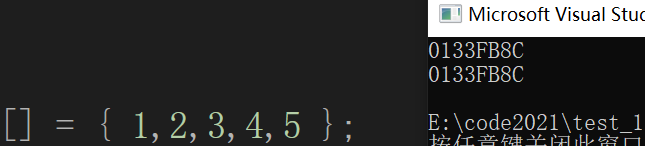
打印的结果相同,由于&arr[0] 是数组第一个元素的地址,而printf("%pn", arr)的打印结果跟它一样,我们得出结论:数组名,就是首元素地址
但是,有两种例外的情况
- sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数组。 sizeof(数组名) 计算的是整个数组的大小,单位是字节
- &数组名,这里的数组名表示的是整个数组,取出的是整个数组的地址
printf("%pn", &arr);而这里打印的结果也一样,因为:虽然&arr表示的是整个数组的地址,
但是整个数组的地址就是首元素的地址
我们再来看一下这些地址+1后的结果
int main()
{
int arr[] = { 1,2,3,4,5 };
printf("%pn", arr+1);
printf("%pn", &arr[0]+1);
printf("%pn", &arr+1);
return 0;
} 
是因为
五.数组的应用实例
1.三子棋
2.扫雷
这两个应用我将单独写文章记录
最后
以上就是魁梧眼睛最近收集整理的关于数组一.一维数组二.二维数组三.数组越界 四. 数组作为函数参数五.数组的应用实例的全部内容,更多相关数组一.一维数组二.二维数组三.数组越界 四.内容请搜索靠谱客的其他文章。








发表评论 取消回复