Example-based算法
简介
基于样例(Example-based)的超分辨率重建方法作为首个基于学习的单图像超分辨算法,由Freeman首次提出。通过运用机器学习相关算法训练数据集,学习得到LR和HR之间的关系,搜索得到与LR最佳匹配的HR,从而达到超分辨重建的目的。
训练集
HR图像——degrade(退化处理)——>LR图像——cubic spline/bilinear interpolation(三次样条/双线性插值)——>HR’图像
HR、HR’预处理(带通滤波和对比归一化图像对)——>以image patch形式存储图像信息
算法
作者发现单独考虑局部图像块信息是不充分的,需要考虑空间邻里效应。提出两种方法,第二种方法是在第一种方法的基础上加以改进的。
Markov network
简单理解就是选择使得以下概率最大的
x
x
x。
P
(
x
∣
y
)
=
1
Z
∏
(
i
j
)
ψ
i
j
(
x
i
,
x
j
)
ϕ
i
(
x
i
,
y
i
)
P(x|y)=frac{1}{Z}prod_{(ij)}psi_{ij}(x_i,x_j)phi_i(x_i,y_i)
P(x∣y)=Z1(ij)∏ψij(xi,xj)ϕi(xi,yi)
为保证重叠区域兼容的相邻面片的像素值应一致,相邻候选块
x
i
x_i
xi,
x
j
x_j
xj 之间的势能量函数
ψ
i
j
(
x
i
,
x
j
)
psi_{ij}(x_i,x_j)
ψij(xi,xj) 如下定义。其中,
d
i
j
(
x
i
,
x
j
)
d_{ij}(x_i,x_j)
dij(xi,xj) 表示在节点
i
i
i 和
j
j
j 的重叠区域中,候选图像块
x
i
x_i
xi,
x
j
x_j
xj 之间的平方差之和。低分辨图像块
y
i
y_i
yi 和候选图像块
x
i
x_i
xi 对应的低分辨率图像之间的似然函数为
ϕ
i
(
x
i
,
y
i
)
phi_i(x_i,y_i)
ϕi(xi,yi) ,用二次惩罚项定义二者差别。
ψ
i
j
(
x
i
,
x
j
)
=
e
x
p
(
−
d
i
j
(
x
i
,
x
j
)
2
σ
2
)
psi_{ij}(x_i,x_j)=exp(-frac{d_{ij}(x_i,x_j)}{2sigma^2})
ψij(xi,xj)=exp(−2σ2dij(xi,xj))
为使得该方法计算可行,采用置信传播(BP, Belief Propagation)从候选样本图像块中挑选出最佳图像块。详细步骤参见另一篇博客,消息传播信息公式为:
m
i
j
(
x
j
)
=
∑
x
i
ψ
i
j
(
x
i
,
x
j
)
∏
k
≠
i
m
k
i
(
x
i
)
ϕ
i
(
x
i
,
y
i
)
m_{ij}(x_j)=sum_{x_i}psi_{ij}(x_i,x_j)prod_{kneq i}m_{ki}(x_i)phi_i(x_i,y_i)
mij(xj)=xi∑ψij(xi,xj)k=i∏mki(xi)ϕi(xi,yi)
x
i
x_i
xi的边际概率为:
b
i
(
x
i
)
=
∏
k
m
k
i
(
x
i
)
ϕ
i
(
x
i
,
y
i
)
b_i(x_i)=prod_k m_{ki}(x_i)phi_i(x_i,y_i)
bi(xi)=k∏mki(xi)ϕi(xi,yi)
在该问题中,传入的消息尺寸为16维(选择相近的16个高分辨图像块),即对每个高分辨候选图像块,可能都需要计算一次。因此,在此基础上提出一种更快捷的方法。
One-pass algorithm
仅针对已选择的相邻高分辨率图像块计算其势能函数,通过低频信息相一致来找出最相近的高分辨图像块,之后确保相匹配的高分辨率图像的高频信息与相邻图像块边缘的一致性。具体流程如下:
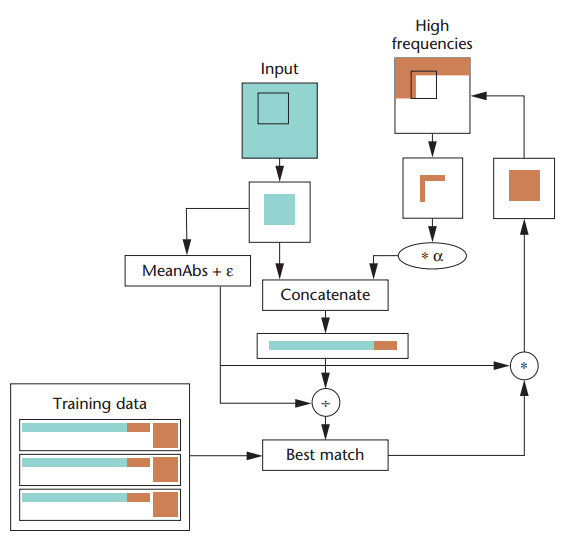
该方法的思想与Markov network是相类似的,只是该方法不需要对所有待选高分辨图像块都计算其势能函数,降低了计算的时间负杂度,预测结果和Markov network的结果也相近似。
以上属个人理解,有不正确之处敬请指正!
最后
以上就是友好画板最近收集整理的关于Example-based算法的全部内容,更多相关Example-based算法内容请搜索靠谱客的其他文章。








发表评论 取消回复