Learning What and Where to Transfer句句解读
- 先看meta learning
- 摘要
- 介绍
- 第三段
- 第四段贡献
- 2.L2WWT
- 2.1 Weighted Feature Matching
- What
- Where
- 2.2 Training Meta-Networks and Target Model
- 3. Experiments
- 3.1. Setups
- 3.1 Setups
- 32*32
- 224*224
- Meta-network architecture.
- Compared schemes for transfer learning.
- 3.2 Evaluation on Various Target Tasks
- 3.3 target数量很少时 更effective了
- 3.4 多源域
- 4. Conclusion
贼懒de博主终于更新了,虽然也没有人看。
笔者的阅读笔记,排版别在意。
今天看一个2019ICML
Learning What and Where to Transfer
• 论文下载>> https://arxiv.org/abs/1905.05901
• 代码地址>> https://github.com/alinlab/L2T-ww
《小王爱迁移》系列之二十二:异构网络的迁移:Learn What-Where to Transfer - 知乎
https://zhuanlan.zhihu.com/p/66130006
四作的主页
http://alinlab.kaist.ac.kr/publications_full.html
先看meta learning
https://blog.csdn.net/a312863063/article/details/91127505
李宏毅机器学习2019(国语)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
https://www.bilibili.com/video/av46561029/?p=32
Meta Learning 入门:MAML 和 Reptile - 云+社区 - 腾讯云
https://cloud.tencent.com/developer/article/1463397
简单讲,what是指迁移什么,由softmax给出weight。而where是指source和target之间对应的pair,从第几层到第几层效果好,weight由meta network给出。连着乘两个系数在s和t之间的L2 objective(其中t要变换一下),之后得到的loss wfm和传统loss相加为final loss。
训练网络的方法也有创新。随缘自己看吧,我真的太懒了多一个字都不想打。
简写啊 s,t都懂的 ,tl: transfer learning
摘要
1. Dl tl
2. 现有方法
3. we提出ww
4. st,(a)pairs(b)how much
5. Validate
介绍
1. Dnn 需要large datasets, but
2. 引出tl(2010YQ)
3. tl的pre-train with fine-tuning
4. Fine-tune缺点不是panacea
5. s,t 是sementically distant,引用
第三段
1. Motivation
2. S 无关 甚至有害
3. 具体例子lower
4. 递进furthermore,直接关联s和t是不直接的
5. Yet, since没有ww的机制,现有的方法需要manual configuration
第四段贡献
1. We propose
2. Our goal is learning to learn,没有手工tuning
3. 具体Specifically, meta 生成weights(fea, pair of st)
• Which fea map and which st layers
• One-step by min the transfer objective only(inner obj) accelerate inner-loop
• Improvements eg
特别地,when t insufficient samples and when transfer from 多models
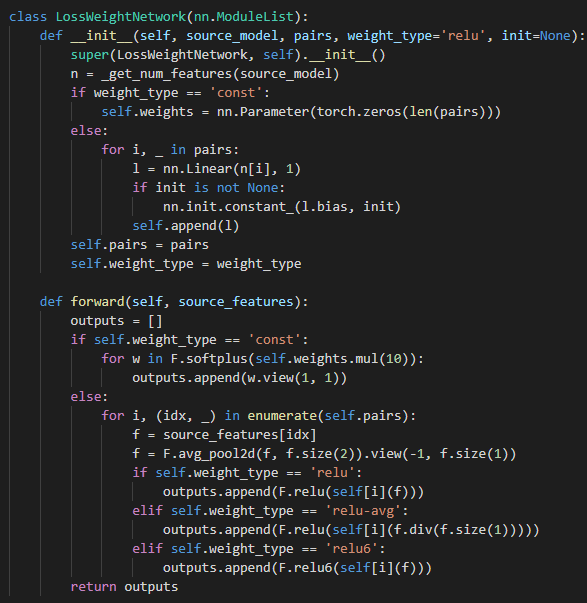
2.L2WWT
1. Our goal, without Manual layer association or feature selection
2. To this end, meta ww(what useful in s transfer to where in t)
3. 我们主要focus on tl 在cnn 之间,generic
2.1 Weighted Feature Matching
1. Cnn well-trained, intermediate feature useful
2. Thus, mimicking fea helpful for another network
3. 介绍符号含义
4. Our goal Tθ非线性 intermediate fea
5. Min L2 obj
6. rθ 线性pointwise convolution as 'fea matching' only in train
在代码里是这样实现的
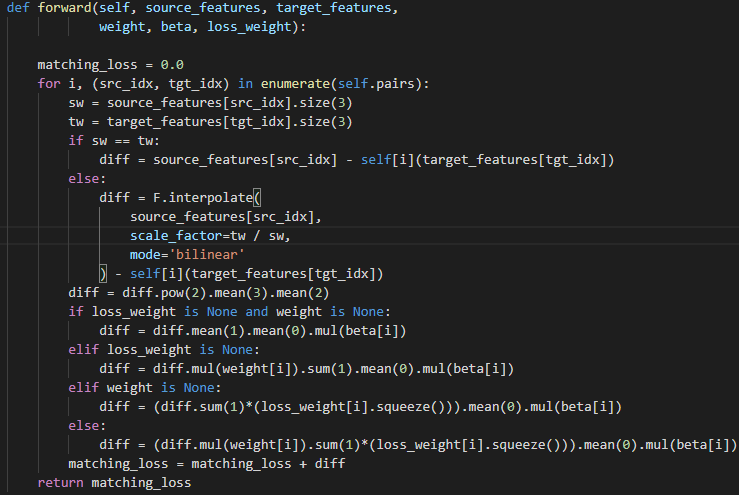
What
1. Attention, weighted fea loss utility on t
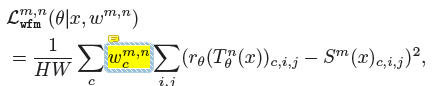
i. 因为每一张图片不一样,so w 是一个function
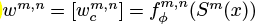
怎么算的
只和s有关,sum=1
softmax output of a small meta-network ϕ(s is input)
Where
To decide amount for optimal layer
怎么算的
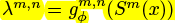
an output of a meta-network, 自动地决定important pairs
就是在L2前面接连乘了两次系数
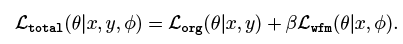
而total loss
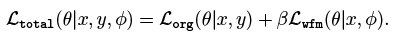
两个系数之间没有联系,都是只和s有关
2.2 Training Meta-Networks and Target Model
1. Our goal LOSS Total for high performance
2. LOSS wfm 鼓励 useful fea的learning
3. To 增加 useful fea by meta
bilevel两步(MAML2017, BILEVEL ICML2018)
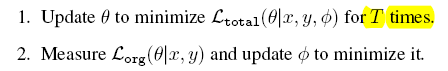
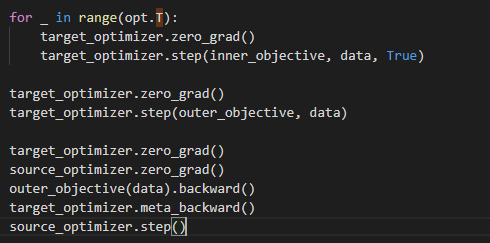
1. Loss org是meta obj
2. Loss wfm 中,meta影响t太weakly,最终在loss org的作用很局限marginal,除非T很大
3. 解决,增加了loss wfm的影响of t model in the inner-loop
4. 很快训练ϕ,和2−stage 相比
5. Alternatively 训练θ或者ϕ
3. Experiments
3.1. Setups
32 224两种尺度
3.2. Evaluation on Various Target Tasks实验
3.3. Experiments on Limited-Data Regimes
3.4. Experiments on Multi-Source Transfer
3.5. Visualization
3.1 Setups
32*32
S TinyImageNet
T CIFAR-10 CIFAR-100 STL-10 三个
S 32layer RESNET
T 9 layer VGG
224*224
S ImageNet
T Caltech-UCSD Bird 200, MIT Indoor Scene Recognition,Stanford 40 Actions,Stanford Dogs四个
S 34 layer ResNet
T 18 layer ResNet
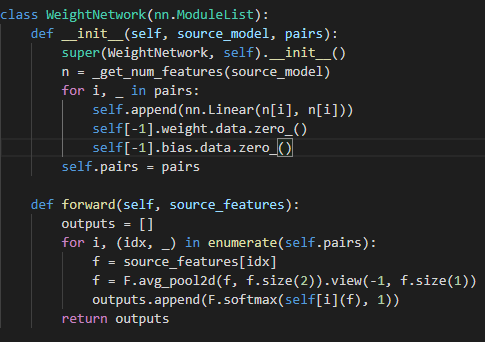
Meta-network architecture.
1 layer fc for each pair(m,n)
input: S的m^"th" 全局平均池化fea
output:
transfer amount λ_c 〖^(m,n)〗 , ReLU6, 保证非负,不会太大
channel assignments w_c 〖^(m,n)〗,sum=1,softmax
Compared schemes for transfer learning.
LwF
AT and FM on fea level (down-sample之前选择layers)
(a) Single: last fea in S , same spatial in t
(b) One to one: down scaling之前 in s,
© all to all: down scaling之前 in s and t, 双线性插值,
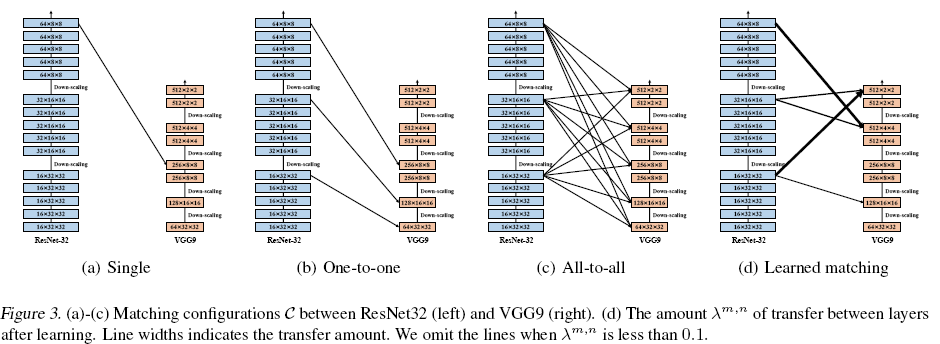
3.2 Evaluation on Various Target Tasks
What only(hand-crafted matching pairs of layers)
Single
One to one
结果和 FM (unweighted) 比较
是weighted的方法
发现 s general 而 t 是 fine-grained时,更effective
Where(all matching pairs)
(1,5) (3,,4)
Fig4
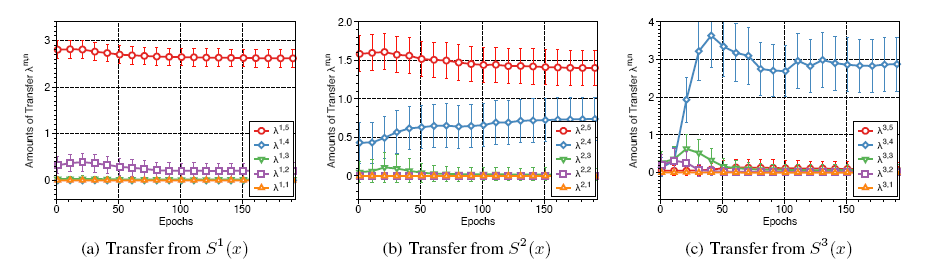 从s的第一层往t迁移的时候,s1相比s3 smaller variance
从s的第一层往t迁移的时候,s1相比s3 smaller variance
因为在s3的时候,high level fea 更task specific(lower task-agnostic.)
证明了 meta net adjust了transfer的amount
(既考虑到了task之间的关系,又fea abstractions的level )
3.3 target数量很少时 更effective了
fig5

CIFAR-10 每一类f50; 100; 250; 500; 1000g样本
3.4 多源域
表2
balancing the transfer
同时使用多个源域 也要求更多的手工特征
S:两个结构: ResNet20, ResNet32
两个数据库: Tiny-ImageNet, CIFAR-10
T:STL-10 with 9-layer VGG
4. Conclusion
a. We propose a t methodbased on meta which selectively
b. Ww
c. Design an efficient meta scheme: a few step in inner-loop
d. Jointly train target and meta
e. Shed a new angle for tl in 多结构和tasks
最后
以上就是细腻乌冬面最近收集整理的关于Learning What and Where to Transfer 2019ICML句句解读的全部内容,更多相关Learning内容请搜索靠谱客的其他文章。








发表评论 取消回复