爬淘宝的商品信息
现在想去爬淘宝上某商品的累计评论数和交易量,如下图所示
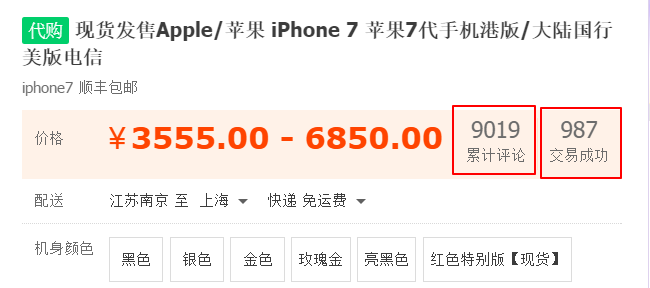
轮子选python的Scrapy,据说很厉害,第一次用,不太懂。
环境的配置
- 首先安装最新版的Ananconda,我这里安装完后显示python版本为3.61
- 安装scrapy, 直接使用命令
conda install scrapy即可安装scrapy,要注意了,需要电脑上安装好pywin32 - 然后下载chromedriver, 放在解压后,将exe文件放在路径
C:ProgramDataAnaconda3Scripts下
项目创建
首先是使用scrapy startproject TB创建一个工程项目,然后cd TB,进入TB目录下,使用命令scrapy genspider taobao taobao.com创建你的爬虫。至此,整个项目搭建完毕,接下来,就是进行代码编写了
代码编写
首先是修改settings.py中的内容,选择不遵守robots.txt协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False因为淘宝开启了robots.txt协议,而scrapy是默认遵守robots.txt协议的,所以,一开始是拒绝爬淘宝的
接下来,修改items.py文件如下所示
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TbItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
trade, comments = scrapy.Field(), scrapy.Field()
item_id = scrapy.Field()
此中内容,表是我们要爬取得到的东西,主要包括商品id,商品累计评价,商品交易量
接下来,编写蜘蛛了
打开spiders下的taobao.py文件修改如下
# -*- coding: utf-8 -*-
import scrapy
from TB.items import TbItem
from scrapy import Request, Selector
from selenium import webdriver
from urllib.parse import urlparse,parse_qs
class TaobaoSpider(scrapy.Spider):
name = "taobao"
allowed_domains = ["taobao.com"]
start_urls = ['https://item.taobao.com/item.htm?spm=a230r.1.14.75.4BT18i&id=538224140282&ns=1&abbucket=8',
'https://item.taobao.com/item.htm?spm=a230r.1.14.3.PPDEVC&id=547701746911&ns=1&abbucket=8']
def __init__(self, *args, **kwargs):
super(TaobaoSpider, self).__init__(*args, **kwargs)
self.driver = webdriver.Chrome()
def parse(self, response):
self.driver.get(response.url)
self.driver.implicitly_wait(30)
selector = Selector(text=self.driver.page_source)
for sel in selector.xpath('//*[@id="J_Counter"]'):
item = TbItem()
item['comments'] = sel.xpath('//*[@id="J_RateCounter"]/text()').extract_first()
item['trade'] = sel.xpath('//*[@id="J_SellCounter"]/text()').extract_first()
# item['item_name'] = sel.xpath('//*[@id="J_Title"]/h3/text()').extract_first()
item['item_id'] = parse_qs(urlparse(response.url).query, True)['id'][0]
yield item
def __del__(self):
if self.driver is not None:
self.driver.quit()函数parse里面主要的工作是利用selenium调用chrome,模拟人操作浏览器访问淘宝,这样能够解决淘宝的动态加载问题
转载于:https://www.cnblogs.com/crackpotisback/p/6733480.html
最后
以上就是勤恳机器猫最近收集整理的关于爬淘宝的商品信息 (上)爬淘宝的商品信息的全部内容,更多相关爬淘宝的商品信息内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复