前言
上周在线上出现出现报警,ID号码一直无法获取,但是只有这一台机器报警,所以第一时间先在服务治理平台上禁用掉这台机器保证服务正常。停掉机器后要排查问题,思考分析步骤如下:
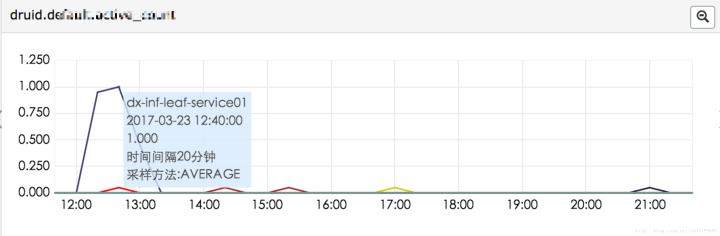
- 通过监控发现只有一个key的ID调用发生下降(第一张),这台机器上的其他key没有任何问题,从数据库更新号段正常。是不是数据库死锁了?
- 这个key在其他机器更新key是正常的,排除数据库的问题,那么就是这台机器的问题
- 查看log,发现这台机器确实没有更新数据库,两个号段的buffer都是空的。为什么更新数据库失败呢?难道是大量的超时?
- 仔细检查log日志,发现并没有超时的error。首先没有超时,但是号段是null的,是不是线程的问题?难道是代码逻辑有问题?
- 理了一遍逻辑发现代码逻辑没有问题,那是线程卡住了?
- 马上抓几次jstack log。果然发现有一条更新线程一直处于runable状态(第二张),其他线程池里面的线程都是waiting状态(禁用了服务,没有请求不会更新).
- 确定是线程一直卡住了,先重启这台机器,保证dx机房有两台机器工作。
- jstack的栈如下
"Thread-Segment-Update-4" daemon prio=10 tid=0x00007f2c6000c000 nid=0x2455 runnable [0x00007f2c55deb000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:170) at java.net.SocketInputStream.read(SocketInputStream.java:141) at com.mysql.jdbc.util.ReadAheadInputStream.fill(ReadAheadInputStream.java:100) at com.mysql.jdbc.util.ReadAheadInputStream.readFromUnderlyingStreamIfNecessary(ReadAheadInputStream.java:143) at com.mysql.jdbc.util.ReadAheadInputStream.read(ReadAheadInputStream.java:173) - locked com.mysql.jdbc.util.ReadAheadInputStream@33d807d4 at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:2911) at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3332) at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3322) at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3762) at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2435) at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2582) at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2531) - locked com.mysql.jdbc.JDBC4Connection@178ec6c at com.mysql.jdbc.ConnectionImpl.setAutoCommit(ConnectionImpl.java:4852) - locked com.mysql.jdbc.JDBC4Connection@178ec6c

不理解上面的排查步骤没关系,理解成一句话就是:一个数据库操作的线程一直处于runable状态但是一直hand住没有返回值
通过jstack的信息,可以发现是我们的一个事务在执行conn,setAutoCommit(true)时,一直在native方法read…长时间read。我们有设置超时时间,但是为什么这里会没有超时呢(发现时线程大概运行了有20min)???。咨询DBA同事定位问题之后,大概得出是因为我们没有设置socketTimeout。如果没有设置socketTimeout将会依赖OS底层的timeout,线上大概是30min。虽然通过DBA同事的经验解决了问题,但是仍然存在疑问,为什么mysql存在两种timeout机制呢?queryTimeout和socketTimeout?socketTimeout难道不应该是queryTimeout的子集?queryTimeout应该也能发现我们的Sql超时了啊?
这就和JDBC的实现机制有关系了,为什么会有两种Timeout机制的存在。用一种超时不能解决问题吗?
JDBC执行SQL的原理
这个名词也就是queryTimeout,他是属于应用层面的timeout机制。用来控制我们sql语句执行的时间的超时,但是mysql并没有用他来发现所有的问题。下面摘抄一段Statement执行SQL的代码片段
CancelTask timeoutTask = null;//实现statementTimeout的timer。每一个SQL执行都会创建一个
try {
//有超时设置会初始化这个timer
if (locallyScopedConnection.getEnableQueryTimeouts() && this.timeoutInMillis != 0 && locallyScopedConnection.versionMeetsMinimum(5, 0, 0)) {
timeoutTask = new CancelTask(this);
locallyScopedConnection.getCancelTimer().schedule(timeoutTask, this.timeoutInMillis);
}
if (!isBatch) {
statementBegins();
}
//执行SQL(sync)
rs = locallyScopedConnection.execSQL(this, null, maxRowsToRetrieve, sendPacket, this.resultSetType, this.resultSetConcurrency,
createStreamingResultSet, this.currentCatalog, metadataFromCache, isBatch);
if (timeoutTask != null) {
timeoutTask.cancel();
locallyScopedConnection.getCancelTimer().purge();
if (timeoutTask.caughtWhileCancelling != null) {
throw timeoutTask.caughtWhileCancelling;
}
timeoutTask = null;
}
synchronized (this.cancelTimeoutMutex) {
if (this.wasCancelled) {
SQLException cause = null;
//如果是被timer kill,则抛出异常
if (this.wasCancelledByTimeout) {
cause = new MySQLTimeoutException();
} else {
cause = new MySQLStatementCancelledException();
}
resetCancelledState();
//抛出
throw cause;
}
}
Timer中的代码大致的意思就是copy一个和现在相同的connection,然后执行一条cancelStmt.execute(“KILL QUERY “ + CancelTask.this.connectionId); 语句给数据库,让数据库立刻停止这个链接的SQL
那么整个SQL执行的过程可以简单的描述如下:
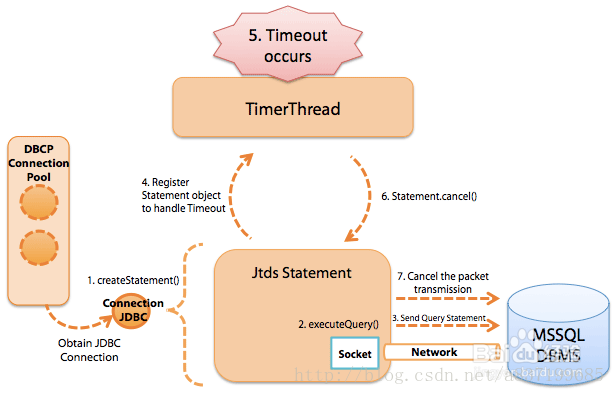
- 执行SQL之前给每一个执行SQL创建一个对应超时时间的Timer,到了时间之后会去kill这调语句
- kill成功之后,数据库会立即返回一个result,也就是上面代码执行SQL语句的返回值
- 正常执行语句,抛出超时异常
这里值得注意的地方,为什么不直接用StatementTimeout直接发现超时,然后返回,不用管rs的结果到底是什么。为了防止超长时间的SQL在server端执行,JDBC在发现自己的statement超时之后,会发一个kill指令给server,那么这个server指令有超时时间吗?有timer吗?在最开始我们代码hang住的setAutoCommit()指令有timer吗?
没有!!!!
下面是通过jprofiler分别执行statement和执行setautoCommit两个指令的内存状态图,可以发现,后者是没有timer对象的(第二张),而前者有(第一张)!!!因为后者的代码根本就没有创建timer逻辑的部分。可以在源码里面看到后者会直接就调用底层的connectionImpl的execSQL方法执行SQL


但是kill是通过copy链接来发送kill命令的。会有timer吗?下图是在发送kill指令时,用debug可以看到,kill 指令发送的时候statementTimeout是0,是不会创建TImer的 ,第一张图是在执行Statement SQL的,超时时间是我们设置的2s,第二张图是执行kill指令时的,可以发现超时时间是0,不会创建timer。仔细想想也能明白,如果kill指令也有timer,逻辑和statement sql一样,那岂不是会无限循环!!


证明
第一种
socketTimeout设置得比StatementTimeOut小为1s,后者为5s执行如下语句:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="jdbc:mysql://127.0.0.2:3306/my?socketTimeout=1000"/>
<property name="username" value="root" />
<property name="password" value="123456" />
<property name="queryTimeout" value="5"/>
//省略
</bean>
//sql 10s之后返回数据
select sleep(10) ,name from user where id=1
会在1s之后得到如下结果,看起来很正常,在timer没有发起kill之前,因为socket没有得到数据所以socket超时了,这一点提醒我们,设置socket超时一定要比statement长,不然你设置得statement超时将毫无意义
The last packet successfully received from the server was 1,057 milliseconds ago. The last packet sent successfully to the server was 1,012 milliseconds ago.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45
第二种
把statement设置为2s,socketTime设置成6s。会在2s之后得到如下输出。如果socketTime设置成比statement大,那么在后者超时之后,会去kill掉SQL之后立马返回抛出异常
com.mysql.jdbc.exceptions.MySQLTimeoutException: Statement cancelled due to timeout or client request
at com.mysql.jdbc.StatementImpl.executeQuery(StatementImpl.java:1390)
at com.alibaba.druid.pool.DruidPooledStatement.executeQuery(DruidPooledStatement.java:140)
第三种
和第二种相同的情况,把statement的超时设置成5s,socket超时设置成15s。但是我会在发起kill之前把网络给断掉,来模拟出现网络问题,或者server直接down掉的情况。会在15s后得到一下结果
The last packet successfully received from the server was 15,003 milliseconds ago. The last packet sent successfully to the server was 15,004 milliseconds ago.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
为什么是15s后呢?为什么不是statement的超时的时间呢?这就和上面JDBC源码部分有关系了。从上面的代码可以看出,rs必须返回之后才会抛出异常,当rs不返回时不会继续往下走的。rs什么时候返回?关于kill query什么时候返回,在网上找的一些资料 https://dev.mysql.com/doc/refman/5.7/en/kill.html
kill命令详解
注:只针对innodb引擎
mysql KILL QUERY只abort线程当前提交执行的操作,其他的保持不变,并且db server报SQL 语法异常(You have an error in your SQL syntax)。
根据当前被kill的statement是否在事务中,分两种情况分析:
- (1) 不在事务中(未显式开启)
- innodb中statement具有原子性。因此kill掉后,会导致statement abort,回滚掉。
- (2) 在事务中
- 假设事务中sql执行顺序是sql1;sql2;sql3; 在执行sql2时被kill掉,则sql2会抛出异常,并且sql2执行失败。但是sql3依旧会执行下去。此时如果在spring层做了事务回滚处理,会对三条sql全部回滚掉。
- sql抛出的异常时MySQLSyntaxErrorException,我们会看到它是受检异常,但是我们了解spring默认是只对非受检异常做回滚处理的,怎么会这样呢?是框架对其做了转化,最终转为非受检异常,spring事物管理器就可以对其做回滚处理了。
mysql收到kill query后执行时机
KILL操作后,该线程上会设置一个特殊的 kill标记位。通常需要一段时间后才能真正关闭线程,因为kill标记位只在特定的情况下才检查。具体时机是
- 执行SELECT查询时,在ORDER BY或GROUP BY循环中,每次读完一些行记录块后会检查 kill标记位,如果发现存在,该语句会终止;
- 执行ALTER TABLE时,在从原始表中每读取一些行记录块后会检查 kill 标记位,如果发现存在,该语句会终止,删除临时表;
- 执行UPDATE和DELETE时,每读取一些行记录块并且更新或删除后会检查 kill 标记位,如果发现存在,该语句会终止,回滚事务,若是在非事务表上的操作,则已发生变更的数据不会回滚;
- GET_LOCK() 函数返回NULL;
- INSERT DELAY线程会迅速内存中的新增记录,然后终止;
- 如果当前线程持有表级锁,则会释放,并终止;
- 如果线程的写操作调用在等待释放磁盘空间,则会直接抛出“磁盘空间满”错误,然后终止;
- 当MyISAM表在执行REPAIR TABLE 或 OPTIMIZE TABLE 时被 KILL的话,会导致该表损坏不可用,指导再次修复完成。
所以,当kill query这条指令发送过去的时候,由于网络问题一直没响应,会等到socketTimeout之后,整个SQL语句的执行才会返回。所以socketTimeout也不宜设置得太长,在网络不好的时候超时时间基本上不会是statementTimeout的时长。这也就证明了jstack中的问题,那一时刻出现了网络问题,到时setAutoCommit这条指令被卡住,由于没有设置socket超时,得依赖os底层的socket超时时间30min,其实如果我们不重启服务,相信30min钟后服务会自愈。
最好大家自己执行一下上面三种情况,就能很快理解
总结
- StatementTimeout主要是为了限制我们执行SQL语句的时长,由于设计问题并不能包含所以超时情况
- 除了用户自己写的SQL,其他的SQL指令依赖的超时时间都是socket超时。例如执行事务时的setAutoCommit和statement执行SQL超时时执行的kill query指令
- 可不可以只设置socket超时?最好不要,如果这样的话会导致mysql server有大量长时间运行的SQL(没有被超时kill)
- socketTimout一定要设置得大于statementTimeout,不然设置后者将会没有任何意义
- 一个SQL就会有一个timer的产生,这一点以前是不知道的,以为都是依赖的底层超时
到此这篇关于JDBC超时机制的文章就介绍到这了,更多相关JDBC超时机制内容请搜索靠谱客以前的文章或继续浏览下面的相关文章希望大家以后多多支持靠谱客!
资料
- http://imysql.com/2014/08/13/mysql-faq-howto-shutdown-mysqld-fulgraceful.shtml
- http://www.importnew.com/2466.html
- https://dev.mysql.com/doc/refman/5.7/en/kill.html
最后
以上就是怕孤独篮球最近收集整理的关于一文深入解析JDBC超时机制的全部内容,更多相关一文深入解析JDBC超时机制内容请搜索靠谱客的其他文章。








发表评论 取消回复