S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization

该模型解决了什么问题?
同样是序列化建模,为什么S3-Rec说自己要比其他的效果好?该文指出,现有的序列化推荐模型使用target item来计算loss的,例如阿里是用历史交互序列,预测下一个点击/转化的商品。这样有什么问题?一个是数据过于稀疏,还有就是上下文信息没有充分被利用。因此S3-Rec引入了自监督学习去解决序列化建模所面临的问题。
这篇论文的自监督学习简单来说就是用序列pretrain,然后再用target item做fine-tuning。只是因为推荐场景的特殊性,这篇论文设计了4个自监督学习目标,充分利用序列,属性,自序列等信息,学到最好的embedding表达。
模型架构图
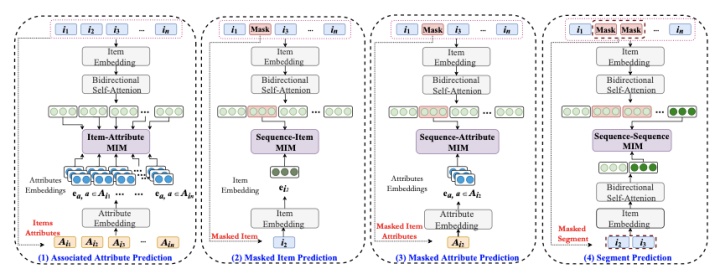
直接看这张图,估计多半是懵逼的。说实话,图画的虽然复杂,实际模型其实是相当简单的。上面4个虚线框,就是4个pretrain的任务。分别是以下4个目标:
- 相关属性学习
- masked item预测
- masked 属性预测
- item段预测
说到pretrain,大家会想到啥?没错,就是bert。这篇论文原封不动的把bert模型搬了过来,但是改变了预训练的方式。十方先简要带大家回顾一下bert的结构。
bert的每一层,可以简要概括为两个部分,MultiHead-Attention和FFN层。MultiHead,顾名思义,大家就理解为self-attention做了好几次,做了几次就有几个head,最后concat即可。FFN就是前馈神经网络,因为attention提取的是线性特征,需要FFN去挖掘非线性的表达。我们看下公式的表达:

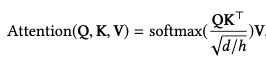
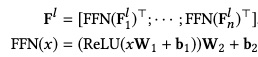
公式很简单,也不是本文重点,不赘述,实在不记得公式含义的,直接度娘bert即可,接下来我们着重介绍4个预训练任务。
挖掘item和属性的关系
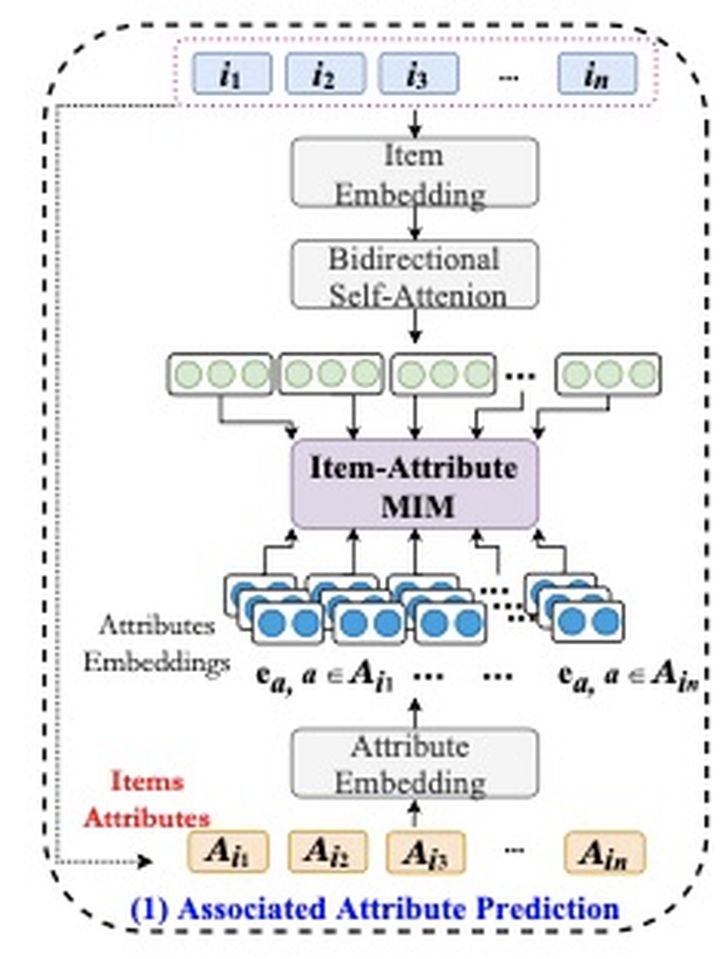
我们从上往中间看,i1~in就是item序列,item embedding就是查embeding词表,bidirectional Self-attention就是bert,总值一个item id序列,到了item-Attribute MIM后,就是一个经过attention变换过的embedding序列。然后我们在从下往上看,Ai1~Ain是i1~in的属性,模型要学的东西很简单,就是这个属性属不属于这个item,负样本随机负采样一些属性即可。loss函数如下:
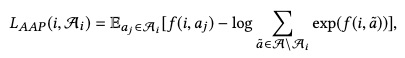
论文里f函数用的不是点积,而是下面这个公式:
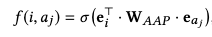
Masked 预测
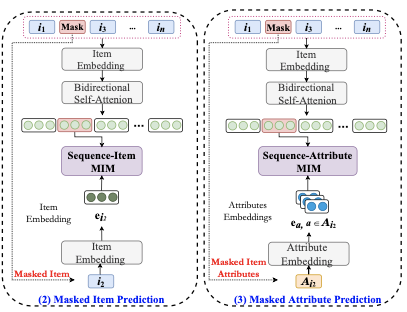
注意,这一节是两个目标,十方放一起讲,因为实在太类似了。看过bert的读者肯定深刻理解什么是masked,没看过bert的,大家就理解为完形填空。在输入侧,我随机挑选一个item,把它的id置为default,然后attention后,相应位置的向量,用来预估它原本的itemid以及属性。
预测itemid公式如下:
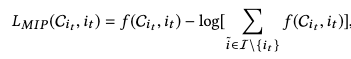
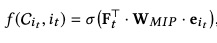
预测属性公式如下:
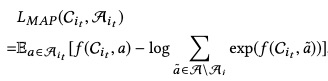
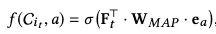
itemid和属性的负样本都是随机负采样。第一个任务充分挖掘了item和上下文的关系,第二个任务挖掘了属性和上下午的关系。
子序列关系挖掘
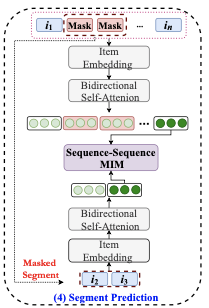
这个就特别有意思了,论文认为,只mask一个item,它的上下文并不能表达这个item。比如你买了个switch,完全是送人,但是你的上下文和游戏一点关联都没有,因此如果mask掉一个连续的子序列,那上线文多少都会和这个序列相关吧。基于这个思想,就有了segment-mask,把序列的一小段mask后,用attention后对应序列的embedding,去预估该子序列的概率,负样本也是随机采样些子序列,公式如下:
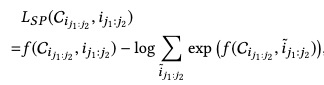
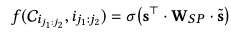
结语
最后,基于以上4个pretrain任务,我们做最后的finetuning。论文里用了pairwise rank loss:
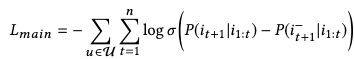
实验当然是bert秒杀所有。
最后
以上就是热情电话最近收集整理的关于事半功倍:推荐系统Pre-train预训练方法的全部内容,更多相关事半功倍内容请搜索靠谱客的其他文章。








发表评论 取消回复