机器学习、深度学习往往给人一种黑盒的感觉,也就是它所表现出来的可解释性程度不高或者是很低,这就给学习使用带来了影响,如果能够对于机器学习的结果进行更好的解释那将会是很棒的。
今天基于微软开源的可解释机器学习框架interpret进行简单的学习实践,主要是想上手我刚刚配置好的jupyter环境来跑一波代码,下面先给出来GitHub地址,在这里。
使用基本的要求是python版本需要在3.5以上,在这里我正好使用的是3.6和kernel来进行实验的。
interpret的安装很简单,命令如下:
pip install numpy scipy pyscaffold
pip install -U interpret安装方法虽然简单,但是安装的过程我个人觉得是比较漫长的,可能是我本地很多依赖的包版本比较低的缘故吧,在安装的过程中有10几个包都被卸载然后重新安装了新的版本了。
安装结束后我们就开始进行简单的实践【以波士顿房价数据为例】:
首先对数据集进行简单的探索可视化:

结果如下:
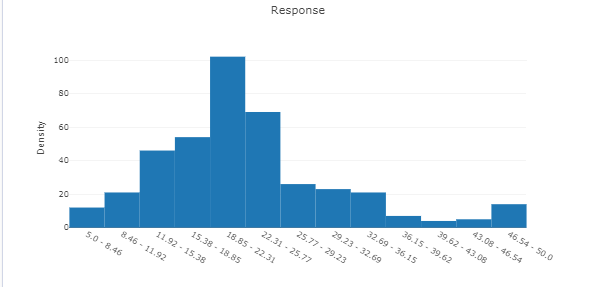
我们可以从summary的下拉框中选择不同的属性进行展示:
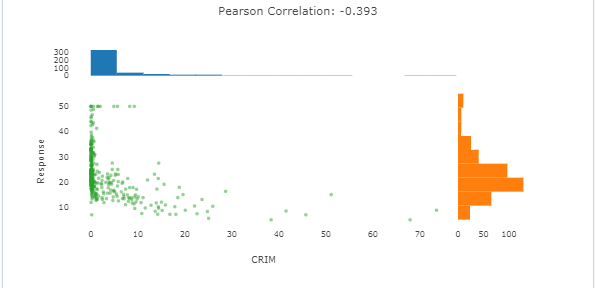
比如:这里我们选择第一个,结果如下:
接下来导入回归模型:

查看一下全局可解释性:
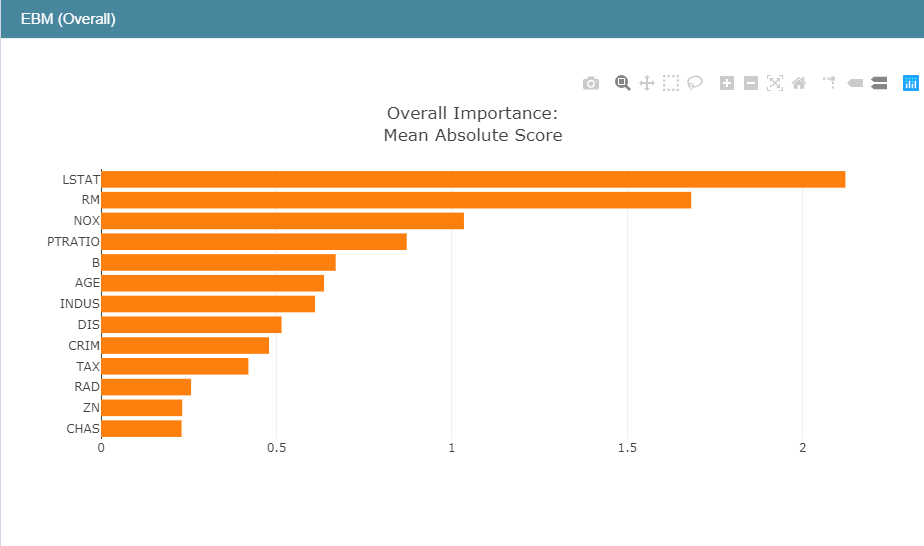
同样可以在下拉框中选择不同的信息进行查看,这里同样以第一个为例进行说明如下:
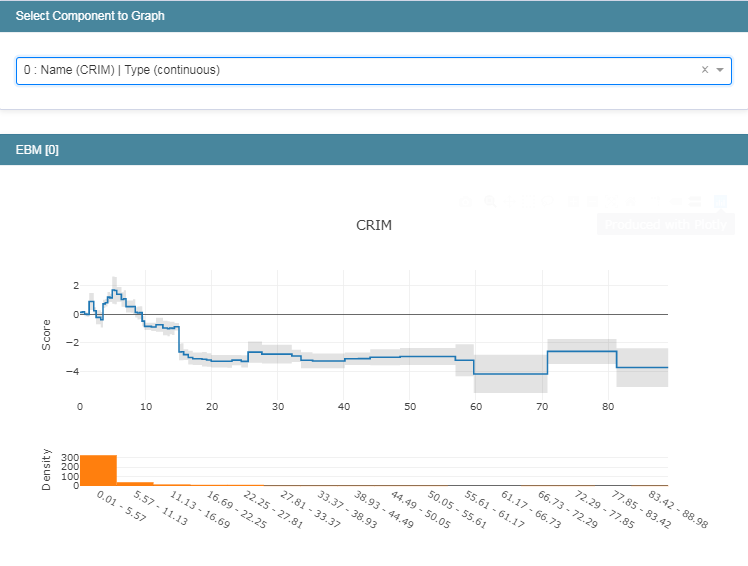
接下来查看一下局部的解释性:

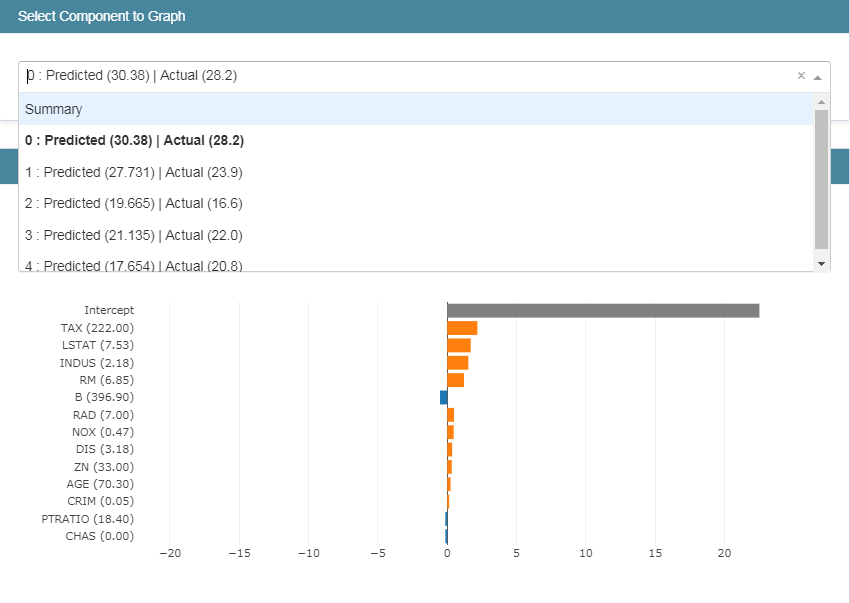
我个人觉得这里还是很重要的,能够很清晰地基于预测值和真实值的对比来分析不同特征属性的重要性程度。
这里执行代码后结果显示如下:
我们通过下拉框来选择不同的信息去展示,同样展示第一个:
接下来简单对比一些三种模型:

结果如下:
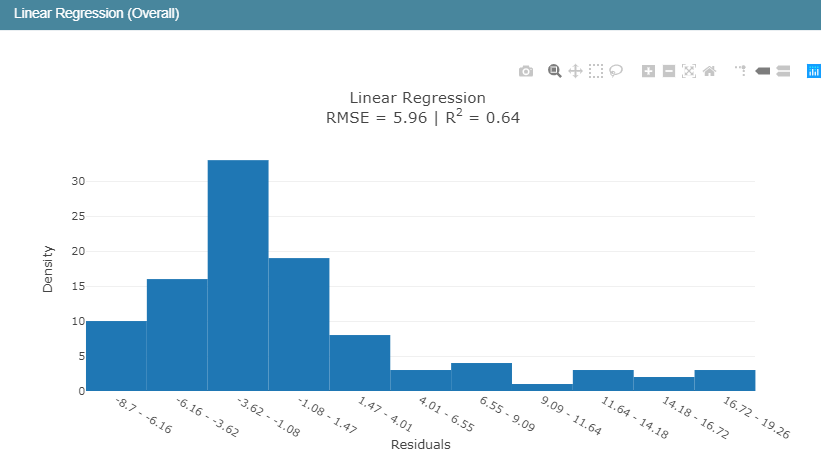
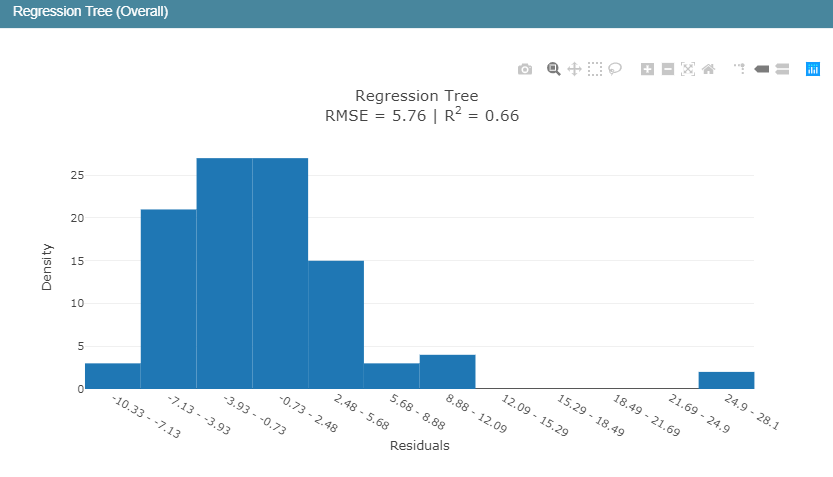
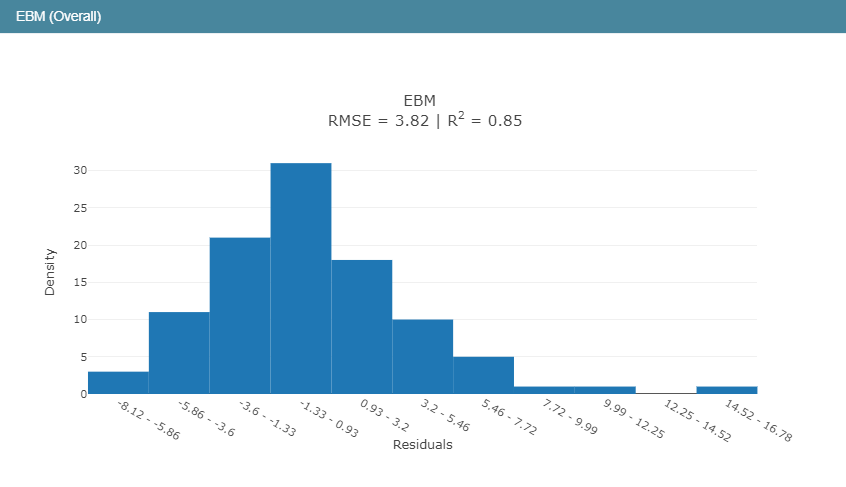
在回归模型中,我们知道R2表示的是判定系数,在我前面的博文里面对于回归模型的四大评价指标都有介绍,感兴趣可以去看看,相关的代码实现都有的,这里简单来说就是判定系数越高表明回归模型的拟合程度越好,模型的性能就越好。从判定系数来看:EBM模型的性能要优于线性回归模型和回归树模型。
简单的一次实践,第一次使用jupyter还是有很多的不适应的,希望后面会变顺畅吧!
上面简单选取了三个回归模型来进行了实验以及结果可视化展示与分析,相信对于interpret已经有了基本的了解了,接下来我们进行一个完整的实验,基于UCI提供的一个工资水平的分类数据集进行。我先贴出来完整的demo.ipynb的脚本内容,因为是刚开始使用这个web交互式编程环境,不像是之前直接写的.py脚本那样,具体实现如下:
{
"cells": [
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"scrolled": false
},
"outputs": [
{
"data": {
"text/html": [
"<!-- http://127.0.0.1:7525/328969744/ -->n",
"<iframe src="http://127.0.0.1:7525/328969744/" width=100% height=800 frameBorder="0"></iframe>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"#!usr/bin/env pythonn",
"#encoding:utf-8n",
"from __future__ import divisionn",
"n",
"'''n",
"__Author__:沂水寒城n",
"功能: 可解释机器学习库 interpret 实践使用n",
"'''n",
"n",
"n",
"import pandas as pdn",
"from sklearn.datasets import load_bostonn",
"from sklearn.model_selection import train_test_splitn",
"from sklearn.linear_model import LogisticRegressionn",
"from sklearn.tree import DecisionTreeClassifiern",
"from sklearn.neural_network import MLPClassifiern",
"from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifiern",
"from sklearn.decomposition import PCAn",
"from sklearn.pipeline import Pipelinen",
"from interpret import shown",
"from interpret.perf import ROCn",
"from interpret.data import Marginaln",
"n",
"n",
"n",
"def dataSplit(dataset,label,ratio=0.3):n",
" '''n",
" 数据集分割-----训练集、测试集合n",
" '''n",
" try:n",
" X_train,X_test,y_train,y_test=train_test_split(dataset,label,test_size=ratio)n",
" except:n",
" dataset,label=np.array(dataset),np.array(label)n",
" X_train,X_test,y_train,y_test=train_test_split(dataset,label,test_size=ratio)n",
" return X_train,X_test,y_train,y_testn",
"n",
" n",
"#加载本地的数据集 n",
"df = pd.read_csv('adult.csv')n",
"df.columns = [ "Age", "WorkClass", "fnlwgt", "Education", "EducationNum",n",
" "MaritalStatus", "Occupation", "Relationship", "Race", "Gender",n",
" "CapitalGain", "CapitalLoss", "HoursPerWeek", "NativeCountry", "Income"n",
" ]n",
"n",
"#定义特征列范围n",
"train_cols = df.columns[0:-1]n",
"#指定标签列n",
"label = df.columns[-1]n",
"X = df[train_cols]n",
"n",
"#对分类标签做简化的二值化处理,转化为:0、1分类n",
"y = df[label].apply(lambda x: 0 if x == " <=50K" else 1) n",
"n",
"#categorical特征数值化处理n",
"X_enc = pd.get_dummies(X, prefix_sep='.')n",
"feature_names = list(X_enc.columns)n",
"#训练集、测试集分隔n",
"X_train, X_test, y_train, y_test = dataSplit(X_enc,y,ratio=0.3)n",
"n",
"#数据集探索n",
"marginal = Marginal().explain_data(X_train, y_train, name = 'Train Data')n",
"show(marginal)n"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"RF Model Training Finished!!!n",
"GBDT Model Training Finished!!!n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"f:\python36\lib\site-packages\sklearn\linear_model\logistic.py:433: FutureWarning:n",
"n",
"Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.n",
"n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"LR Model Training Finished!!!n",
"DT Model Training Finished!!!n",
"MLP Model Training Finished!!!n"
]
}
],
"source": [
"#PCA数据特征降维+模型训练【基于随机森林模型】n",
"pca = PCA()n",
"rf = RandomForestClassifier(n_estimators=50)n",
"RF = Pipeline([('pca', pca), ('rf', rf)])n",
"RF.fit(X_train, y_train)n",
"print('RF Model Training Finished!!!')n",
"n",
"n",
"#PCA数据特征降维+模型训练【基于梯度提升决策树模型】n",
"pca = PCA()n",
"gbdt = GradientBoostingClassifier(n_estimators=50)n",
"GBDT = Pipeline([('pca', pca), ('gbdt', gbdt)])n",
"GBDT.fit(X_train, y_train)n",
"print('GBDT Model Training Finished!!!')n",
"n",
"n",
"#PCA数据特征降维+模型训练【基于逻辑回归模型】n",
"pca = PCA()n",
"lr = LogisticRegression()n",
"LR = Pipeline([('pca', pca), ('lr', lr)])n",
"LR.fit(X_train, y_train)n",
"print('LR Model Training Finished!!!') n",
"n",
"n",
"#PCA数据特征降维+模型训练【基于决策树模型】n",
"pca = PCA()n",
"dt = DecisionTreeClassifier()n",
"DT = Pipeline([('pca', pca), ('dt', dt)])n",
"DT.fit(X_train, y_train)n",
"print('DT Model Training Finished!!!') n",
"n",
"n",
"#PCA数据特征降维+模型训练【基于多层感知器神经网络模型】n",
"pca = PCA()n",
"mlp = MLPClassifier()n",
"MLP = Pipeline([('pca', pca), ('mlp', mlp)])n",
"MLP.fit(X_train, y_train)n",
"print('MLP Model Training Finished!!!') "
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"<!-- http://127.0.0.1:7525/91332056/ -->n",
"<iframe src="http://127.0.0.1:7525/91332056/" width=100% height=800 frameBorder="0"></iframe>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"#随机森林模型性能n",
"RF_perf = ROC(RF.predict_proba).explain_perf(X_test, y_test, name='RF')n",
"show(RF_perf)"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"<!-- http://127.0.0.1:7525/416994248/ -->n",
"<iframe src="http://127.0.0.1:7525/416994248/" width=100% height=800 frameBorder="0"></iframe>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"#梯度提升决策树模型性能n",
"GBDT_perf = ROC(GBDT.predict_proba).explain_perf(X_test, y_test, name='GBDT')n",
"show(GBDT_perf)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"<!-- http://127.0.0.1:7525/416993408/ -->n",
"<iframe src="http://127.0.0.1:7525/416993408/" width=100% height=800 frameBorder="0"></iframe>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"#逻辑回归模型性能n",
"LR_perf = ROC(LR.predict_proba).explain_perf(X_test, y_test, name='LR')n",
"show(LR_perf)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"<!-- http://127.0.0.1:7525/340319648/ -->n",
"<iframe src="http://127.0.0.1:7525/340319648/" width=100% height=800 frameBorder="0"></iframe>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"#决策树模型性能n",
"DT_perf = ROC(DT.predict_proba).explain_perf(X_test, y_test, name='DT')n",
"show(DT_perf)"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"<!-- http://127.0.0.1:7525/339351704/ -->n",
"<iframe src="http://127.0.0.1:7525/339351704/" width=100% height=800 frameBorder="0"></iframe>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"#多层感知器神经网络模型性能n",
"MLP_perf = ROC(MLP.predict_proba).explain_perf(X_test, y_test, name='MLP')n",
"show(MLP_perf)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "python36",
"language": "python",
"name": "python36"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.6"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
怎么说呢,直接来看可读性不高甚至是很差的,所以我就不去基于上述的文本形式的代码进行讲解说明了,感兴趣的可以直接复制过去运行的,接下来还是针对每一段代码块来进行解释说明:
首先是我们的数据部分:
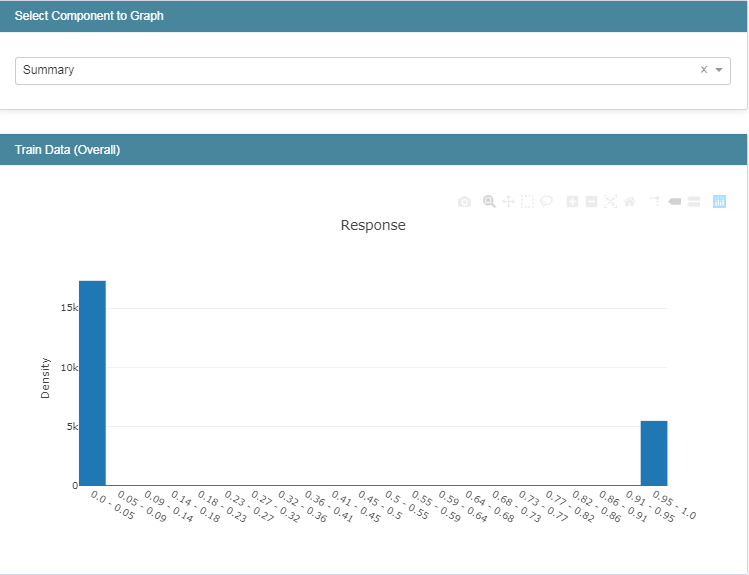
主要包括数据集的加载,类别标签的的0、1二值化转化处理,以及训练集和测试集划分处理。完成上述工作之后我们对原始的数据集进行了探索,绘制图像数据如下:
展示第一个属性特征的详细信息如下:
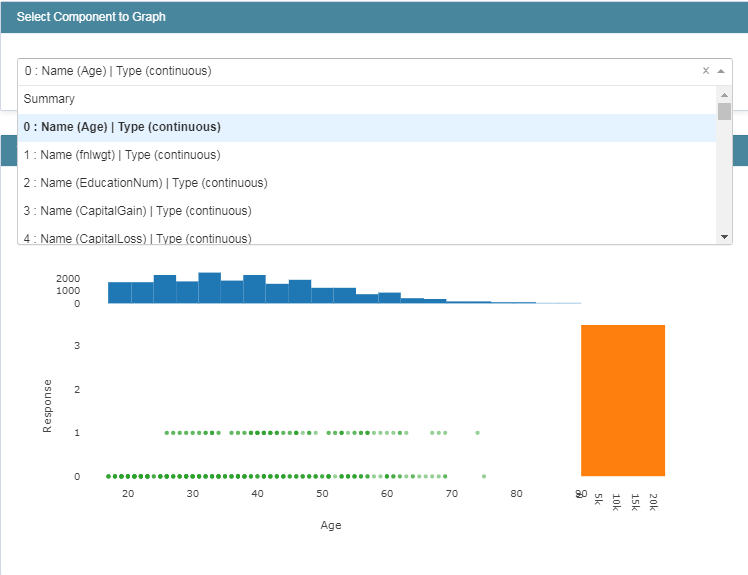
完成了数据集的处理与探索之后,接下来需要构建和训练模型:

可以看到:我上面一共选择了五种模型分别是:随机森林模型、梯度提升决策树模型、逻辑回归模型、决策树模型和多层感知机神经网络模型。该阶段的输出如下:

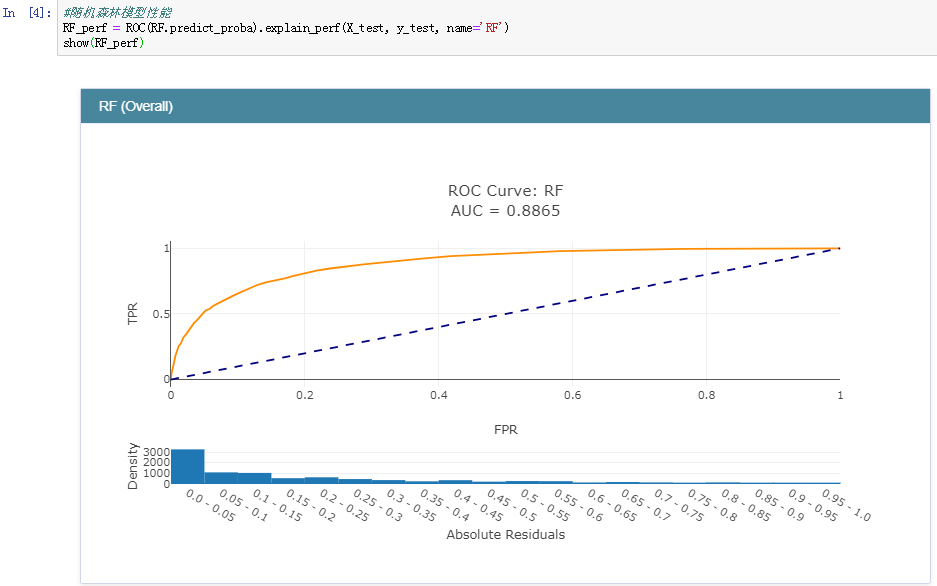
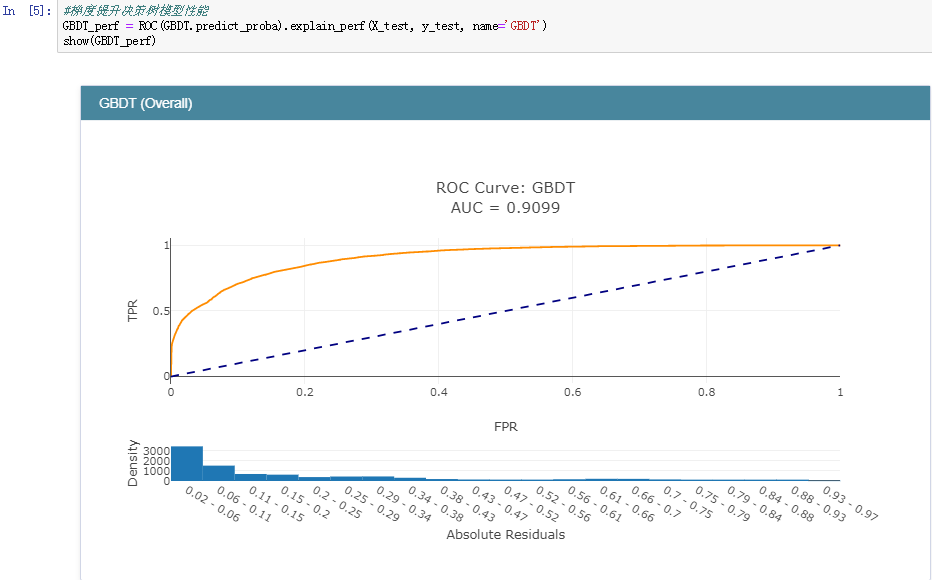
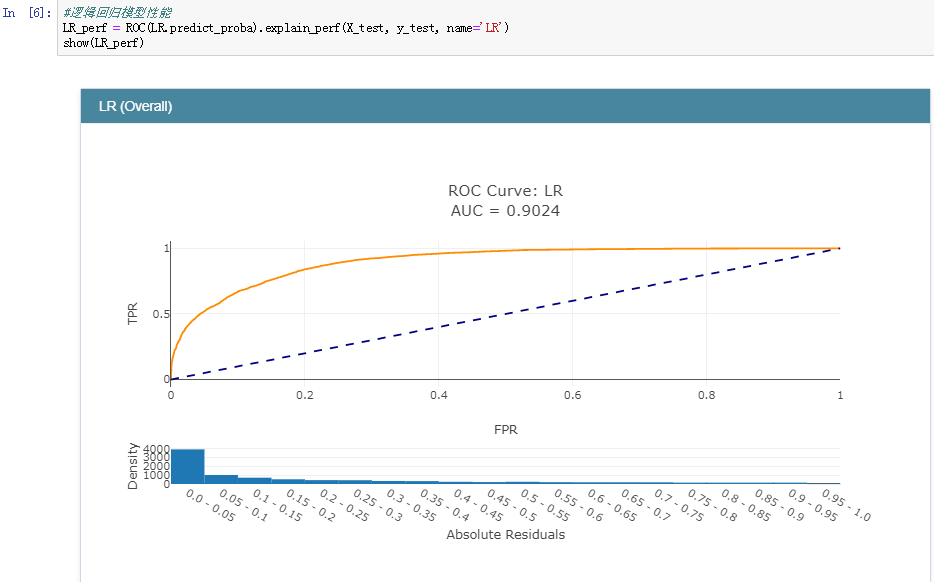
之后,完成了模型的训练后就可以对各个模型的分类性能做一个评估了,在分类领域中,较为常用的指标主要包括:精确率、召回率、准确率和F1值。在数据曲线方面主要用到的有:ROC曲线【AUC值】和PR曲线。今天我们采用的是ROC曲线【AUC值】来衡量各个模型的性能,AUC值就是ROC曲线与X轴之间的面积大小,结果如下:
随机森林模型:
梯度提升决策树模型:
逻辑回归模型:
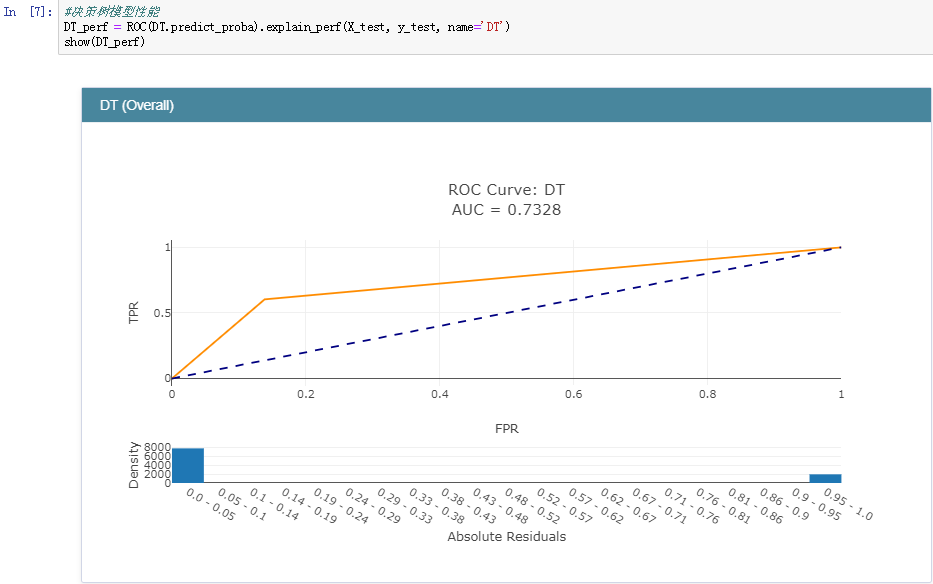
决策树模型:
多层感知器神经网络模型:
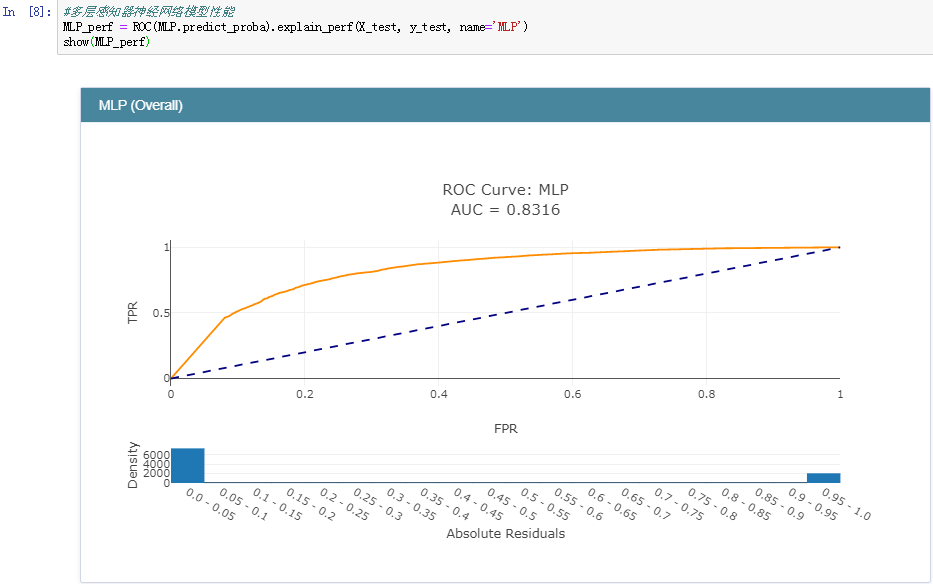
正是因为ROC曲线无法直接用于比较大小,才使用AUC值来间接地比对,从上述五种分类模型的AUC值来看:GBDT模型的性能最好,这个也比较符合我平时的实践,一般来说:在同等的参数配置下GBDT模型的性能相对来说都是很出色的,但是时间消耗来说也是比较大的,因为模型是串行设计和计算的。
最后贴出来数据集的地址,感兴趣的话可以去实验玩玩。
今天的实践内容就到这里,感觉还是很有收获的,继续努力了!
最后
以上就是合适河马最近收集整理的关于微软开源可解释机器学习框架 interpret 学习实践的全部内容,更多相关微软开源可解释机器学习框架内容请搜索靠谱客的其他文章。








发表评论 取消回复