目录
- 1 任务描述
- 2 使用MRT批量转为tiff数据
- 3 提取点坐标所在栅格的值
- 3.1 ArcGIS 方法
- 3.2 python gdal多值提取至点过程
- a. 提取矢量点的坐标
- b. 批量读取栅格数据
- c. 多点提取至栅格
- d. 导出为csv文件
- 4 批量提取完整代码
- PS: 新手求生欲
1 任务描述
获取MODIS level3大气月值统计产品数据(hdf文件),通过MRT工具批量提取出子数据集合,并转为tiff数据,再用python gdal 模块依照气象站点的shp文件提取出站点所在像元的值,最后汇总到excel。
数据来源:LAADS DAAC(MODIS Find Data)
数据类型:MOD08_M3(区别MYD08_M3:观测平台不同,MOD为Terra,MYD为Aqua)
数据子集要素(hdf文件含有多个子数据集合):气溶胶光学厚度(加权)平均值、大气水汽含量(最高、最低)平均值、云分数平均值、云光学厚度平均值、臭氧含量平均值共11个子图层。

2 使用MRT批量转为tiff数据
参考博客:
MRT下载、安装、拼接等操作
MRT(MODIS Reprojection Tool)安装、批量处理教程
批量处理结果:每个因子一个文件夹,文件夹中是已完成投影的单波段 tiff 数据。
3 提取点坐标所在栅格的值
现在需要提取红点(shp)所在像元上的值。
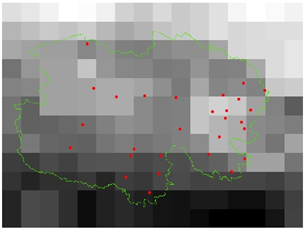
3.1 ArcGIS 方法
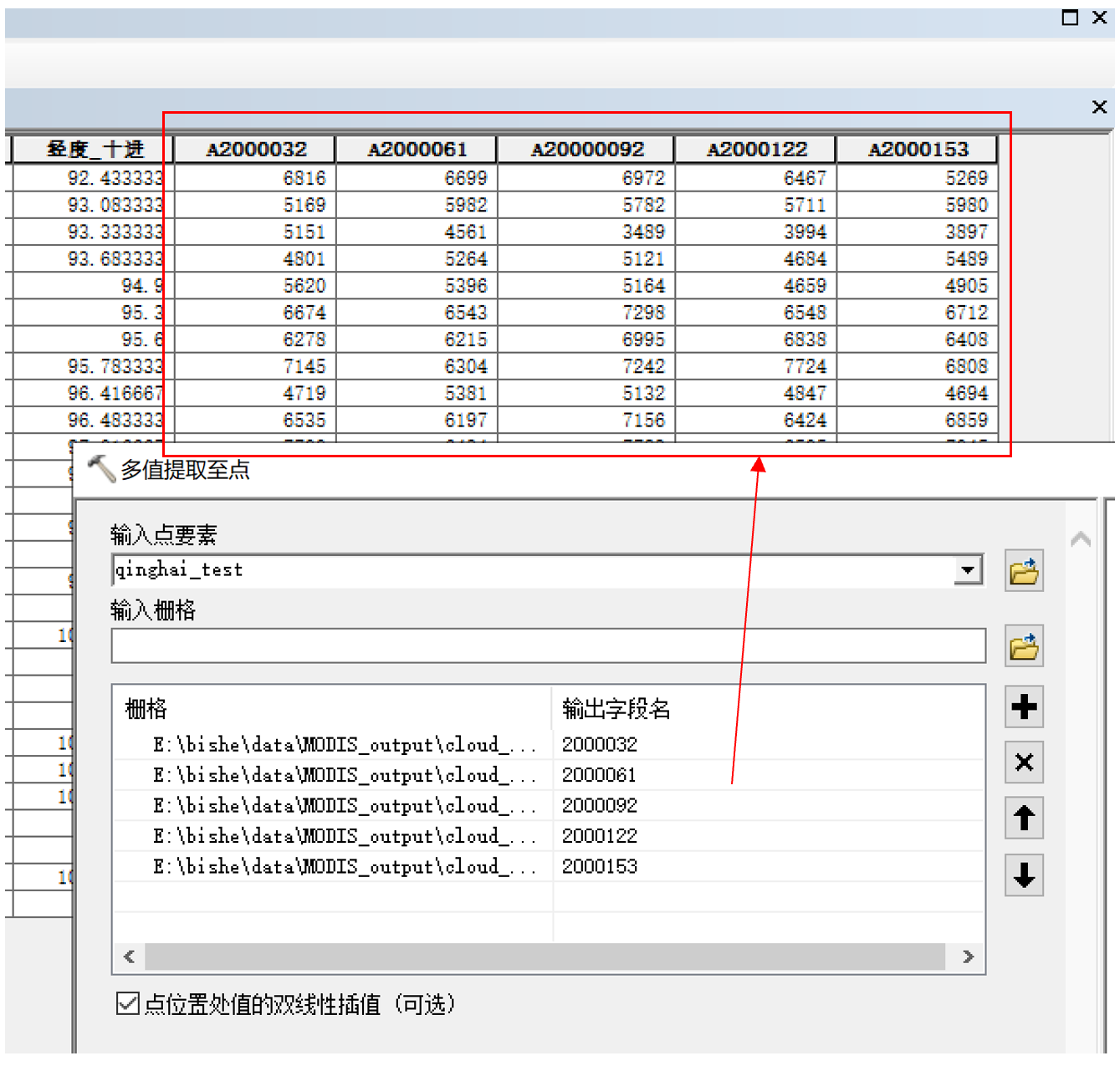
ArcToolbox → Spatial Analyst Tool → 提取分析 →多值提取至点(ExtractMultiValuesToPoints)
完成后,shp点文件的属性表能添加提取值的列。但是一张张添加,再导出表格的速度很慢,效率也比较低。
3.2 python gdal多值提取至点过程
参考博客:
Python + GDAL处理数据(3):提取栅格数据到点和栅格重采样
Python中gdal实现多幅栅格遥感影像图层数据批量绘制直方图
利用python读取点矢量对应栅格值
gdal 设计用来处理各种栅格地理数据格式的类库。
ogr 矢量库提供了简单的矢量数据读写工具
from osgeo import gdal, ogr
a. 提取矢量点的坐标
打开矢量数据
要读取某种类型的数据,必须要先载入数据驱动(driver),也就是初始化一个对象,让它“知道”某种数据结构。
# 数据驱动driver的open()方法返回一个数据源对象 0是只读,为 1是可写
driver = ogr.GetDriverByName('ESRI Shapefile')
shp = "E:\bishe\data\qxz_shp\qinghai_test1.shp"
ds = driver.Open(shp, 0)
if ds is None:
print('打开矢量文件失败')
sys.exit(1)
else:
print('打开矢量文件成功')
out: 打开矢量文件成功
读取矢量数据
Shapefile读取流程(部分):
driver → datasource → layer → feature→ geometry/field
driver → datasource → layer → layerdef→fieldfn
# 读取数据层
# 一般ESRI的shapefile都是填0的,如果不填的话默认也是0.
layer = ds.GetLayer(0)
# 要素个数
layer.GetFeatureCount()
out: 28
【28个要素,即28行数据(28个点)】
查看矢量图层属性
# 获取图层属性表定义
featuredefn = layer.GetLayerDefn()
# 获取属性表中字段个数
fieldcount = featuredefn.GetFieldCount()
# 输出矢量包含的属性列表名称
for attr in range(fieldcount):
# 获取矢量对用属性字段的定义
fielddefn = featuredefn.GetFieldDefn(attr)
#输出字段名称和字段类型
print("%s: %s" %(fielddefn.GetNameRef(),fielddefn.GetFieldTypeName(fielddefn.GetType())))
out: 【real型数据的存储大小为4个字节,可精确到小数点后第7位数字】
区站号: Real
台站名称: String
……
# 查看几何类型
geom = feature.GetGeometryRef()
geom.GetGeometryName()
out: ‘POINT’【点数据】
读取点坐标
构建三张列表,分别存储X坐标,Y坐标,以及具有区分意义的字段,如本套数据存储“区站号“。
# 存放每个点的xy坐标的数组
xValues = []
yValues = []
# 存放点“区站号”
station_list = []
读取图层中的要素feature,通过循环将28个要素的坐标提取和存储下来。
# 重置遍历对象(所有要素)的索引位置,以便读取
layer.ResetReading()
for i in range(layer.GetFeatureCount()):
feature = layer.GetFeature(i)
geometry = feature.GetGeometryRef()
x = geometry.GetX()
y = geometry.GetY()
#将要分类的点的坐标和点的类型添加
xValues.append(x)
yValues.append(y)
# 读取矢量对应”区站号“字段的值
station = feature.GetField("区站号")
station_list.append(station)
b. 批量读取栅格数据
os:operating system的缩写,提供Python 程序与操作系统进行交互的接口。
import os
读取栅格数据所在的文件夹中的所有数据,因为全部为tiff数据,所以可以直接读取。
# 读取栅格数据的文件夹
read_file_path = "E:\bishe\data\MODIS_output\cloud_fraction"
# listdir(path) 获取路径下的所有文件(全部为tif)
file_list = os.listdir(read_file_path)
len(file_list)
out: 253
【整个文件夹有253张栅格数据】
若文件夹下有其他数据,还应进行tiff数据的筛选。
tif_list=[]
for file in file_list:
if os.path.splitext(file)[1]==".tif":
tif_list.append(file)
c. 多点提取至栅格
以2000年为例,提取每个站点每个月的栅格值。(月份有可能缺失,不是每年都有12列数据)
date_list = []
for file in file_list:
#文件名称第10-14是年(YYYYYDDD)
if file[10:14] == "2000":
# 日期存入列表
date = file[10:17]
date_list.append(date)
# data_list存储(年+日序数):如2000032(表示2000年第32天,即2月1日)
len(date_list)
out:11 【2000年只有11个月的数据集】
创建一个二维列表,纵坐标是”区站号“,横坐标是时间(每月YYYYDDD)
# 创建二维空列表
values = [[0 for col in range(len(date_list))] for row in range(len(station_list))]
循环依次打开文件名中有2000(年)的文件,并计算坐标对应的像素值。
# count控制二维数组的列,每打开一个tiff,就新增一列(一个月的数据)
count = 0
for file in file_list:
if file[10:14] == "2000":
# 打开文件
path = os.path.join(read_file_path, file)
dr = gdal.Open(path)
# 存储着栅格数据集的地理坐标信息
transform = dr.GetGeoTransform()
# 影像左上角横坐标
x_origin = transform[0]
# 影像左上角纵坐标
y_origin = transform[3]
# 遥感图像的水平空间分辨率或者东西方向上的像素分辨率
pixel_width = transform[1]
# 遥感图像的垂直空间分辨率或者南北方向上的像素分辨率
pixel_height = transform[5]
for i in range(len(station_list)):
x = xValues[i]
y = yValues[i]
# 计算某一坐标对应像素的相对位置(pixel offset),也就是该坐标与左上角的像素的相对位置,按像素数计算
x_offset = int((x - x_origin) / pixel_width)
y_offset = int((y - y_origin) / pixel_height)
dt = dr.ReadAsArray(x_offset, y_offset, 1, 1)
values[i][count] = dt.flatten()
count += 1
d. 导出为csv文件
csv:逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
Pandas : Python 语言的一个扩展程序库,用于数据分析。其是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
import pandas as pd
构建数据框,导出数据
df = pd.DataFrame(columns=date_list, index=station_list, data=values)
save_path = 'E:\bishe\data\csv\cloud_fraction\cloud_fraction_2000.csv'
df.to_csv(save_path)
导出结果(excel/wps可以直接打开,使用查找替换ctrl+F, 将’[’ 和 ‘]’ 替换成空(不输入)即可)
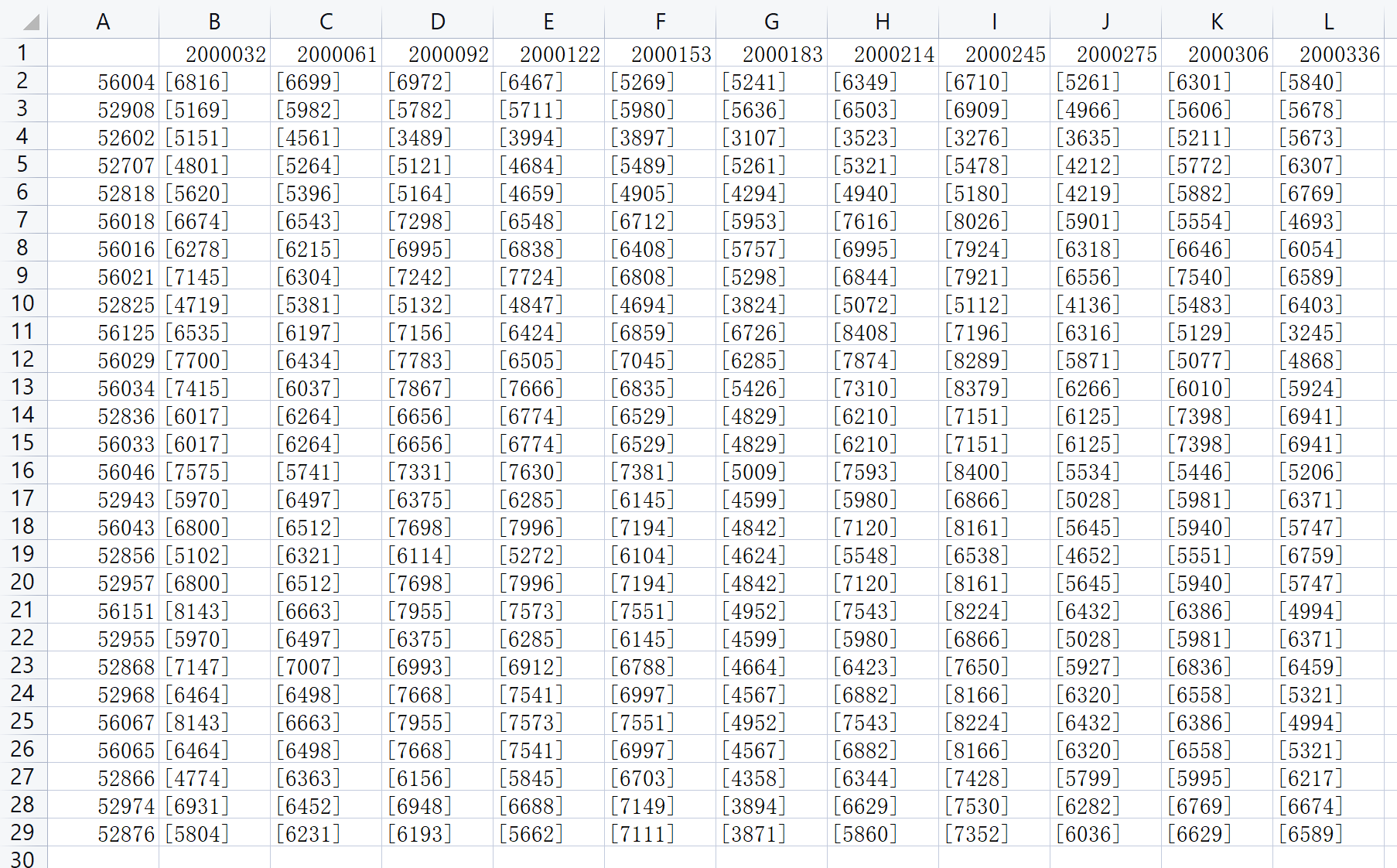
4 批量提取完整代码
每年提取一张表,即依照年份循环即能实现批量提取。定义一个函数extract_values_to_point,将年year作为输入参数,循环使用这一函数。另外矢量数据只需要一份,不需要反复提取,也不用查看各种属性(理解原理就可以了)。
import os
import pandas as pd
from osgeo import gdal, ogr
# 环境变量设置问题,找到proj文件
os.environ['PROJ_LIB'] = r'D:ms4wPythonLibsite-packagespyprojproj_dirshareproj'
# 矢量文件操作
driver = ogr.GetDriverByName('ESRI Shapefile')
shp_path = "E:\bishe\data\qxz_shp\qinghai_test1.shp"
ds = driver.Open(shp_path, 0)
layer = ds.GetLayer(0)
xValues = []
yValues = []
station_list = []
layer.ResetReading()
for i in range(layer.GetFeatureCount()):
feature = layer.GetFeature(i)
geometry = feature.GetGeometryRef()
x = geometry.GetX()
y = geometry.GetY()
xValues.append(x)
yValues.append(y)
station = feature.GetField("区站号")
station_list.append(station)
# 读取栅格数据的文件夹
# 每个因子(hdf子数据)一个文件夹,之前是cloud_fraction,现在使用water_vapor_low
read_file_path = "E:\bishe\data\MODIS_output\water_vapor_low"
file_list = os.listdir(read_file_path)
定义函数
def extract_values_to_point(year):
date_list = []
for file in file_list:
if file[10:14] == year:
date = file[10:17]
date_list.append(date)
values = [[0 for col in range(len(date_list))] for row in range(len(station_list))]
count = 0
for file in file_list:
if file[10:14] == year:
path = os.path.join(read_file_path, file)
dr = gdal.Open(path)
transform = dr.GetGeoTransform()
x_origin = transform[0]
y_origin = transform[3]
pixel_width = transform[1]
pixel_height = transform[5]
for i in range(len(station_list)):
x = xValues[i]
y = yValues[i]
x_offset = int((x - x_origin) / pixel_width)
y_offset = int((y - y_origin) / pixel_height)
dt = dr.ReadAsArray(x_offset, y_offset, 1, 1)
values[i][count] = dt.flatten()
count += 1
df = pd.DataFrame(columns=date_list, index=station_list, data=values)
save_path = 'E:\bishe\data\csv\water_vapor_low\a' + year + '.csv'
df.to_csv(save_path)
循环这一函数,如提取2000~2020年的数据
for y in range(2000, 2021):
input_year = str(y)
extract_values_to_point(input_year)
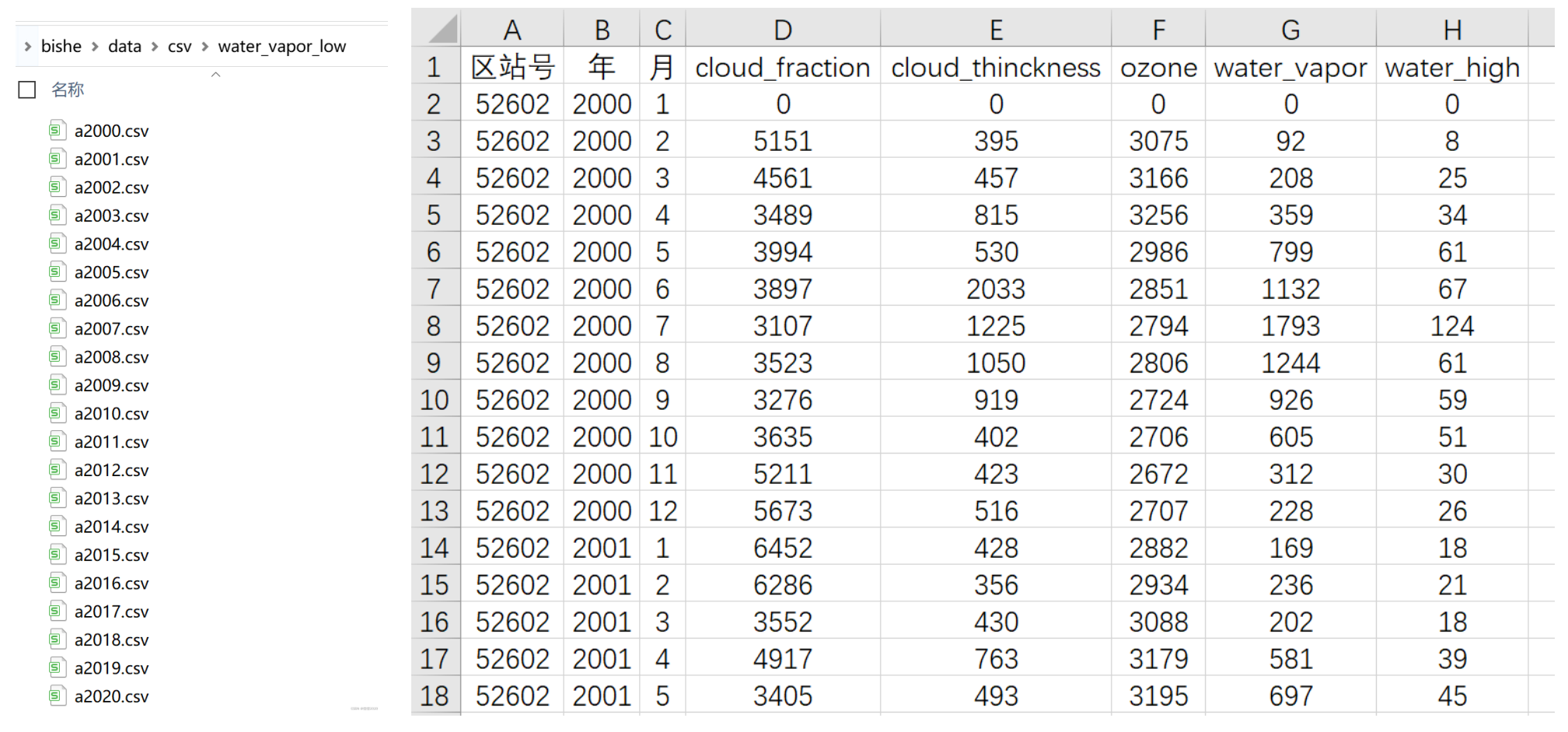
运行结果:
通过excel函数vlookup+函数match将所有因子和时间汇总到一张excel。
参考:八种方式实现多条件匹配
例如使用辅助列的办法进行多条件匹配:
=VLOOKUP(E3,'E:bishedatacsv[collect.xlsx]water_high'!$C$1:$O$608,MATCH(C3,'E:bishedatacsv[collect.xlsx]water_high'!$C$1:$O$1,0),0)
PS: 新手求生欲
本人刚学python和gdal,还是个编程菜鸡……循环出多张表再汇总终究还是慢一些,一定有直接操作电子表格一步到位的办法,整个代码应该也有不规范和可以再优化的地方,但是总体上对于我5个因子,20年的数据量来看,还算够用。另外,使用arcpy模块写代码可能更快,不过基于我对开源gdal的喜爱,就没有尝试arcpy了。因此,欢迎有更好更高效方法的各位大佬们与我交流!
最后
以上就是正直小松鼠最近收集整理的关于python gdal 矢量点坐标对应栅格值的批量提取_以MODIS大气产品为例(详细讲解+完整代码)1 任务描述2 使用MRT批量转为tiff数据3 提取点坐标所在栅格的值4 批量提取完整代码PS: 新手求生欲的全部内容,更多相关python内容请搜索靠谱客的其他文章。








发表评论 取消回复