生信入门(七)——数据预处理1
文章目录
- 生信入门(七)——数据预处理1
- 一、用基本包处理数据框
- 1.查看数据框中的内容
- 2、选取数据库的子集
- 3、将数据按照某个变量的值排序:order()
- 4、查找和删除数据:duplicated()
- 5、在数据框中添加和删除变量
- 6、把数据框添加到搜索路径
后面几节,将分别使用基本包和当前流行的 dplyr 包处理数据框,并介绍数据框的合并、长宽格式的转换、缺失值的处理、处理大型数据集的策略等操作。
一、用基本包处理数据框
加载epiDisplay包里的小型数据集Familydata
1.查看数据框中的内容
# BiocManager::install("epiDisplay")
library(epiDisplay)
data("Familydata")
ls()# 显示数据名
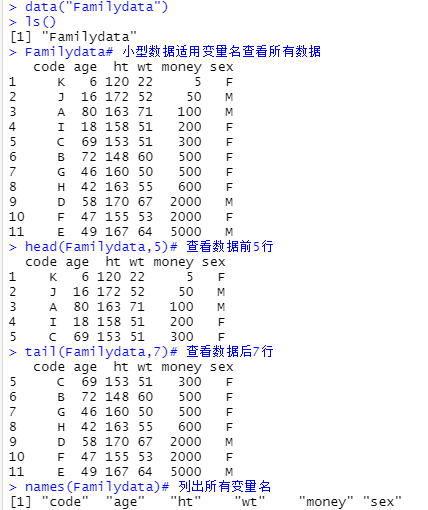
Familydata# 小型数据适用变量名查看所有数据
head(Familydata,5)# 查看数据前5行
tail(Familydata,7)# 查看数据后7行
names(Familydata)# 列出所有变量名
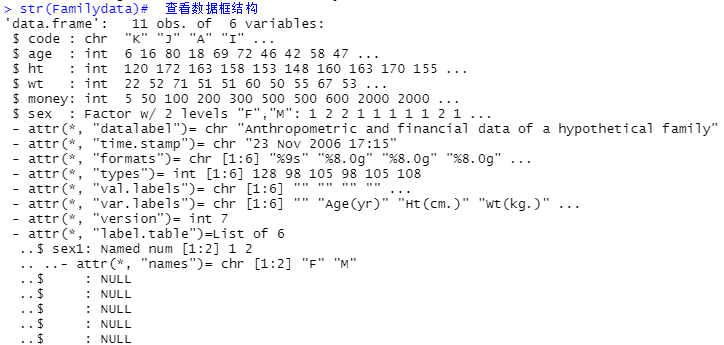
str(Familydata)# 查看数据框结构
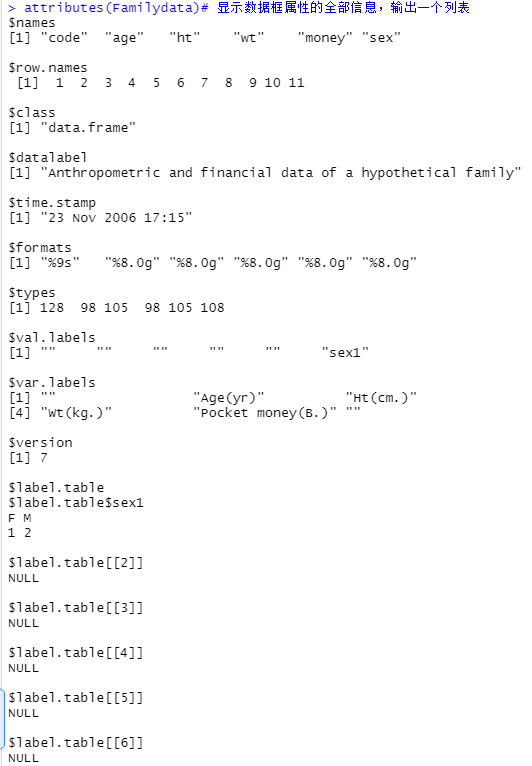
attributes(Familydata)# 显示数据框属性的全部信息,输出一个列表
#用户可以修改和自定义属性(为第一个和最后一个变量定义标签)
attr(Familydata,"var.labels")[1]<-"Identification number"
attr(Familydata,"var.labels")[6]<-"Gender"
attributes(Familydata)$var.labels# 显示两个变量信息
des(Familydata)# 显示数据信息,不想要str,可以用des

2、选取数据库的子集
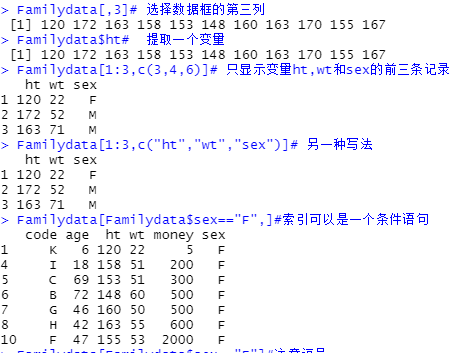
Familydata[,3]# 选择数据框的第三列
Familydata$ht# 提取一个变量
Familydata[1:3,c(3,4,6)]# 只显示变量ht,wt和sex的前三条记录
Familydata[1:3,c("ht","wt","sex")]# 另一种写法
Familydata[Familydata$sex=="F",]#索引可以是一个条件语句,注意逗号!!!
subset(Familydata,sex=="F")# 另一种选择子集的方法
subset(Familydata,sex=="F",select = c(ht,wt))# 选择女性中的变量ht和wt,subset只是选择一个子集显示,不会影响原来的数据框
sample.rows<-sample(1:nrow(Familydata),size=3,replace = FALSE)#在数据框中随机抽取一个大小为3的样本
sample.rows
3、将数据按照某个变量的值排序:order()
Familydata[order(Familydata$age),]# 将数据框Familydata以age从小到大显示
Familydata[order(Familydata$age,decreasing = TRUE),]# 将数据按照从大到小排序
Familydata[order(-Familydata$age),]#将age取反效果相同
4、查找和删除数据:duplicated()
duplicated(Familydata$code)# 检查该变量是否存在重复值
# 如果数据框的行数较多,逐一查看很麻烦,使用any()函数
any(duplicated(Familydata$code))
# 使用table,还可以的大重复的个数
table(duplicated(Familydata))

#复制源数据后将第2行添加在第12行
Familydata1<-Familydata
Familydata1[12,]<-Familydata[2,]
Familydata1
which(duplicated(Familydata1$code))#使用which()函数找到变量code重复值所在的行
unique.code.data<-Familydata1[!duplicated(Familydata1$code),]#删除重复的行
unique.code.data
identical(unique.code.data,Familydata)#查看两个对象是否一致
5、在数据框中添加和删除变量
Familydata$log10money<-log10(Familydata$money)#添加变量log10money
Familydata<-transform(Familydata,log10money=log10(money))#同样的效果
names(Familydata)

Familydata[,-7]#从数据框删除一个变量,删除第七列
# 以上命令只显示所需的子集,对数据库本身不会产生影响,下面命令会永久删除数据框中的变量
colnames(Familydata)
Familydata$log10money<-NULL
colnames(Familydata)

6、把数据框添加到搜索路径
在前面查看和使用数据框中的变量时,我们需要在变量名前面加上数据框名和符号 $。这种方式有时候会显得比较烦琐,尤其是数据框和变量的名字都很长的时候。
函数 attach( ) 或者函数 with( ) 可以用来简化代码。函数 attach( ) 可以将数据框添加到搜索路径中。
attach(Familydata)#将数据框添加到搜索路径
search()#查看搜索路径中的所有对象

数据框已经在搜索路径的第二个位置中了,而变量 age 又在该数据框里,所以现在可以直接使用变量 age
summary(age)#

把一个数据框放入搜索路径类似于使用函数 library( ) 加载一个包。调入搜索路径的数据框和加载的包都会被自动读入 R,并一直存放在内存中直至它们被移出(detach( ))。
使用函数 attach( ) 虽然会在输入代码时带来一些便利,但同时也会带来一些问题。例如,重复加载数据框可能会最终导致系统资源过度负荷。另外,如果全局环境中或多个数据框中有相同的变量名,容易使用户产生混淆。因此,有些 R 的使用者尽量避免使用函数 attach( ),而使用函数 with( )。
# with的用法(以database中的infert为例)
infert#查看数据
with(infert,summary(age))
函数 with( ) 的局限性在于,对于多次使用数据框,我们必须重复使用函数 with( )。此外,赋值仅在此函数内部生效。
# 不忘将数据框从搜索路径移除
detach(Familydata)
search()

今日告一段落,明天见~
最后
以上就是震动冰淇淋最近收集整理的关于生信入门(七)——数据预处理1生信入门(七)——数据预处理1的全部内容,更多相关生信入门(七)——数据预处理1生信入门(七)——数据预处理1内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复