我是靠谱客的博主 沉静舞蹈,这篇文章主要介绍读取xml文件中的信息到txt文本中1.代码2.root.iter(‘size’)和root.find(‘size’)3.参考链接:,现在分享给大家,希望可以做个参考。
1.代码
import xml.etree.ElementTree as ET
import os
"""
r''要加上的
"""
source = r'D:pycharmpytorch相关labelImg-masterori_xlm' # 文件夹路径
dir = os.listdir(source)
dir为一个列表
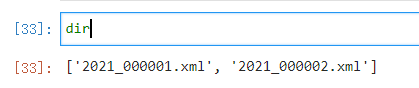
查看dir中的第二个元素(index=1)
作为一个N叉树
可以查看其叶子节点
里面出现了多个’obejct’节点
因为源xml文件框了好几个不同的对象
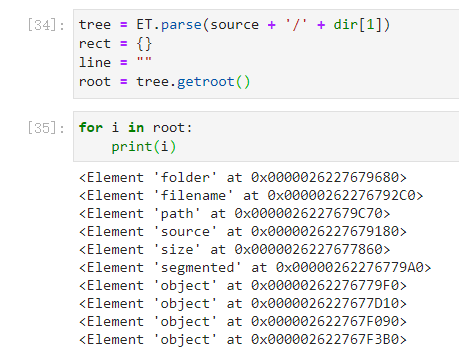
查看xml文件里面的的路径名
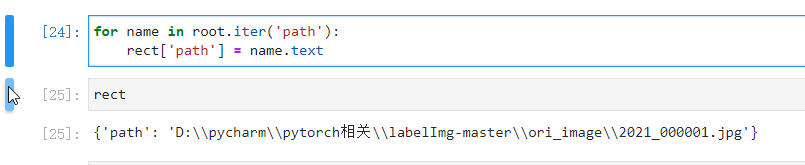
当一个root里有多个’object‘属性时,通过双层for循环即可取出来
for i in root.iter('object'):
print(i)
for j in i.iter('bndbox'):
print(j)
<Element 'object' at 0x00000262276779F0>
<Element 'bndbox' at 0x0000026227677B80>
<Element 'object' at 0x0000026227677D10>
<Element 'bndbox' at 0x0000026227677EA0>
<Element 'object' at 0x000002622767F090>
<Element 'bndbox' at 0x000002622767F220>
<Element 'object' at 0x000002622767F3B0>
<Element 'bndbox' at 0x000002622767F540>
把坐标和name写进一个txt文件中
for i in range(len(dir)):
tree = ET.parse(source + '/' + dir[i])
rect = {}
line = ""
root = tree.getroot()
with open('D:pycharmpytorch相关labelImg-masterori_xlminfo.txt', 'a', encoding='utf-8') as f1:
# 路径信息
for name in root.iter('path'):
"""
rect是一个字典,没有key时,会自动生成key以及对应的value
"""
rect['path'] = name.text
for ob in root.iter('object'):
for bndbox in ob.iter('bndbox'):
"""
for i in root:
print(i)
<<<
<Element 'folder' at 0x0000026227679680>
<Element 'filename' at 0x00000262276792C0>
<Element 'path' at 0x0000026227679C70>
<Element 'source' at 0x0000026227679180>
<Element 'size' at 0x0000026227677860>
<Element 'segmented' at 0x00000262276779A0>
<Element 'object' at 0x00000262276779F0>
<Element 'object' at 0x0000026227677D10>
<Element 'object' at 0x000002622767F090>
<Element 'object' at 0x000002622767F3B0>
出现多个叶子节点object,只需要两层迭代。就能把每一个name和bndbox坐标取出来
"""
for xmin in bndbox.iter('xmin'):
rect['xmin'] = xmin.text
for ymin in bndbox.iter('ymin'):
rect['ymin'] = ymin.text
for xmax in bndbox.iter('xmax'):
rect['xmax'] = xmax.text
for ymax in bndbox.iter('ymax'):
rect['ymax'] = ymax.text
print(rect['xmin'] + ' ' + rect['ymin'] + ' ' + rect['xmax'] + ' ' + rect['ymax'])
line = rect['xmin'] + ' ' + rect['ymin'] + ' ' + rect['xmax'] + ' ' + rect['ymax'] + " "
f1.write(line)
# 文本信息,这个循环应该在for bndbox 外面的,才合理
for t in ob.iter('name'):
print(t.text)
f1.write(t.text + 'n')
print结果如下
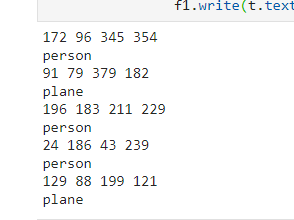
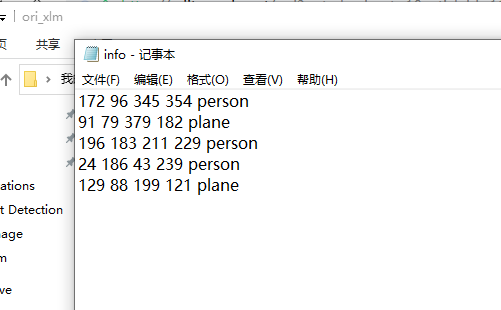
txt文件内容如下:
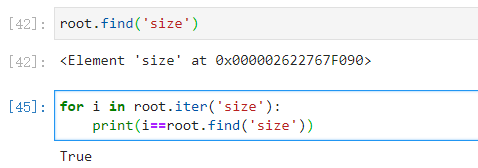
2.root.iter(‘size’)和root.find(‘size’)
前者为迭代器,还是要靠for才能取出其element
后者为element
for i in root.iter('size'):
print(i==root.find('size'))
# True

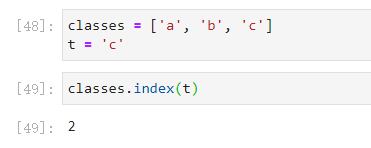
cls_id = classes.index(cls) 这个注意一下
"""
把左上、右下坐标形式转换为
(x,y,h,w)
并且归一化(0,1)之间
"""
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + 'n')
3.参考链接:
1.使用labelImg标注数据的方法
2.读取labelimg生成的xml标签
最后
以上就是沉静舞蹈最近收集整理的关于读取xml文件中的信息到txt文本中1.代码2.root.iter(‘size’)和root.find(‘size’)3.参考链接:的全部内容,更多相关读取xml文件中内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复