字符串
字符串(str)一般是指Unicode字符串,见名知意,字符串是由多个字符所构成的一个串。
它是Python中最常用的数据类型之一,因此十分重要。
字符串有一个最显著的特征,即不可变,也就是说你无法使用索引来改变字符串中的字符,仅限于获取。
字符串特性
字符串特性如下:
- 字符串属于线性扁平序列
- 字符串是不可变的,即对象本身的属性不会根据外部变化而变化
- 字符串底层是一段连续的内存空间
基本声明
以下是使用类实例化的形式进行对象声明:
string = str("ABCDEFG")
print("value : %rntype : %r" % (string, type(string)))
# value : 'ABCDEFG'
# type : <class 'str'>
也可以选择使用更方便的字面量形式进行对象声明,使用英文状态下的单引号、双引号、三单引号、三双引号将数据项进行包裹即可:
string = "ABCDEFG"
print("value : %rntype : %r" % (string, type(string)))
# value : 'ABCDEFG'
# type : <class 'str'>
个人并不推荐常规的使用三单引号或三双引号进行字符串定义,因为除了字符串定义外它们还具有文档注释的功能。
续行操作
在Python中,如果一个字符串过长,可能会导致不符合PEP8规范的情况出现。
- 每行最大的字符数不可超过79,文档字符或者注释每行不可超过72
如果要定义这样的长字符串,推荐使用三单引号或者三双引号进行定义,这样即可进行换行(但会保留特殊字符,如n):
string = """
江雪
柳宗元
千山鸟飞绝
万径人踪灭
孤舟蓑笠翁
独钓寒江雪
"""
print("value : %rntype : %r" % (string, type(string)))
# value : 'n 江雪n 柳宗元n千山鸟飞绝n万径人踪灭n孤舟蓑笠翁n独钓寒江雪n'
# type : <class 'str'>
类型转换
字符串支持与布尔型、整形、以及浮点型进行转换,这是最常用的操作:
string = "100"
iStr = int(string)
bStr = bool(string)
fStr = float(string)
print("value : %rntype : %r" % (iStr, type(iStr)))
print("value : %rntype : %r" % (bStr, type(bStr)))
print("value : %rntype : %r" % (fStr, type(fStr)))
# value : 100
# type : <class 'int'>
# value : True
# type : <class 'bool'>
# value : 100.0
# type : <class 'float'>
需要注意的是,如果一个字符串不是纯数字,那么将其转换为整形或浮点型时将会出现异常:
string = "Non-digital string: 100"
iStr = int(string)
fStr = float(string)
print("value : %rntype : %r" % (iStr, type(iStr)))
print("value : %rntype : %r" % (fStr, type(fStr)))
# ValueError: invalid literal for int() with base 10: 'Non-digital string: 100'
此外,字符串也支持转换为列表以及集合:
string = "①〇②④"
setStr = set(string)
listStr = list(string)
print("value : %rntype : %r" % (setStr, type(setStr)))
print("value : %rntype : %r" % (listStr, type(listStr)))
# value : {'①', '〇', '②', '④'}
# type : <class 'set'>
# value : ['①', '〇', '②', '④']
# type : <class 'list'>
特殊的
在普通的声明字符串中,后面一般都会跟上一个特殊字符。
该字符具有特殊的意义,如n代表换行,t代表制表符等,这种具有特殊意义的char组合被称为转义字符。
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| a | 响铃(BEL) | 007 |
| b | 退格(BS) ,将当前位置移到前一列 | 008 |
| f | 换页(FF),将当前位置移到下页开头 | 012 |
| n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| v | 垂直制表(VT) | 011 |
| 代表一个反斜线字符’’’ | 092 | |
| ’ | 代表一个单引号(撇号)字符 | 039 |
| " | 代表一个双引号字符 | 034 |
| ? | 代表一个问号 | 063 |
| � | 空字符(NUL) | 000 |
| ddd | 1到3位八进制数所代表的任意字符 | 三位八进制 |
| xhh | 十六进制所代表的任意字符 | 十六进制 |
如果你还是不能理解,那么可看下面这个示例:
我想打印 hello”world,并且我的字符串字面量声明采用 “ 进行包裹。
我们必须进行“的转义,让它变为一个普通字符,而非Python中字符串字面量语法表示符:
print("hello"world")
# hello"world
r字符串
如果在声明字符串的前面加上字符r,则代表该字符串中不会存在转义字符,所有字符将按照普通的方式进行解读。
r字符串也被称为原始字符串:
s1 = r"ntb"
print(s1)
# ntb
字节串
字节串(bytes)是字符串的另一种表现形式。
它记录内存中的原始数据,你可以将它理解为2进制数据。
字节串可用于网络传输、多媒体持久化存储中,它和字符串拥有相同的特性,即不可变。
字节串仅在Python3中出现,Python2中不存在该类型。
基本声明
以下是使用类实例化的形式进行对象声明,必须传入一个字符串及指定该字符串的编码格式,如不传入字符串,则默认生成空的bytes对象:
bitStr = bytes("ABCDEFG".encode("u8"))
print("value : %rntype : %r" % (bitStr, type(bitStr)))
# value : b'ABCDEFG'
# type : <class 'bytes'>
也可以选择使用更方便的字面量形式进行对象声明,使用英文状态下的小写b加上单引号、双引号、三单引号、三双引号将数据项进行包裹即可,注意数据项必须位于ASCII码表之内:
bitStr = b"ABCDEFG"
print("value : %rntype : %r" % (bitStr, type(bitStr)))
# value : b'ABCDEFG'
# type : <class 'bytes'>
个人并不推荐常规的使用三单引号或三双引号进行字节串定义,它们还具有文档注释的功能。
编码解码
一个非ASCII标准字符串要变为字节串,必须通过encode()方法来做指定编码格式。
而一个字节串要想变为非ASCII标准字符串,也必须通过decode()方式做指定解码格式。
s = "你好,世界,hello,world!"
bitStr = bytes(s.encode(encoding="u8"))
print(bitStr)
string = str(bitStr.decode(encoding="u8"))
print(string)
# b'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8cxefxbcx8chelloxefxbcx8cworld!'
# 你好,世界,hello,world!
如果直接使用str.encode()则自动将str转变为bytes类型。
反之,如果直接使用bytes.decode()时bytes也会自动转为str类型。
因此我们可以省略bytes()和str()在外部的包裹:
s = "你好,世界,hello,world!"
bitStr = s.encode(encoding="u8")
print(bitStr)
string = bitStr.decode(encoding="u8")
print(string)
# b'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8cxefxbcx8chelloxefxbcx8cworld!'
# 你好,世界,hello,world!
四则运算
基本操作
字符串支持与字符串进行加法运算,做到拼接的效果,由于字符串是不可变的,所以会生成一个新的字符串:
s1 = "string1"
s2 = "string2"
print(s1 + s2)
# string1string2
字符串支持与整形进行乘法运算,做到重复打印的效果,由于字符串是不可变的,所以会生成一个新的字符串:
s1 = "*"
print(s1 * 3)
# ***
“可变”的字符串
str可以使用+=操作,来使原本的字符串与新的字符串进行拼接。
+=是一种常见的操作,所以CPython内部为其做了优化。
一个str在初始化内存的时候,程序会为它留出额外的可扩展空间,因此进行增量操作的时候,并不会涉及复制原有字符串到新位置这类操作,而是在原有字符串位置的后面添加上新的字符串。
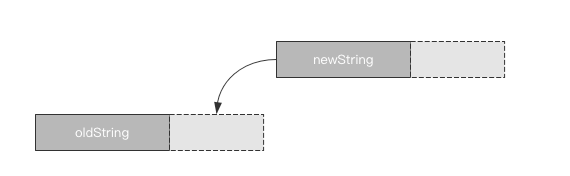
基于这个点,我们看一个有趣的问题:
>>> a
'hello world !'
>>> id(a)
140521043795728
>>> a+="d"
>>> id(a)
140521043795728
>>> a+="d"
>>> id(a)
140521043795728
>>> a
'hello world !dd'
乍看之下其实会发现字符串的+=操作并不会开辟额外的内存空间,但是事实并非如此。
CPython的字符串在底层依旧是不可变的,当这个字符串被+=新的字符串时,会产生一个新的字符串,恰好该字符串会复用之前字符串的id()值。
这个问题在stackoverflow上已经有人问过了,这里贴出原贴:
点我跳转
字符间隙
看一个有趣的例子:
s1 = "HELLO"
boolRET = "" in s1
print(boolRET)
# True
下一个例子,使用count()方法计算该字符串中空白字符的数量:
s1 = "HELLO"
print(s1.count(""))
# 6
小问号你是否充满了很多朋友?
实际上,Python内部进行str存储的时候会为每个字符之间留一个空隙,如下所示:

所以才会造成上述情况的发生。
intern机制
intern机制是Python解释器为了节省内存而做出的一种策略。
当第一次创建一个短字符串的时候,都会用一个全局的字典将该字符串进行存储,而短字符串的定义如下:
- 长度不超过20
- 不含空格
当再次创建这个短字符串,会先查看全局字典中是否存在该短字符串,如果存在则不创建而是直接进行引用。
这种策略也被称之为短字符串驻留机制。
下面这个示例字符串是符合短字符串的,因此会进行驻留:
>>> s1 = "Python"
>>> s2 = "Python"
>>> s1 is s2
True
由于字符串中含有空格,故该字符串不会触发驻留机制:
>>> s1 = "Pytho n"
>>> s2 = "Pytho n"
>>> s1 is s2
False
字符串长度超过20,也不会触发驻留机制:
>>> s1 = "Python" * 10
>>> s2 = "Python" * 10
>>> s1 is s2
False
如果是空字符串,也会有驻留机制:
>>> s1 = ""
>>> s2 = ""
>>> id(s1)
4360137392
>>> id(s2)
4360137392
绝对引用
字符串拥有绝对引用的特性,则无论是深拷贝还是浅拷贝,都不会获得其副本,而是直接对源对象进行引用:
>>> import copy
>>> oldStr = "0" * 100
>>> id(oldStr)
4373971144
>>> s1 = copy.copy(oldStr)
>>> id(s1)
4373971144
>>> s2 = copy.deepcopy(oldStr)
>>> id(s2)
4373971144
索引切片
字符串由于是线性结构,故支持索引和切片操作。
由于字符串是不可变类型,所以索引操作也仅支持获取数据项,不支持删改数据项。
使用方法参照列表的索引切片一节。
常用方法
方法一览
常用的str方法一览:
| 方法名 | 返回值 | 描述 |
|---|---|---|
| strip() | str | 移除字符串两侧指定的字符,如不进行指定,则默认移除n、t以及空格。 |
| split() | list | 按照指定字符进行从左到右的分割,以列表形式返回。可指定maxslipt限制切分次数 |
| rsplit() | list | 按照指定字符进行从右到左的分割,以列表形式返回。可指定maxslipt限制切分次数 |
| join() | str | 将一个列表中的数据项以指定字符拼接成新的字符串 |
| replace() | str | 将字符串中的指定子串替换成另一个子串 |
| count() | integer | 统计子串在父串中出现的次数 |
| title() | str | 令字符串中的每一个单词首字母大写 |
| capitalize() | Str | 令字符串中的句首单词首字母变为大写 |
| find() | integer | 查找子串首次出现在父串中的索引值,若存在则返回索引,若不存在则返回-1,从左至右查找 |
| rfind() | integer | 同上,从右至左查找 |
| upper() | str | 令字符串中所有的小写字母转换为大写 |
| lower() | str | 令字符串中所有的大写字母转换为小写 |
| startswith() | bool | 判断字符串是否以特定子串开头 |
| endswith() | bool | 判断字符串是否以特定子串结束 |
| isdigit() | bool | 判断该字符串是否是一个数字串 |
基础公用函数:
| 函数名 | 返回值 | 描述 |
|---|---|---|
| len() | integer | 返回容器中的项目数 |
| enumerate() | iterator for index, value of iterable | 返回一个可迭代对象,其中以小元组的形式包裹数据项与正向索引的对应关系 |
| reversed() | … | 详情参见函数章节 |
| sorted() | … | 详情参见函数章节 |
获取长度
使用len()方法来进行字符串长度的获取。
返回int类型的值。
s1 = "abcdefg"
print(len(s1))
# 7
Python在对内置的数据类型使用len()方法时,实际上是会直接的从PyVarObject结构体中获取ob_size属性,这是一种非常高效的策略。
PyVarObject是表示内存中长度可变的内置对象的C语言结构体。
直接读取这个值比调用一个方法要快很多。
移除空白
使用strip()方法移除字符串两侧指定的字符,如不进行指定,则默认移除n、t以及空格。
返回str类型的值。
s1 = " abcdefg $$$"
res = s1.strip(" $")
print(res)
# abcdefg
拆分列表
使用split()方法按照指定字符进行从左到右的分割,以列表形式返回。可指定maxslipt限制切分次数。
返回list类型的值。
s1 = "ab,cd,ef,gh"
res = s1.split(",",maxsplit=1)
print(res)
# ['ab', 'cd,ef,gh']
使用rsplit()方法按照指定字符进行从右到左的分割,以列表形式返回。可指定maxslipt限制切分次数。
返回list类型的值。
s1 = "ab,cd,ef,gh"
res = s1.rsplit(",",maxsplit=1)
print(res)
# ['ab,cd,ef', 'gh']
列表合并
使用join()方法将一个列表中的数据项以指定字符拼接成新的字符串。
返回str类型的值。
l1 = ["a","b","c"]
res = "-".join(l1)
print(res)
# a-b-c
替换操作
使用replace()方法将字符串中的指定子串替换成另一个子串。
返回str类型的值。
s1 = "ABCDEFG"
res = s1.replace("BCD","bcd")
print(res)
# AbcdEFG
次数统计
使用count()方法统计子串在父串中出现的次数。
返回int类型的值。
s1 = "HELLO"
res = s1.count("L")
print(res)
# 2
词首大写
使用title()方法令字符串中的每一个单词首字母大写。
返回str类型的值。
s1 = "hello world"
res = s1.title()
print(res)
# Hello World
句首大写
使用capitalize()方法令字符串中的句首单词变为大写。
返回str类型的值。
s1 = "hello world"
res = s1.capitalize()
print(res)
# Hello world
索引位置
使用find()方法查找子串首次出现在父串中的索引值,若存在则返回索引,若不存在则返回-1,这是从左至右查找,rfind()则是从右至左查找。
返回int类型的值。
s1 = "hello world"
res = s1.find("w")
print(res)
# 6
小写转大写
使用upper()方法令字符串中所有的小写字母转换为大写。
返回str类型的值。
s1 = "hello world"
res = s1.upper()
print(res)
# HELLO WORLD
大写转小写
使用lower()方法令字符串中所有的大写字母转换为小写。
返回str类型的值。
s1 = "HELLO WORLD"
res = s1.lower()
print(res)
# hello world
指定开头
使用startswith()方法判断字符串是否以特定子串开头。
返回bool类型的值。
s1 = "HELLO WORLD"
res = s1.startswith("HE")
print(res)
# True
指定结尾
使用endswith()方法判断字符串是否以特定子串结束。
返回bool类型的值。
s1 = "HELLO WORLD"
res = s1.endswith("LD")
print(res)
# False
数字串
使用isdigit()方法判断该字符串是否是一个数字串。
返回bool类型的值。
s1 = "100"
res = s1.isdigit()
print(res)
# True
其他方法
以下是一些其他不太常用的方法:
| 方法名 | 返回值 | 描述 |
|---|---|---|
| index() | integer | 同find(),唯一区别找不到抛出异常,find()是返回-1,从左至右查找 |
| rindex() | integer | 同上,从右至左查找 |
| swapcase() | str | 字符串中大小进行翻转。大写转小写,小写转大写。 |
| expandtabs() | str | 指定字符串中的tab长度,t代表制表符,默认长度为8 |
| center() | str | 指定宽度,指定字符。若字符串的长度不够则将字符串放在中间,两侧使用指定字符填充 |
| ljust() | str | 指定宽度,指定字符。若字符串的长度不够则将字符串放在左边,右侧使用指定字符填充 |
| rjust() | str | 指定宽度,指定字符。若字符串的长度不够则将字符串放在右边,左侧使用指定字符填充 |
| zfill() | str | 同rjust(),但是不可指定填充字符。按0进行填充 |
| isdecimal() | bool | 判断字符串是否由数字组成。只支持unicode并且没有bytes的使用 |
| isnumeric() | bool | 判断字符串是否由数字组成。只支持unicode,中文数字,罗马数字并且没有bytes的使用 |
| isalnum() | bool | 判断字符串是否仅由数字和字母构成 |
| isalpha() | bool | 判断字符串是否仅由字母构成 |
| isspace() | bool | 判断字符串是否仅由空格构成 |
| islower() | bool | 判断字符串是否纯小写 |
| isupper() | bool | 判断字符串是否纯大写 |
| istitle() | bool | 判断字符串中的单词是否首字母大写 |
index()与rindex()方法:
s1 = "Python"
s1.index("a")
s1.rindex("a")
# ValueError: substring not found
字符串翻转swapcase()方法:
s1 = "Python"
print(s1.swapcase())
# pYTHON
指定制表符长度的expandtabs()方法,默认制表符的长度为8,下面指定为4:
s1 = "Ptyttthtotn"
print(s1)
print(s1.expandtabs(4))
# P y t h o n
# P y t h o n
字符填充系列:
s2 = "H"
print(s2.center(20, "+"))
print(s2.ljust(20, '+'))
print(s2.rjust(20, '+'))
print(s2.zfill(20)) # 0 填充,不可指定填充字符
# 其实总体来说就是将一个字符必须按照指定字符扩展为指定长度
# 区别在于源字符串的位置在指定填充符的中间、左侧、还是右侧
# +++++++++H++++++++++
# H+++++++++++++++++++
# +++++++++++++++++++H
# 0000000000000000000H
字符串判断系列之数字串检测:
s1 = b"4" # 字节数字串
s2 = u"4" # unicode数字串,默认Python3的str就是unicode编码,可以不用加u
s3 = "四" # 中文数字串
s4 = "Ⅳ" # 罗马数字串
# isdigt()检测是否为数字串,只支持bytes和unicode
print(s1.isdigit()) # True
print(s2.isdigit()) # True
print(s3.isdigit()) # False
print(s4.isdigit()) # False
# isdecimal()检测是否为数字串,只支持unicode字符串,如果是bytes字节串则抛出异常
print(s2.isdecimal()) # True
print(s3.isdecimal()) # False
print(s4.isdecimal()) # False
# isnumeric()检测是否为数字串,不支持bytes字节串,支持unicode字符串、中文数字串、罗马数字串
print(s2.isnumeric()) # True
print(s3.isnumeric()) # True
print(s4.isnumeric()) # True
字符串判断之成员检测:
s1 = "Python3.6.8"
# isalnum() 判断字符串是否仅由数字和字母构成
print(s1.isalnum()) # False
# isalpha() 判断字符串是否仅由字母构成
print(s1.isalpha()) # False
# isspace() 判断字符串是否仅由空格构成
print(s1.isspace()) # False
字符串判断之大小写检测:
s1 = "Python3.6.8"
# islower() 判断字符串是否纯小写
print(s1.islower()) # False
# isupper() 判断字符串是否纯大写
print(s1.isupper()) # False
# istitle() 判断字符串中的单词是否首字母大写
print(s1.istitle()) # True
版本区别
数字与字符串对比
在Python2中是支持字符串与数字进行比较的,字符串永远比数字大:
>>> "0" > 1
True
但是在Python3中,这种比较会抛出异常:
>>> "0" > 1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '>' not supported between instances of 'str' and 'int'
表现形式
Python2的字符串表现形式为原始字节序列,也就是说Python2的str其实实际上是Python3的字节串,故仅支持在ASCII码表之内的字符:
>>> s1 = "你好,世界"
>>> s1
'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8c'
但是在Python3中的字符串表现形式不是这样的,Python3中的字符串统一都为Unicode字符串:
>>> s1 = "你好,世界"
>>> s1
'你好,世界'
底层探究
扁平序列
这里引出一个新的概念,线性扁平序列。
- 扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型
- 扁平序列里存放的是值而不是引用
- 扁平序列不支持多维的说法,仅有一个维度
字符串为什么要设计成不可变类型?这是由于字符串内部是采用连续存储的方式。
因为字符串是连续的一块内存存放(在c语言体现中其实是一个数组,以�结尾),被看做为一个整体,修改其中某一个数据项那么必定会导致后面的内存发生变化,链式反应滚起雪球需要处理的数据量很庞大,于是Python干脆不支持修改字符串。
strobject.c源码
官网参考:点我跳转
源码一览:点我跳转
关于字符串的源码阅读,感兴趣的朋友可以看一下,这里不再进行延伸阅读。
最后
以上就是单薄苗条最近收集整理的关于Python系列 12 线性扁平序列(str)字符串字节串四则运算字符间隙intern机制绝对引用索引切片常用方法版本区别底层探究的全部内容,更多相关Python系列内容请搜索靠谱客的其他文章。








发表评论 取消回复