这一章主要讲数据压缩算法,PCA
1. Motivation
数据降维的目的主要包括
- 数据压缩:将高维数据压缩至低维数据,以减小数据的存储量。
- 可视化:将高维数据压缩至低维数据后,我们就可以对数据进行可视化,判断数据的离散和聚类。
1.1 Motivation I: Data Compression
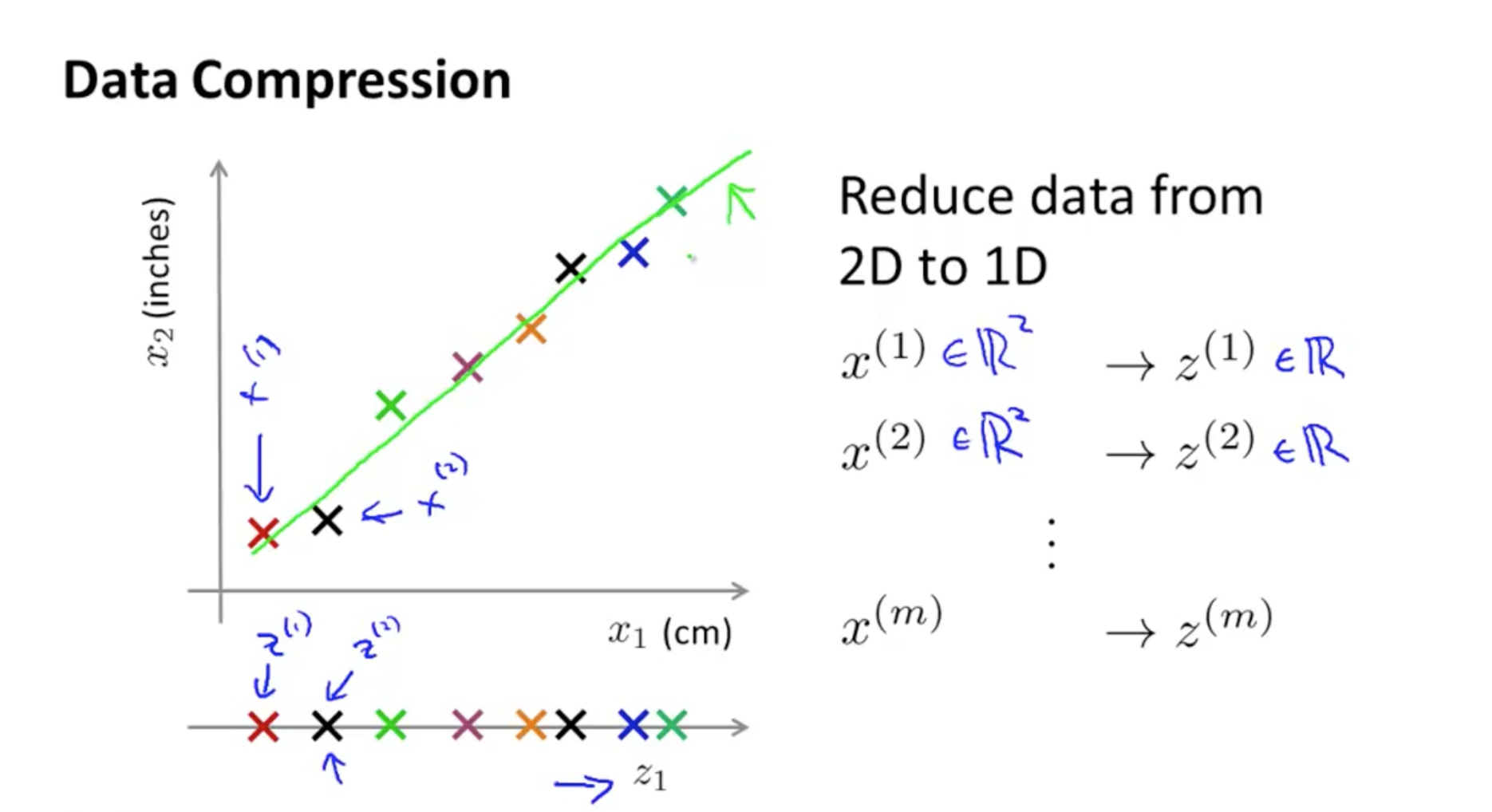
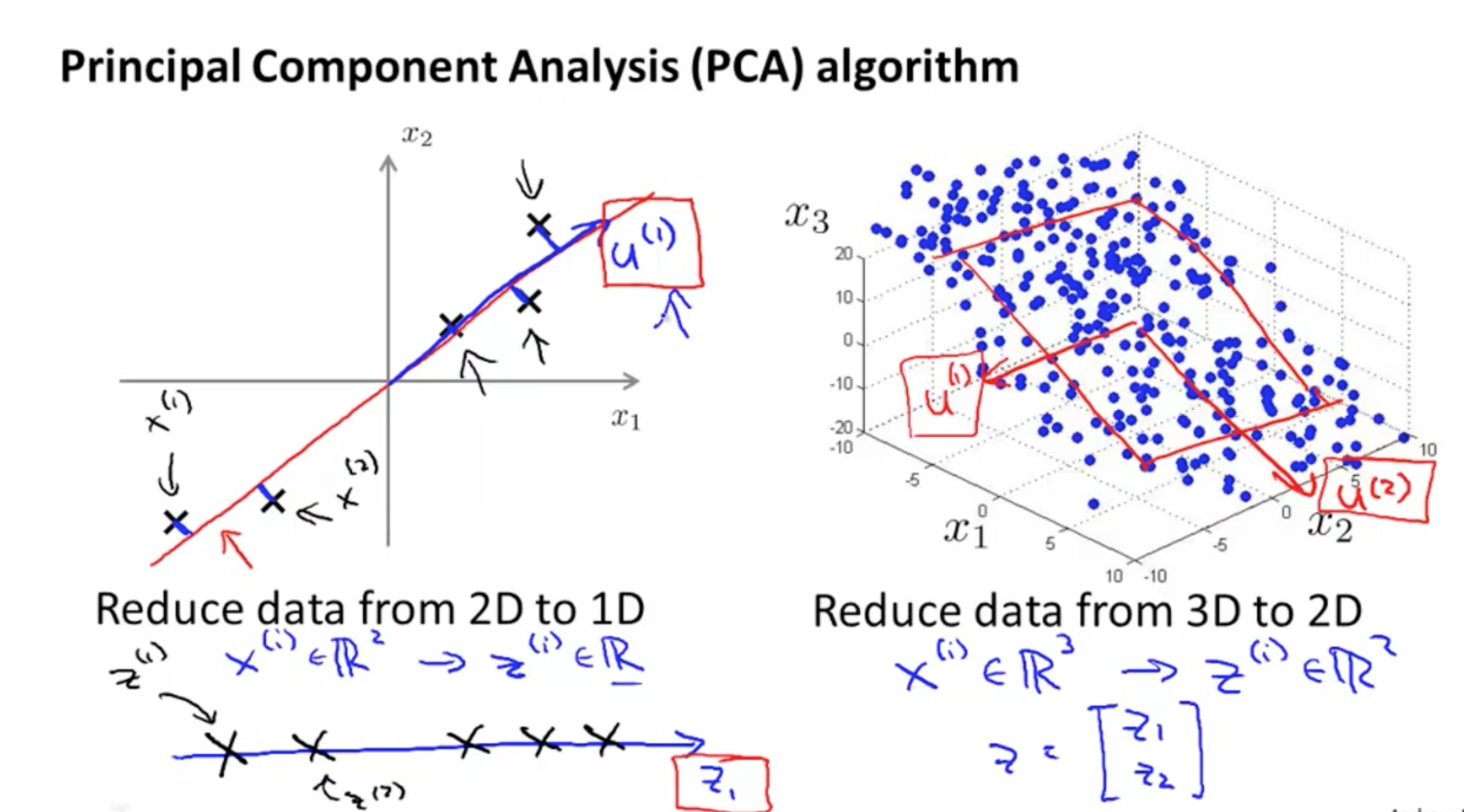
(1)从2维数据降维至1维数据
将2维数据投影到一条直线上,已达到降维至1的目的。假设有m个样本,则降维后也有m个样本,只是特征维数减小了。
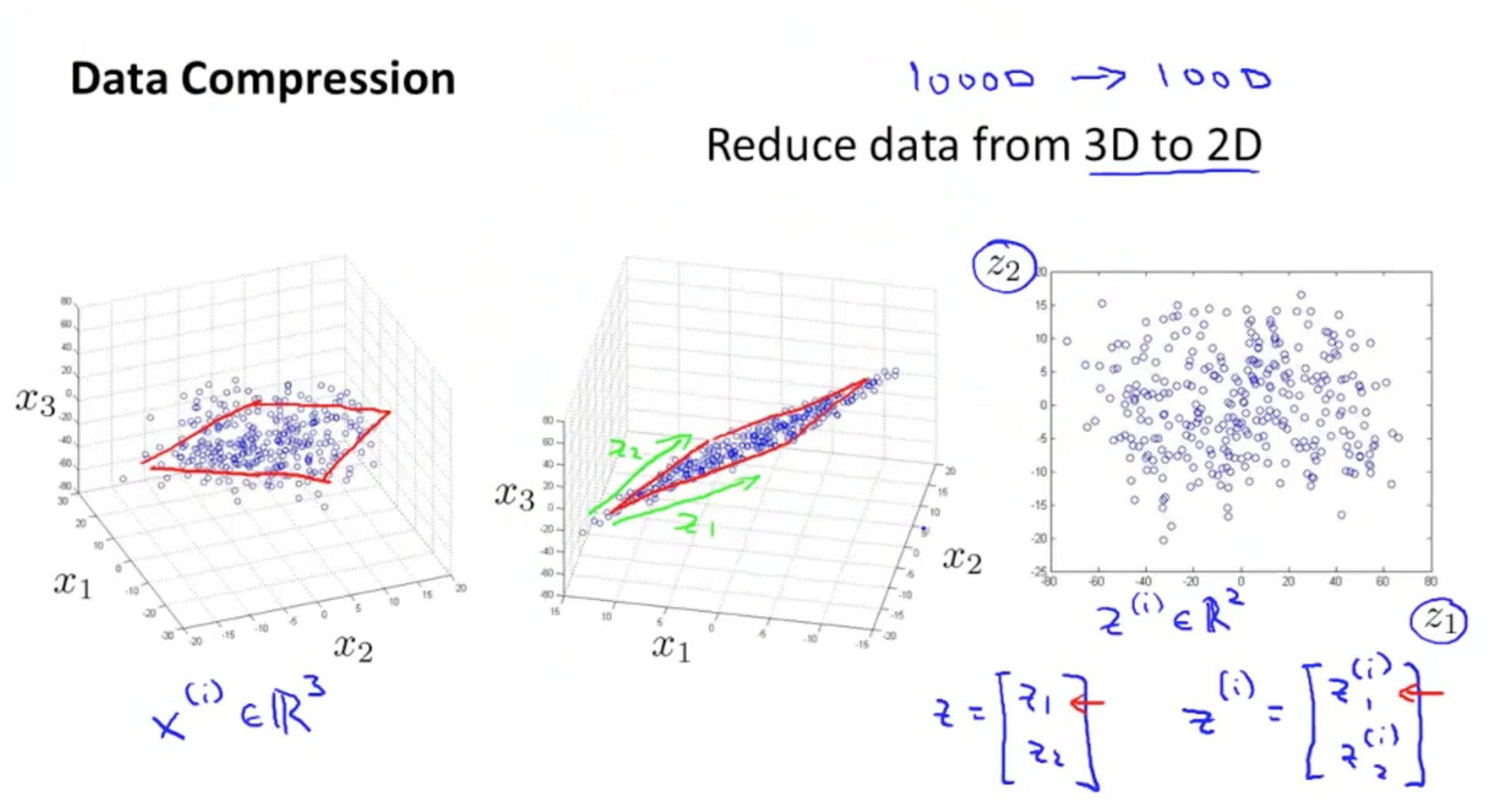
(2)从3维数据降维至2维数据
将3维数据投影到一个平面上,已达到降维至2的目的。同理,假设有m个样本,则降维后也有m个样本,只是特征维数减小了。
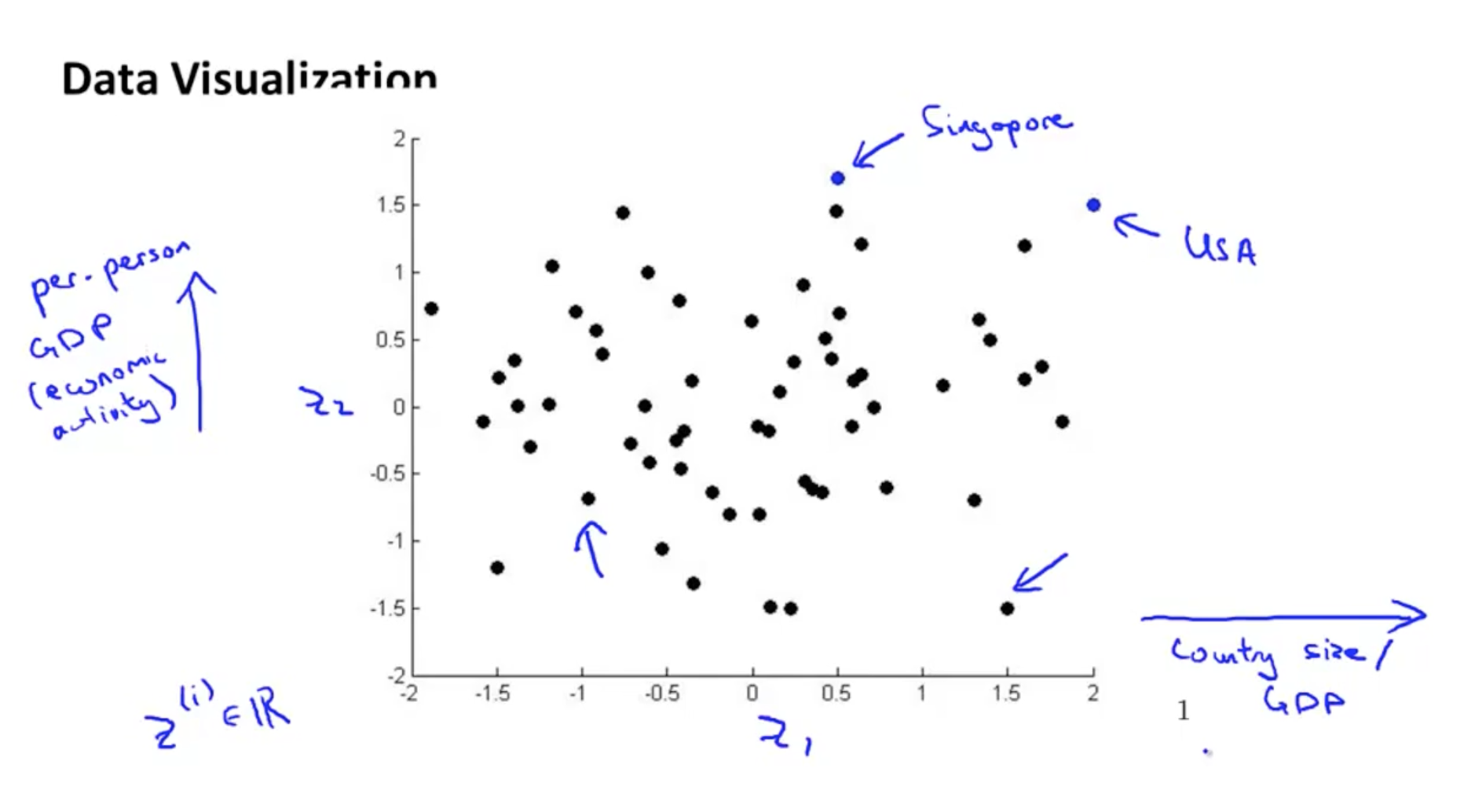
1.2 Motivation II: Visualization
数据降维的第二个作用即可以对低维数据进行可视化。假设我们有一组样本有很多特征,这样是无法进行可视化表达的。
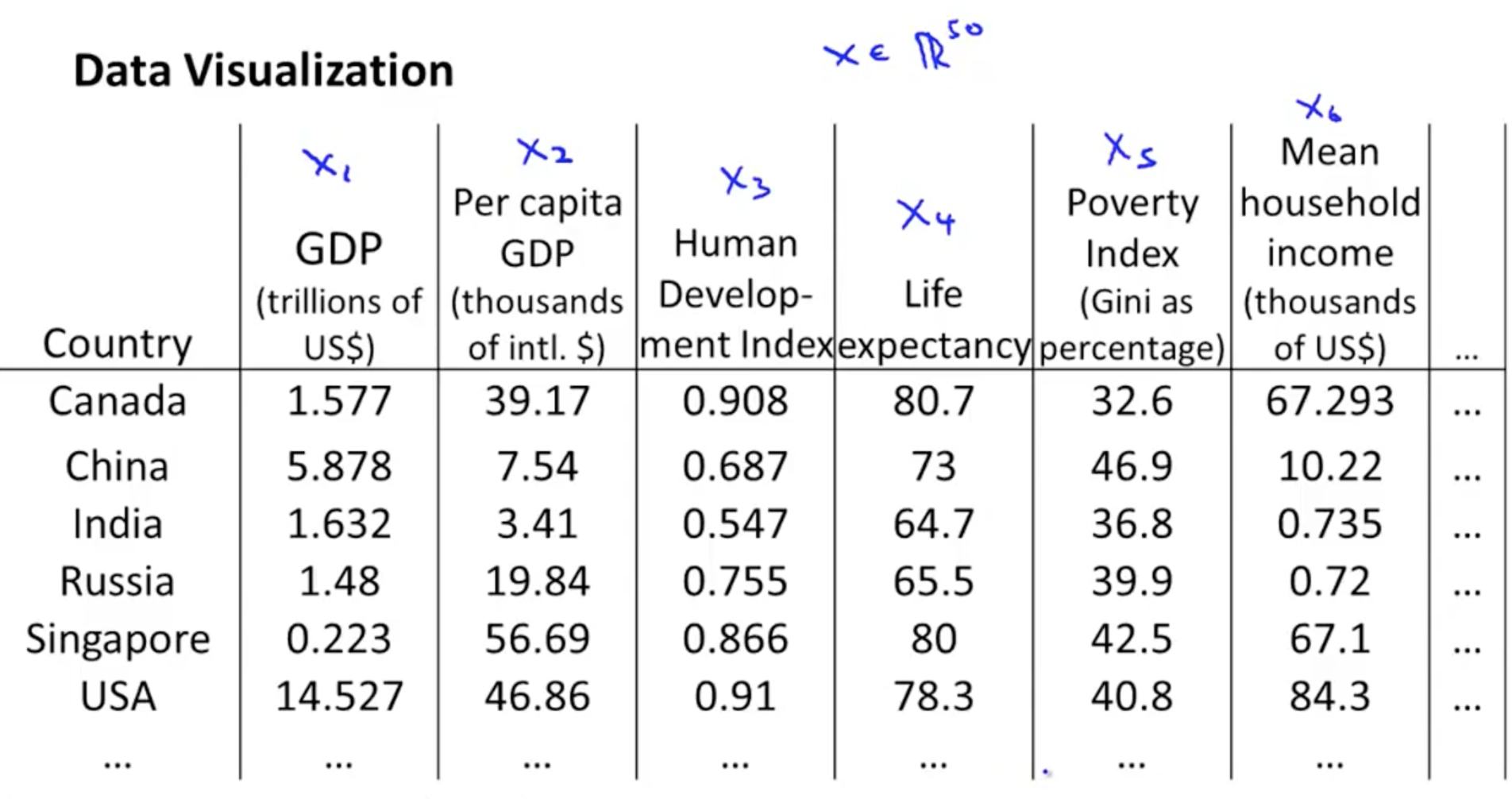
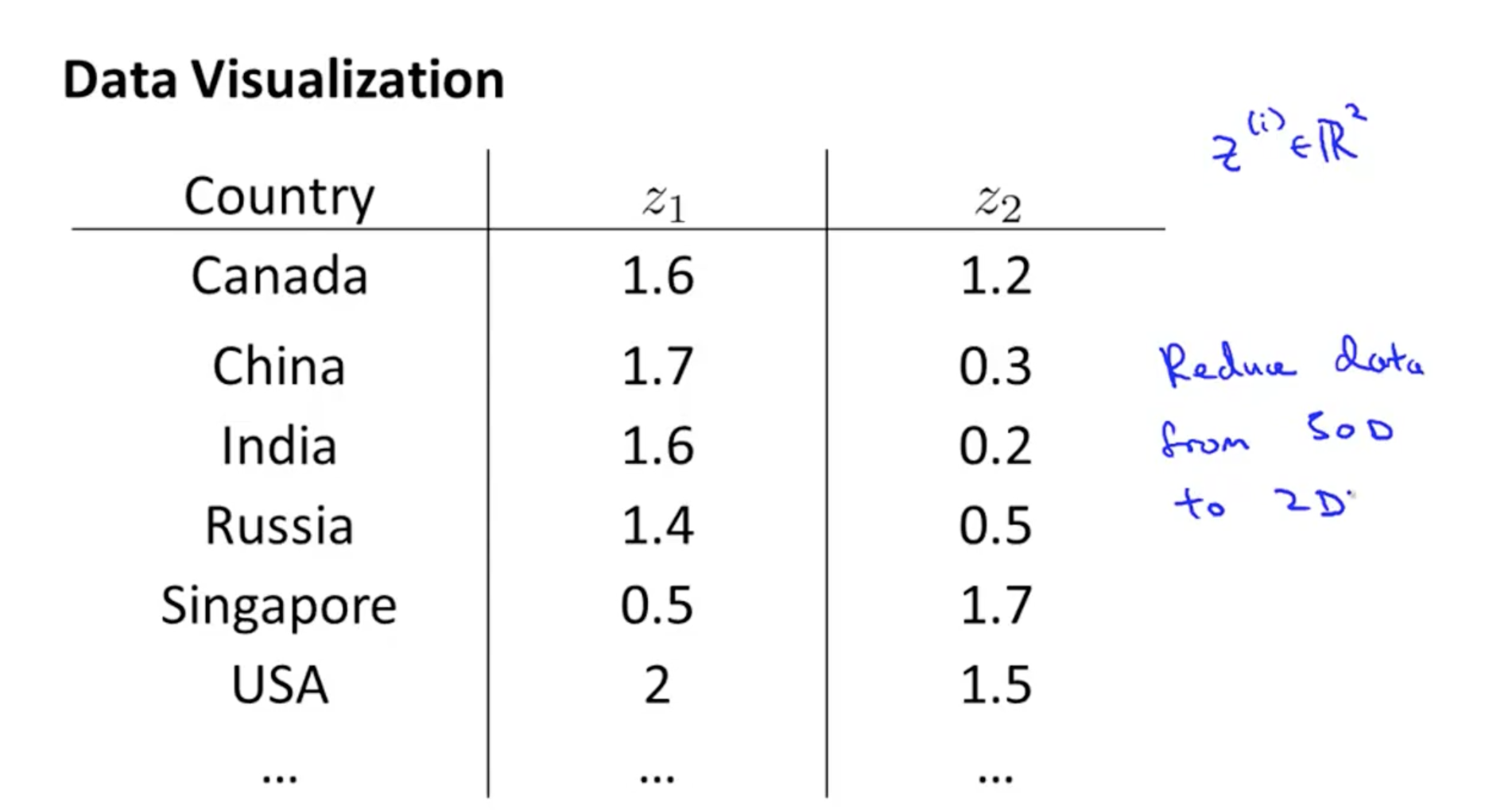
但是当我们对其进行数据降维至2维空间,可以进行可视化表达。
需要注意的是,数据降维后的特征维并没有具体的物理含义。可以根据数据的实际情况大致描述一种特征。
2. Principal Component Analysis
PCA是数据降维常用的算法。
2.1 Principal Component Analysis Problem Formulation
(1)假设我们要从2维数据降维至1维数据,那么PCA算法的目的是找到一个直线,使得所有样本投影到这条直线的距离误差最小。
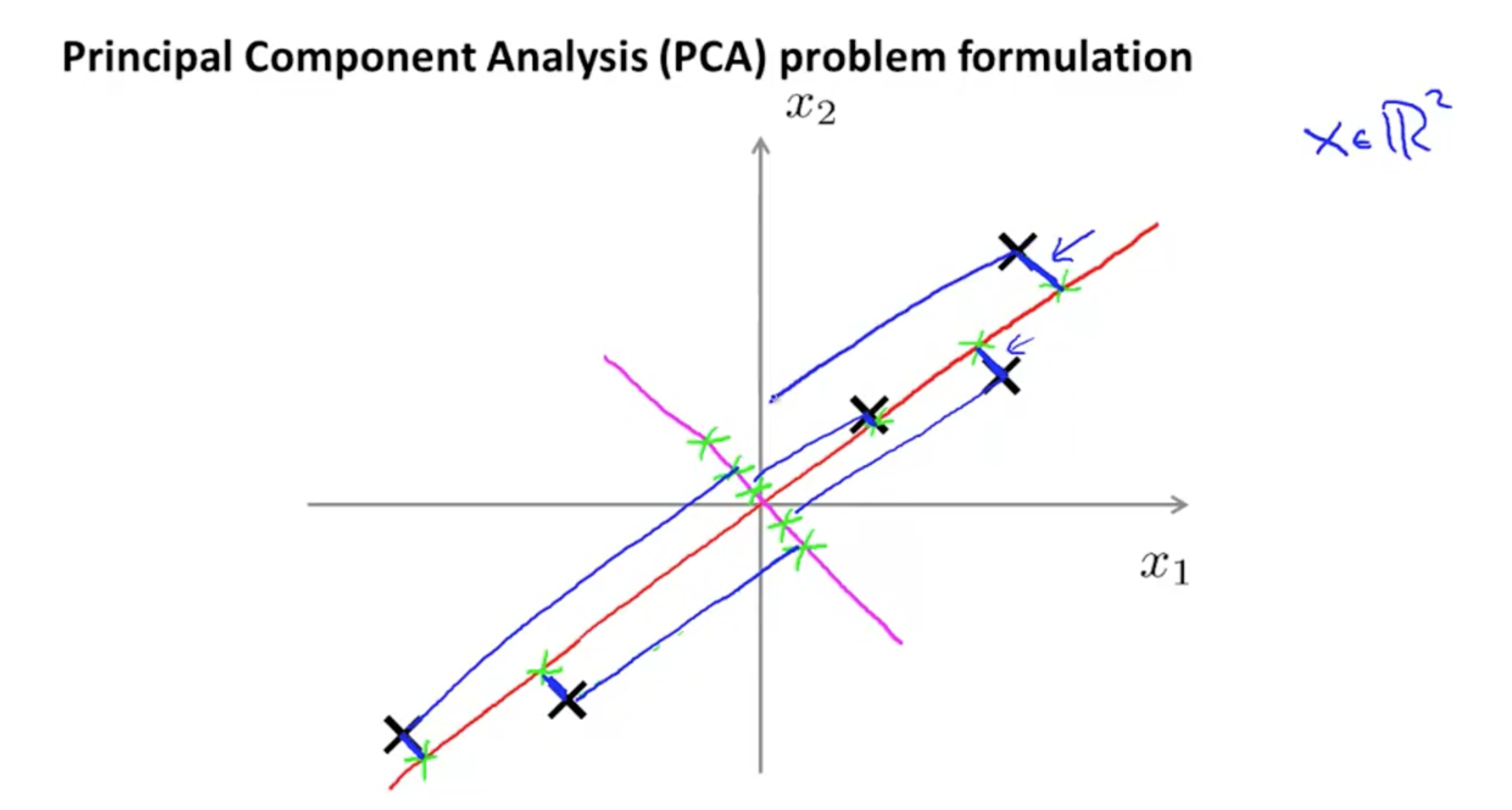
(2)更专业的解释:
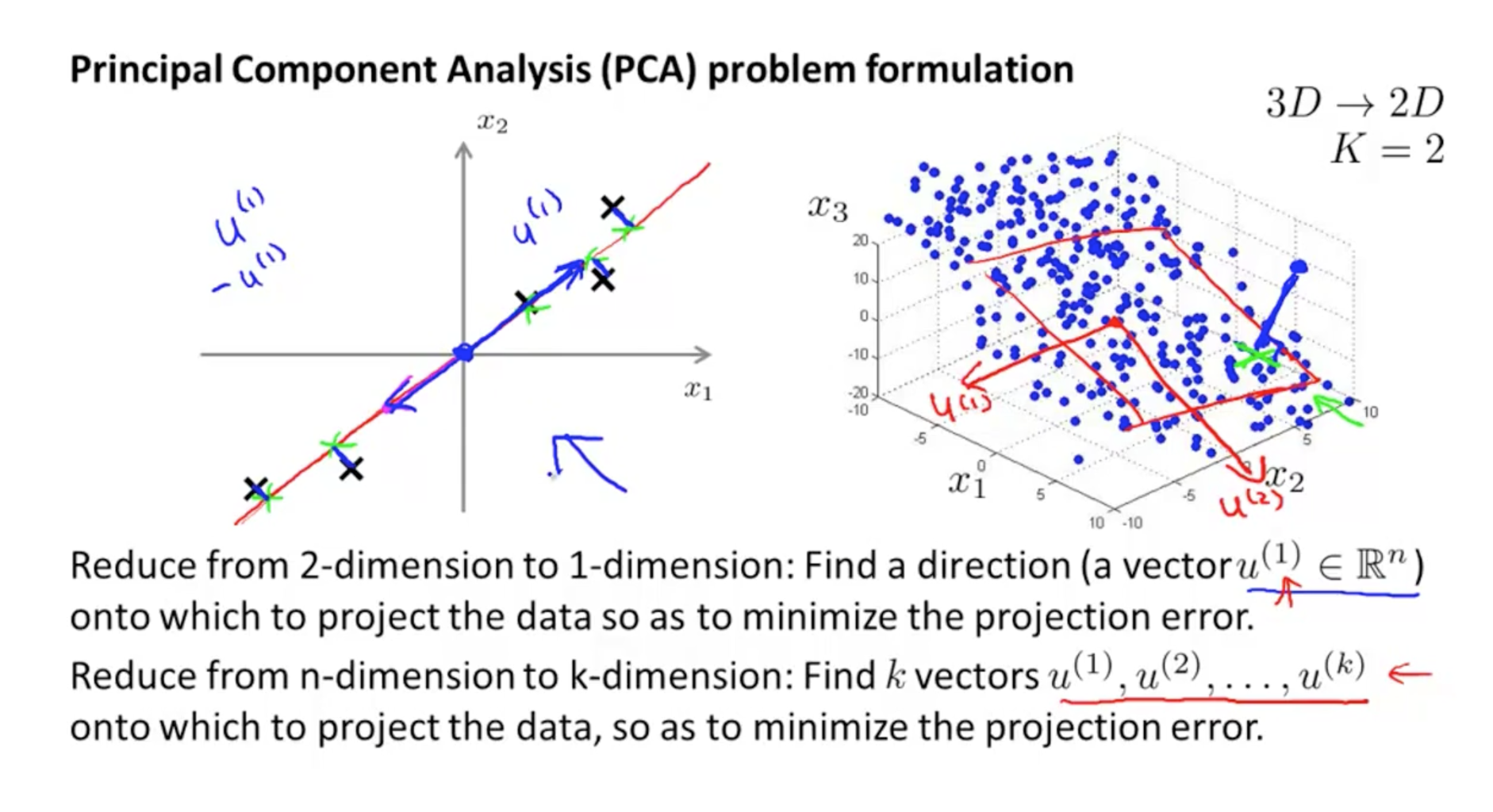
- 假设我们要从2维数据降至1维数据,那么PCA算法的目的是找到一个向量 u(1) 使得所有数据样本投影到这个向量时的投影误差最小。
- 假设我们要从n维数据降至k维数据,那么PCA目的是找到一组向量 u(1),u(2),u(3),.......u(k) 使得所有数据样本投影到这个向量时的投影误差最小。
找到的向量即是新的特征向量(坐标轴)
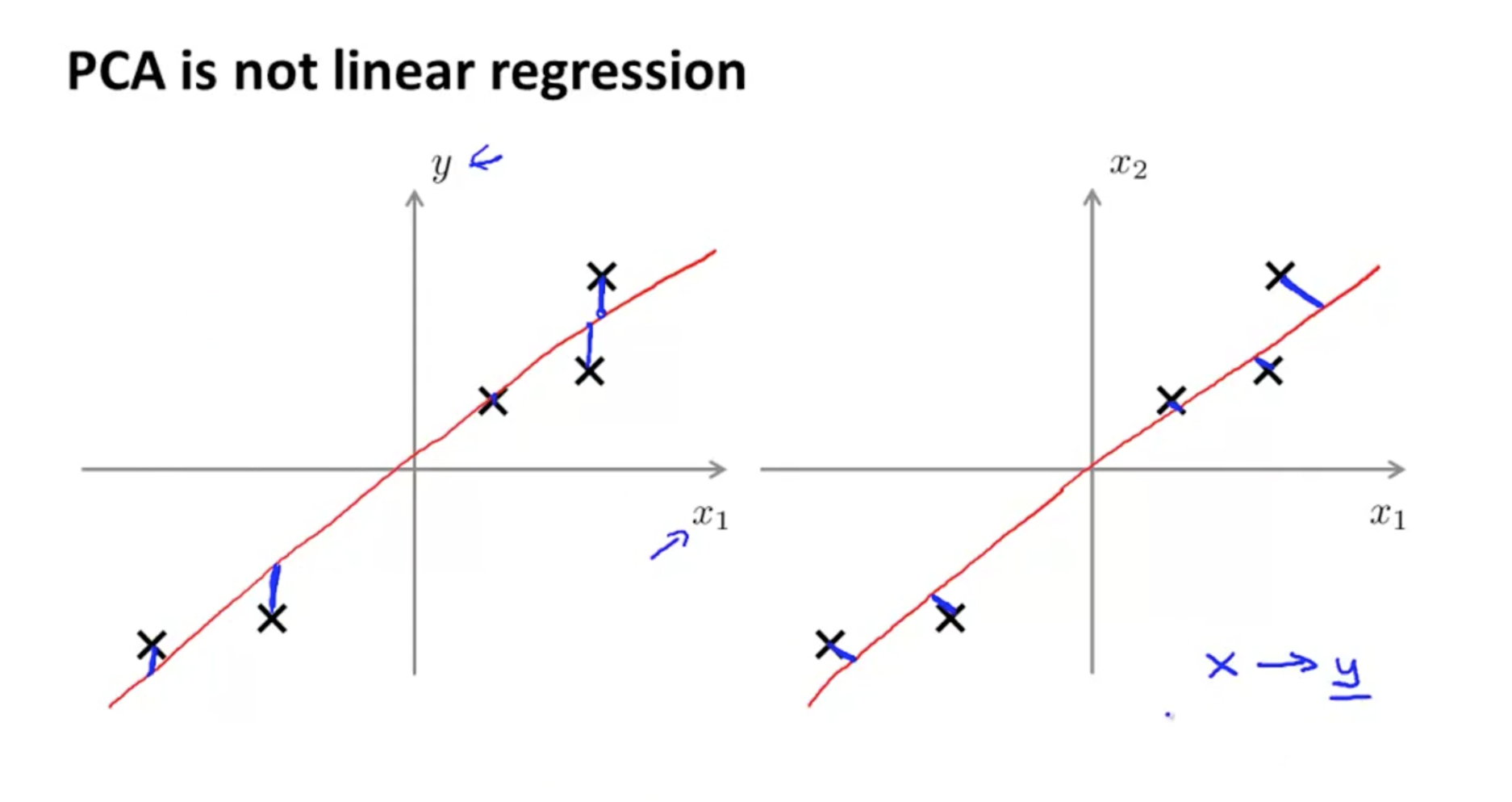
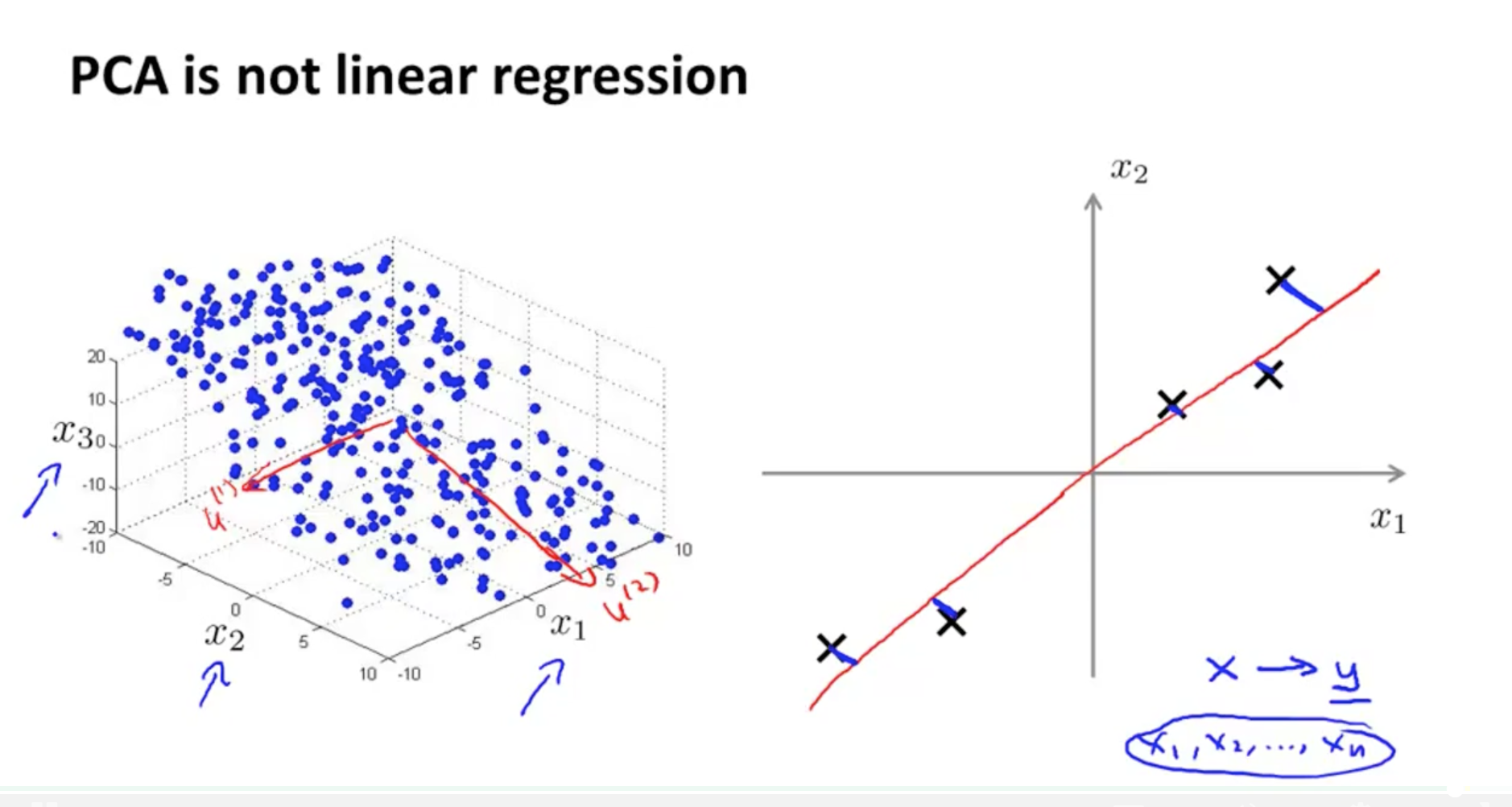
(3)PCA和线性回归的区别
- PCA和LR是不同的算法,PCA计算的是投影误差,而LR计算的是预测值与实际值的误差。
- PCA中只有特征没有标签数据y,LR中既有特征样本也有标签数据。
2.2 Principal Component Analysis Algorithm
(1)数据预处理
假设我们有一组样本,首先对其进行均值归一化(特征缩放),使其均值为0。

(2)PCA算法的目的
PCA算法是找到一组向量
u(1),u(2),u(3),.......u(k)
使得所有数据样本投影到这个向量时的投影误差最小。那应该怎么计算得到那组向量呢?
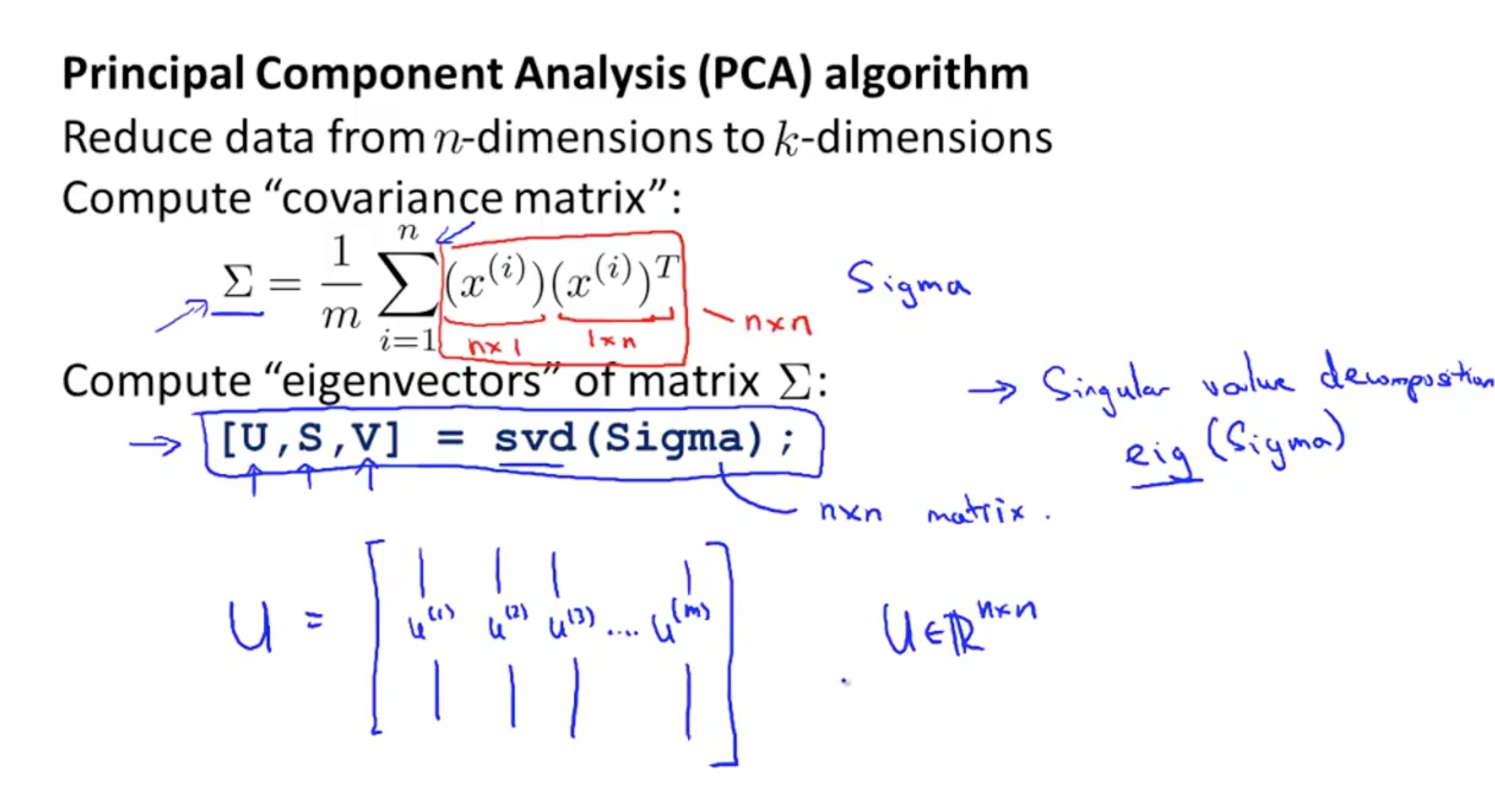
(3)PCA算法
- 首先计算所有样本的协方差矩阵 Σn×n
-
Σ=1m∑i=1n(x(i))(x(i))T
- 然后利用SVD奇异值分解分解协方差矩阵
-
[U,S,V]=svd(Σ)
- 得到的矩阵
-
Un×n=⎡⎣⎢|u(1)||u(2)||u(3)||...||u(n)|⎤⎦⎥
- 即是那组使得投影误差最小的向量(这里没有给出证明)。
在实际运算中也可以用eig()函数代替SVD函数,因为协方差矩阵始终为对称正定矩阵(n*n),一定会存在特征值,奇异值矩阵分解主要是针对那些不是方阵的矩阵进行的一种分解。
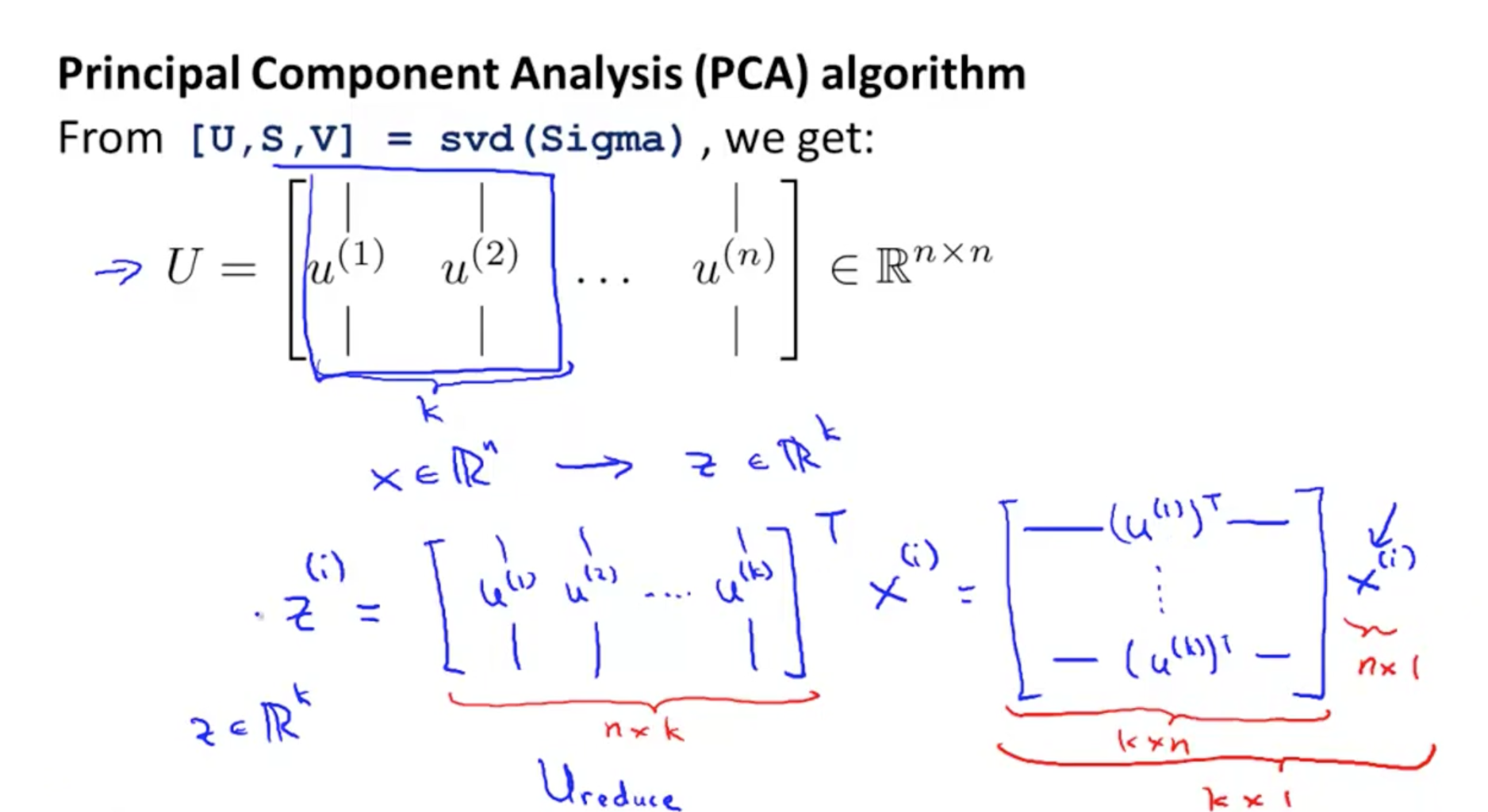
(4)PCA降维
前面算出的新特征向量组成的矩阵为nXn维的,为了降维,我们可以只取出前k个向量,然后将原始数据样本
x(1),x(2),x(3),.......x(m)
(
x∈Rn
)转化为新的特征向量下的新数据样本
z(1),z(2),z(3),.......z(m)
(
z∈Rk
)
(5)PCA算法总结
- 对数据进行均值归一化,确保每一个特征的均值为0,根据实际情况看是否做特征缩放,以使得所有特征之间具有比较行。
- 计算所有样本之间的协方差矩阵
- 利用奇异值分解对协方差矩阵进行分解求出新的特征向量空间
- 然后取前k个向量作为新的特征向量空间,将原始特征空间中的数据样本x转化为新特征空间中的新的数据样本z。(注意不包括偏差项 x0 )

3. Applying PCA
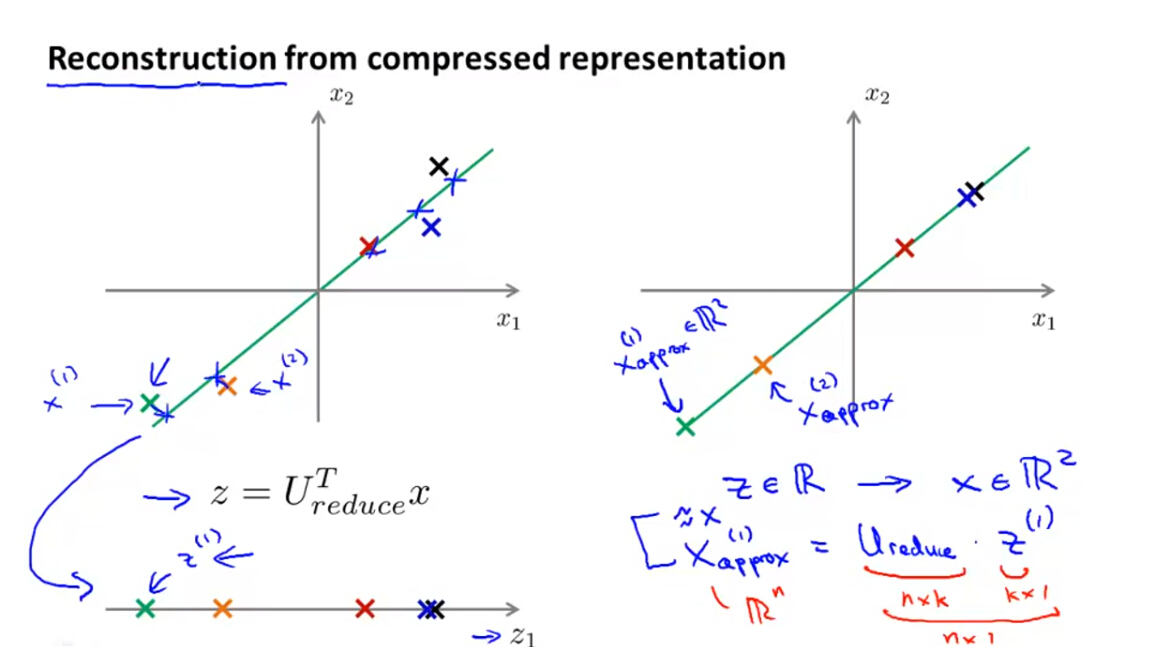
3.1 Reconstruction from Compressed Representation
之前讲了如何利用PCA算法将高维数数据降维至低维数据,现在我们想如何将压缩后的数据转化为开始的高维数据。之前的新样本数据为:
转化为原始高维数据则为:
xappox 与原始样本 x 基本相等,但并不完全相等。
3.2 Choosing the Number of Principal Components
如何选择主成分的个数对于数据压缩也是很重要的。
(1)根据平均平方投影误差和总体变化率(即样本点距离原点的远近度量值)
平均平方投影误差:
总体变化率:
则有:
上式表达了PCA保留了多少的原始数据的差异性,如99%等。

该方差的步骤是:
选择不同的k值,运行PCA计算Xapprox,然后代入上述方法计算是否满足上述条件。

(2)利用奇异值进行计算
当用SVD对样本之间的协方差矩阵进行计算时,可以求出协方差矩阵的奇异值
Sij
,则通过计算贡献率
有:
(3)计算不同K值对应的 累积贡献率,可以选择主成分的数量。例如我要保留原始数据99%的差异性,则令:

3.3 Advice for Applying PCA
(1)利用PCA加速监督学习算法
- 将训练样本的特征向量提取出来(不包括标签数据)
- 运行PCA将原始训练样本 x(1),x(2),x(3),.......x(m) ( x∈Rn )映射到降维后新数据样本 z(1),z(2),z(3),.......z(m) ( z∈Rk )中
- 将新的训练样本和标签数据重新组合重新的训练样本进行学习求解最优参数 θ
- 如果有新样本加入,则首先要对新样本进行PCA映射,然后将得到的新样本z代入到模型中进行计算
PCA只运行到训练样本中,不用在交叉验证数据集和测试数据集中,当求得了映射关系后,可以将这种关系直接应用到交叉验证数据集和测试数据集中

(2)PCA的应用
- 数据压缩
- 压缩数据,减小存储空间和内存空间
- 加速学习算法
- 可视化

(3)不建议利用PCA防止过拟合问题
PCA可以减少特征的数量(维数),所以在理论上讲可以防止过拟合问题,但是并不是最好的方法。最好的方法还是利用规则化参数对算法防止过拟合。

(4)何时使用PCA
并不是所有的问题都是要对原始数据进行PCA降维,首先应看在不使用PCA的情况下算法的运行情况,如果未达到所期望的结果,再考虑PCA对数据进行降维。

最后
以上就是大意飞机最近收集整理的关于【Stanford机器学习笔记】12-Dimensionality Reduction1. Motivation2. Principal Component Analysis3. Applying PCA的全部内容,更多相关【Stanford机器学习笔记】12-Dimensionality内容请搜索靠谱客的其他文章。








发表评论 取消回复